大端模式、小端模式和C#反转
A、C#大端模式和小端模式。
小端(little-endian)模式:低地址上存放低字节,高地址上存放高字节。
如0x11223344→ byte[] numBytes = new byte[]{ 0x44,0x33,0x22,0x11};
numBytes[0] = 0x44; //低地址存放低字节
numBytes[3] = 0x11; //高地址存放高字节
反之,高字节在前,低字节在后,则为大端模式。
反转示例:
short num = 12;
byte[] bytes = BitConverter.GetBytes(s);
Array.Reverse(bytes); //bytes转换为倒序(反转),可实现大端小端的转换
B、大端模式和小端模式。原文地址:https://blog.csdn.net/qqliyunpeng/article/details/68484497
作者: 李云鹏(qqliyunpeng@sina.cn)
版本号: 20170330
更新时间: <2017-04-06>
原创时间: <2017-03-30>
版权: 本文采用以下协议进行授权,自由转载 - 非商用 - 非衍生 - 保持署名 | Creative Commons BY-NC-ND 3.0,转载请注明作者及出处.
1. 概念简介
不同的系统在存储数据时是分大端(bit-endian)小端(little-endian)存储的,比如,Inter x86、ARM核采用的是小端模式,Power PC、MIPS UNIX和HP-PA UNIX采用大端模式
小端模式用文字描述是,低地址上存放低字节,高地址上存放高字节。
假如有一个32位的数据 0x11223344,则在小端模式上的机器上存储为如下的形式:
【1】0x11223344这个数中 0x11 是高字节(MSB),0x44是地字节(LSB)
【2】讨论大小端的时候最小单位是字节
【3】内存的画法中采用的是向上增长的
【3】可以将数据比作方向盘,顺时钟旋转得到的在内存中的布局是小端存储
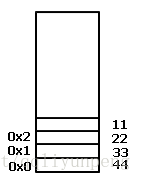
至于大端模式用文字描述是,低地址上存放高字节,高地址上存放低字节。
2. 如何判断
判断的方法有很多种,下面将简单的列举几种:
第一种方法:
- /*
- * 1: little-endian
- * 0: big-endian
- */
- int checkEndian()
- {
- int a = 1;
- char *p = (char *)&a;
- return (*p == 1);
- }
【1】如果是大端,*p的结果是0
第二种方法:
- /*
- * 1: little-endian
- * 0: big-endian
- */
- int checkEndian()
- {
- union w
- {
- int a;
- char b;
- } c;
- c.a = 1;
- return (c.b == 1);
- }
函数中打印方法:
- printf("%s\n", checkEndian() ? "little-endian" : "big-endian");
3. 大端和小端的转换
- int big_litle_endian(int x)
- {
- int tmp;
- tmp = (((x)&0xff)<<24) + (((x>>8)&0xff)<<16) + (((x>>16)&0xff)<<8) + (((x>>24)&0xff));
- return tmp;
- }
4. 其他
1. 在通信的场合经常会遇到大端和小端的转换的问题,比如tcp/ip 中,tcp/ip 中规定了自己传输的时候采用大端模式,当然相应的它也提供了很多函数来做支持。
如果主机是小端的模式,在跟网络进行交互的时候经常要用到如下的函数
- htons —— 把unsigned short类型从 主机序 转成 网络字节序
- ntohs —— 把unsigned short类型从 网络字节序 转成 主机序
- htonl —— 把unsigned long类型从 主机序 转成 网络字节序
- ntohl —— 把unsigned long类型从 网络字节序 转成 主机序
- #if defined(_LINUX) || defined(_DARWIN)
- #include <netinet/in.h>
- #endif
- #ifdef WIN32
- #include <WINSOCK2.H>
- #endif
当一个系统要发送的数据是 0x12345678,以大端模式发送,则会先发送0x12.
2. 如何在64位ubuntu下同下编译32位的程序?
需要先安装32位的库:sudo apt-get install libc6-dev-i386
然后在编译的时候加上-m32选项。
C、C#实现反转总结。原文地址:https://blog.csdn.net/chenfujun818/article/details/78654956
下面是C#版 反转数组的几种总结。
解决其他同行的转换字符串而来。觉得很实用就整理了一下。
字符串版地址:http://m.blog.csdn.net/superit401/article/details/51318880
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
//unity 必须引用 system.text 命名空间
using System.Text;
public class ArrayReverseTest : MonoBehaviour {
private List<int> _arrList = new List<int>{12,58,36,46,78,463,588,999};
void Start () {
PrintList();
Debug.Log(" ================ before ==============");
// _arrList = ArrayReverse();
// _arrList = BufferReverse();
// _arrList = StackReverse();
// _arrList = XORReverse();
RecursiveReverse(_arrList,0,_arrList.Count -1);
PrintList();
Debug.Log(" ================ after ==============");
}
//方法一 使用.net 自带的Array.Reverse() 面试时不建议用
List<int> ArrayReverse()
{
_arrList.Reverse();
return _arrList;
}
// 方法二 使用缓存数组方式 取1/2 进行交换
List<int> BufferReverse()
{
int countList = _arrList.Count;
for(int i = 0;i < countList / 2 ;i++)
{
int temp = _arrList[i];
_arrList[i] = _arrList[countList - i - 1];
_arrList[countList - i - 1] = temp;
}
return _arrList;
}
//方法三 使用栈
List<int> StackReverse()
{
List<int> tempList = new List<int>();
tempList.Clear();
Stack stack = new Stack();
foreach(int value in _arrList)
{
stack.Push(value);//入栈
}
for(int i = 0;i < _arrList.Count;i++)
{
tempList.Add((int)stack.Pop());//出栈
}
return tempList;
}
//方法四 使用异或运算进行反转
List<int> XORReverse()
{
int countList = _arrList.Count - 1;
for(int i = 0;i < countList;i++,countList--)
{
_arrList[i] ^= _arrList[countList];
_arrList[countList] ^= _arrList[i];
_arrList[i] ^= _arrList[countList];
}
return _arrList;
}
//方法五 使用递归 进行反转
void RecursiveReverse(List<int> list,int left,int right)
{
if(left >= right)
return;
//转换方式一
// int temp = list[left];
// list[left] = list[right];
// list[right] = temp;
//转换方式二
list[left] ^= list[right];
list[right] ^= list[left];
list[left] ^= list[right];
RecursiveReverse(list,++left,--right);
}
void PrintList()
{
//使用stringBuilder 的好处不言自明了 反转字符串的时候 它也是一种方式
StringBuilder strBuilder = new StringBuilder();
for(int i = 0,Max = System.Math.Min(_arrList.Count,_arrList.Count);i< _arrList.Count;i++)
{
strBuilder.Append(_arrList[i]);
strBuilder.Append(" ");
}
Debug.Log(" _arrlist = " + strBuilder);
}
}
字符串反转的9种方法1. 使用Array.Reverse方法public static string ReverseByArray(string original)
{
char[] c = original.ToCharArray();
Array.Reverse(c);
return new string(c);
}
2. 使用字符缓存
在面试或笔试中,往往要求不用任何类库方法,那么有朋友大概会使用类似下面这样的循环方法
public static string ReverseByCharBuffer(this string original)
{
char[] c = original.ToCharArray();
int l = original.Length;
char[] o = new char[l];
for (int i = 0; i < l ; i++)
{
o[i] = c[l - i - 1];
}
return new string(o);
}
当然,聪明的同学们一定会发现不必对这个字符数组进行完全遍历,通常情况下我们会只遍历一半
public static string ReverseByCharBuffer2(string original)
{
char[] c = original.ToCharArray();
int l = original.Length;
for (int i = 0; i < l / 2; i++)
{
char t = c[i];
c[i] = c[l - i - 1];
c[l - i - 1] = t;
}
return new string(c);
}
ReverseByCharBuffer使用了一个新的数组,而且遍历了字符数组的所有元素,因此时间和空间的开销都要大于ReverseByCharBuffer2。
在Array.Reverse内部,调用了非托管方法TrySZReverse,如果TrySZReverse不成功,实际上也是调用了类似ReverseByCharBuffer2的方法。
if (!TrySZReverse(array, index, length))
{
int num = index;
int num2 = (index + length) - 1;
object[] objArray = array as object[];
if (objArray == null)
{
while (num < num2)
{
object obj3 = array.GetValue(num);
array.SetValue(array.GetValue(num2), num);
array.SetValue(obj3, num2);
num++;
num2--;
}
}
else
{
while (num < num2)
{
object obj2 = objArray[num];
objArray[num] = objArray[num2];
objArray[num2] = obj2;
num++;
num2--;
}
}
}
大致上我能想到的算法就是这么多了,但是我无意间发现了StackOverflow上的一篇帖子,才发现这么一个看似简单的反转算法实现起来真可谓花样繁多。
3. 使用StringBuilder
使用StringBuilder方法大致和ReverseByCharBuffer一样,只不过不使用字符数组做缓存,而是使用StringBuilder。
public static string ReverseByStringBuilder(this string original)
{
StringBuilder sb = new StringBuilder(original.Length);
for (int i = original.Length - 1; i >= 0; i--)
{
sb.Append(original[i]);
}
return sb.ToString();
}
当然,你可以预见,这种算法的效率不会比ReverseByCharBuffer要高。
我们可以像使用字符缓存那样,对使用StringBuilder方法进行优化,使其遍历过程也减少一半
public static string ReverseByStringBuilder2(this string original)
{
StringBuilder sb = new StringBuilder(original);
for (int i = 0, j = original.Length - 1; i <= j; i++, j--)
{
sb[i] = original[j];
sb[j] = original[i];
}
return sb.ToString();
}
以上这几种方法按算法角度来说,其实可以归结为一类。然而下面的几种算法就完全不是同一类型的了。
使用栈
4. 栈是一个很神奇的数据结构。我们可以使用它后进先出的特性来对数组进行反转。先将数组所有元素压入栈,然后再取出,顺序很自然地就与原先相反了。
public static string ReverseByStack(this string original)
{
Stack<char> stack = new Stack<char>();
foreach (char ch in original)
{
stack.Push(ch);
}
char[] c = new char[original.Length];
for (int i = 0; i < original.Length; i++)
{
c[i] = stack.Pop();
}
return new string(c);
}
两次循环和栈的开销无疑使这种方法成为目前为止开销最大的方法。但使用栈这个数据结构的想法还是非常有价值的。
使用XOR
5. 使用逻辑异或也可以进行反转
public static string ReverseByXor(string original)
{
char[] charArray = original.ToCharArray();
int l = original.Length - 1;
for (int i = 0; i < l; i++, l--)
{
charArray[i] ^= charArray[l];
charArray[l] ^= charArray[i];
charArray[i] ^= charArray[l];
}
return new string(charArray);
}
在C#中,x ^= y相当于x = x ^ y。通过3次异或操作,可以将两个字符为止互换。对于算法具体的解释可以参考这篇文章。
6. 使用指针
使用指针可以达到最快的速度,但是unsafe代码不是微软所推荐的,在这里我们就不多做讨论了
public static unsafe string ReverseByPointer(this string original)
{
fixed (char* pText = original)
{
char* pStart = pText;
char* pEnd = pText + original.Length - 1;
for (int i = original.Length / 2; i >= 0; i--)
{
char temp = *pStart;
*pStart++ = *pEnd;
*pEnd-- = temp;
}
return original;
}
}
7. 使用递归
对于反转这类算法,都可以使用递归方法
public static string ReverseByRecursive(string original)
{
if (original.Length == 1)
return original;
else
return original.Substring(1).ReverseByRecursive() + original[0];
}
8. 使用委托,还可以使代码变得更加简洁
public static string ReverseByRecursive2(this string original)
{
Func<string, string> f = null;
f = s => s.Length > 0 ? f(s.Substring(1)) + s[0] : string.Empty;
return f(original);
}
但是委托开销大的弊病在这里一点也没有减少,以至于我做性能测试的时候导致系统假死甚至内存益处。
使用LINQ
9. System.Enumerable里提供了默认的Reverse扩展方法,我们可以基于该方法来对String类型进行扩展
public static string ReverseByLinq(this string original)
{
return new string(original.Reverse().ToArray());
}
大端模式、小端模式和C#反转的更多相关文章
- 判断CPU是大端还是小端模式
在小端模式中,低位字节放在低地址,高位字节放在高地址:在大端模式中,低位字节放在高地址,高位字节放在低地址.big-endian和little-endian,51单片机是典型的大端模式,Intel电脑 ...
- 转!大端模式&小端模式
大端模式&小端模式 在C语言中除了8位的char型之外,还有16位的short型,32位的long型(要看具体的编译器),对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器 ...
- 【转】如何判断CPU是大端还是小端模式
原文网址:http://blog.csdn.net/ysdaniel/article/details/6617458 如何判断CPU是大端还是小端模式 http://blog.sina.com.cn/ ...
- 大端模式&小端模式、主机序&网络序、入栈地址高低问题
一.大端模式&小端模式 所谓的“大端模式”,是指数据的低位(就是权值较小的后面那几位)保存在内存的高地址中,而数据的高位,保存在内存的低地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处 ...
- 大端模式 VS 小端模式
简单点说,就是字节的存储顺序,如果数据都是单字节的,那怎么存储无所谓了,但是对于多字节数据,比如int,double等,就要考虑存储的顺序了.注意字节序是硬件层面的东西,对于软件来说通常是透明的.再说 ...
- Linux网络编程1——小端模式与大端模式
数据存储优先顺序的转换 计算机数据存储有两种字节优先顺序:高位字节优先(称为大端模式)和低位字节优先(称为小端模式).内存的低地址存储数据的低字节,高地址存储数据的高字节的方式叫小端模式.内存的高地址 ...
- C/C++ 工具函数 —— 大端模式和小端模式的互换
小端模式:小在小,大在大:大端模式:小在大,大在小: uint32_t swap_endian(uint32_t val) { val = ((val << 8) & 0xFF00 ...
- 【C/C++开发】内存对齐(内存中的数据对齐)、大端模式及小端模式
数据对齐,是指数据所在的内存地址必须是该数据长度的整数倍.DWORD数据的内存起始地址能被4除尽,WORD数据的内存起始地址能被2除尽.X86 CPU能直接访问对齐的数据,当它试图访问一个未对齐的数据 ...
- C++查看大端小端模式
在学习计算机组成原理的时候,看到大端小端模式,便想实验一下,首先介绍一下 C 中的union,这个平时用得少,估计在单片机这种可能会运用,在平时写代码的时候几乎是用不着union的. union:联合 ...
随机推荐
- XOR Queries(莫队+trie)
题目链接: XOR Queries 给出一个长度为nn的数组CC,回答mm个形式为(L, R, A, B)(L,R,A,B)的询问,含义为存在多少个不同的数组下标k \in [L, R]k∈[L,R] ...
- [Linux] sed命令使用之在文件中快速删除/增加指定行
1.删除文档的第一行 sed -i '1d' <file> 2.删除文档的最后一行sed -i '$d' <file> 3.在文档指定行中增加一行例如文档如下:echo &qu ...
- 機器學習基石 机器学习基石(Machine Learning Foundations) 作业2 第10题 解答
由于前面分享的几篇博客已经把其他题的解决方法给出了链接,而这道题并没有,于是这里分享一下: 原题: 这题说白了就是求一个二维平面上的数据用决策树来分开,这就是说平面上的点只能画横竖两个线就要把所有的点 ...
- phpcms修改增加编辑时摘要自动提取的数量
\caches\caches_model\caches_data\model_field_1.cache.php 搜索 name="introcude_length" value= ...
- 【解题报告】Codeforces Round #301 (Div. 2) 之ABCD
A. Combination Lock 拨密码..最少次数..密码最多有1000位. 用字符串存起来,然后每位大的减小的和小的+10减大的,再取较小值加起来就可以了... #include<st ...
- 因为yii2中jquery位置默认在最下方,可将自定义js位置放在下方
因为yii2中jquery位置默认在最下方,可将自定义js位置放在下方,这样就可以执行当页面加载完触发动作.记录下方式,查找方便 <?php $this->beginBlock('test ...
- ssh/scp免密码登录传输
# 本地服务器生成key(直接回车默认) ssh-keygen # 将key传输到要登录的服务器 ssh-copy-id -i /root/.ssh/id_rsa.pub root@IP地址 # 输入 ...
- mysql 查找除id外其他重复的字段数据
如表 test1 有多个重复的字段 其中有些数据完全重复是错误的数据,我们要把他找出来,然后删除掉 select * from test1 a where (a.phone,a.name) in ( ...
- Emgucv3.0的安装与配置
环境:vs2015+Emgucv3.0 Emgu Cv简介: Emgu CV 是.NET平台下对OpenCV图像处理库的封装.也就是OpenCV的.NET版.它运行在.NET兼容的编程语言下调用Ope ...
- fopen()和fclose()
1.fopen()函数的用法fopen函数用于打开文件, 其调用格式为:FILE *fopen(char *filename, *type);fopen()函数中第一个形式参数表示文件名, 可以包含路 ...