intellij-idea打包Scala代码在spark中运行
、创建好Maven项目之后(记得添加Scala框架到该项目),修改pom.xml文件,添加如下内容:
<properties>
<spark.version>2.1.</spark.version>
<scala.version>2.11</scala.version>
</properties> <dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency> </dependencies> <build>
<plugins> <plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin> <plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.19</version>
<configuration>
<skip>true</skip>
</configuration>
</plugin> </plugins>
</build>
其中保存之后,需要点击下面的import change,这样相当于是下载jar包
二、编写一个Scala程序,统计单词的个数
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object WordCount {
def main(args: Array[String]) {
if (args.length == ) {
System.err.println("Usage: spark.example.WordCount <input> <output>")
System.exit()
} val input_path = args().toString
val output_path = args().toString val conf = new SparkConf().setAppName("WordCount")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") val sc = new SparkContext(conf)
val inputFile = sc.textFile(input_path)
val countResult = inputFile.flatMap(line => line.split(" "))
.map(word => (word, ))
.reduceByKey(_ + _)
.map(x => x._1 + "\t" + x._2)
.saveAsTextFile(output_path)
}
}
三、打包
file->Porject Structure->Artifacts->绿色的加号->JAR->from modules...
然后填写定义的类名,选择copy to..选项(打包这一个类)

点击ok之后,然后build->build Artifacts->build,等待build完成。然后可以在项目的这个目录中找到刚刚打包的这个jar包

四、运行在spark集群上面
1. 把jar包放到能访问spark集群的机器上面
2. 运行
/usr/local/spark/bin/spark-submit --class WordCount --master spark://master:7077 /data/wangzai/package/WordCount.jar \
hdfs://master:9000/spark/test.data hdfs://master:9000/spark_output/spark_wordcount \
--executor-memory 1G \
--executor-cores 1 \
--num-executors 10
3. 结果

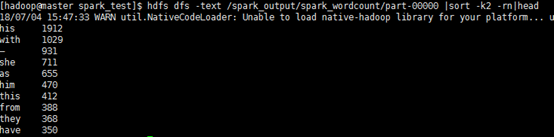
intellij-idea打包Scala代码在spark中运行的更多相关文章
- sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类
sbt打包Scala写的Spark程序,打包正常,提交运行时提示找不到对应的类 详述 使用sbt对写的Spark程序打包,过程中没有问题 spark-submit提交jar包运行提示找不到对应的类 解 ...
- IntelliJ IDEA开发Scala代码,与java集成,maven打包编译
今天尝试了一下在IntelliJ IDEA里面写Scala代码,并且做到和Java代码相互调用,折腾了一下把过程记录下来. 首先需要给IntelliJ IDEA安装一下Scala的插件,在IDEA的启 ...
- pycharm中运行成功的python代码在jenkin中运行问题总结
我们在用selenium+python完成了项目的UI自动化后,一般用jekins持续集成工具来定期运行,python程序在pycharm中编辑运行成功,但在jenkins中运行失败的两个问题,整理如 ...
- 使用IDEA打包scala程序并在spark中运行
一.首先配置ssh无秘钥登陆, 先使用这条命令:ssh-keygen,然后敲三下回车: 然后使用cd .ssh进入 .ssh这个隐藏文件夹: 再创建一个文件夹authorized_keys,使用命令t ...
- 使用IntelliJ IDEA编写Scala在Spark中运行
使用Scala写一个测试代码: object Test { def main(args: Array[String]): Unit = { println("hello world" ...
- maven 打包Scala代码到jar包
idea的pom.xml文件配置 <dependencies> <dependency> <groupId>org.scala-lang</groupId&g ...
- .NetCore下利用Jenkins如何将程序自动打包发布到Docker容器中运行
说道这一块纠结了我两天时间,感觉真的很心累,Jenkins的安装就不多说了 这里我们最好直接安装到宿主机上,应该pull到的jenkins版本是2.6的,里面很多都不支持,我自己试了在容器中安装的情况 ...
- intellij idea打包出来的jar包,运行时中文乱码
比如以下代码: import javax.swing.*; public class addJarPkg { public static void main(String[] args) { JFra ...
- eclipse将项目打包成jar在linux中运行
最近因为项目需要,做了几个外挂程序做数据传输,涉及到项目打包操作,在此记录一下打包步骤和其中出现的问题. 1.首先右键项目文件夹,点击export,弹出如下选择框,在其中输入jar搜索,并选择JAR ...
随机推荐
- python 发送email
pyton smtplib发送邮件 在邮件中设置并获取到 smtp域名 在脚本中执行命名,收件人可以是 多个,在列表中 import smtplib from email.mime.text impo ...
- AWS系列-EC2默认限制说明
Amazon EC2 提供您可以使用的不同资源,例如实例和卷. 在您创建 AWS 账户时,AWS 会针对每个区域中的这些资源设置限制.此页面列出您在 亚太区域 (东京) 中的 EC2 服务限制. 1. ...
- JAVA上百实例源码网站
JAVA源码包1JAVA源码包2JAVA源码包3JAVA源码包4 JAVA开源包1 JAVA开源包2 JAVA开源包3 JAVA开源包4 JAVA开源包5 JAVA开源包6 JAVA开源包7 JAVA ...
- 收集各种在线HTTP网站载入速度(响应时间)站长测试(检测)工具
收集各种在线HTTP网站载入速度(响应时间)站长测试(检测)工具 名称\详情 简单功能描述 推荐星级 演示/示例 监控宝 从中国多地对你提交的URL进行载入速度(响应时间)测试 ★★★★★ 17C ...
- 【黑金原创教程】【Modelsim】【第一章】Modelsim仿真的扫盲文
声明:本文为黑金动力社区(http://www.heijin.org)原创教程,如需转载请注明出处,谢谢! 黑金动力社区2013年原创教程连载计划: http://www.cnblogs.com/al ...
- maven项目引入jar包
今天看一下maven项目的创建和具体操作.
- springboot + ApplicationListener
ApplicationListener自定义侦听器类 @Component public class InstantiationTracingBeanPostProcessor implements ...
- 160607、springmvc+spring使用taskExecutor
第一步:导入spring core的jar+springmvc的jar 第二步:springmvc的配置文件中 <bean id="taskExecutor" class=& ...
- Zabbix的API的使用
上一篇:Zabbix低级主动发现之MySQL多实例 登录请求(返回一个token,在后面的api中需要用到) curl -s -X POST -H 'Content-Type:application/ ...
- web.xml 中以编码方式添加filter并设置初始化参数AbstractAnnotationConfigDispatchServletInitializer
web.xml中配置filter <?xml version="1.0" encoding="UTF-8"?> <web-app versio ...