Sprk SQL
一.Spark SQL概述
1.Spark SQL的前生今世
Shark是一个为Spark设计的大规模数据仓库系统,它与Hive兼容。Shark建立在Hive的代码基础上,并通过将Hive的部分物理执行计划交换出来。这个方法使得Shark的用户可以加速Hive的查询,但是Shark继承了Hive的大且复杂的代码使得Shark很难优化和维护,同时Shark依赖于Spark的版本。随着我们遇到了性能优化的上限,以及集成SQL的一些复杂的分析功能,我们发现Hive的MapReduce设计的框架限制了Shark的发展。在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。
2.什么是Spark SQL
- Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
相比于Spark RDD API,Spark SQL包含了对结构化数据和在其上运算的更多信息,Spark SQL使用这些信息进行了额外的优化,使对结构化数据的操作更加高效和方便。
有多种方式去使用Spark SQL,包括SQL、DataFrames API和Datasets API。但无论是哪种API或者是编程语言,它们都是基于同样的执行引擎,因此你可以在不同的API之间随意切换,它们各有各的特点,看你喜欢那种风格。
3.为什么要学习Spark SQL
1.Spark SQL与Hive比较
- Hive是将Hive SQL转换成MapReduce然后提交到集群中去执行,大大简化了编写MapReduce程序的复杂性,但是MapReduce这种计算模型执行效率比较慢.
- Spark SQL是将Spark SQL转换成RDD,然后提交到集群中去运行,执行效率非常快!
2.Spark SQL的特性
- 易整合
将sql查询与spark程序无缝混合,可以使用java、scala、python、R等语言的API操作。
统一的数据访问
以相同的方式连接到任何数据源。
兼容Hive
支持hiveSQL的语法。
- 标准的数据连接
可以使用行业标准的JDBC或ODBC连接。
二.DataFrame
1.什么是DataFrame
- DataFrame的前身是SchemaRDD,从Spark 1.3.0开始SchemaRDD更名为DataFrame。与SchemaRDD的主要区别是:DataFrame不再直接继承自RDD,而是自己实现了RDD的绝大多数功能。你仍旧可以在DataFrame上调用rdd方法将其转换为一个RDD。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,DataFrame带有Schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型,但底层做了更多的优化。DataFrame可以从很多数据源构建,比如:已经存在的RDD、结构化文件、外部数据库、Hive表。
2.DataFrame与RDD的区别
- RDD可看作是分布式的对象的集合,Spark并不知道对象的详细模式信息,DataFrame可看作是分布式的Row对象的集合,其提供了由列组成的详细模式信息,使得Spark SQL可以进行某些形式的执行优化。使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么,DataFrame多了数据的结构信息,即schema。这样看起来就像一张表了,DataFrame还配套了新的操作数据的方法,DataFrame API(如df.select())和SQL(select id, name from xx_table where ...)。
DataFrame还引入了off-heap,意味着JVM堆以外的内存, 这些内存直接受操作系统管理(而不是JVM)。Spark能够以二进制的形式序列化数据(不包括结构)到off-heap中, 当要操作数据时, 就直接操作off-heap内存. 由于Spark理解schema, 所以知道该如何操作。
RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
DataFrame这个高一层的抽象后,我们处理数据更加简单了,甚至可以用SQL来处理数据了,对开发者来说,易用性有了很大的提升。通过DataFrame API或SQL处理数据,会自动经过Spark 优化器(Catalyst)的优化,即使你写的程序或SQL不高效,也可以运行的很快。
3.DataFrame与RDD的优缺点
- RDD的优缺点:
优点:
(1)编译时类型安全
编译时就能检查出类型错误
(2)面向对象的编程风格
直接通过对象调用方法的形式来操作数据
缺点:
(1)序列化和反序列化的性能开销
无论是集群间的通信, 还是IO操作都需要对对象的结构和数据进行序列化和反序列化。
(2)GC的性能开销
频繁的创建和销毁对象,
势必会增加GC
- DataFrame的优缺点
DataFrame通过引入schema和off-heap(不在堆里面的内存,指的是除了不在堆的内存,使用操作系统上的内存),解决了RDD的缺点, Spark通过schame就能够读懂数据, 因此在通信和IO时就 只需要序列化和反序列化数据, 而结构的部分就可以省略了;通过off-heap引入,可以快速的操作数据,避免大量的GC。但是却丢了RDD的优点,DataFrame不是类型安全的, API也不是面向对象 风格的。
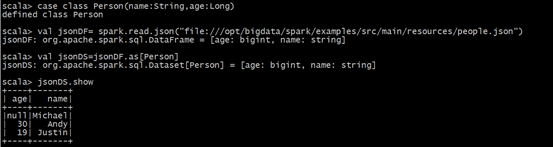
4.读取数据源创建DataFrame
1.读取文本文件创建DataFrame
在spark2.0版本之前,Spark SQL中SQLContext是创建DataFrame和执行SQL的入口,可以利用hiveContext通过hive sql语句操作hive表数据,兼容hive操作,并且hiveContext继承自SQLContext。在 spark2.0之后,这些都统一于SparkSession,SparkSession 封装了 SparkContext,SqlContext,通过SparkSession可以获取到SparkConetxt,SqlContext对象。
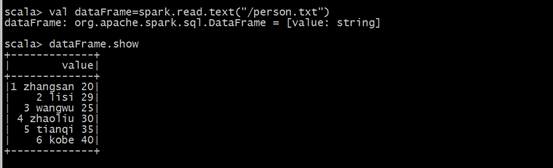
(1)在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上。person.txt内容为:
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
上传数据文件到HDFS上:hdfs dfs -put person.txt /
(2)在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
先执行 spark-shell --master local[2]
val lineRDD= sc.textFile("/person.txt").map(_.split(" "))

(3)定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)

(4)将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))

(5)将RDD转换成DataFrame
val personDF = personRDD.toDF

(6)对DataFrame进行处理
personDF.show

personDF.printSchema
4.DataFrame常用操作
1.DSL风格语法
DataFrame提供了一个领域特定语言(DSL)来操作结构化数据。
下面是一些使用示例:
(1)查看DataFrame中的内容,通过调用show方法
personDF.show

(2)查看DataFrame部分列中的内容 查看name字段的数据
personDF.select(personDF.col("name")).show

查看name字段的另一种写法
personDF.select("name").show

查看 name 和age字段数据
personDF.select(col("name"), col("age")).show

(3)打印DataFrame的Schema信息
personDF.printSchema

(4)查询所有的name和age,并将age+1
personDF.select(col("id"), col("name"), col("age") + 1).show

也可以这样:
personDF.select(personDF("id"), personDF("name"), personDF("age") + 1).show

(5)过滤age大于等于25的,使用filter方法过滤
personDF.filter(col("age") >= 25).show

(6)统计年龄大于30的人数
personDF.filter(col("age")>30).count()

(7)按年龄进行分组并统计相同年龄的人数
personDF.groupBy("age").count().show

2.SQL 风格语法
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql() 来执行SQL语句查询,结果返回一个DataFrame。
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:
personDF.registerTempTable("t_person")
(1)查询年龄最大的前两名
spark.sql("select * from t_person order by age desc limit 2").show

(2)显示表的Schema信息
spark.sql("desc t_person").show

(3)查询年龄大于30的人的信息
spark.sql("select * from t_person where age > 30 ").show

5.DataSet
- 什么是DataSet
DataSet是分布式的数据集合,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函 数)以及使用了Spark SQL优化的执行引擎。DataSet可以通过JVM的对象进行构建,可以用函数式的转换(map/flatmap/filter)进行多种操作。
- DataSet DataFrame RDD的区别
假设RDD中的两行数据长这样:
| 1, 张三, 23 |
| 2, 李四, 35 |
那么DataFrame中的数据长这样:
| ID:String | Name:String | Age:int |
| 1 | 张三 | 23 |
| 2 | 李四 | 35 |
那么Dataset中的数据长这样:
| value:String |
| 1, 张三, 23 |
| 2, 李四, 35 |
DataSet包含了DataFrame的功能,Spark2.0中两者统一,DataFrame表示为DataSet[Row],即DataSet的子集。
(1)DataSet可以在编译时检查类型
(2)并且是面向对象的编程接口
相比DataFrame,Dataset提供了编译时类型检查,对于分布式程序来讲,提交一次作业太费劲了(要编译、打包、上传、运行),到提交到集群运行时才发现错误,这会浪费大量的时间,这也是引 入Dataset的一个重要原因。
DataFrame和DataSet可以相互转化
(1)DataFrame转为 DataSet
df.as[ElementType] 这样可以把DataFrame转化为DataSet。
(2)DataSet转为DataFrame
ds.toDF() 这样可以把DataSet转化为DataFrame。
- 创建DataSet
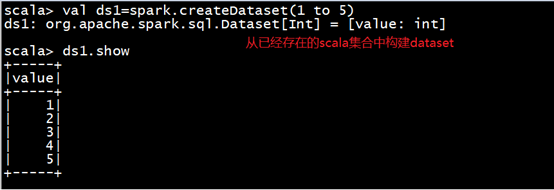
(1)通过spark.createDataset创建
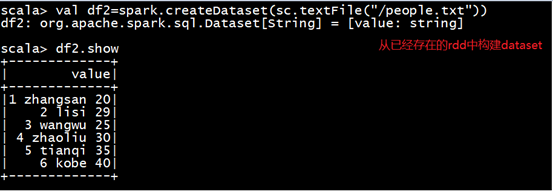
(2)通toDS方法生成DataSet
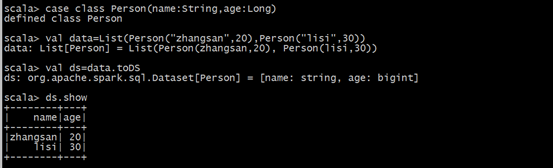
(1)通过DataFrame转化生成 使用as[类型]转换为DataSet
Sprk SQL的更多相关文章
- SQL Server优化技巧之SQL Server中的"MapReduce"
日常的OLTP环境中,有时会涉及到一些统计方面的SQL语句,这些语句可能消耗巨大,进而影响整体运行环境,这里我为大家介绍如何利用SQL Server中的”类MapReduce”方式,在特定的统计情形中 ...
- 最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目
最近帮客户实施的基于SQL Server AlwaysOn跨机房切换项目 最近一个来自重庆的客户找到走起君,客户的业务是做移动互联网支付,是微信支付收单渠道合作伙伴,数据库里存储的是支付流水和交易流水 ...
- SQL Server 大数据搬迁之文件组备份还原实战
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 解决方案(Solution) 搬迁步骤(Procedure) 搬迁脚本(SQL Codes) ...
- Sql Server系列:分区表操作
1. 分区表简介 分区表在逻辑上是一个表,而物理上是多个表.从用户角度来看,分区表和普通表是一样的.使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性. 分区表是把数据按设 ...
- SQL Server中的高可用性(2)----文件与文件组
在谈到SQL Server的高可用性之前,我们首先要谈一谈单实例的高可用性.在单实例的高可用性中,不可忽略的就是文件和文件组的高可用性.SQL Server允许在某些文件损坏或离线的情况下,允 ...
- EntityFramework Core Raw SQL
前言 本节我们来讲讲EF Core中的原始查询,目前在项目中对于简单的查询直接通过EF就可以解决,但是涉及到多表查询时为了一步到位就采用了原始查询的方式进行.下面我们一起来看看. EntityFram ...
- 从0开始搭建SQL Server AlwaysOn 第一篇(配置域控)
从0开始搭建SQL Server AlwaysOn 第一篇(配置域控) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www.cnb ...
- 从0开始搭建SQL Server AlwaysOn 第二篇(配置故障转移集群)
从0开始搭建SQL Server AlwaysOn 第二篇(配置故障转移集群) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www ...
- 从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn)
从0开始搭建SQL Server AlwaysOn 第三篇(配置AlwaysOn) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://w ...
随机推荐
- JavaScript中Array数组的方法
查找: indexOf.lastIndexOf 迭代:every.filter.forEach.map.somereduce.reduceRight 用法: /* 1 查找方法: * arr.inde ...
- 翻译:JVM虚拟机规范1.7中的运行时常量池部分(二)
本篇为JVM虚拟机规范1.7中的运行时常量池部分系列的第二篇. 4.4.4. The CONSTANT_Integer_info and CONSTANT_Float_info Structures ...
- Web微信
一.源代码地址: https://github.com/HuangAm/Webweixin 二.总结: 1.分析Http请求 - 请求方式:get.post等等 - URL:每个请求的url,固定部分 ...
- MIT许可证
MIT许可证(The MIT License)是许多软件授权条款中,被广泛使用的其中一种.与其他常见的软件授权条款(如GPL.LGPL.BSD)相比,MIT是相对宽松的软件授权条款. MIT 许可证几 ...
- 定义一个方法get_page(url),url参数是需要获取网页内容的网址,返回网页的内容。提示(可以了解python的urllib模块)
定义一个方法get_page(url),url参数是需要获取网页内容的网址,返回网页的内容.提示(可以了解python的urllib模块) import urllib.request def get_ ...
- Java集合框架的四个接口
接口 [四个接口 collection list set map 的区别] collection 存储不唯一的无序的数据 list 存储有序的不唯一的数据 set 存储无序的唯一的数据 m ...
- C/C++下调用matlab函数操作说明
1.matlab的安装 连接:http://pan.baidu.com/s/1qXuF7aO 安装32位版本的matlab(在目录下bin文件夹中有两个文件夹,选择win32文件夹下的setup进行安 ...
- Linux(一)VMware虚拟机的安装
vmware的安装文件: 链接:https://pan.baidu.com/s/1QGjNqRZzE-vV7Af0PI2QYA 密码:omfe 1.1 首先下载安装包 安装包的内容 1.2 双击exe ...
- Linux提示字符设置
当我们登陆linux后,显示的提示字符究竟是什么意思呢?又可不可以设置呢. 首先来看看默认的显示: 普通用户: [fuwh@localhost ~]$ root用户: [root@localhost ...
- 【GDOI】【图论-最短路】时间与空间之旅
最近打的一场校内训练的某题原题... 题目如下: Description 公元22××年,宇宙中最普遍的交通工具是spaceship.spaceship的出现使得星系之间的联系变得更为紧密,所以spa ...