flink学习笔记:DataSream API
本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1.执行计划Graph
Flink 通过Stream API (Batch API同理)开发的应用,底层有四层执行计划,我们首先来看Flink的四层执行计划如下图所示。
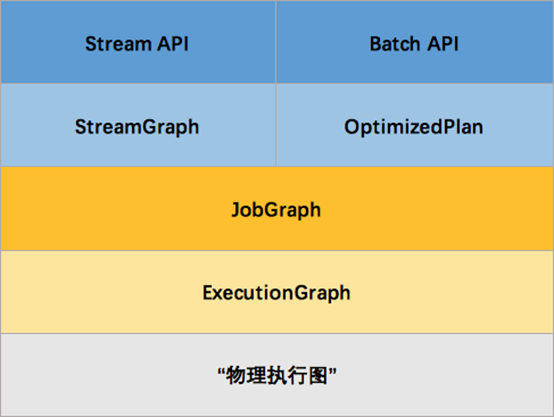
通过Stream API开发的Flink应用,底层首先转换为StreamGraph,然后再转换为JobGraph,接着转换为ExecutionGraph,最后生成“物理执行图”。
StreamGraph
1.根据用户代码生成最初的图
2.它通过类表示程序的拓扑结构
3.它是在client端生成
JobGraph
1.优化streamgraph
2.将多个符合条件的Node chain在一起
3.在client端生成,然后交给JobManager
ExecutionGraph
JobManger根据JobGraph 并行化生成ExecutionGraph
物理执行图
实际执行图,不可见
1.1 StreamGraph
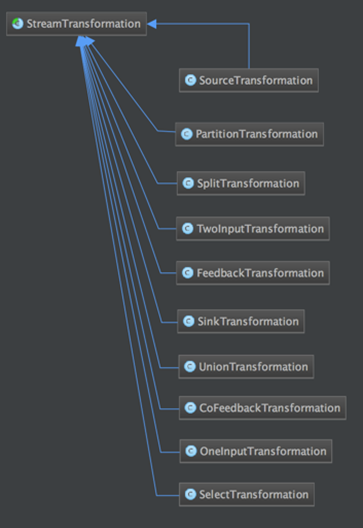
StreamGraph
通过Stream API提交的文件,首先会被翻译成StreamGraph。StreamGraph的生成的逻辑是在StreamGraphGenerate类的generate方法。而这个generate的方法又会在StreamExecutionEnvironment.execute方法被调用。
1.env中存储 List<StreamTransformation<?> ,里面存储了各种算子操作。
2.StreamTransformation(是一个类)
a)它描述DataStream之间的转化关系 。
b)它包含了StreamOperator/UDF 。
c)它包含了很多子类,比如OneInputTransformation/TwoInputTransform/ SourceTransformation/ SinkTransformation/ SplitTransformation等。
3.StreamNode/StreamEdge
StreamNode(算子)/StreamEdge(算子与算子之间的联系)是通过StreamTransformation来构造。
1.2 StreamGraph转JobGraph
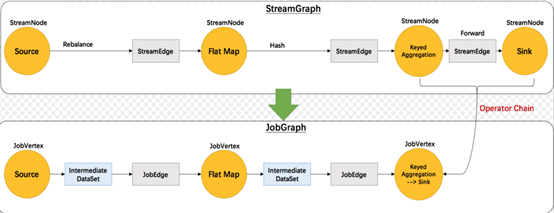
1.3 JobGraph
从StreamGraph到JobGraph转换过程中,内部角色也会进行转换
1.StreamNode->JobVertex:StreamNode转换为JobVertex
2.StreamEdge->JobEdge:StreamEdge转换为JobEdge
3.将符合条件的StreamNode chain成一个JobVertex(顶点)
a)没有禁用Chain
b)上下游算子并行度一致
c)下游算子的入度为1(也就是说下游节点没有来自其他节点的输入)
d)上下游算子在同一个slot group下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
e)上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
f)上下游算子之间没有数据shuffle (数据分区方式是 forward)
4.根据group指定JobVertex所属SlotSharingGroup
5.配置checkpoint策略
6.配置重启策略
1.4 JobGraph -> ExecutionGraph
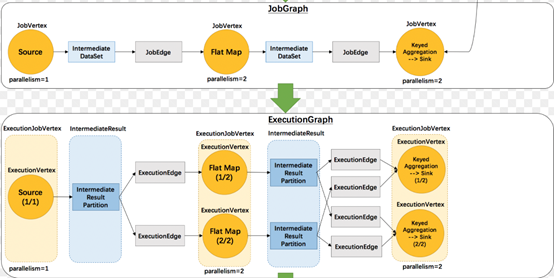
1.5 ExecutionGraph
从JobGraph转换ExecutionGraph的过程中,内部会出现如下的转换。
1.ExecutionJobVertex <- JobVertex:JobVertex转换为ExecutionJobVertex 。
2.ExecutionVertex(比如map)可以并发多个任务。
3.ExecutionEdge <- JobEdge:JobEdge转换为ExecutionEdge。
4.ExecutionGraph 是一个2维结构。
5.根据2维结构分发对应Vertex到指定slot 。
2. DataStreamContext
Flink通过StreamExecutionEnvironment.getExecutionEnvironment()方法获取一个执行环境,Flink引用是在本地执行,还是以集群方式执行,系统会自动识别。如果是本地执行会调用createLocalEnvironment()方法,如果是集群执行会调用createExecutionEnvironment()。
3. 数据源(DataSource)
Flink数据源可以有两种实现方式:
1.内置数据源
a)基于文件
b)基于Socket
c)基于Collection
2.自定义数据源
a)实现SourceFunction(非并行的)
b)实现ParallelSourceFunction
c)继承RichParallelSourceFunction
public class SimpleSourceFunction implements ParallelSourceFunction<Long> {
private long num = 0L;
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<Long> sourceContext) throws Exception {
while (isRunning) {
sourceContext.collect(num); num++;
Thread.sleep(10000);
}
}
@Override
public void cancel() {
isRunning = false;
}
}
4. Transformation
Transformation(Operators/操作符/算子):可以将一个或多个DataStream转换为新的DataStream。

5. DataSink
Flink也包含两类Sink:
1.常用的sink会在后续的connectors中介绍。
2.自定义Sink
自定义Sink可以实现SinkFunction 接口,也可以继承RichSinkFunction。
6. 流式迭代运算(Iterations)
简单理解迭代运算:
当前一次运算的输出作为下一次运算的输入(当前运算叫做迭代运算)。不断反复进行某种运算,直到达到某个条件才跳出迭代(是不是想起了递归)
流式迭代运算:
1.它没有最大迭代次数
2.它需要通过split/filter转换操作指定流的哪些部分数据反馈给迭代算子,哪些部分数据被转发到下游DataStream
3.基本套路
1)基于输入流构建IterativeStream(迭代头)
2)定义迭代逻辑(map fun等)
3)定义反馈流逻辑(从迭代过的流中过滤出符合条件的元素组成的部分流反馈给迭代头进行重复计算的逻辑)
4)调用IterativeStream的closeWith方法可以关闭一个迭代(也可表述为定义了迭代尾)
5)定义“终止迭代”的逻辑(符合条件的元素将被分发给下游而不用于进行下一次迭代)
4.流式迭代运算实例
问题域:输入一组数据,我们对他们分别进行减1运算,直到等于0为止.
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.IterativeStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @Author: lifei
* @Date: 2018/12/16 下午6:43
*/
public class IterativeStreamJob {
public static void main(String[] args) throws Exception {
//输入一组数据,我们对他们分别进行减1运算,直到等于0为止
final StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input=env.generateSequence(0,100);//1,2,3,4,5
//基于输入流构建IterativeStream(迭代头)
IterativeStream<Long> itStream=input.iterate();
//定义迭代逻辑(map fun等)
DataStream<Long> minusOne=itStream.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value-1;
}
});
//定义反馈流逻辑(从迭代过的流中过滤出符合条件的元素组成的部分流反馈给迭代头进行重复计算的逻辑)
DataStream<Long> greaterThanZero=minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value>0;
}
});
//调用IterativeStream的closeWith方法可以关闭一个迭代(也可表述为定义了迭代尾)
itStream.closeWith(greaterThanZero);
//定义“终止迭代”的逻辑(符合条件的元素将被分发给下游而不用于进行下一次迭代)
DataStream<Long> lessThanZero=minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return value<=0;
}
});
lessThanZero.print();
env.execute("IterativeStreamJob");
}
}
7. Execution参数
Controlling Latency(控制延迟)
1.默认情况下,流中的元素并不会一个一个的在网络中传输(这会导致不必要的网络流量消耗),而是缓存起来,缓存的大小可以在Flink的配置文件、 ExecutionEnvironment、设置某个算子上进行配置(默认100ms)。
1)好处:提高吞吐
2)坏处:增加了延迟
2.如何把握平衡
1)为了最大吞吐量,可以设置setBufferTimeout(-1),这会移除timeout机制,缓存中的数据一满就会被发送
2)为了最小的延迟,可以将超时设置为接近0的数(例如5或者10ms)
3)缓存的超时不要设置为0,因为设置为0会带来一些性能的损耗
3.其他更多的Execution参数后面会有专题讲解
8. 调试
对于具体开发项目,Flink提供了多种调试手段。Streaming程序发布之前最好先进行调试,看看是不是能按预期执行。为了降低分布式流处理程序调试的难度,Flink提供了一些列方法:
1.本地执行环境
2.Collection Data Sources
3.Iterator Data Sink
本地执行环境:
本地执行环境不需要刻意创建,可以断点调试
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
DataStream<String> lines = env.addSource(/* some source */);
env.execute();
Collection Data Sources:
Flink提供了一些Java 集合支持的特殊数据源来使得测试更加容易,程序测试成功后,将source和sink替换成真正source和sink即可。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();
env.fromElements(1, 2, 3, 4, 5);
env.fromCollection(Collection);
env.fromCollection(Iterator, Class);
env.generateSequence(0, 1000)
Iterator Data Sink:
Flink提供一个特殊的sink来收集DataStream的结果
DataStream<Tuple2<String, Integer>> myResult = ...
Iterator<Tuple2<String, Integer>> myOutput = DataStreamUtils.collect(myResult)

flink学习笔记:DataSream API的更多相关文章
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Java学习笔记之---API的应用
Java学习笔记之---API的应用 (一)Object类 java.lang.Object 类 Object 是类层次结构的根类.每个类都使用 Object 作为超类.所有对象(包括数组)都实现这个 ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记-flink实战
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记-支持的数据类型
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记-新一代Flink计算引擎
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink Runtime
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators串烧
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators之Process Function
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- Struts2分模块开发
-------------------siwuxie095 Struts2 分模块开发 在实际开发中,如果一个项目是团队开发的,也就是很多人开发的, 每个人都需要去修改 struts.xml,因为 s ...
- Kubuntu上截屏的小技巧
Kubuntu上自带了截屏软件ksnapshot,只需要按Print Screen就会自动调起,实际上挺方便的:但是,Print Screen的默认行为是截下整个屏幕,这往往不是我们需要的. 实际上, ...
- Nginx 事件基本处理流程分析
说明:本文章重点关注事件处理模型.有兴趣的同学可以去http://tengine.taobao.org/book/查找更多资料.Tengine应该是淘宝基于Nginx自己做的修改.这个地址的文档还在不 ...
- HBase数据读写流程(1.3.1)
===数据写入流程=== 源码:https://github.com/apache/hbase/blob/master/hbase-server/src/main/java/org/apache/ha ...
- 1256 Anagram
题目链接: http://poj.org/problem?id=1256 题意: 根据自定义的字典序: 'A'<'a'<'B'<'b'<...<'Z'<'z' 和输 ...
- python 网络编程 TCP/IP socket UDP
TCP/IP简介 虽然大家现在对互联网很熟悉,但是计算机网络的出现比互联网要早很多. 计算机为了联网,就必须规定通信协议,早期的计算机网络,都是由各厂商自己规定一套协议,IBM.Apple和Micro ...
- Ubuntu下安装配置ScrumWorks
1) 安装JDK6 Ubuntu默认的是OpenJDK,而ScrumWorks不支持使用OpenJDK哦,一次必须装个Oracle的JDK6 2) 下载安装Mysql5 http://dev.my ...
- 用Collections升降排序
//期末从业人员 总收入 资产总计等 升降 排序 if("qmcyry".equals(sss)){ if("desc".equals(orders)){ Co ...
- 大前端涉猎之前后端交互总结1: 软件架构与PHP搭建
1 软件架构与PHP搭建 1.1 HTTP服务器(web服务器) 即( web服务器 )网站服务器,主要提供文档(文本.图片.视频.音频)web浏览服务,一般安装Apache.Nginx服务器软件. ...
- Hadoop(分布式系统基础架构)---Hive与HBase区别
对于刚接触大数据的用户来说,要想区分Hive与HBase是有一定难度的.本文将尝试从其各自的定义.特点.限制.应用场景等角度来进行分析,以作抛砖引玉之用. Hive是什么? Apache Hive是 ...