HBase之八--(3):Hbase 布隆过滤器BloomFilter介绍
布隆过滤器( Bloom filters)
数据块索引提供了一个有效的方法,在访问一个特定的行时用来查找应该读取的HFile的数据块。但是它的效用是有限的。HFile数据块的默认大小是64KB,这个大小不能调整太多。
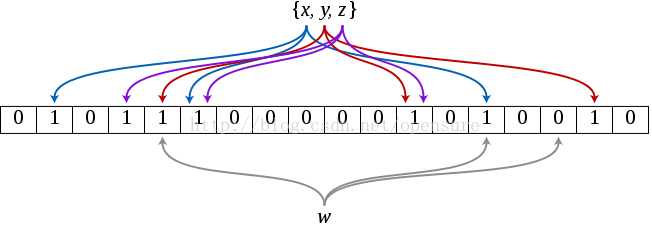
如果你要查找一个短行,只在整个数据块的起始行键上建立索引无法给你细粒度的索引信息。例如,如果你的行占用100字节存储空间,一个64KB的数据块包含(64 * 1024)/100 = 655.53 = ~700行,而你只能把起始行放在索引位上。你要查找的行可能落在特定数据块上的行区间里,但也不是肯定存放在那个数据块上。这有多种情况的可能,或者该行在表里不存在,或者存放在另一个HFile里,甚至在MemStore里。这些情况下,从硬盘读取数据块会带来IO开销,也会滥用数据块缓存。这会影响性能,尤其是当你面对一个巨大的数据集并且有很多并发读用户时。
布隆过滤器允许你对存储在每个数据块的数据做一个反向测试。当某行被请求时,先检查布隆过滤器看看该行是否不在这个数据块。布隆过滤器要么确定回答该行不在,要么回答它不知道。这就是为什么我们称它是反向测试。布隆过滤器也可以应用到行里的单元上。当访问某列标识符时先使用同样的反向测试。
布隆过滤器也不是没有代价。存储这个额外的索引层次占用额外的空间。布隆过滤器随着它们的索引对象数据增长而增长,所以行级布隆过滤器比列标识符级布隆过滤器占用空间要少。当空间不是问题时,它们可以帮助你榨干系统的性能潜力。
你可以在列族上打开布隆过滤器,如下所示:
hbase(main)> create 'mytable',{NAME=>'colfam1',BLOOMFILTER=>'ROWCOL'}
BLOOMFILTER参数的默认值是NONE。一个行级布隆过滤器用ROW打开,列标识符级布隆过滤器用ROWCOL打开。行级布隆过滤器在数据块里检查特定行键是否不存在,列标识符级布隆过滤器检查行和列标识符联合体是否不存在。ROWCOL布隆过滤器的开销高于ROW布隆过滤器。
- if (memOnly == false
- && ((StoreFileScanner) kvs).shouldSeek(scan, columns)) {
- scanners.add(kvs);
- }
- if (!scan.isGetScan()) {
- return true;
- }
- byte[] row = scan.getStartRow();
- switch (this.bloomFilterType) {
- case ROW:
- return passesBloomFilter(row, 0, row.length, null, 0, 0);
- case ROWCOL:
- if (columns != null && columns.size() == 1) {
- byte[] column = columns.first();
- return passesBloomFilter(row, 0, row.length, column, 0, column.length);
- }
- // For multi-column queries the Bloom filter is checked from the
- // seekExact operation.
- return true;
- default:
- return true;
- }
- // Seek all scanners to the start of the Row (or if the exact matching row
- // key does not exist, then to the start of the next matching Row).
- if (matcher.isExactColumnQuery()) {
- for (KeyValueScanner scanner : scanners)
- scanner.seekExactly(matcher.getStartKey(), false);
- } else {
- for (KeyValueScanner scanner : scanners)
- scanner.seek(matcher.getStartKey());
- }
- public boolean seekExactly(KeyValue kv, boolean forward)
- throws IOException {
- if (reader.getBloomFilterType() != StoreFile.BloomType.ROWCOL ||
- kv.getRowLength() == 0 || kv.getQualifierLength() == 0) {
- return forward ? reseek(kv) : seek(kv);
- }
- boolean isInBloom = reader.passesBloomFilter(kv.getBuffer(),
- kv.getRowOffset(), kv.getRowLength(), kv.getBuffer(),
- kv.getQualifierOffset(), kv.getQualifierLength());
- if (isInBloom) {
- // This row/column might be in this store file. Do a normal seek.
- return forward ? reseek(kv) : seek(kv);
- }
- // Create a fake key/value, so that this scanner only bubbles up to the top
- // of the KeyValueHeap in StoreScanner after we scanned this row/column in
- // all other store files. The query matcher will then just skip this fake
- // key/value and the store scanner will progress to the next column.
- cur = kv.createLastOnRowCol();
- return true;
- }
HBase之八--(3):Hbase 布隆过滤器BloomFilter介绍的更多相关文章
- Hbase 布隆过滤器BloomFilter介绍
转载自:http://blog.csdn.net/opensure/article/details/46453681 1.主要功能 提高随机读的性能 2.存储开销 bloom filter的数据存在S ...
- Spark布隆过滤器(bloomFilter)
数据过滤在很多场景都会应用到,特别是在大数据环境下.在数据量很大的场景实现过滤或者全局去重,需要存储的数据量和计算代价是非常庞大的.很多小伙伴第一念头肯定会想到布隆过滤器,有一定的精度损失,但是存储性 ...
- 布隆过滤器(BloomFilter)持久化
摘要 Bloomfilter运行在一台机器的内存上,不方便持久化(机器down掉就什么都没啦),也不方便分布式程序的统一去重.我们可以将数据进行持久化,这样就克服了down机的问题,常见的持久化方法包 ...
- 白话布隆过滤器BloomFilter
通过本文将了解到以下内容: 查找问题的一般思路 布隆过滤器的基本原理 布隆过滤器的典型应用 布隆过滤器的工程实现 场景说明: 本文阐述的场景均为普通单机服务器.并非分布式大数据平台,因为在大数据平台下 ...
- 【浅析】|白话布隆过滤器BloomFilter
通过本文将了解到以下内容: 查找问题的一般思路 布隆过滤器的基本原理 布隆过滤器的典型应用 布隆过滤器的工程实现 场景说明: 本文阐述的场景均为普通单机服务器.并非分布式大数据平台,因为在大数据平台下 ...
- 海量数据处理之布隆过滤器BloomFilter算法
Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合.使用场景:数据量为100亿 ...
- 一道腾讯面试题:如何快速判断某 URL 是否在 20 亿的网址 URL 集合中?布隆过滤器
何为布隆过滤器 还是以上面的例子为例: 判断逻辑: 多次哈希: Guava的BloomFilter 创建BloomFilter 最终还是调用: 使用: 算法特点 使用场景 假设遇到这样一个问题:一个网 ...
- python实现布隆过滤器及原理解析
python实现布隆过滤器及原理解析 布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地 ...
- Redis实现布隆过滤器解析
布隆过滤器原理介绍 [1]概念说明 1)布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合 ...
随机推荐
- Jquery validation自定义验证
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- (转载)Android学习笔记⑨——android.content.ActivityNotFoundException异常处理
异常1:Java.lang.ClassNotFoundException 08-13 18:29:22.924: E/AndroidRuntime(1875):Caused by: Java.lang ...
- onunload、onbeforeunload事件详解--zhuan
最近项目中做到一个功能:在上传页面用户开始上传文件之后用户点击任意跳转都需要弹出提示层进行二次确定才允许他进行跳转,这样做的目的是为了防止用户的错误操作导致这珍贵的UGC 流失(通常用户在一次上传不成 ...
- 使用DaoCloud持续构建docker镜像,自动化部署
我们学会了在主机上安装部署docker,也学会了构建自己的docker镜像和容器,启停也都会用了,下一步就需要持续构建发布docker的技能了. 我们希望能在代码提交后,有个远程服务能自动开始构建项目 ...
- HDU - 5324:Boring Class (CDQ分治&树状数组&最小字典序)
题意:给定N个组合,每个组合有a和b,现在求最长序列,满足a不升,b不降. 思路:三位偏序,CDQ分治. 但是没想到怎么输出最小字典序,我好菜啊. 最小字典序: 我们倒序CDQ分治,ans[i]表 ...
- Web应用中使用JavaMail发送邮件进行用户注册
现在很多的网站都提供有用户注册功能, 通常我们注册成功之后就会收到一封来自注册网站的邮件.邮件里面的内容可能包含了我们的注册的用户名和密码以及一个激活账户的超链接等信息.今天我们也来实现一个这样的功能 ...
- BZOJ4668 冷战 【LCT】
Description 1946 年 3 月 5 日,英国前首相温斯顿·丘吉尔在美国富尔顿发表"铁幕演说",正式拉开了冷战序幕. 美国和苏联同为世界上的"超级大国&quo ...
- BZOJ2303: [Apio2011]方格染色 【并查集】
Description Sam和他的妹妹Sara有一个包含n × m个方格的表格.她们想要将其的每个方格都染成红色或蓝色.出于个人喜好,他们想要表格中每个2 × 2的方形区域都包含奇数个(1 个或 3 ...
- pat甲级 1155 Heap Paths (30 分)
In computer science, a heap is a specialized tree-based data structure that satisfies the heap prope ...
- Python基础之路
一.Python基础之简介 二.Python基础之数据类型 三.Python之运算符 三.Python变量 四.Python之流程控制 三.Python基础之函数 四.Python基础之面向对象