[Note] Yet Another Resource Negotiator
Yet Another Resource Negotiator
Apache Hadoop YARN 是新一代资源管理调度框架,主要针对 Hadoop MapReduce 1.0 的缺陷做出了改进
MapReduce 1.0 的缺陷
MapReduce 1.0 采用 Master/Slave 架构设计,包括一个 JobTracker 和若干个 TaskTracker
前者负责作业调度和资源管理,后者负责执行 JobTracker 指派的具体任务
这种架构设计有以下的缺陷
单点故障问题(single point of failure),单一的 JobTracker 负责所有 MapReduce 作业的调度
JobTracker 负载过重,JobTracker 既要负责作业调度和失败回复,又要负责资源管理分配,导致一旦 MapReduce 任务过多,JobTracker 需要的内存开销就过大,容易引起 JobTracker 失败,因此 MapReduce 1.0 支持的主机数目的上限仅约为 4000 个
TaskTracker 的内存溢出,在 TaskTracker 端,资源的分配并不考虑 CPU 和内存的实际使用情况,而是根据 MapReduce 任务的个数来分配资源,当两个具有较大内存消耗的任务分配到同一个 TaskTracker 上时,容易发生内存溢出
资源的不合理划分,CPU 和内存的资源被强制等量划分成多个插槽(slot),插槽又被进一步划分为 Map 插槽和 Reduce 插槽两种,分别提供给 Map 任务和 Reduce 任务使用,彼此之间不能使用分配给对方的插槽。这会导致当 Map 任务已经用完 Map 插槽时,即使系统中还有大量空闲的 Reduce 插槽,也不能拿来运行 Map 任务,反之亦然。从而当系统中一种任务满负荷,另一种几乎空闲时,会造成资源的浪费
YARN 的设计思路
YARN 的基本设计思路是放权,即通过把原 JobTracker 的三个主要功能,资源管理,任务调度和任务监控进行拆分,分别交给不同的新组件去管理,来改变原来 JobTracker 负担过重的情况
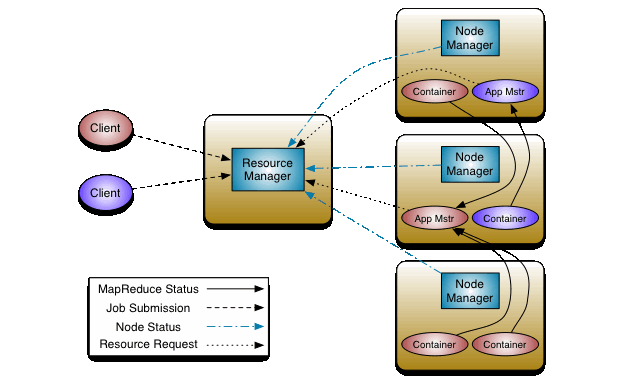
YARN 包括 ResourceManager,ApplicationMaster 和 NodeManager
ResourceManager 负责资源管理,ApplicationMaster 负责任务调度和监控,NodeManager 负责具体执行任务
此前在 Hadoop 1.0 中,MapReduce 1.0 既是一个计算框架,也是一个资源管理调度框架,到了 Hadoop 2.0 以后,MapReduce 1.0 的资源管理调度功能分离重构为 YARN,YARN 是一个纯粹的资源管理调度框架,而原来的 MapReduce 变为 MapReduce 2.0,是一个运行在 YARN 上的纯粹计算框架,不再自己负责资源管理调度,转而由 YARN 提供资源管理调度服务
YARN 的体系结构
| 组件(Component) | 功能 |
|---|---|
| ResourceManager | ①处理客户端请求 ②启动/监控 ApplicationMaster ③监控 NodeManager ④资源分配与调度 |
| ApplicationMaster | ①申请资源给应用程序,并把内部任务分配给应用程序 ②任务的调度,监控和容错 |
| NodeManager | ①单个节点上的资源管理 ②处理来自 ResourceManager 的命令 ③处理来自 ApplicationMaster 的命令 |
YARN 中以容器(Container)作为动态资源分配单位,相比 MapReduce 1.0 使用基于任务数目的插槽,容器内封装了一定数量的 CPU,内存和磁盘等资源,从而限定每个应用程序可以使用的资源量
YARN 的工作流程
下面以在 YARN 框架中执行一个 MapReduce 程序,从提交到完成作为例子
用户编写客户端应用程序,向 YARN 提交应用程序,提交的内容包括 ApplicationMaster 程序,启动 ApplicationMaster 的命令和用户程序等
YARN 中的 ResourceManager 负责接收和处理来自客户端的请求,接到客户端应用程序请求后,ResourceManager 里面的调度器回味应用程序分配一个容器。同时,ResourceManager 的应用程序管理器会与该容器所在的 NodeManager 通信,为该应用程序在该容器中启动一个 ApplicationMaster
ApplicationMaster 被创建后首先向 ResourceManager 注册,从而使得用户可以通过 ResourceManager 来直接查看应用程序的运行状态,步骤 4 到 7 是应用程序的执行步骤
ApplicationMaster 采用轮询的方式通过 RPC(remote procedure call)协议向 ResourceManager 申请资源
ResourceManager 以容器的形式向提出申请的 ApplicationMaster 分配资源,ApplicationMaster 申请到资源后,与该容器所在的 NodeManager 通信,要求它启动任务
当 ApplicationMaster 要求容器启动任务时,ApplicationMaster 会为任务设置好运行环境,包括环境变量,jar 包和二进制程序等,然后将任务启动命令写到一个脚本中,最后通过在容器中运行该脚本来启动任务
各个任务通过某个 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,让 ApplicationMaster 随时掌握任务运行状态,以便在任务失败时重启任务
应用程序运行完成后,ApplicationMaster 向 ResourceManager 的应用程序管理器注销并关闭自己
[Note] Yet Another Resource Negotiator的更多相关文章
- Hadoop 2.0 中的资源管理框架 - YARN(Yet Another Resource Negotiator)
1. Hadoop 2.0 中的资源管理 http://dongxicheng.org/mapreduce-nextgen/hadoop-1-and-2-resource-manage/ Hadoop ...
- YARN - Yet Another Resource Negotiator
http://www.socc2013.org/home/program http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-ya ...
- spark 笔记 4:Apache Hadoop YARN: Yet Another Resource Negotiator
spark支持YARN做资源调度器,所以YARN的原理还是应该知道的:http://www.socc2013.org/home/program/a5-vavilapalli.pdf 但总体来说, ...
- The Qt Resource System
The Qt Resource System The Qt resource system is a platform-independent mechanism for storing binary ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- Migrating from MapReduce 1 (MRv1) to MapReduce 2 (MRv2, YARN)...
This is a guide to migrating from Apache MapReduce 1 (MRv1) to the Next Generation MapReduce (MRv2 o ...
- YARN(MapReduce 2)运行MapReduce的过程-源码分析
这是我的分析,当然查阅书籍和网络.如有什么不对的,请各位批评指正.以下的类有的并不完全,只列出重要的方法. 如要转载,请注上作者以及出处. 一.源码阅读环境 需要安装jdk1.7.0版本及其以上版本, ...
- Hadoop3.x 三大组件详解
Hadoop Hadoop适合海量数据分布式存储和分布式计算 运行用户使用简单的编程模型实现跨机器集群对海量数据进行分布式计算处理 1. 概述 1.1 简介 Hadoop核心组件 HDFS (分布式文 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- 转-Web Service中三种发送接受协议SOAP、http get、http post
原文链接:web服务中三种发送接受协议SOAP/HTTP GET/HTTP POST 一.web服务中三种发送接受协议SOAP/HTTP GET/HTTP POST 在web服务中,有三种可供选择的发 ...
- Servlet--取得session,application内置对象
在前面的博客里面,使用Servlet取得了request,response,config对象,实际上通过Servlet程序也可以取得session,application等内置对象. 1,通过Http ...
- YourSQLDba介绍
YourSQLDba介绍 YourSQLDba是一个法国人写的程序,它是由一系列T-SQL存储过程构成的脚本文件.可以理解成一个组件或安装包,从而简化了在Mircorsoft SQL Server 2 ...
- shell第四篇(上)
第四篇了解Shell 命令执行流程图 {网中人大哥推荐参考Learning the Bash Shell, 2nd Edition,第 178页:中文版229页} Shell 从标准输入或脚本中读取的 ...
- dotween tips
涉及kill及复用的行为比较奇怪. 使用shortcut方式调用dotween时,每次调用都是增加一个新的tweener,如果该tweener控制的属性与上次调用相同时,会出现奇怪的行为,应该是多个t ...
- How do I copy SQL Azure database to my local development server?(如何将Azure 中的数据库备份到本地)
Now you can use the SQL Server Managerment Studio to do this: Connect to the SQL Azure database. 通过 ...
- python交互模式下tab键自动补全
import rlcompleter,readline readline.parse_and_bind('tab:complete')
- Codeforce D. Make a Permutation!
D. Make a Permutation! time limit per test 2 seconds memory limit per test 256 megabytes input stand ...
- Vue.js根据列表某列值更新filter
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- BZOJ 4078: [Wf2014]Metal Processing Plant [放弃了]
以后再也不做$World Final$的题了................ 还我下午 bzoj上TLE一次后就不敢交了然后去uva交 Claris太神了代码完全看不懂 还有一个代码uva上竟然WA了 ...