scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)
上篇已经对数据进行了清洗,本篇对反爬虫做一些应对措施,主要包括随机UserAgent、随机代理。
一、随机UA
分析:构建随机UA可以采用以下两种方法
- 我们可以选择很多UserAgent,形成一个列表,使用的时候通过middleware获取到settings.py文件中的配置,然后进行随机选择
- 使用第三方库fake-useragent,这个库可以方便的生成一个随机UA,使用起来也很方便
本篇我们使用第二种方式来构建随机UA
安装第三方库fake_useragent,使用命令pip install fake-useragent

生成ua的方式很简单
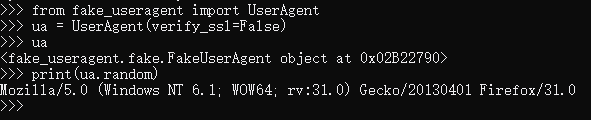
from fake_useragent import UserAgent ua = UserAgent(verify_ssl=False) #正常不需要这个参数,如果无法获取请添加这个参数
print(ua.random)
下面开始项目代码的编写
在middlewares.py文件中,我们对scrapy默认的UserAgentMiddleware进行改写
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware #导入默认的UA中间件的类
from fake_useragent import UserAgent
class LagouUserAgentMiddleware(UserAgentMiddleware): #新建一个拉钩网的UA中间件类继承自默认的类
def process_request(self, request, spider):
request.headers.setdefault(b'User-Agent', UserAgent(verify_ssl=False).random) #设置一个随机的UA
print('当前ua %s' % request.headers['User-Agent']) #打印出来看一下
把我们在lagou_c.py文件中custom_settings中的UA注释掉
这样UA就设置好了,还需要到settings.py文件中把它激活
DOWNLOADER_MIDDLEWARES = {
#'lagou.middlewares.LagouDownloaderMiddleware': 543, #有注释,是未激活的中间件
'lagou.middlewares.LagouUserAgentMiddleware': 333, #优先级是333,自己随便设置,数字越小代表优先级越高
}
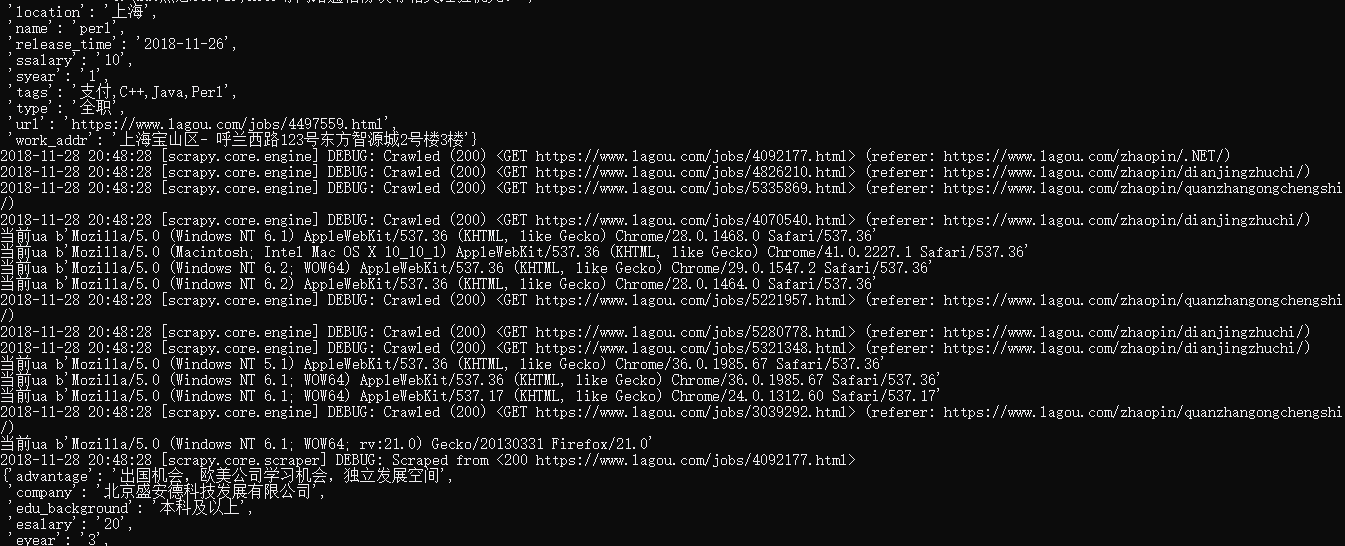
我们运行一下爬虫,看下结果,可以看到UA在随机的更换
二、随机代理
分析:构建随机代理可以采用以下两种方法
- 我们可以选择很多proxy,形成一个列表,使用的时候通过middleware获取到settings.py文件中的配置,然后进行随机选择
- 构建一个随机代理池,通过middleware对随机代理进行设置
这里我们采用第二种方式,网上有别人构建的代理池,我就直接拿来用了,毕竟重复造轮子的时间,你可以用来做很多其他事情了。
我这里使用的是阿里云ECS服务器Centos 7,本地windows操作一样
首先使用git命令下载仓库(没有git的去下载一个,这个必学,可以简单理解为git本地仓库,github远程仓库,本地的可以上传,远程的可以下载)
git clone https://github.com/Python3WebSpider/ProxyPool.git
- 进入到PrxxyPool文件夹,然后再进入proxypool文件夹

- 编辑里面的setting.py文件,修改TEST_URL = 'http://www.lagou.com',这么做的目的就是让这些代理去请求拉勾网,如果成功就说明这个代理有效

- 我们接下来把这个代理池运行起来,在run.py文件目录下,运行run.py程序

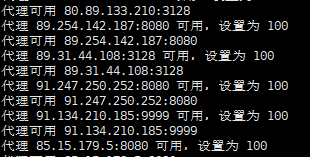
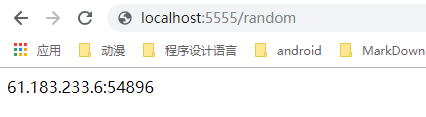
- 可以看到代理自动获取并且在测试可用性,我们可以打开浏览器,看下获取一个随机代理,如果是远程服务器,地址为ip:5555/random (ip为远程服务器ip),如果是阿里云服务器需要设置安全组,放开5555端口。
现在开始编写我们的爬虫代码
在middlewares.py文件,新增一个LagouProxyMiddleware类
import requests
from requests.exceptions import ConnectionError class LagouProxyMiddleware(object):
def __init__(self,proxy_url):
self.proxy_url = proxy_url def get_random_proxy(self):
’‘’
使用requests获取代理
‘’‘
try:
response = requests.get(self.proxy_url)
if response.status_code == 200:
random_proxy = response.text
return random_proxy
except ConnectionError:
return False def process_request(self, request, spider):
if request.meta.get('retry_times'): #如果重试次数为0,就使用默认的ip地址进行页面爬取,否则使用代理
random_proxy = self.get_random_proxy()
if random_proxy:
uri = 'https://{}'.format(random_proxy)
print('当前代理为{}'.format(request.meta['proxy']))
request.meta['proxy'] = uri #设置随机代理 @classmethod
def from_crawler(cls,crawler):
’‘’
类函数,使用crawler来获取settings中的PROXY_URL,也就是生成随机代理的url
‘’‘
settings = crawler.settings
return cls(
proxy_url=settings.get('PROXY_URL')
)
在settings.py中激活这个中间件,并且定义PROXY_URL
DOWNLOADER_MIDDLEWARES = {
#'lagou.middlewares.LagouDownloaderMiddleware': 543,
'lagou.middlewares.LagouUserAgentMiddleware': 333,
'lagou.middlewares.LagouProxyMiddleware': 444,
}
PROXY_URL = 'http://localhost:5555/random' #哪台设备运行的代理池,就把localhost修改为那台设备的ip,本机不用修改
至此我们就完成了随机UA和随机代理的设置,老规矩,运行下爬虫。当然,因为本地ip没有被封,所以一直就会使用本地ip,不会使用代理ip,毕竟免费的代理慢。

scrapy抓取拉勾网职位信息(六)——反爬应对(随机UA,随机代理)的更多相关文章
- scrapy抓取拉勾网职位信息(一)——scrapy初识及lagou爬虫项目建立
本次以scrapy抓取拉勾网职位信息作为scrapy学习的一个实战演练 python版本:3.7.1 框架:scrapy(pip直接安装可能会报错,如果是vc++环境不满足,建议直接安装一个visua ...
- scrapy抓取拉勾网职位信息(三)——爬虫rules内容编写
在上篇中,分析了拉勾网需要跟进的页面url,本篇开始进行代码编写. 在编写代码前,需要对scrapy的数据流走向有一个大致的认识,如果不是很清楚的话建议先看下:scrapy数据流 本篇目标:让拉勾网爬 ...
- scrapy抓取拉勾网职位信息(二)——拉勾网页面分析
网站结构分析: 四个大标签:首页.公司.校园.言职 我们最终是要得到详情页的信息,但是从首页的很多链接都能进入到一个详情页,我们需要对这些标签一个个分析,分析出哪些链接我们需要跟进. 首先是四个大标签 ...
- scrapy抓取拉勾网职位信息(七)——数据存储(MongoDB,Mysql,本地CSV)
上一篇完成了随机UA和随机代理的设置,让爬虫能更稳定的运行,本篇将爬取好的数据进行存储,包括本地文件,关系型数据库(以Mysql为例),非关系型数据库(以MongoDB为例). 实际上我们在编写爬虫r ...
- scrapy抓取拉勾网职位信息(四)——对字段进行提取
上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来 这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:sc ...
- scrapy抓取拉勾网职位信息(七)——实现分布式
上篇我们实现了数据的存储,包括把数据存储到MongoDB,Mysql以及本地文件,本篇说下分布式. 我们目前实现的是一个单机爬虫,也就是只在一个机器上运行,想象一下,如果同时有多台机器同时运行这个爬虫 ...
- scrapy抓取拉勾网职位信息(八)——使用scrapyd对爬虫进行部署
上篇我们实现了分布式爬取,本篇来说下爬虫的部署. 分析:我们上节实现的分布式爬虫,需要把爬虫打包,上传到每个远程主机,然后解压后执行爬虫程序.这样做运行爬虫也可以,只不过如果以后爬虫有修改,需要重新修 ...
- scrapy抓取拉勾网职位信息(五)——代码优化
上一篇我们已经让代码跑起来,各个字段也能在控制台输出,但是以item类字典的形式写的代码过于冗长,且有些字段出现的结果不统一,比如发布日期. 而且后续要把数据存到数据库,目前的字段基本都是string ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
随机推荐
- 不平衡分类学习方法 --Imbalaced_learn
最近在进行一个产品推荐课题时,由于产品的特性导致正负样本严重失衡,远远大于3:1的比例(个人认为3:1是建模时正负样本的一个临界点),这样的样本不适合直接用来建模,例如正负样本的比例达到了50:1,就 ...
- CentOS部署.NetCore服务
1. 安装CentOs,可使用最小安装包镜像:http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-Minimal-17 ...
- jQuery 写的简单打字游戏
var off_x; //横坐标 var count=0; //总分 var speed=5000; //速度,默认是5秒. var keyErro=0; //输入错误次数 var keyRight= ...
- 【Codeforces752D】Santa Claus and a Palindrome [STL]
Santa Claus and a Palindrome Time Limit: 20 Sec Memory Limit: 512 MB Description 有k个串,串长都是n,每个串有一个a ...
- 关于Http协议、ASP.NET 核心知识(2)
简介HTTP (对于http协议的描述我前部分有写,但基于保证文档独立完整性的原则,我再写一遍.反正又不花钱.) 这货的学名叫:超文本传输协议 英文名字:(HTTP,HyperText Transfe ...
- 重载jquery on方法实现click事件在移动端的快速响应
额,这个标题取的还真是挺装的... 其实我想表达的是jquery click事件如何在移动端自动转换成touchstart事件. 因为移动端click事件会比touchstart事件慢几拍 移动设备某 ...
- 再续 virtualenv II
为什么搭建虚拟环境 搭建 Python 虚拟环境,可以方便的解决不同项目中对类库的依赖问题.当然,也可以方便地Python2,Python3 共存.避免包的混乱和版本的冲突.为每个程序单独创建虚拟环境 ...
- php之复制文件——php经典实例
php之复制文件——php经典实例 <?php function dirCopy($dir1,$dir2){ //判断是否目录存在 if(!file_exists($dir2) || !is_d ...
- PHP动态修改配置文件——php经典实例
文件结构: index.php 主页 config 配置文件 doUpdate.php 修改功能页 index.php <html> <head> <title>修 ...
- oracle查看表中数据的大小
通过从视图 user_segments的字段 bytes中找到 select SUM(bytes)/1024/1024 from user_segments where segment_name='E ...