RabbitMQ消息队列(九)RPC开始应用吧
一 简单应用
RPC——远程过程调用,通过网络调用运行在另一台计算机上的程序的函数\方法,是构建分布式程序的一种方式。RabbitMQ是一个消息队列系统,可以在程序之间收发消息。利用RabbitMQ可以实现RPC。本文所有操作都是在ubuntu16.04.3上进行的,示例代码语言为Python2.7。
yum install rabbitmq-server python-pika -y
/etc/init.d/rabbitmq-server start
update-rc.d rabbitmq-server enable
1 RPC的基本实现
root@ansible:~/workspace/RPC_TEST/RPC01# cat RPC_Server.py
#!/usr/bin/env python
# coding:utf-8 """
1.首先与rabbitmq建立链接,然后定义个函数fun(),
fun的功能是传入一个数返回该数的2倍,这个函数就是我们要远程调用的函数
2.on_request()是一个回调函数,他作为参数传递给了basic_consume(),
当basic_consume()在队列中消费1条消息时,on_request()就会被调用
3.on_request()从消息内容body中获取数,并传给fun()进行计算,并将返回值作为消息内容发给调用方指定的队列
队列名称保存在props.relay_to中
"""
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fun(n):
return n*2 def on_request(channel,method,props,body):
print " props.correlation_id: %s" %props.correlation_id
print "props.reply_to: %s" %props.reply_to
n = int(body)
response = fun(n)
channel.basic_publish(exchange='',routing_key=props.reply_to,
properties=pika.BasicProperties(
correlation_id=props.correlation_id),
body=str(response))
channel.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request,queue='rpc_queue')
print "[x] Waiting RPC request..."
channel.start_consuming()
以上代码中,首先与RabbitMQ服务建立连接,然后定义了一个函数fun(),fun()功能很简单,输入一个数然后返回该数的两倍,这个函数就是我们要远程调用的函数。on_request()是一个回调函数,它作为参数传递给了basic_consume(),当basic_consume()在队列中消费1条消息时,on_request()就会被调用,on_request()从消息内容body中获取数字,并传给fun()进行计算,并将返回值作为消息内容发给调用方指定的接收队列,队列名称保存在变量props.reply_to中。
root@ansible:~/workspace/RPC_TEST/RPC01# cat RPC_Client.py
#!/usr/bin/env python
# coding:utf-8 """
1. 链接rabbitmq ,然后开始消费消息队列callback_queue中的消息,该队列的名字通过RPC_Server端的Request属性中的
props.reply_to告诉server端,把返回的消息发送到这里队列中
2. basic_consume()的回调函数为on_response(),这个函数从callback_queue队列中取出消息的结果
3. 函数call实际的发送请求,把数字n发给服务器端,当response不为空时,返回response的值 """ import pika
import uuid class RpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue # 订阅消息,并触发回调函数
self.channel.basic_consume(self.on_response,no_ack=True,
queue=self.callback_queue) def on_response(self,channel,method,props,body):
# 判断client端这次的请求是server端这次的响应
if self.corr_id == props.correlation_id:
print "self.corr_id: %s" %self.corr_id
print "self.callback_queue: %s" %self.callback_queue
self.response = body def call(self,n):
self.response = None
self.corr_id = str(uuid.uuid4()) # 发布消息,relay_to表示接收消息的队列,correlation_id表示携带请求的唯一ID
self.channel.basic_publish(exchange='',routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return str(self.response) rpc = RpcClient() print "[x] Requesting..."
response = rpc.call(2) print "[.] Got %r" %response
代码开始也是连接RabbitMQ,然后开始消费消息队列callback_queue中的消息,该队列的名字通过Request的属性reply_to传递给服务端,就是在上面介绍服务端代码时提到过的props.reply_to,作用是告诉服务端把结果发到这个队列。 basic_consume()的回调函数变成了on_response(),这个函数从callback_queue的消息内容中获取返回结果。
函数call实际发起请求,把数字n发给服务端程序,当response不为空时,返回response值。
有本事来张图描述一下:
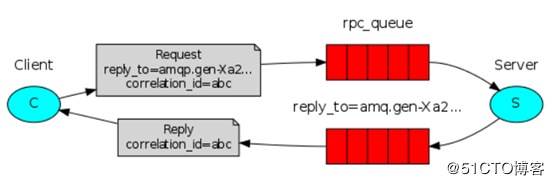
当客户端启动时,它将创建一个callback queue用于接收服务端的返回消息Reply,名称由RabbitMQ自动生成,如上图中的amq.gen-Xa2..。同一个客户端可能会发出多个Request,这些Request的Reply都由callback queue接收,为了互相区分,就引入了correlation_id属性,每个请求的correlation_id值唯一。这样,客户端发起的Request就带由2个关键属性:reply_to告诉服务端向哪个队列返回结果;correlation_id用来区分是哪个Request的返回。
2 稍微复杂点的RPC
如果服务端定义了多个函数供远程调用怎么办?有两种思路,一种是利用Request的属性app_id传递函数名,另一种是把函数名通过消息内容发送给服务端。
1)第一种思路
root@ansible:~/workspace/RPC_TEST/RPC02# cat RPC_Server.py
#!/usr/bin/env python
# coding:utf-8 """
1.首先与rabbitmq建立链接,然后定义个函数fun(),
fun的功能是传入一个数返回该数的2倍,这个函数就是我们要远程调用的函数
2.on_request()是一个回调函数,他作为参数传递给了basic_consume(),
当basic_consume()在队列中消费1条消息时,on_request()就会被调用
3.on_request()从消息内容body中获取数,并传给fun()进行计算,并将返回值作为消息内容发给调用方指定的队列
队列名称保存在props.relay_to中。 疑问:
1. server端怎么得到client的callback_queue的?
是通过过 routing_key=props.reply_to得到的,props是一个神奇的东西
2. 一个队列中多个请求,怎么区分的 ?
是通过props.correlation_id 然后client端做判断,是否和自己的相等。还是props
"""
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.queue_declare(queue='rpc_queue') def a(n):
return n*2 def b(n):
return n*4 def on_request(channel,method,props,body):
print " props.correlation_id: %s" %props.correlation_id
print "props.reply_to: %s" %props.reply_to
#n = int(body)
n = body
funname = props.app_id
print 'funname: %s' %funname
if funname == 'a': response = a(n)
if funname == 'b':
response = b(n) channel.basic_publish(exchange='',routing_key=props.reply_to,
properties=pika.BasicProperties(
correlation_id=props.correlation_id),
body=str(response))
channel.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request,queue='rpc_queue')
print "[x] Waiting RPC request..."
channel.start_consuming()
上面代码的一点改进就是如果函数过多怎么办?尼玛的,破电脑,都写完了,尼玛突然关机了,真是操了,有机会立马换ubuntu系统,windows太尼玛坑爹了,尤其是TMD的win10。
移驾http://www.cnblogs.com/wanstack/p/7052874.html
root@ansible:~/workspace/RPC_TEST/RPC02# cat RPC_Client.py
#!/usr/bin/env python
# coding:utf-8 """
1. 链接rabbitmq ,然后开始消费消息队列callback_queue中的消息,该队列的名字通过RPC_Server端的Request属性中的
props.reply_to告诉server端,把返回的消息发送到这里队列中
2. basic_consume()的回调函数为on_response(),这个函数从callback_queue队列中取出消息的结果
3. 函数call实际的发送请求,把数字n发给服务器端,当response不为空时,返回response的值 """ import pika
import uuid class RpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue # 订阅消息,并触发回调函数
self.channel.basic_consume(self.on_response,no_ack=True,
queue=self.callback_queue) def on_response(self,channel,method,props,body):
# 判断client端这次的请求是server端这次的响应
if self.corr_id == props.correlation_id:
print "self.corr_id: %s" %self.corr_id
print "self.callback_queue: %s" %self.callback_queue
self.response = body def call(self,n):
self.response = None
self.corr_id = str(uuid.uuid4()) # 发布消息,relay_to表示接收消息的队列,correlation_id表示携带请求的唯一ID
self.channel.basic_publish(exchange='',routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
app_id=str(n)),
body=str('request'))
while self.response is None:
self.connection.process_data_events()
return str(self.response) rpc = RpcClient() print "[x] Requesting..."
response = rpc.call('b') print "[.] Got %r" %response
函数call()接收参数name作为被调用的远程函数的名字,通过app_id传给服务端程序,这段代码里我们选择调用服务端的函数b(),rpc.call(“b”)。
2)第二种方式
root@ansible:~/workspace/RPC_TEST/RPC03# cat RPC_Server.py
#!/usr/bin/env python
# coding:utf-8 """
1.首先与rabbitmq建立链接,然后定义个函数fun(),
fun的功能是传入一个数返回该数的2倍,这个函数就是我们要远程调用的函数
2.on_request()是一个回调函数,他作为参数传递给了basic_consume(),
当basic_consume()在队列中消费1条消息时,on_request()就会被调用
3.on_request()从消息内容body中获取数,并传给fun()进行计算,并将返回值作为消息内容发给调用方指定的队列
队列名称保存在props.relay_to中。 疑问:
1. server端怎么得到client的callback_queue的?
是通过过 routing_key=props.reply_to得到的,props是一个神奇的东西
2. 一个队列中多个请求,怎么区分的 ?
是通过props.correlation_id 然后client端做判断,是否和自己的相等。还是props
"""
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.queue_declare(queue='rpc_queue') def a():
return 2 def b():
return 4 def on_request(channel,method,props,body):
print " props.correlation_id: %s" %props.correlation_id
print "props.reply_to: %s" %props.reply_to
#n = int(body) funname = body
# args01 = body.__code__.co_varnames[0]
print 'funname: %s' %funname
if funname == 'a': response = a()
if funname == 'b':
response = b() channel.basic_publish(exchange='',routing_key=props.reply_to,
properties=pika.BasicProperties(
correlation_id=props.correlation_id),
body=str(response))
channel.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request,queue='rpc_queue')
print "[x] Waiting RPC request..."
channel.start_consuming()
root@ansible:~/workspace/RPC_TEST/RPC03# cat RPC_Client.py
#!/usr/bin/env python
# coding:utf-8 """
1. 链接rabbitmq ,然后开始消费消息队列callback_queue中的消息,该队列的名字通过RPC_Server端的Request属性中的
props.reply_to告诉server端,把返回的消息发送到这里队列中
2. basic_consume()的回调函数为on_response(),这个函数从callback_queue队列中取出消息的结果
3. 函数call实际的发送请求,把数字n发给服务器端,当response不为空时,返回response的值 """ import pika
import uuid class RpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue # 订阅消息,并触发回调函数
self.channel.basic_consume(self.on_response,no_ack=True,
queue=self.callback_queue) def on_response(self,channel,method,props,body):
# 判断client端这次的请求是server端这次的响应
if self.corr_id == props.correlation_id:
print "self.corr_id: %s" %self.corr_id
print "self.callback_queue: %s" %self.callback_queue
self.response = body def call(self,name):
self.response = None
self.corr_id = str(uuid.uuid4()) # 发布消息,relay_to表示接收消息的队列,correlation_id表示携带请求的唯一ID
self.channel.basic_publish(exchange='',routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(name))
while self.response is None:
self.connection.process_data_events()
return str(self.response) rpc = RpcClient() print "[x] Requesting..."
response = rpc.call('b') print "[.] Got %r" %response
与第一种实现方法的区别就是没有使用属性app_id,而是把要调用的函数名放在消息内容body中,执行结果跟第一种方法一样。
一个简单的实际应用案例
下面我们将编写一个小程序,用于收集多台KVM宿主机上的虚拟机数量和剩余可使用的资源。程序由两部分组成,运行在每台宿主机上的脚本agent.py和管理机上收集信息的脚本collect.py。从RPC的角度,agent.py是服务端,collect.py是客户端。
root@ansible:~/workspace/RPC_TEST/RPC04# cat agent.py
#!/usr/bin/env python
# coding:utf-8 """
类似于RPC中的Server端
""" import pika
import libvirt
import psutil
import json
import socket
import os
import sys
# 用于解析XML文件
from xml.dom import minidom RabbitmqHost = '172.20.6.184'
RabbitmqUser = 'admin'
RabbitmqPwd = 'admin' credentials = pika.PlainCredentials(RabbitmqUser,RabbitmqPwd) # 链接libvirt,libvirt是一个虚拟机、容器管理程序 def get_conn():
conn = libvirt.open('qemu:///system')
if conn == None:
print "Failed to open connection to QEMU/KVM" sys.exit(2) else:
return conn # 获取宿主机虚拟机running的数量
def getVMcount():
conn = get_conn()
domainIDs = conn.listDomainsID()
return len(domainIDs) # 获取分配给所有虚拟机的内存之和
def getMemoryused():
conn = get_conn()
domainIDs = conn.listDomainsID()
used_mem = 0
for id in domainIDs:
dom = conn.lookupByID(id)
used_mem += dom.maxMemory()/(1024*1024)
# used_mem = ''.join((str(used_mem),'G'))
return used_mem # 获取分配给所有虚拟机的内存之和
def getCPUused():
conn = get_conn()
domainIDs = conn.listDomainsID()
used_cpu = 0
for id in domainIDs:
dom = conn.lookupByID(id)
used_cpu += dom.maxVcpus()
return used_cpu # 获取所有虚拟机磁盘文件大小之和
def getDiskused(): conn = get_conn()
domainIDs = conn.listDomainsID()
diskused = 0 for id in domainIDs:
# 获取libvirt对象
dom = conn.lookupByID(id)
# 获取虚拟机xml描述配置文件
xml = dom.XMLDesc(0)
doc = minidom.parseString(xml)
disks = doc.getElementsByTagName('disk')
for disk in disks:
if disk.getAttribute('device') == 'disk':
diskfile = disk.getElementsByTagName('source')[0].getAttribute('file')
diskused += dom.blockInfo(diskfile,0)[0]/(1024**3)
return diskused # 使agent.py进入守护进程模式
def daemonize(stdin='/dev/null',stdout='/dev/null',stderr='/dev/null'):
try:
pid = os.fork()
if pid > 0:
sys.exit(0)
except OSError,e:
sys.stderr.write("fork #1 failed: (%d) %s\n" % (e.errno,e.strerror))
sys.exit(1)
os.chdir("/")
os.umask(0)
os.setsid()
try:
pid = os.fork()
if pid > 0:
sys.exit(0)
except OSError,e:
sys.stderr.write("fork #2 failed: (%d) %s\n" % (e.errno,e.strerror))
sys.exit(1)
for f in sys.stdout,sys.stderr,: f.flush()
si = file(stdin,'r')
so = file(stdout,'a+',0)
se = file(stderr,'a+',0)
os.dup2(si.fileno(),sys.stdin.fileno())
os.dup2(so.fileno(),sys.stdout.fileno())
os.dup2(se.fileno(),sys.stderr.fileno()) daemonize('/dev/null','/root/kvm/agent.log','/root/kvm/agent.log') connection = pika.BlockingConnection(pika.ConnectionParameters(host=RabbitmqHost,
credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange='kvm',type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 把随机queue绑定到exchange上
channel.queue_bind(exchange='kvm',queue=queue_name) # 定义回调函数
def on_request(channle,method,props,body):
sys.stdout.write(body+'\n')
sys.stdout.write("callback_queue : %s" %props.reply_to)
sys.stdout.flush()
mem_total = psutil.virtual_memory()[0]/(1024*1024*1024)
cpu_total = psutil.cpu_count()
statvfs = os.statvfs('/root')
disk_total = (statvfs.f_frsize * statvfs.f_blocks)/(1024**3)
print(type(mem_total))
print(type(getMemoryused()))
mem_unused = mem_total - getMemoryused()
cpu_unused = cpu_total - getCPUused()
disk_unused = disk_total - getDiskused()
data = {
'hostname': socket.gethostname(),
'vm' : getVMcount(),
'available_memory' : mem_unused,
'available_cpu' : cpu_unused,
'available_disk' : disk_unused,
}
json_str = json.dumps(data) # 把dict转换成str类型 # 服务器端回复client消息到callback_queue中
channel.basic_publish(exchange='',routing_key=props.reply_to,
properties=pika.BasicProperties(
correlation_id=props.correlation_id,
),
body=json_str,
)
channel.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request,queue=queue_name) sys.stdout.write('[x] Waiting PRC request\n')
sys.stdout.flush() channel.start_consuming()
root@ansible:~/workspace/RPC_TEST/RPC04# cat collent.py
#!/usr/bin/env python
# coding:utf-8 import pika
import uuid
import json
import datetime RabbitmqHost = '172.20.6.184'
RabbitmqUser = 'admin'
RabbitmqPwd = 'admin' credentials = pika.PlainCredentials(RabbitmqUser,RabbitmqPwd) class RpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host=RabbitmqHost,
credentials=credentials))
self.channel = self.connection.channel()
self.channel.exchange_declare(exchange='kvm', type='fanout')
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue self.channel.basic_consume(self.on_responses,no_ack=True,queue=self.callback_queue) self.responses = [] def on_responses(self,channel,method,props,body):
if self.corr_id == props.correlation_id:
self.responses.append(body) def call(self):
timestamp = datetime.datetime.strftime(datetime.datetime.now(),'%Y-%m-%dT%H:%M:%SZ')
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='kvm',routing_key='',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body='%s: receive a request.' %timestamp) # 定义超时回调函数
def outoftime():
self.channel.stop_consuming() self.connection.add_timeout(30,outoftime)
self.channel.start_consuming()
print "callback_queue : %s" %self.callback_queue
return self.responses rpc = RpcClient()
responses = rpc.call()
for i in responses:
response = json.loads(i)
print '[.] Got %r' %response
本文在前面演示的RPC都是只有一个服务端的情况,客户端发起请求后是用一个while循环来阻塞程序以等待返回结果的,当self.response不为None,就退出循环。
如果在多服务端的情况下照搬过来就会出问题,实际情况中我们可能有几十台宿主机,每台上面都运行了一个agent.py,当collect.py向几十个agent.py发起请求时,收到第一个宿主机的返回结果后就会退出上述while循环,导致后续其他宿主机的返回结果被丢弃。这里我选择定义了一个超时回调函数outoftime()来替代之前的while循环,超时时间设为30秒。collect.py发起请求后阻塞30秒来等待所有宿主机的回应。如果宿主机数量特别多,可以再调大超时时间。真是怕了,先这样结束吧。还有一个例子下篇写
地址原文:http://blog.51cto.com/3646344/2097020
RabbitMQ消息队列(九)RPC开始应用吧的更多相关文章
- RabbitMQ 消息队列 实现RPC 远程过程调用交互
#!/usr/bin/env python # Author:Zhangmingda import pika,time import uuid class FibonacciRpcClient(obj ...
- (转)RabbitMQ消息队列(九):Publisher的消息确认机制
在前面的文章中提到了queue和consumer之间的消息确认机制:通过设置ack.那么Publisher能不到知道他post的Message有没有到达queue,甚至更近一步,是否被某个Consum ...
- (转)RabbitMQ消息队列(七):适用于云计算集群的远程调用(RPC)
在云计算环境中,很多时候需要用它其他机器的计算资源,我们有可能会在接收到Message进行处理时,会把一部分计算任务分配到其他节点来完成.那么,RabbitMQ如何使用RPC呢?在本篇文章中,我们将会 ...
- RabbitMQ消息队列(九):Publisher的消息确认机制
在前面的文章中提到了queue和consumer之间的消息确认机制:通过设置ack.那么Publisher能不到知道他post的Message有没有到达queue,甚至更近一步,是否被某个Consum ...
- RabbitMQ消息队列(七):适用于云计算集群的远程调用(RPC)
在云计算环境中,很多时候需要用它其他机器的计算资源,我们有可能会在接收到Message进行处理时,会把一部分计算任务分配到其他节点来完成.那么,RabbitMQ如何使用RPC呢?在本篇 ...
- (九)RabbitMQ消息队列-通过Headers模式分发消息
原文:(九)RabbitMQ消息队列-通过Headers模式分发消息 Headers类型的exchange使用的比较少,以至于官方文档貌似都没提到,它是忽略routingKey的一种路由方式.是使用H ...
- RabbitMQ消息队列1: Detailed Introduction 详细介绍
1. 历史 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有 ...
- 使用EasyNetQ组件操作RabbitMQ消息队列服务
RabbitMQ是一个由erlang开发的AMQP(Advanved Message Queue)的开源实现,是实现消息队列应用的一个中间件,消息队列中间件是分布式系统中重要的组件,主要解决应用耦合, ...
- rabbitMQ消息队列1
rabbitmq 消息队列 解耦 异步 优点:解决排队问题 缺点: 不能保证任务被及时的执行 应用场景:去哪儿, 同步 优点:保证任务被及时的执行 缺点:排队问题 大并发 Web nginx 1000 ...
- RabbitMQ 消息队列 应用
安装参考 详细介绍 学习参考 RabbitMQ 消息队列 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. M ...
随机推荐
- 如何检测浏览器是否安装了Adblock,uBlock Origin,Adguard,uBlock等广告屏蔽插件
由于我们网站上的广告经常被一些广告插件给屏蔽掉,上级给我下达了一个检测浏览器是否安装了屏蔽广告的插件的任务. 经过研究,借鉴,参考,整合了如下三种解决方案. 方案一: 利用广告插件通过对含有goo ...
- Dictionary 初始化数据
Dictionary<string, string> dic = new Dictionary<string, string>() { { ...
- ruby中的链式访问和方法嵌套
先看一道题,这道题是codewars上的一道题,我很早就看到了,但是不会写.等到又看到这道题的时候,我刚看完元编程那本书,觉得是可以搞定它的时候了.废话不多说,先看这道题,题目最开始是为JavaScr ...
- split_lzo_lib.sh
split_lzo_lib.sh #!/bin/sh#输入文件名filename=$1#分割文件大小filesize=4096#输出库文件名libname="lib"$(echo ...
- 《Unity3D》通过对象池模式,管理场景中的元素
池管理类有啥用? 在游戏场景中,我们有时候会需要复用一些游戏物体,比如常见的子弹.子弹碰撞类,某些情况下,怪物也可以使用池管理,UI部分比如:血条.文字等等 这些元素共同的特性是:存在固定生命周期,使 ...
- 《UML和模式应用》读书笔记(一)面向对象分析和设计简单示例
在开始进行对象分析和设计之前,先通过“扔骰子”这个软件(游戏者扔两个骰子,如果总是是7,则赢,否则输),来简单分析下这个过程. 1:用例 需求分析,可能包括人们如何应用的场景或情节,这些都可以被编写成 ...
- centos7下配置iptables实现外网访问内网服务器
说明:Centos 7 默认的防火墙是 firewall,安装iptables之前需关闭Firewall 外网机器:外网ip:120.25.71.183内网ip:10.1.1.23 内网机器:内网ip ...
- hadoop 一些命令
关闭访问墙 service iptables stop hadoop dfs -mkdir input hadoop dfs -copyFromLocal conf/* input hadoop j ...
- I.MX6中PC连接开发板问题
修改板端的文件 添加登录密码: passwd vi /etc/network/interrfaces 在auto eth0下增加auto eth1 如果采用固定ip方式可以在后面增加一段固定ip设置 ...
- 搭建Firekylin博客
搭建步骤 1).安装 Node.js curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash - yum - ...