Hadoop系列002-从Hadoop框架讨论大数据生态
本人微信公众号,欢迎扫码关注!

从Hadoop框架讨论大数据生态
1、Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
2、Hadoop发展历史
1)Lucene--Doug Cutting开创的开源软件,用java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2)2001年年底成为apache基金会的一个子项目
3)对于大数量的场景,Lucene面对与Google同样的困难
4)学习和模仿Google解决这些问题的办法 :微型版Nutch
5)可以说Google是hadoop的思想之源(Google在大数据方面的三篇论文)
- GFS --->HDFS
- Map-Reduce --->MR
- BigTable --->Hbase
6)2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,使Nutch性能飙升
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
8)名字来源于Doug Cutting儿子的玩具大象
9)Hadoop就此诞生并迅速发展,标志这云计算时代来临
3、Hadoop三大发行版本
Apache、Cloudera、Hortonworks
1)Apache版本最原始(最基础)的版本,对于入门学习最好。
2)Cloudera在大型互联网企业中用的较多。
- 2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
- 2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
- CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强
- Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
- Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
3)Hortonworks文档较好。
- 2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
- 公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
- 雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
- Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
- HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
- Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
4、Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
5、Hadoop组成
5.1 HDFS架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
5.2 YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度。
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令。
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
5.3 MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
6、大数据技术生态体系
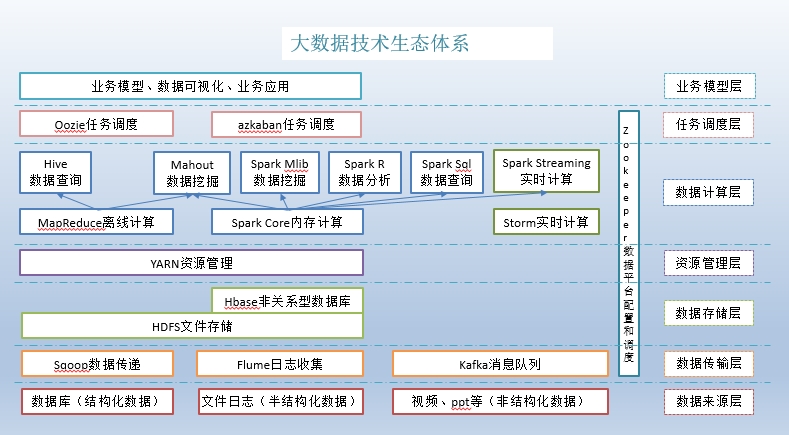
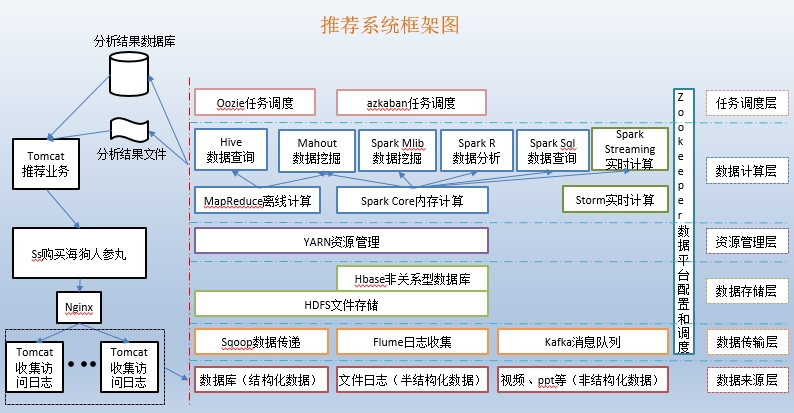
7、推荐系统框架图
Hadoop系列002-从Hadoop框架讨论大数据生态的更多相关文章
- Hadoop基础(二):从Hadoop框架讨论大数据生态
1 Hadoop是什么 2 Hadoop三大发行版本 Hadoop三大发行版本:Apache.Cloudera.Hortonworks. Apache版本最原始(最基础)的版本,对于入门学习最好. C ...
- 啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
一.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP通常是指一个更广泛的概 ...
- 从Hadoop框架讨论大数据
[Hadoop是什么?] 1)Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构. 2)主要解决,海量数据的存储和海量数据的分析计算问题. 3)广义上来说,HADOOP 通常是指一 ...
- Hadoop生态圈-大数据生态体系快速入门篇
Hadoop生态圈-大数据生态体系快速入门篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.大数据概念 1>.什么是大数据 大数据(big data):是指无法在一定时间 ...
- Hadoop优势,组成的相关架构,大数据生态体系下的模式
Hadoop优势,组成的相关架构,大数据生态体系下的模式 一.Hadoop的优势 二.Hadoop的组成 2.1 HDFS架构 2.2 Yarn架构 2.3 MapReduce架构 三.大数据生态体系 ...
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
- 追本溯源 解析“大数据生态环境”发展现状(CSDN)
程学旗先生是中科院计算所副总工.研究员.博士生导师.网络科学与技术重点实验室主任.本次程学旗带来了中国大数据生态系统的基础问题方面的内容分享.大数据的发展越来越快,但是对于大数据的认知大都还停留在最初 ...
- 开源大数据生态下的 Flink 应用实践
过去十年,面向整个数字时代的关键技术接踵而至,从被人们接受,到开始步入应用.大数据与计算作为时代的关键词已被广泛认知,算力的重要性日渐凸显并发展成为企业新的增长点.Apache Flink(以下简称 ...
- 一文带你读懂zookeeper在大数据生态的应用
一个执着于技术的公众号 一.简述 在一群动物掌管的世界中,动物没有人类聪明的思想,为了保持动物世界的生态平衡,这时,动物管理员-zookeeper诞生了. 打开Apache zookeeper的官网, ...
随机推荐
- jquery的$.extend和$.fn.extend作用及区别/用span实现进度条/腾讯云IIS端口号修改
jQuery为开发插件提拱了两个方法,分别是: jQuery.fn.extend(); jQuery.extend(); 虽然 javascript 没有明确的类的概念,但是用类来理解它,会更方便. ...
- Javascript书籍推荐----(步步为赢)
在此分享一些高清javascript书籍,因为我也没有全部看完,所以在这只是推荐,不同的书适合不同的人,所有的书在网上均有电子书,若找不到,请在博客留言,我有大部分书籍的电子稿.希望有更多的好书分享出 ...
- 区分IE8 、IE9 、IE10的专属css hack
想让IE8及以下的浏览器实现同样的效果,且不希望使用css3pie或htc或条件注释等方法时,可能就会需要用到IE8和IE9的专属css hack了. .test{ /* 1. */ color:#0 ...
- public_handers.go
package],,) ],,) ]:],,);:],],,) ) ]],,) )) ,) )) if etagMatch { w.WriteHeader(ht ...
- BZOJ_2661_[BeiJing wc2012]连连看_费用流
BZOJ_2661_[BeiJing wc2012]连连看_费用流 Description 凡是考智商的题里面总会有这么一种消除游戏.不过现在面对的这关连连看可不是QQ游戏里那种考眼力的游戏.我们的规 ...
- BZOJ_1826_[JSOI2010]缓存交换 _线段树+贪心
BZOJ_1826_[JSOI2010]缓存交换 _线段树+贪心 Description 在计算机中,CPU只能和高速缓存Cache直接交换数据.当所需的内存单元不在Cache中时,则需要从主存里把数 ...
- JVM内存异常与常用内存参数设置总结
Java Web程序由于引入大量第三方java类库,在启动时经常会遇到内存溢出(Memory Overflow)或者内存泄漏(Memory leak)问题,导致程序启动失败. 一.OOM异常分类: O ...
- HTTP VISUAL HTTP请求可视化工具、HTTP快照工具(公测)
先啰嗦几句,最近工作比较忙,再加上自己又开设了一个小站(简单点),没时间写博客,都快憋坏了,趁着周末有时间,抓紧来一篇~ HTTP VISUAL是一款HTTP可视化工具,它可以记录HTTP请求,包括请 ...
- Python核心编程
对<Python核心编程>的褒奖" The long-awaited second edition of Wesley Chun's Core PythonProgramming ...
- 从壹开始前后端分离 41 || Nginx+Github+PM2 快速部署项目(一)
前言 哈喽大家周一好!今天是农历腊月二十三,小年开始,恭祝大家新年快乐(哈哈你五福了么