在Docker和Kubernetes上运行MongoDB微服务
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟。容器是完全使用沙箱机制,相互之间不会有任何接口。
本文介绍了利用Docker和Kubernetes搭建一套具有冗余备份集合的MongoDB服务,从容器对CI和CD引发的改变入手,讨论了容器技术对MongoDB带来的挑战和机会,然后实战如何部署一套稳定的MongoDB服务,非常的干货~
想尝试在笔记本电脑上运行MongoDB么?希望通过执行一个简单的命令,然后就有一个轻量级、自组织的沙盒么?并可再通过一条命令就可以移除所有的痕迹么?
需要在多个环境中运行相同的应用程序栈?创建自己的容器镜像,使得开发、测试、操作和支持团队启动一份完全相同的环境。
容器正在改变整个软件生命周期;它覆盖了从最初的技术试验到通过开发、测试、部署和支持的概念证明。
阅读微服务:容器和编排白皮书(https://www.mongodb.com/collateral/microservices-containers-and-orchestration-explained)。
编排工具管理着多个容器如何创建、升级和高可用。编排同样管理着容器如何连接,并利用多个微服务容器创建稳定的应用服务。
丰富的功能、简单的工具、强大的API让容器和编排得到DevOps团队的青睐。DevOps工程师将它们整合到持续集成(CI)和持续交付(CD)工作流中。
本篇文章将探索在尝试运行和编排MongoDB容器时遇到的问题,并描述如何克服这些问题。
采用容器和编排运行MongoDB带来了一些新的思考:
MongoDB数据库节点是有状态的。若一个容器挂了,并且被重新编排,数据丢失是不能接受的(虽然它可以从其他节点中恢复数据,但是很费时)。为解决这个问题,Kubernetes中的卷抽象(Volume abstraction)特性将用于映射MongoDB数据文件夹到一个持久化地址,避免容器的失败或重编排。
同一组MongoDB数据库备份节点之间需要通信,即使是在重编排之后。同一冗余备份集合的节点必须知道全部其他节点的地址,但是当某个容器重编排之后,它的IP地址会变化。例如,所有Kubernetes内的容器共享一个IP地址,当pod被重编排之后这个地址就会改变。在Kubernetes中,这个问题可以通过联系Kubernetes服务与MongoDB节点来解决,采用Kubernetes的DNS服务提供主机名给重编排之后的服务。
一旦每个独立的MongoDB节点(每个节点在单独容器中)启动起来,备份集合必须初始化,并把每个节点加入进来。这需要编排工具提供额外的逻辑。特别是备份集合中只有一个MongoDB节点时,必须执行rs.initiate和rs.add命令。
如果编排框架提供自动化重编排容器功能(如Kubernetes的特性),那么这可以提高MongoDB的容灾性,节点会在挂掉之后自动重新创建,恢复到完整冗余水平且不需要人工干预。
当编排框架掌控所有容器的状态时,它并不管理容器内的应用或者备份数据。这就意味着采用一个有效的管理和备份方案很重要,如MongoDB Cloud Manager,包括MongoDB Enterprise Advanced和MongoDB Professional两部分。考虑到需要创建镜像,可采用你倾向的MongoDB版本和MongoDB Automation Agent。
如前一节所述,MongoDB这类分布式数据库在利用编排框架(如Kubernetes)进行部署时需要额外考虑。本节将对这部分细节进行分析,并介绍如何实现。
首先,我们在一个单独的Kubernetes集群(同一个数据中心内,并不存在物理上的冗余备份)中创建整个MongoDB冗余集合。如果跨多个数据中心进行创建,其步骤也差异不大,后续将会介绍。
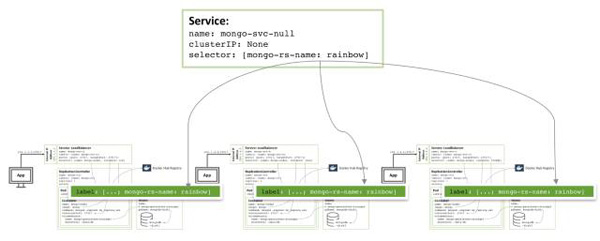
备份中的每个成员都运行在独自的pod中,只暴露其IP地址和端口。固定的IP地址对于外部应用和其他冗余备份节点非常重要,它决定了哪些pod将被重新部署。
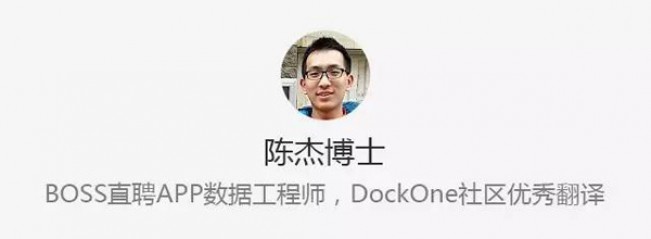
下图展示了其中一个pod与关联的冗余控制器和服务的关系。
深入这些配置中描述的资源,内容如下:
启动核心节点mongo-node1,该节点包括了一个叫做的mongo的镜像,来源于Docker Hub,其暴露27107端口。
Kubernetes的卷特性用于映射/data/db文件夹到持久化目录mongo-persistent-storage1;该目录为Google Cloud上创建的目录映射mongodb-disk1,用于持久化MongoDB的数据。
容器由pod进行管理,标记为mongo-node,同时对rod提供一个随机生成的名字。
冗余控制器命名为mongo-rc1,用于确保mongo-node1的实例一直处于运行中。
负载均衡服务命名为mongo-svc-a用27017暴露端口。该服务通过pod的标签匹配正确的服务到对应的pod上,对外暴露的ip和端口给应用程序使用,同时用于冗余备份集合中各节点的通信。虽然每个容器拥有内部ip,但是当容器被重启或者移动之后它们会变更,因此不能用于冗余备份集合之间的通信。
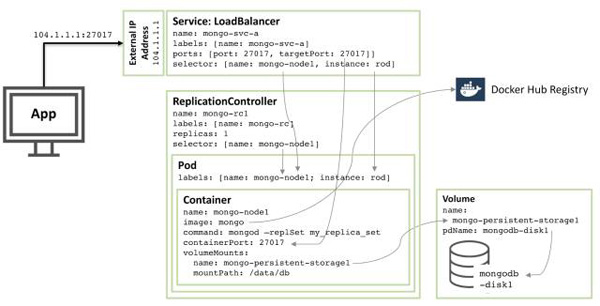
下图展示了冗余备份及中的另一个成员信息:
90%的配置是相同的,只有几处不同:
硬盘和卷的名字必须是唯一的,于是采用mongodb-disk2和mongo-persisitent-storage2
Pod分配到jane实例,同时节点命名为mongo-node2,用于区分新服务与图1中的Pod
冗余控制命名为mongo-rc2
服务命名为mongo-svc-b,并获取一个不同的外部IP地址(本例子中,Kubernets分配为104.1.4.5)
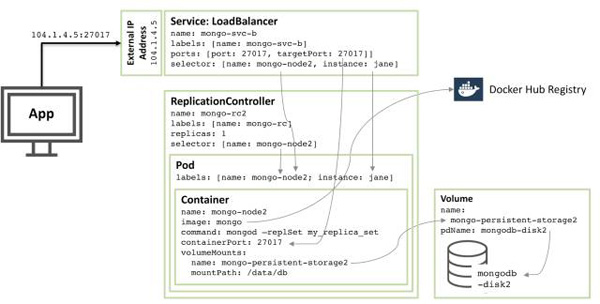
第三个冗余备份成员的配置仿照上述的模式进行,下图展示了完整的冗余配置集合:
注意,即使配置如图3一样,在一个三个或者多个节点的Kubernetes集群上,Kubernetes可能会调度两个或者多个MongoDB冗余备份成员在同一个宿主机上。这是因为Kubernetes将三个pod视为三个独立的服务。
为了增加冗余,需要创建一个额外的headless服务。该服务不具备提供外部服务的能力,甚至没有外部IP地址,但是它用于通知Kubernetes这三个MongoDB Pod是属于同一个服务,于是Kubernetes会将它们调度在不同的节点上。
具体的配置文件和相关操作命令可以从《启动微服务:容器&调度说明白皮书》中找到。其中包含了三个特殊的步骤确保合并三个MongoDB到一个功能中,即本文中描述的冗余备份。
所有冗余部件均运行在同一个GCE集群上时具有很高的风险,在同一个zone的集群也一样。如果发生一个重大事件导致可用zone离线,那么MongoDB冗余集合也就不可用。如果需要地理上的冗余备份,那么三个pod需要运行在不同的zone内。
只需要很少的改动就可以创建这样一个冗余备份集合。每一个集群需要独自的Kubernetes YAML文件来定义pod、冗余控制器和服务。然后,就可以完成一个zone的集群创建、持久化存储和MongoDB节点。
下图展示了运行在不同zone上的冗余结合:

本文转载地址:https://www.linuxprobe.com/docker-kubernetes-with-mangdb.html
在Docker和Kubernetes上运行MongoDB微服务的更多相关文章
- 在Kubernetes上运行SAP UI5应用(下): 一个例子体会Kubernetes内容器的高可用性和弹性伸缩
上一篇文章 在Kubernetes上运行SAP UI5应用(上),我介绍了如何在Docker里运行一个简单的SAP UI5应用,并且已经成功地将一个包含了这个UI5应用的docker镜像上传到Dock ...
- 在kubernetes上运行WASM负载
在kubernetes上运行WASM负载 WASM一般用在前端业务中,但目前有扩展到后端服务的趋势.本文使用Krustlet 将WASM服务部署到kubernetes. 简介 Krustlet 是一个 ...
- Docker在Linux上运行NetCore系列(一)配置运行DotNetCore控制台
转发请注明此文章作者与路径,请尊重原著,违者必究. 系列文章:https://www.cnblogs.com/alunchen/p/10121379.html 本篇文章操作系统信息 Linux:ubu ...
- 开始使用 Docker (Linux 上运行 SQL Server) 上的 SQL Server 容器 - SQL Server | Microsoft Docs
原文:开始使用 Docker (Linux 上运行 SQL Server) 上的 SQL Server 容器 - SQL Server | Microsoft Docs 快速入门:使用 Docker ...
- 「在 Kubernetes 上运行 Pgpool-Il」实现 PostgreSQL 查询(读)负载均衡和连接池
介绍如何在 Kubernetes 上运行 Pgpool-II 实现 PostgreSQL 读查询负载均衡和连接池. 介绍 因为 PostgreSQL 是一个有状态的应用程序,并且管理 PostgreS ...
- Kubernetes实战 - 从零开始搭建微服务 1 - 使用kind构建一个单层架构Node/Express网络应用程序
使用kind构建一个单层架构Node/Express网络应用程序 Kubernetes实战-从零开始搭建微服务 1 前言 准备写一个Kubernetes实战系列教程,毕竟cnblogs作为国内最早的技 ...
- Kubernetes实战 - 从零开始搭建微服务 - 1.5 提高可用性-发布多节点的Node/Express网络应用程序
1.5 提高可用性-发布多节点的Node/Express网络应用程序 Kubernetes实战 - 从零开始搭建微服务 前言 在上一篇文章中,已经学习了如何简单地开发一个单层网络应用.[Kuberne ...
- 在Kubernetes上运行SAP UI5应用(上)
2018年只剩最后30天了.Jerry在2017年的最后一天,曾经立下一个目标:这个微信公众号在2018年保证至少每周发布一篇SAP原创技术文章. 从Jerry在后台统计的2018全年文章数量来看,这 ...
- 在 Kubernetes 上运行高可用的 Kafka 集群
转载自:https://www.qikqiak.com/post/deploy-kafka-ha-on-k8s/ Apache Kafka 是目前最流行的分布式消息发布订阅系统,虽然 Kafka 非常 ...
随机推荐
- Python并发编程-队列
队列 IPC = Inter-Process Communication 队列 先进先出 队列的几种方法 #put() #full() #get() #empty() #get-nowait() fr ...
- 在树莓派3B上安装node.js
本文主讲如何在树莓派3B上安装node.js 环境描述1. 树莓派安装了`2016-11-25-raspbian-jessie-lite`(PS:在此版本的镜像中,默认禁用了ssh,在烧录好镜像之后, ...
- 01-学前入门.Net 能做什么
桌面应用程序 Winfrom(.Net开发的桌面应用程序叫Winfrom应用程序) Internet应用程序 ASP.NET (.Net开发的Internet应用程序叫ASP.N ...
- 2016 湖南省省赛B题《有向无环图》
题目链接[https://vjudge.net/problem/CSU-1804] 题意: 给出一个有向无环图,然后让你算下面的结果,count(i,j)表示i->j之间的路径条数. 题解: 根 ...
- 【UOJ #107】【APIO 2013】ROBOTS
http://uoj.ac/problem/107 设\(f(l,r,i,j)\)表示\([l,r]\)中的机器人聚集到\((i,j)\)需要花的最小操作数. \(f(l,r,i,j)=\min\le ...
- [CODE FESTIVAL 2018]Sushi Restaurant
题意:有$n$个人,对每个人,他有$p_i$的概率饥饿值为$x_i$($1\leq i\leq m$),你现在要做$n$盘寿司,每盘寿司有一定的数量,当这$n$个人的饥饿值确定后他们会自己选择最优的( ...
- 【最小割】【Dinic】HihoCoder - 1252 - The 2015 ACM-ICPC Asia Beijing Regional Contest - D - Kejin Game
题意:有一个技能学习表,是一个DAG,要想正常学习到技能x,要将指向x的技能全部先学到,然后会有一个正常花费cx.然后你还有一种方案,通过氪金dx直接获得技能x.你还可以通过一定的代价,切断一条边.问 ...
- Java 基础总结--反射的基本操作
一.反射的概念 JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性:这种动态获取的信息以及动态调用对象的方法的功能称为 ...
- Spark参数配置总结
- iOS 画圆
_demoView = [[UIView alloc] initWithFrame:CGRectMake(100, 100, 100, 100)]; [self.view addSubview:_de ...