re模块之re.match
re模块——python 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
问题:从以下文件里取出所有的手机号:
姓名 地区 身高 体重 电话
况咏蜜 北京 171 48 13651054608
王心颜 上海 169 46 13813234424
马纤羽 深圳 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 深圳 177 54 18835324553
贺婉萱 深圳 174 52 18933434452
叶梓萱 上海 171 49 18042432324
杜姗姗 北京 167 49 13324523342
常用的办法:使用for语句读取每一行,然后取出每一条line 中的位数为11的数字串。
f = open('phone_num', 'r', encoding='utf-8')
phones = []
for line in f:
name, city, height, weight, phone = line.split()
if phone.startswith('1') and len(phone) == 11:
phones.append(phone)
print(phones)如果使用re模块,该如何实现呢?
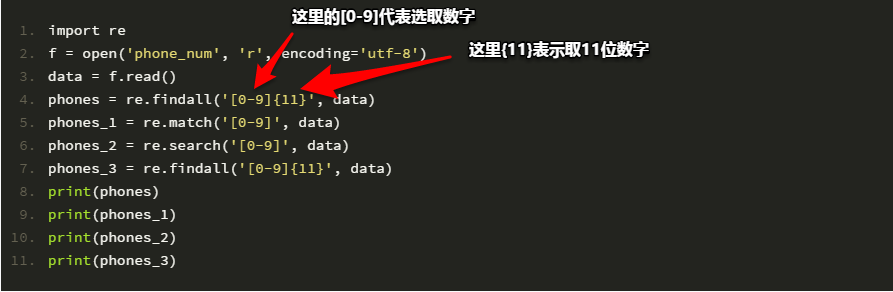
import re
f = open('phone_num', 'r', encoding='utf-8')
data = f.read()
phones = re.findall('[0-9]{11}', data)
phones_1 = re.match('[0-9]', data)
phones_2 = re.search('[0-9]', data)
phones_3 = re.findall('[0-9]{11}', data)
print(phones)
print(phones_1)
print(phones_2)
print(phones_3)输出的结果为:
phones = ['13651054608', '13813234424', '13744234523', '15823423525', '18623423421', '18623423765', '18835324553', '18933434452', '18042432324', '13324523342']
phones_1 = None
phones_2 = <_sre.SRE_Match object; span=(27, 28), match='2'>
phones_3 = ['13651054608', '13813234424', '13744234523', '15823423525', '18623423421', '18623423765', '18835324553', '18933434452', '18042432324', '13324523342']
re的匹配语法有以下几种:
- re.match 从头开始匹配
- re.search 匹配包含
- re.findall 把所有匹配到的字符放到以列表中的元素返回
- re.split 以匹配到的字符当做列表分隔符
- re.sub 匹配字符并替换
re.fullmatch 全部匹配
1. re.match
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
1.1 函数语法:
re.match(pattern, string, flags=0)
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
- pattern 匹配模式,由re.compile获得
- string 需要匹配的字符串
比如,在上面的例子中,re.match('[0-9]{11}', data):
[0-9]:匹配的表达式,如果字符串的开头满足是数字,那么就返回这个值;
{11}:如果该字符串为11位,那么就返回;
data:要匹配的字符串,本例中就是phone_num文件中的内容。
匹配成功re.match方法返回一个匹配的对象,否则返回None;我们也可以用group(num)或者groups()匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例一:
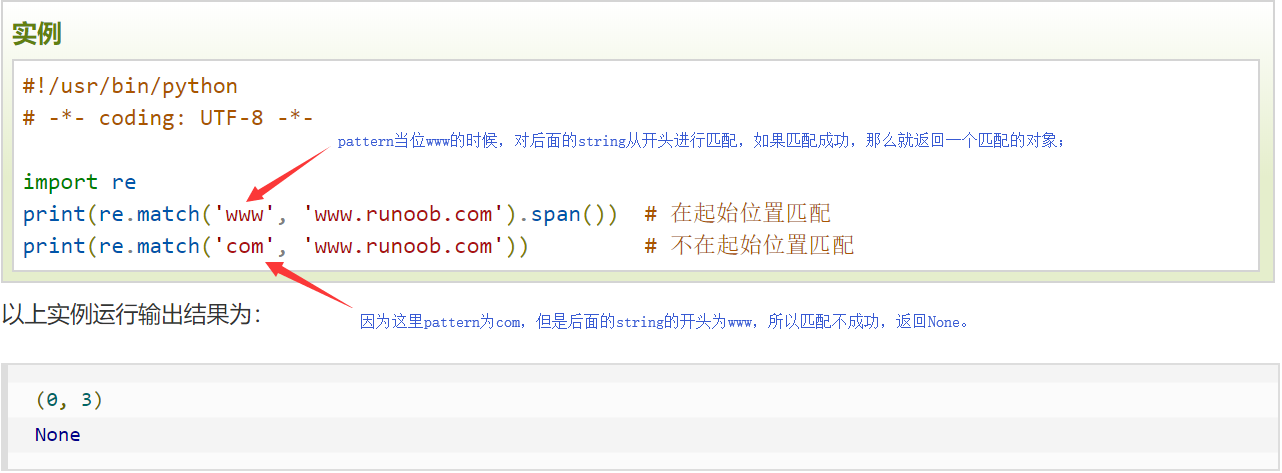
实例二:

实例三:
import re
pattern = re.compile(r'hello')
a = re.match(pattern, 'hello world')
b = re.match(pattern, 'world hello')
c = re.match(pattern, 'hell')
d = re.match(pattern, 'hello ')
if a:
print(a.group())
else:
print('a 失败')
if b:
print(b.group())
else:
print('b 失败')
if c:
print(c.group())
else:
print('c 失败')
if d:
print(d.group())
else:
print('d 失败')输出结果为:
hello
b 失败
c 失败
hello1.2 match的属性和方法
import re
str = 'hello world! hello python'
pattern = re.compile(r'(?P<first>hell\w)(?P<symbol>\s)(?P<last>.*ld!)') # 分组,0 组是整个 hello world!, 1组 hello,2组 ld!
match = re.match(pattern, str)
print('group 0:', match.group(0)) # 匹配 0 组,整个字符串
print('group 1:', match.group(1)) # 匹配第一组,hello
print('group 2:', match.group(2)) # 匹配第二组,空格
print('group 3:', match.group(3)) # 匹配第三组,ld!
print('groups:', match.groups()) # groups 方法,返回一个包含所有分组匹配的元组
print('start 0:', match.start(0), 'end 0:', match.end(0)) # 整个匹配开始和结束的索引值
print('start 1:', match.start(1), 'end 1:', match.end(1)) # 第一组开始和结束的索引值
print('start 2:', match.start(1), 'end 2:', match.end(2)) # 第二组开始和结束的索引值
print('pos 开始于:', match.pos)
print('endpos 结束于:', match.endpos) # string 的长度
print('lastgroup 最后一个被捕获的分组的名字:', match.lastgroup)
print('lastindex 最后一个分组在文本中的索引:', match.lastindex)
print('string 匹配时候使用的文本:', match.string)
print('re 匹配时候使用的 Pattern 对象:', match.re)
print('span 返回分组匹配的 index (start(group),end(group)):', match.span(2))group 0: hello world!
group 1: hello
group 2:
group 3: world!
groups: ('hello', ' ', 'world!')
start 0: 0 end 0: 12
start 1: 0 end 1: 5
start 2: 0 end 2: 6
pos 开始于: 0
endpos 结束于: 25
lastgroup 最后一个被捕获的分组的名字: last
lastindex 最后一个分组在文本中的索引: 3
string 匹配时候使用的文本: hello world! hello python
re 匹配时候使用的 Pattern 对象: re.compile('(?P<first>hell\\w)(?P<symbol>\\s)(?P<last>.*ld!)')
span 返回分组匹配的 index (start(group),end(group)): (5, 6)
- 为什么group(0)打印出来的结果是“hello world!”
因为pattern设置的就是从hell——ld!,所以hello python并不会匹配,自然也就不会打印。- "?P< first>hell\w" 代表是什么意思?
这是?< first>是python语言里面的一种特殊的匹配方式,将匹配到的结果标记一个名字——也就是<>括号中的单词;然后,\w 表示匹配[A-Z, a-z, 0-9]的字符。
re模块之re.match的更多相关文章
- python re模块search()与match()区别
re.search()搜索字符串并返回结果. 整个字符串搜索. re.match()匹配字符串并返回结果 从开始处匹配. 所以,match()可以理解为search()的一个子集.
- Python 五个常用模块资料 os sys time re built-in
1.os模块 os模块包装了不同操作系统的通用接口,使用户在不同操作系统下,可以使用相同的函数接口,返回相同结构的结果. os.name:返回当前操作系统名称('posix', 'nt', ' ...
- python 常用模块
1.os模块 os模块包装了不同操作系统的通用接口,使用户在不同操作系统下,可以使用相同的函数接口,返回相同结构的结果. os.name:返回当前操作系统名称('posix', 'nt', 'os2' ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- Python之正则表达式(re模块)
本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 正则表达式(Regluar Expressions)又称规则 ...
- Python中的re模块--正则表达式
Python中的re模块--正则表达式 使用match从字符串开头匹配 以匹配国内手机号为例,通常手机号为11位,以1开头.大概是这样13509094747,(这个号码是我随便写的,请不要拨打),我们 ...
- re模块的应用
import re # 正则表达式中的转义 : # '\(' 表示匹配小括号 # [()+*?/$.] 在字符组中一些特殊的字符会现出原形 # 所有的 \w \d \s(\n,\t, ) \W \D ...
- 【转】fnmatch模块的使用——主要作用是文件名称的匹配,并且匹配的模式使用的unix shell风格
[转]fnmatch模块的使用 fnmatch模块的使用 此模块的主要作用是文件名称的匹配,并且匹配的模式使用的unix shell风格.fnmatch比较简单就4个方法分别是:fnmatch,fnm ...
- 【转】Python之正则表达式(re模块)
[转]Python之正则表达式(re模块) 本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 参考文档 提示: ...
随机推荐
- vector 介绍
介绍 这篇文章的目的是为了介绍std::vector,如何恰当地使用它们的成员函数等操作.本文中还讨论了条件函数和函数指针在迭代算法中使用,如在remove_if()和for_each()中的使用.通 ...
- matlab调用c程序(转载)
通过把耗时长的函数用c语言实现,并编译成mex函数可以加快执行速度. Matlab本身是不带c语言的编译器的,所以要求你的机器上已经安装有VC,BC或Watcom C中的一种. 如果你在安装Matla ...
- pycharm中import动态链接库pyd有错误
有红色波浪线提示unsolved reference云云 去setting里面设置interpreters, 在path里面添加对应的路径, 是包含对应头文件的路径, 不要忘记右边的小按钮去Relo ...
- js中将时间(如:2017-10-8 22:44:55)转化为时间搓,时间戳转为标准格式时间
function split_time(time){//将当前时间转换成时间搓 例如2013-09-11 12:12:12 var arr=time.split(" "); var ...
- gradle 插件
1. 系统内置插件的应用 a. 二进制 apply plugin :"pluginname" 比如: java b. 脚本插件 apply from : "version ...
- qt ui程序使用Linux的文件操作open、close (转)
原文地址:qt ui程序使用Linux的文件操作open.close 作者:kjpioo 提出这个问题是因为在qt的QWidget类型的对象中,close()函数会和QWidget::close()冲 ...
- ecmall公告挂件分析(转)--此挂件写法已有更新的写法。
ecmall的首页,基本上都是由挂件的形式实现的.ecmall所有的挂件程序,都在external\widgets文件下面.ecmall首页公告的插件,就是notice目录里面. 分析里面文件,con ...
- 优化RequireJS项目(合并与压缩)
关于RequireJS已经有很多文章介绍过了.这个工具可以将你的JavaScript代码轻易的分割成苦 干个模块(module)并且保持你的代码模块化与易维护性.这样,你将获得一些具有互相依赖关系的J ...
- RK3288 USB UVC camera 摄像头 VIDIOC_DQBUF Failed!!! err[I/O error]
RK3288 Android5.1 多个品牌USB摄像头 同一块主板和代码,大部分品牌的USB摄像头可以正常使用,只有某一款USB摄像头不能使用. 插上摄像头,底层可以识别到摄像头. &l ...
- linux(centos)下安装ffmpeg
[备忘]windows环境下20行php代码搞定音频裁剪 上次我的这篇文章将了windows下web中如何操作ffmpeg的文章,这里则记录下linux(centos)下的安装 首先:我花了中午大概1 ...