从零开始山寨Caffe·陆:IO系统(一)
你说你学过操作系统这门课?写个无Bug的生产者和消费者模型试试!
——你真的学好了操作系统这门课嘛?
在第壹章,展示过这样图:

其中,左半部分构成了新版Caffe最恼人、最庞大的IO系统。
也是历来最不重视的一部分。
第伍章又对左半部分的独立性进行了分析,我是这么描述到:
Datum和Blob(Batch)不是上下文相关的。
Blob包含着正向传播的shape信息,这些信息只有初始化网络在初始化时才能确定。
而Datum则只是与输入样本有关。
所以,Datum的读取工作可以在网络未初始化之前就开始,这就是DataReader采用线程设计的内涵。
所以,左半部分又可以分为左左半部分,和左右半部分。
阻塞队列
生产者与消费者
第伍章讲到,在一个机器学习系统中,生产者和消费者的执行周期是不一样的。
为了平衡在周期上的差异,节约计算资源,我们显然需要对生产者做一定限制。
存储生产资源,可以用数组,也可以用STL容器。
再考虑生产者和消费者的行为:
①不存在随机访问:
显然,消费者是按照固定顺序访问缓冲区的。
我们没有必要考虑随机访问的情况。
②不存在随机写入:
显然,生产者每次只需要将资源放置于缓冲区两端。
我们没有必要考虑在线性表中间位置写入的情况。
由于vector底层由顺序表实现,其访问速度随着元素数量的递增而递减,
而queue底层由链式表实现,其访问速度不随元素数量的递增而递减,且没有随机写入/访问的情况。
所以,选择queue作为缓冲区是比较优异的。
为了限制生产者的行为,我们需要在STL提供的queue基础上,改进出一种新的数据结构——Blocking Queue。
互斥锁
第肆章简单提到了mutex问题,这是阻塞队列除了Blocking之外,需要考虑的第二大问题。
并且已经证明了:生产者和消费者之间必然是异步的。
我们以队列的push和pop操作为例,分析一下,为什么在多线程情况下,需要加mutex。
假设线程A预备执行push操作,所以它是一个生产者;
假设线程B预备执行pop操作,所以它是一个消费者;
设有临界缓冲区队列Q,在某时刻T,线程A发出push操作,在T+1时候,线程B发出pop操作,
且push需要10个单位时间,pop只需要一个单位时间,问T+2时刻,pop出去的资源你敢用嘛?
显然,没人敢用这个执行push的半成品。
发生上述问题的症结在于,两个异步线程对于同一个资源,产生了争夺行为。
解决方案就是:在push时,锁住资源,禁止pop;在pop时,锁住资源,禁止push。
广义上,我们可以认为,需要将push和pop函数变成原子函数,即:执行期间不可中断的函数。
———————————————————————————————————————————————————————————
另外,需要注意的是,mutex与blocking是两个概念。
在广义上,mutex会将多个线程对同一个资源的异步并行操作,拉成一个串行执行队列,串行等待执行。
而blocking则是将线程休眠,CPU会暂时放弃对其控制。
在程序员界,虽然有时候会把mutex和blocking都称为阻塞,但其原理和内涵是完全不同的。
———————————————————————————————————————————————————————————
boost提供不俗的mutex功能,使用前需要 #include "boost/thread/mutex.hpp"
你可以将一个boost::mutex对象嵌入到一个类当中,这样,允许每一个类对象拥有一把锁。
由于对一个queue对象,主要是锁住来自该对象的push和pop操作,
所以,mutex理应当是以类对象为一个单位的,参考代码如下:
template <typename T>
class BlockingQueue{
public:
void push(const T& t){
boost::mutex::scoped_lock lock(mutex);
Q.push(t);
}
T pop(){
boost::mutex::scoped_lock lock(mutex);
T t = Q.front();
Q.pop();
return t;
}
private:
boost::mutex mutex;
queue<T> Q;
};
boost::mutex::scoped_lock lock提供局部锁定功能。
它与boost::scoped_ptr有类似的效果,scoped_ptr在作用域结束后,就立即释放对象。
而scoped_lock在作用域结束后,会立即解锁,如果不用scoped_lock,我们可以这么写:
void push(const T& t){
mutex.lock();
Q.push(t);
mutex.unlock();
}
条件阻塞与激活
前面几章说了那么久的阻塞,其中大部分指的应该是blocking。
mutex大部分情况下,都只是在锁一个局部函数,阻塞周期非常短。
唯一的例外是Layer的正向传播函数forward,mutex锁住的周期非常长。
blocking和mutex的唯一不同在于:
blocking之后,操作系统会唆使CPU放弃对线程的处理。
这是非常危险的一个行为,因为该线程被家长赶去睡觉了,而且不能反抗家长的命令。
除非家长通知它:噢,你可以活动了。在此之前,该线程将永远处于无效状态。
上面的例子有两个重点:
①CPU放弃线程
②不可主动激活
既然如此,为了激活这个线程,模型就必须设计成“对偶模型”,而生产者和消费者,恰恰正是对偶的。
———————————————————————————————————————————————————————————
boost::condition_variable提供了简单的blocking功能,为了统一控制,可以将其与mutex捆在一起:
template <typename T>
class BlockingQueue
{
public:
class Sync{
public:
boost::mutex mutex;
boost::condition_variable condition;
};
private:
queue<T> Q;
boost::shared_ptr<Sync> sync;
};
现在考虑一下,何时需要注销、阻塞一个线程,大致有两种情况:
①缓冲区空,此时消费者不能消费,拒绝pop操作之后,可以交出CPU控制权。
②缓冲区满,此时生产者不能生产,拒绝push操作之后,可以交出CPU控制权。
为了激活彼此,就需要模型是对偶的:
①经历缓冲区空之后,突然push了一个元素,此时应当由生产者激活消费者线程。
②经历缓冲区满之后,突然pop了一个元素,此时应当由消费者激活生产者线程。
看起来,我们可以将代码写成这样:
void BlockingQueue<T>::push(const T& t){
boost::mutex::scoped_lock lock(sync->mutex);
while (Q.full()){
sync->condition.wait(lock); //suspend, spare CPU clock
}
Q.push(t);
sync->condition.notify_one();
}
template<typename T>
T BlockingQueue<T>::pop(const string& log_waiting_msg){
boost::mutex::scoped_lock lock(sync->mutex);
while (Q.empty()){
sync->condition.wait(lock); //suspend, spare CPU clock
}
T t = Q.front();
Q.pop();
sync->condition.notify_one();
return t;
}
其中,sync->condition.wait(lock)表示使用当前mutex为标记,交出CPU控制权。
sync->condition.notify_one()则表示激活一个线程的CPU控制权。
可以看到,blocking和activating的代码是完全对偶的,blocking自己,activating对方。
双阻塞队列
上节代码是不可能实现的,因为没有Q.full()这个函数。
在传统生产者、消费者程序中,通常会使用单缓冲队列。
使用单缓冲队列是没有问题的,因为在这种简单的代码结构中,我们很容易知道缓冲队列的上界。
比如,设定缓冲队列大小为20,在编程中,可以通过检测 if(count==20)来达到。
当代码结构复杂时,比如,缓冲队列大小变量通常在非常上层上层上层的位置,而处于底层的缓冲队列,
是无法探知何谓“缓冲队列满”的含义的,这就为编程带来很大的难题。
———————————————————————————————————————————————————————————
解决方案是,使用双缓冲队列组方案,我们设定两个阻塞队列,一个叫free,一个叫full。
两者组成一个QueuePair:
class QueuePair{
public:
QueuePair(const int size);
~QueuePair();
BlockingQueue<Datum*> free; // as producter queue
BlockingQueue<Datum*> full; // as consumer queue
};
为了避免检测缓冲队列的上界,我们可以先放置与上界数量等量的空元素指针到free队列。
每次生产者生产时,从free队列中pop一个空Datum元素,填充,再扔进full队列。
这样,BlockingQueue的push操作就不需要检测上界了。
原理很简单,生产者想要push,之前必须pop,pop可以通过检测缓冲队列空来实现。
这样,就用检测一个缓冲队列的空,模拟且替代了检测另一个缓冲队列的满。
对于上层代码而言,我们仅仅需要预先填充N个元素至free队列中即可,非常方便。
这部分是DataReader的设计核心。
代码实战
★数据结构
———————————————————————————————————————————————————————————
建立blocking_queue.hpp。
template <typename T>
class BlockingQueue
{
public:
BlockingQueue();
void push(const T& t);
T pop(const string& log_waiting_msg="");
T peek();
size_t size();
// try_func return false when need blocking
// try_func for destructor
bool try_pop(T* t);
bool try_peek(T* t);
class Sync{
public:
boost::mutex mutex;
boost::condition_variable condition;
};
private:
queue<T> Q;
boost::shared_ptr<Sync> sync;
};
★class BlockingQueue
除了push和pop之外,追加队列第三个常用操作——peek。
peek目的是取出队首元素,但是不从队列里pop掉。
peek用于实验性读取Datum,为DataTransfomer初始化所用。
除了通过返回值之外获取之外,我们还要准备try系列函数。
try除了获取元素外,同时返回一个bool值,表明成功或者失败。
主要用于对Datum的析构,这也是所有代码里,唯一一处对protobuff数值的析构。
★实现
———————————————————————————————————————————————————————————
建立blocking_queue.cpp。
整体代码没有什么好说的,细节以及在上文讲解了。
template<typename T>
BlockingQueue<T>::BlockingQueue() :sync(new Sync()) {} template<typename T>
void BlockingQueue<T>::push(const T& t){ // function_local mutex and unlock automaticly
// cause another thread could call pop externally
// when this thread is calling push pop&peer at the same time boost::mutex::scoped_lock lock(sync->mutex);
Q.push(t); // must wake one opposite operation avoid deadlock
// formula: wait_kind_num = notify_kind_num
// referring Producter-Consumer Model and it's semaphore setup method
sync->condition.notify_one();
} template<typename T>
T BlockingQueue<T>::pop(const string& log_waiting_msg){
boost::mutex::scoped_lock lock(sync->mutex);
while (Q.empty()){
if (!log_waiting_msg.empty()){ LOG_EVERY_N(INFO, ) << log_waiting_msg; }
sync->condition.wait(lock); //suspend, spare CPU clock
}
T t = Q.front();
Q.pop();
return t;
} template<typename T>
T BlockingQueue<T>::peek(){
boost::mutex::scoped_lock lock(sync->mutex);
while (Q.empty())
sync->condition.wait(lock);
T t = Q.front();
return t;
} template<typename T>
bool BlockingQueue<T>::try_pop(T* t){
boost::mutex::scoped_lock lock(sync->mutex);
if (Q.empty()) return false;
*t = Q.front();
Q.pop();
return true;
} template<typename T>
bool BlockingQueue<T>::try_peek(T* t){
boost::mutex::scoped_lock lock(sync->mutex);
if (Q.empty()) return false;
*t = Q.front();
return true;
} template<typename T>
size_t BlockingQueue<T>::size(){
boost::mutex::scoped_lock lock(sync->mutex);
return Q.size();
}
实现
模板实例化
在第壹章,我们提到了INSTANTIATE_CLASS(classname)宏的作用。
本段将重点解释,出现在blocking_queue.cpp最后的实例化代码。
模板机制与编译空间
template<typename T>可以说是整个Caffe里出现频率最高的代码了。
C++编译器有个好玩的特性,就是对于在cpp文件里出现的模板定义代码,
只检查最基本的语法错误,比如标点符号之类的。甚至你把变量名拼错了,编译仍然能通过。
所以,我在最初山寨Caffe的时候,写了一堆错误的代码,编译器都没告诉我。
后来在医院体检时,偶然转了几圈,大概猜到了编译器应该是为模板代码开了独立的编译检查空间。
为了便于理解,参考图如下:
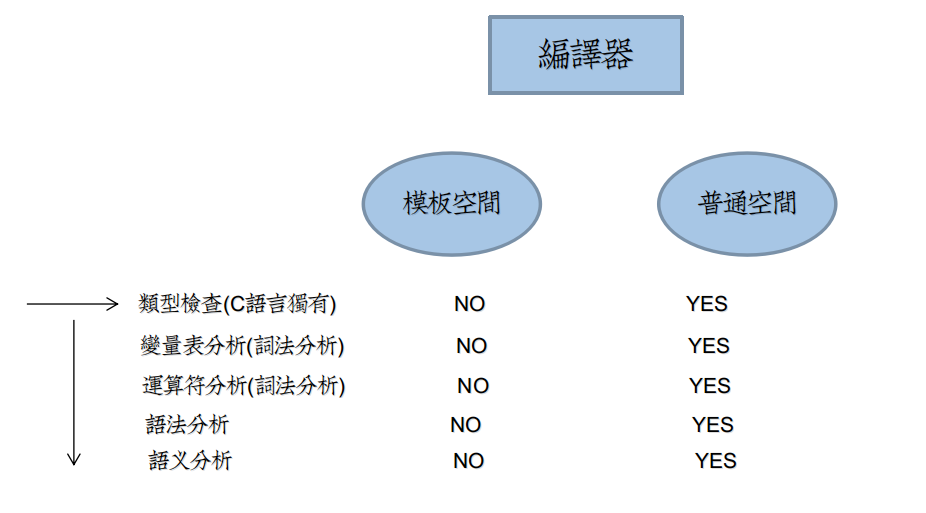
由于C/C++是强类型检查语言,类型检查处于编译先锋位置。
而未确定类型的模板定义代码,将不会进行大部分词法分析、语法分析、语义分析。
头文件与源文件
奇怪的是,如果你将模板定义代码写在头文件里,那么它就会被上升到普通编译空间。
原理大致如下:
编译器不会对未include的头文件进行最终编译。
这意味着,如果你要使用一个模板类型,比如A<int> a;
必然处于include下,此时必然是指定类型的,编译器就不必将代码push到模板空间。
或者,存在一种转移,编译器将定义代码由模板空间转到普通空间,进行下一步分析。
然而,如果我们将模板定义代码写在源文件A.cpp里,然后在B.cpp里,使用A<int> a,
此时编译器应该去哪里找模板类A的定义代码?按照编译链追溯,应该是到A.hpp里,
再由A.hpp,找到A.cpp。
这种思路在模板定义于A.cpp是不可能实现的,如图所示:
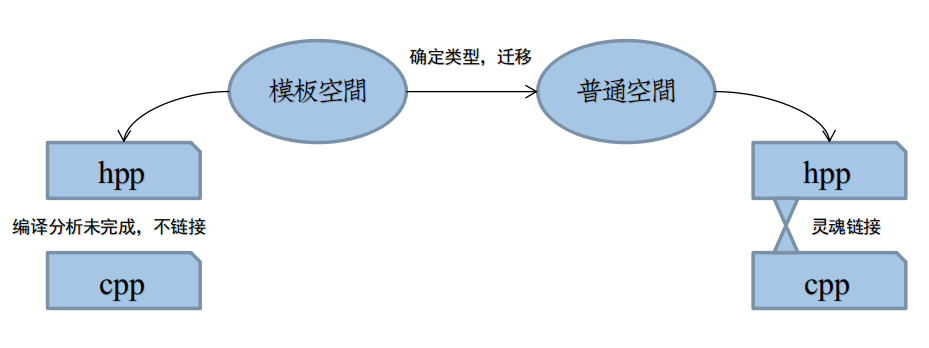
这是两种空间本质区别,由于模板空间的分析没有结束,C++不会让你由hpp找到cpp中的定义代码的。
实例化
为了能让编译A.cpp时,从模板空间迁移到普通空间,我们必须为其提供明确的类型。
比如在blocking_queue.cpp的结尾,你应该添加以下代码:
template class BlockingQueue<Batch<float>*>;
template class BlockingQueue<Batch<double>*>;
template class BlockingQueue < Datum* > ;
template class BlockingQueue < boost::shared_ptr<QueuePair> > ;
这四行代码枚举了BlockingQueue中可能出现的所有具体类型,此时编译器才会对A.cpp进行完整的编译。
在common.hpp中的实例化宏则要简单的多,
#define INSTANTIATE_CLASS(classname) \
template class classname<float>; \
template class classname<double>
该宏用于Blob、Layer、Net和Solver四大数据结构,因为它们的类型,除了float,就是double。
特殊化
模板机制中存在模板特殊化的概念,它在功能上等效于实例化。
模板特殊化在math_functions.cpp中将会大量存在。
比如此函数:
template<>
void dragon_cpu_gemm<double>(const CBLAS_TRANSPOSE transA, const CBLAS_TRANSPOSE transB,
const int M, const int N, const int K, const double alpha, const double* A, const double* B,
const double beta, double *C){
int lda = (transA == CblasNoTrans) ? K : M;
int ldb = (transB == CblasNoTrans) ? N : K;
cblas_dgemm(CblasRowMajor, transA, transB, M, N, K, alpha, A, lda, B, ldb, beta, C, N);
}
注意实例化与特殊化template附近的区别,特殊化需要添加<>。
模板特殊化必须要明确给出指定类型的代码,而实例化则不必给出。
模板实例化本质是模板特殊化的特例,条件是:所有类型,执行相同的代码。
而这份相同的代码,以下述形式给出:
template<typename T>
XXX<T>::Y(){
......
......
}
你可以将实例化视为声明,特殊化视为定义。
两者给出其一,就能让编译器完整编译分离的模板定义代码,前提是,必须写在cpp文件中。
CUDA与NVCC编译器
NVCC编译cu文件时,会无视A.cpp里的任何实例化、特殊化代码。
Caffe中给出的解决方案是,追加对cu文件中函数的特别实例化。
由以下几个宏实现:
#define INSTANTIATE_LAYER_GPU_FORWARD(classname) \
template void classname<float>::forward_gpu( \
const vector<Blob<float>*>& bottom, \
const vector<Blob<float>*>& top); \
template void classname<double>::forward_gpu( \
const vector<Blob<double>*>& bottom, \
const vector<Blob<double>*>& top); #define INSTANTIATE_LAYER_GPU_BACKWARD(classname) \
template void classname<float>::backward_gpu( \
const vector<Blob<float>*>& top, \
const vector<bool> &data_need_bp, \
const vector<Blob<float>*>& bottom); \
template void classname<double>::backward_gpu( \
const vector<Blob<double>*>& top, \
const vector<bool> &data_need_bp, \
const vector<Blob<double>*>& bottom) #define INSTANTIATE_LAYER_GPU_FUNCS(classname) \
INSTANTIATE_LAYER_GPU_FORWARD(classname); \
INSTANTIATE_LAYER_GPU_BACKWARD(classname)
更多参考
见CSDN板块的讨论:http://bbs.csdn.net/topics/380250382
完整代码
blocking_queue.hpp
https://github.com/neopenx/Dragon/blob/master/Dragon/include/blocking_queue.hpp
blocking_queue.cpp
https://github.com/neopenx/Dragon/blob/master/Dragon/src/blocking_queue.cpp
从零开始山寨Caffe·陆:IO系统(一)的更多相关文章
- 从零开始山寨Caffe·拾贰:IO系统(四)
消费者 回忆:生产者提供产品的接口 在第捌章,IO系统(二)中,生产者DataReader提供了外部消费接口: class DataReader { public: ......... Blockin ...
- 从零开始山寨Caffe·零:必先利其器
工作环境 巧妇有了米炊 众所周知,Caffe是在Linux下写的,所以长久以来,大家都认为跑Caffe,先装Linux. niuzhiheng大神发起了caffe-windows项目(解决了一些编译. ...
- 从零开始山寨Caffe·拾:IO系统(三)
数据变形 IO(二)中,我们已经将原始数据缓冲至Datum,Datum又存入了生产者缓冲区,不过,这离消费,还早得很呢. 在消费(使用)之前,最重要的一步,就是数据变形. ImageNet Image ...
- 从零开始山寨Caffe·捌:IO系统(二)
生产者 双缓冲组与信号量机制 在第陆章中提到了,如何模拟,以及取代根本不存的Q.full()函数. 其本质是:除了为生产者提供一个成品缓冲队列,还提供一个零件缓冲队列. 当我们从外部给定了固定容量的零 ...
- 从零开始山寨Caffe·肆:线程系统
不精通多线程优化的程序员,不是好程序员,连码农都不是. ——并行计算时代掌握多线程的重要性 线程与操作系统 用户线程与内核线程 广义上线程分为用户线程和内核线程. 前者已经绝迹,它一般只存在于早期不支 ...
- 从零开始山寨Caffe·玖:BlobFlow
听说Google出了TensorFlow,那么Caffe应该叫什么? ——BlobFlow 神经网络时代的传播数据结构 我的代码 我最早手写神经网络的时候,Flow结构是这样的: struct Dat ...
- 从零开始山寨Caffe·柒:KV数据库
你说你会关系数据库?你说你会Hadoop? 忘掉它们吧,我们既不需要网络支持,也不需要复杂关系模式,只要读写够快就行. ——论数据存储的本质 浅析数据库技术 内存数据库——STL的map容器 关 ...
- 从零开始山寨Caffe·壹:仰望星空与脚踏实地
请以“仰望星空与脚踏实地”作为题目,写一篇不少于800字的文章.除诗歌外,文体不限. ——2010·北京卷 仰望星空 规范性 Caffe诞生于12年末,如果偏要形容一下这个框架,可以用"须敬 ...
- 从零开始山寨Caffe·伍:Protocol Buffer简易指南
你为Class外访问private对象而苦恼嘛?你为设计序列化格式而头疼嘛? ——欢迎体验Google Protocol Buffer 面向对象之封装性 历史遗留问题 面向对象中最矛盾的一个特性,就是 ...
随机推荐
- linux vi(vim)常用命令汇总
1 查找 /xxx(?xxx) 表示在整篇文档中搜索匹配xxx的字符串, / 表示向下查找, ? 表示向上查找其中xxx可以是正规表达式,关于正规式就不多说了. 一般来说是区分大小写的, 要想不区分大 ...
- 使用node初始化项目
初始化项目 在建项目的时候经常会建很多文件夹和文件,今天使用node初始化项目自动生成这些内容. 执行步骤 执行命令 node init 初始化项目生成package.json 设置配置文件 var ...
- 鼠标上下滑动总是放大缩小页面,按住ctrl+0
鼠标上下滑动总是放大缩小页面,可能是ctrl键失灵了,幸好键盘有两个ctrl键,按住ctrl+0,页面就正常了,吓死宝宝了,~~~~(>_<)~~~~
- Xcode 属性面板添加自定义控件属性
让自定义控件像原生控件一样可以在属性面板配置参数,Apple文档传送 直接上效果图,根据
- PEAR安装
看到PEAR章节,提到安装PEAR需要go-pear.bat,我机器上的PHP(v7.0.8)目录下,并没有go-pear.bat这个文件,网上查了一遍,怎么说的都有,最后还是在官网上找到解决方案. ...
- git bash操作
1. GIT说明 1> git是分布式,或者说是去中心化的.表现为: 开发者的可以在本地使用git并完美的控制自己的版本,而无需与服务端交互: 开发者可以将本地库在某个服务端备份,这种情况类似S ...
- centos6.5安装elasticsearch
java下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.htmles下载地址 : ...
- 卡拉OK效果的实现-iOS音乐播放器
自己编写的音乐播放器偶然用到这个模块,发现没有思路,而且上网搜了搜,关于这方面的文章不是很多,没找到满意的结果,然后自己也是想了想,最终实现了这种效果,想通了发现其实很简单. 直接上原理: 第一种: ...
- Java研发岗位面试归类A(附答案)
题目来自http://www.codeceo.com/article/201-java-interview-qa.html,答案自己网上找的,如有疏漏,欢迎斧正.一起学习,共同进步. 一.Java基础 ...
- C++ 系列:socket 资料收集
Copyright © 1900-2016, NORYES, All Rights Reserved. http://www.cnblogs.com/noryes/ 欢迎转载,请保留此版权声明. -- ...