Python【第二课】 字符串,列表,字典,集合,文件操作
本篇内容
字符串操作
列表,元组操作
字典操作
集合操作
文件操作
- 其他
1.字符串操作
1.1 字符串定义
特性:不可修改
字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
name = "40kuaiqianzhuawawa"
name = '40kuaiqianzhuawawa'
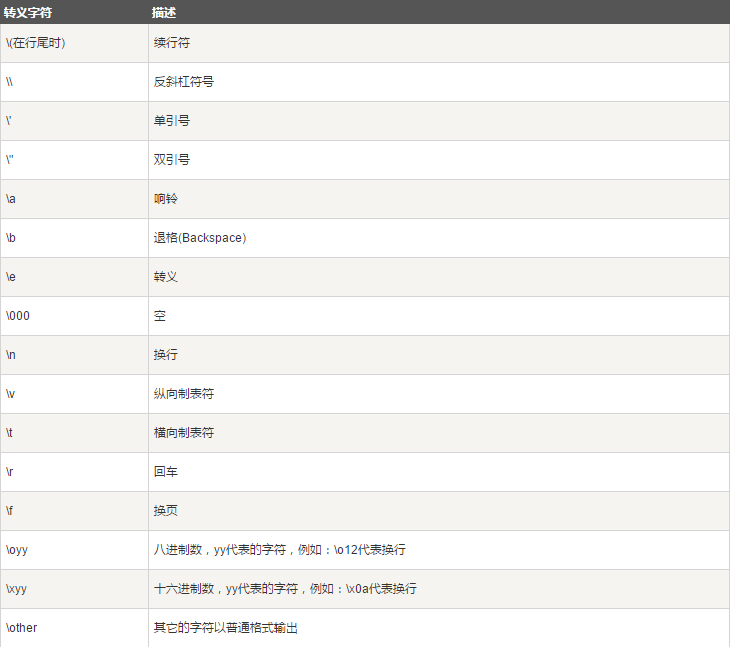
1.2 python转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:
1.3 Python字符串运算符
a = "40kuai"
b = "Python"
# 字符串连接
# +
print(a+b) # 输出:40kuaiPython # 重复输出字符串
# *
print(a * 2) # 输出:40kuai40kuai # 通过索引获取字符串中字符
# []
print(a[1]) # 输出:0 # 截取字符串中的一部分
# [:]
print(a[1:3]) # 输出:0k # 成员运算符-如果字符串中[不]包含给定的字符返回True
# in [not in]
print("k" in a) # 输出:True
print("P" not in b) # 输出:False # 原始字符串
# r/R
print(r"\n") # 输出:\n
print(R"\n") # 输出:\n
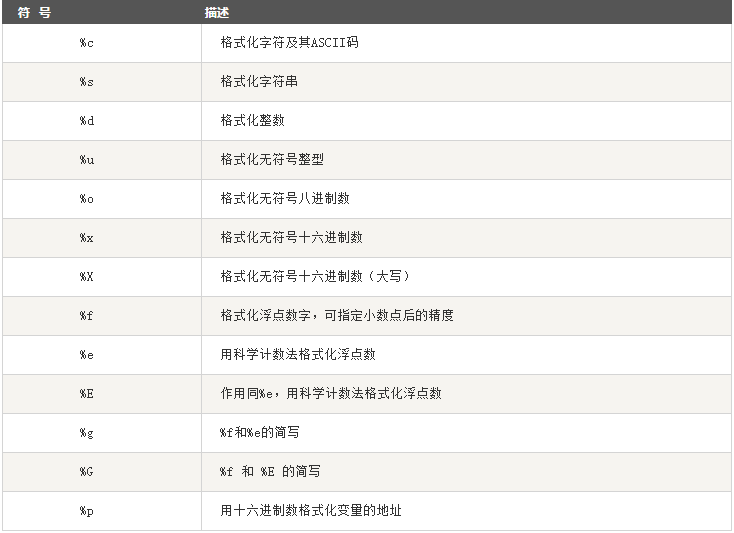
1.4 字符串格式化
Python 支持格式化字符串的输出,例如:
print("%s,%s"%("40kuai",18))
#输出 40kuai,18
python字符串格式化符号:
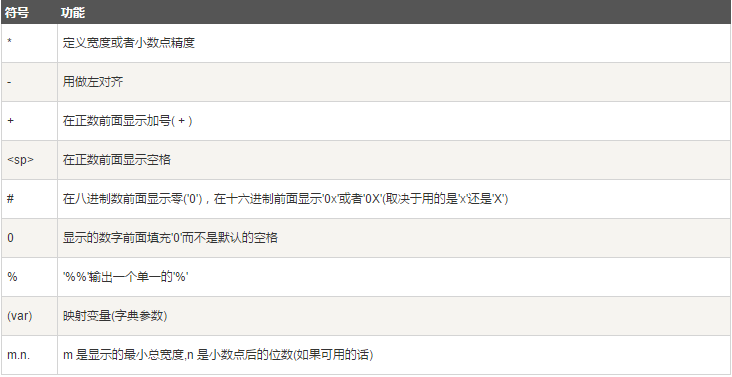
格式化操作符辅助指令:
1.5 python的字符串内建函数
抄过来了:http://www.runoob.com/python/python-strings.html
点击函数可以查看更详细的说明:
| 方法 | 描述 |
|---|---|
|
把字符串的第一个字符大写 |
|
|
返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
|
|
返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
|
|
以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除 非 errors 指 定 的 是 'ignore' 或 者'replace' |
|
|
以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
|
|
检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
|
|
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
|
|
检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
|
|
跟find()方法一样,只不过如果str不在 string中会报一个异常. |
|
|
如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
|
|
如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
|
|
如果 string 只包含十进制数字则返回 True 否则返回 False. |
|
|
如果 string 只包含数字则返回 True 否则返回 False. |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
|
|
如果 string 中只包含数字字符,则返回 True,否则返回 False |
|
|
如果 string 中只包含空格,则返回 True,否则返回 False. |
|
|
如果 string 是标题化的(见 title())则返回 True,否则返回 False |
|
|
如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
|
|
以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
|
|
返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
|
|
转换 string 中所有大写字符为小写. |
|
|
截掉 string 左边的空格 |
|
|
maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
|
|
返回字符串 str 中最大的字母。 |
|
|
返回字符串 str 中最小的字母。 |
|
|
有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
|
|
把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
|
|
类似于 find()函数,不过是从右边开始查找. |
|
|
类似于 index(),不过是从右边开始. |
|
|
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
|
|
string.rpartition(str) |
类似于 partition()函数,不过是从右边开始查找. |
|
删除 string 字符串末尾的空格. |
|
|
以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 |
|
|
按照行分隔,返回一个包含各行作为元素的列表,如果 num 指定则仅切片 num 个行. |
|
|
检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
|
|
在 string 上执行 lstrip()和 rstrip() |
|
|
翻转 string 中的大小写 |
|
|
返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
|
|
根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
|
|
转换 string 中的小写字母为大写 |
|
|
返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
|
|
isdecimal()方法检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。 |
2.列表,元组操作
2.1 列表
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
2.1.1 定义列表
创建一个列表,只要把逗号分隔的不同的数据项使用方括号括起来即可。如下所示:
与字符串的索引一样,列表索引从0开始。列表可以进行截取、组合等。
list1 = ["40kuai","shuai",18,"iti"]
list2 = [1, 2, 3, 4]
2.1.2 查询列表中的值
list1 = ["40kuai","shuai",18,"iti"]
list2 = [1, 2, 3, 4]
print(list1[1])
print(list1[1:3])
print(list2[::2]) # 输出
# shuai
# ['shuai', 18]
# [1, 3]
2.1.3 更新列表中的值
list1 = ["40kuai","shuai",18,"iti"]
list1[1] = "henshuai"
print(list1)
# 输出
# ['40kuai', 'henshuai', 18, 'iti']
2.1.4 删除列表中的值
可以使用 del 语句来删除列表的的元素,如下实例:
list1 = ["40kuai","shuai",18,"iti"]
del list1[1]
print(list1) # 输出
# ['40kuai', 18, 'iti']
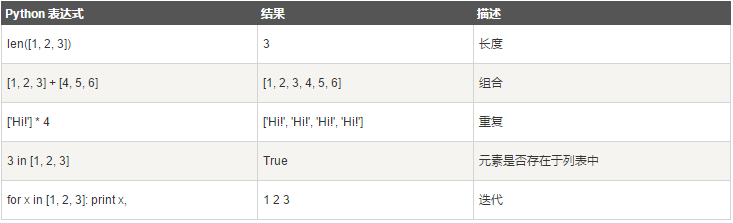
2.1.5 列表的脚本操作符
2.1.6 列表的方法
列表定义如下:
list1 = ["40kuai","shuai",18,"iti"]
list2 = [1, 2, 3, 4]
方法如下:
# -----删除列表中元素-----
list1.remove("shuai")
print(list1)
# 输出
# ['40kuai', 18, 'iti'] #-----追加元素到列表尾部-----
list1.append("666")
print(list1)
# 输出
# ['40kuai', 'shuai', 18, 'iti', '666'] #-----清空列表-----
list1.clear()
print(list1)
# 输出
# [] #-----复制list1的元素到list2中-----
list2 = list.copy(list1)
print(list1)
print(list2)
# 输出
# ['40kuai', 'shuai', 18, 'iti']
# ['40kuai', 'shuai', 18, 'iti'] #-----统计列表中某个元素的个数-----
print(list1.count("shuai"))
# 输出
# 1 #-----在列表尾部加入另一个列表的元素-----
list2 = [1,2,3,4,5]
list1.extend(list2)
print(list1)
# 输出
# ['40kuai', 'shuai', 18, 'iti', 1, 2, 3, 4, 5] #-----查找元素所在位置索引-----
print(list1.index("shuai"))
# 输出
# 1 #-----在指定位置前插入元素-----
list1.insert(1,"666")
print(list1)
# 输出
# ['40kuai', '666', 'shuai', 18, 'iti'] #-----删除指定列表中的索引元素----- 默认删除最后一个
list1.pop()
print(list1)
list1.pop(0)
print(list1)
# 输出
# ['40kuai', 'shuai', 18]
# ['shuai', 18] #-----排序-----
#list.sort()
#list.remove()
# 下次补全。
2.2 元组
2.2.1 元组特性
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
如下实例:
list1 = ("40kuai","shuai",18,"iti")
元组的使用方法只有两个,分别是count()和index,自己去试试吧。
3 字典操作
3.1 字典的定义
字典是另一种可变容器模型,且可存储任意类型对象,每一个key,对应一个value。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
dic = {'name': '40kuai', 'age': '18'}
# 四种定义字典的方法
dic = dict() # 空字典
dic = dict(name='40kuai', age=18)
dic = dict({'name':'40kuai', 'age':18})
dic = dict((('name', '40kuai'), ('age', 18)))
key的定义规则:
1.key必须唯一
2.key的类型必须为不可变,例如 字符串,数字或元组
3.2 字典的特性
1.无序性
2.天生去重(因为key唯一)
3.查询效率高
3.3 字典的使用
增加
dic = {'name': '40kuai', 'age': 18}
dic["gfs"] = "xiaoxiao"
print(dic)
# 输入
# {'gfs': 'xiaoxiao', 'age': 18, 'name': '40kuai'}
查询
dic = {'name': '40kuai', 'age': '18'}
print(dic['name'])
print(dic['name1'])
# 输出
# 正常输出为kye所对应的value值
# 40kuai
# 如果字典中没有相应的key则会返回报错
# print(dic['name1'])
# KeyError: 'name1'
修改
dic = {'name': '40kuai', 'age': 18}
dic["name"] = "alex"
dic["age"] = 19
print(dic)
# 输出
# {'age': 19, 'name': 'alex'}
删除
dic = {'name': '40kuai', 'age': 18}
# 删除字典一对数据
del dic["name"]
print(dic)
# 输出
# {'age': 18}
# 删除字典
del dic
print(dic)
循环dict
name= {1101:"40kuai",1102:"xiaojiuzi",1103:"xiaojiuzhi"}
for key in name: # 效率高
print(key,name[key])
# 输出
# 1101 40kuai
# 1102 xiaojiuzi
# 1103 xiaojiuzhi
# items会先把dict转化为list,数据大时会影响效率
for k,v in name.items(): # 效率低
print(k,v)
# 输出
# 1101 40kuai
# 1102 xiaojiuzi
# 1103 xiaojiuzhi
3.4 字典的其他方法
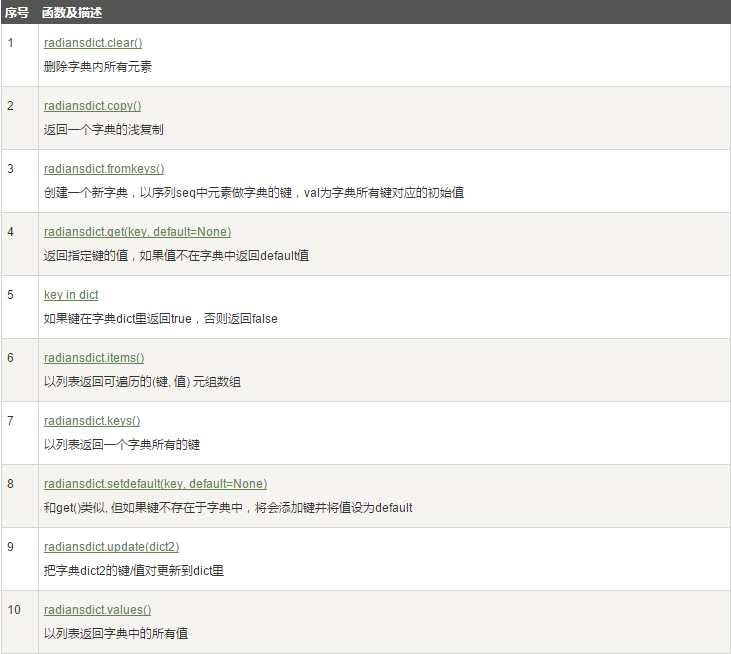
抄的,详细的可以去这里找:http://www.runoob.com/python3/python3-dictionary.html
但是每个还是试一试吧:
4.集合操作
4.1 集合定义
定义:由不同元素组成的集合,集合中是一组无序排列的可hash值,可以作为字典的key
特性:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
4.2 集合的关系运算
python中的关系运算表
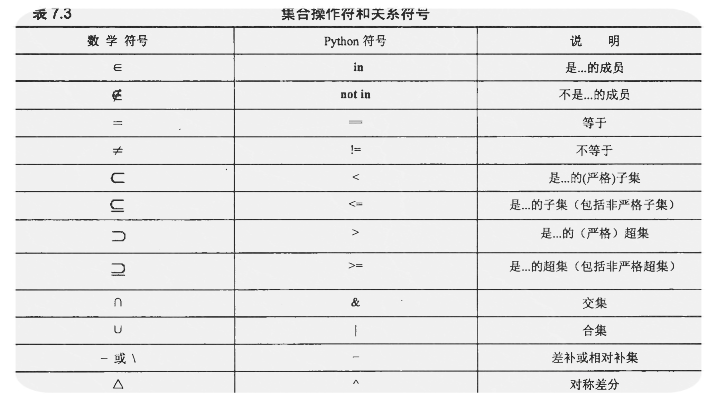
# 交集 &
python = {1,2,3,4,5,6,7,8,"b"}
linux = {2,3,4,5,6,7,8,9,0,10,"a","b"}
print(python.intersection(linux))
print(python & linux)
# 并集 |
print(python|linux)
print(python.union(linux))
# 差集 -
print(python-linux)
print(linux-python)
print(python.difference(linux))
# 对称差集 ^
s1 = {1,2,3,4,5}
s2 = {2,3}
print(s1^s2)
print(s1.symmetric_difference(s2)) # 子集
print(s1<=s2) # False
print(s1.issubset(s2)) # 相当于print(s1<=s2)
# 父集
print(s1>=s2) #Ture
print(s1.issuperset(s2)) # 相当于print(s1>=s2)
4.3 集合方法
s1 = {1,2,3}
# 更新 把元素分开加入集合
# 通常是两个集合之间的操作使用update
s1.update('e')
print(s1)
s2={'e','d','s'}
s1.update(s2)
print(s1)
s1.update("40kuai")
print(s1)
# 增加
s1.add("40kuai")
print(s1)
# 随机删除删除
s1.pop()
# 指定删除
s1.remove('e') # 没有会报错
print(s1)
s1.discard('w')
print(s1.discard('w')) # 没有返回None
# 计算完差集再赋值给s1
s1 = {1,2,3}
s2 = {4,5,6,3}
s1.difference_update(s2) # s1 = s1 - s2
s1.intersection_update(s2) # s1 = s1 + s2
# 清空集合
s1.clear()
print(s1)
# copy集合
s3 = s1.copy()
print(s3)
5.文件操作
5.1 文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
理想三旬
词:唐映枫 曲:陈鸿宇
雨后有车驶来
驶过暮色苍白
旧铁皮往南开 恋人已不在
收听浓烟下的
诗歌电台
不动情的咳嗽 至少看起来
归途也还可爱
琴弦少了姿态
再不见那夜里
听歌的小孩
时光匆匆独白
将颠沛磨成卡带
已枯卷的情怀
踏碎成年代
就老去吧 孤独别醒来
你渴望的离开
只是无处停摆
就歌唱吧 眼睛眯起来
而热泪的崩坏
只是没抵达的存在
青春又醉倒在
籍籍无名的怀
靠嬉笑来虚度
聚散得慷慨
辗转却去不到
对的站台
如果漂泊是成长
必经的路牌
你迷醒岁月中
那贫瘠的未来
像遗憾季节里
未结果的爱
弄脏了每一页诗
吻最疼痛的告白
而风声吹到这
已不需要释怀
就老去吧 孤独别醒来
你渴望的离开
只是无处停摆
就歌唱吧 眼睛眯起来
而热泪的崩坏
只是没抵达的存在
就甜蜜地忍耐
繁星润湿窗台
光影跳动着像在
困倦里说爱
再无谓的感慨
以为明白
梦倒塌的地方
今已爬满青苔
实例文件
文件打开的流程示范:
#因为windows默认的编码方式是gbk,所以文件的打开默认使用系统默认的编码方式,windows的默认编码方式是gbk,
如果报错的文件编码方式是‘utf-8’,则需要在文件打开时指定编码方式。
f = open('python_file',encoding='utf-8')
first_line = f.readline() #一次只读一行
print(first_line.strip())
print("万恶的分割线!".center(50,'-'))
date = f.read() # 读取剩下所有内容,文件过大时不要使用
print(date)
f.close() #使用文件记得关闭文件
# 输出的一部分
# 理想三旬
# ---------------------万恶的分割线!----------------------
# 词:唐映枫 曲:陈鸿宇
# 雨后有车驶来
# 驶过暮色苍白
# 旧铁皮往南开 恋人已不在
5.2 文件的打开模式
r:只读模式
w:只读模式
a:只能追加 ### +
r+ :追加+读,可以实现定长修改
w+ :清空源文件内容,再写入新内容
a+ :追加+读 ### U \r \n \r\n自动转化成\n
rU
r+U ### b 表示处理二进制文件
rb : 以二进制模式打开文件,不能声明encoding
wb :以二进制写入文件,必须写入bytes格式
5.3 文件操作的其他方法
因为把多个方法用一个文件做的例子,会有坑,要小心。
f = open('python_file','r+')
# 读取文件一行
print("分割线来了".center(50,'-'))
# 一次读取整个文件或者剩下没读的所有
print(f.read())
# 返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。
print(f.fileno())
# 刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。
f.flush()
# 如果文件连接到一个终端设备返回 True,否则返回 False。
print(f.isatty())
# 返回文件是否打开 [如果错误程序不向下执行]------>括号内为作者自己编的
print(f.readable())
# 读取文件全部或未读的剩余全部,把读取到的加入到列表并返回
print(f.readlines())
# 设置文件当前位置
f.seek(0,0)
# fileObject.seek(offset[, whence])
# offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
# whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
# 如果流支持随机访问返回True
print(f.seekable())
# 返回当前流位置
print(f.tell())
# 截断文件大小字节。
f.truncate(100)
# 将字符串写入文件,没有返回值。
f.seek(0,0)
f.write("我是倒数第三个方法")
# 判断文件是否可写 [哈哈哈]
f.writable()
# writelines() 方法用于向文件中写入一序列的字符串。
# 这一序列字符串可以是由迭代对象产生的,如一个字符串列表。
# 换行需要制定换行符 \n。
f.writelines()
f.close() #关闭文件,关闭后不能再进行读写操作。
5.4 with
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r') as f:
...
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
在Python 2.7 后,with又支持同时对多个文件的上下文进行管理,即:
with open('log1') as obj1, open('log2') as obj2:
pass
5.5 文件编码
python3 中在使用open打开文件是可以在open函数中使用encoding="utf-8",来指定打开文件的文件编码格式。
Python2 中open方法不可以指定encoding参数,可以对内容进行decode(),encode()转换后写入文件,或者使用codecs模块来指定一个编码打开文件:
import codecs
f = codecs.open('test.txt', encoding='UTF-8')
6.其他
6.1 输入的字符串变为字典
date = input(">>:") # 输入 >>:{'name':'40kuai','age':18}
a = eval(date)
print(a['name'])
eval的详细介绍给你的地址自己看吧。http://www.cnblogs.com/liu-shuai/p/6098246.html
6.2 三元运算
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# a = 2
# b = 3
# if a > b:
# c = a+b
# else:
# c=a-b # 三元运算
a=4
b=3
c=a+b if a>b else a-b
print(c)
未完待续。。想不起来了。以后想起来就补。。。
Python【第二课】 字符串,列表,字典,集合,文件操作的更多相关文章
- Learn day3 深浅拷贝/格式化/字符串/列表/字典/集合/文件操作
1. pass break continue # ### pass break continue # (1) pass 过 """如果代码块当中,什么也不写,用pass来 ...
- python中用json存储列表字典等文件操作
JSON字符串用json.dumps, json.loads JSON文件名用json.dump, json.load 由于需要在脚本重启后依旧能够记住之前所使用的列表内容, 故采用json存储列表文 ...
- python3笔记十八:python列表元组字典集合文件操作
一:学习内容 列表元组字典集合文件操作 二:列表元组字典集合文件操作 代码: import pickle #数据持久性模块 #封装的方法def OptionData(data,path): # ...
- 简学Python第二章__巧学数据结构文件操作
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- Python基础2 列表 元祖 字符串 字典 集合 文件操作 -DAY2
本节内容 列表.元组操作 字符串操作 字典操作 集合操作 文件操作 字符编码与转码 1. 列表.元组操作 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 定义列表 ...
- int bool 字符串 列表 字典 集合
1.int和bool 输出i的最大二进制位数inti = 1000 print(i.bit_length()) 2. str int bool list set dict tuple 相互转换 pr ...
- python中的字符串 列表 字典
字符串 一个有序的字符集合 不可变 1,可以使用for in语句进行迭代循环,返回元素 2,in类是于str.find()方法但是是返回布尔结果 str.find()返回 ...
- python之字符串,列表,字典,元组,集合内置方法总结
目录 数字类型的内置方法 整型/浮点型 字符串类型的内置方法 列表的内置方法 字典的内置方法 元组的内置方法 集合类型内置方法 布尔类型 数据类型总结 数字类型的内置方法 整型/浮点型 加 + 减 - ...
- python :列表 字典 集合 类 ----局部变量可以改全局变量
#列表 字典 集合 类 ----局部变量可以改全局变量,除了整数和字符串 names=["alex","jack","luck"] def ...
- 初识python 字符串 列表 字典相关操作
python基础(一): 运算符: 算术运算: 除了基本的+ - * / 以外,还需要知道 : // 为取整除 返回的市商的整数部分 例如: 9 // 2 ---> 4 , 9.0 // ...
随机推荐
- Something about SeekingJob---Resume简历
这几天脑子里满满的装的都是offer.offer.offer快到碗里来,但是offer始终不是巧克力,并没那么甜美可口易消化. 找工作刚开始,就遇到了不小的阻力,看到Boss直聘上各种与IT相关的工作 ...
- nyoj 概率计算
概率计算 时间限制:1000 ms | 内存限制:65535 KB 难度:1 描述 A和B两个人参加一场答题比赛.比赛的过程大概是A和B两个人轮流答题,A先答.一旦某人没有正确回答问题,则对手 ...
- 通过URL传递PDF名称参数显示PDF
1 <%@ page language="java" import="java.util.*,java.io.*" 2 pageEncoding=&quo ...
- GitHub 上下载单个文件夹
写代码的一定经常去github上查看.下载一些源码,有时候会想下载一个项目中的一个文件夹里的内容,但是github上只提供了整个项目的下载,而整个项目里东西太多,压缩的文件太大,github的下载速度 ...
- kubernetes进阶(02)kubernetes的node
一.Node概念 Node是Pod真正运行的主机,可以物理机,也可以是虚拟机. 为了管理Pod,每个Node节点上至少要运行container runtime(比如docker或者rkt). kube ...
- Web 项目报错No suitable driver found for jdbc:mysql://localhost:3306/book 的一个解决办法
确认jar包加入到了build path中,然后注意版本是否与数据库相配,还要留意将jar包放入WEB-INF下的lib文件夹中
- JVM 掌握要点
重读JVM jvm系列:jvm知识点总览 1. 认识Java虚拟机 默认Hotspot实现 2. 类加载机制 知道双亲委派模型 编译为class javac → 装载 class ClassLoade ...
- 初识 SpringMVC
1.Spring MVC 的工作流程 1.web请求被 前端控制器(DispatcherServlet)拦截 2.DispatcherServlet调用 映射处理器(HandelerMapping)查 ...
- POJ-1556 The Doors---线段相交+最短路
题目链接: https://vjudge.net/problem/POJ-1556 题目大意: 给一个10*10的正方形房间中间用墙隔开每个墙上有两个门,给出门的两个端点坐标求从左边中点走到右边中点所 ...
- POJ-1125 Stockbroker Grapevine---Floyd应用
题目链接: https://vjudge.net/problem/POJ-1125 题目大意: 股票经纪人要在一群人中散布一个谣言,而谣言只能在亲密的人中传递,题目各处了人与人之间的关系及传递谣言所用 ...