Apache Spark简单介绍、安装及使用
Apache Spark安装及配置(OS X下的Ubuntu虚拟机)
安装 Anaconda
bash Anaconda2-4.1.1-Linux-x86_64.sh
$ sudo apt-get install software-properties-common
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer
设置JAVA_HOME
gedit .bashrc
JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JAVA_HOME
PATH=$PATH:$JAVA_HOME
export PATH
$ tar -zxvf spark-2.0.0-bin-hadoop2.7.tgz
$ rm spark-2.0.0-bin-hadoop2.7.tgz
gedit .bashrc
export PYSPARK_DRIVER_PYTHON=ipython
export PYSPARK_DRIVER_PYTHON_OPTS=notebook
cd ~/spark-2.0.0-bin-hadoop2.7
./bin/pyspark
Apache Spark简单使用
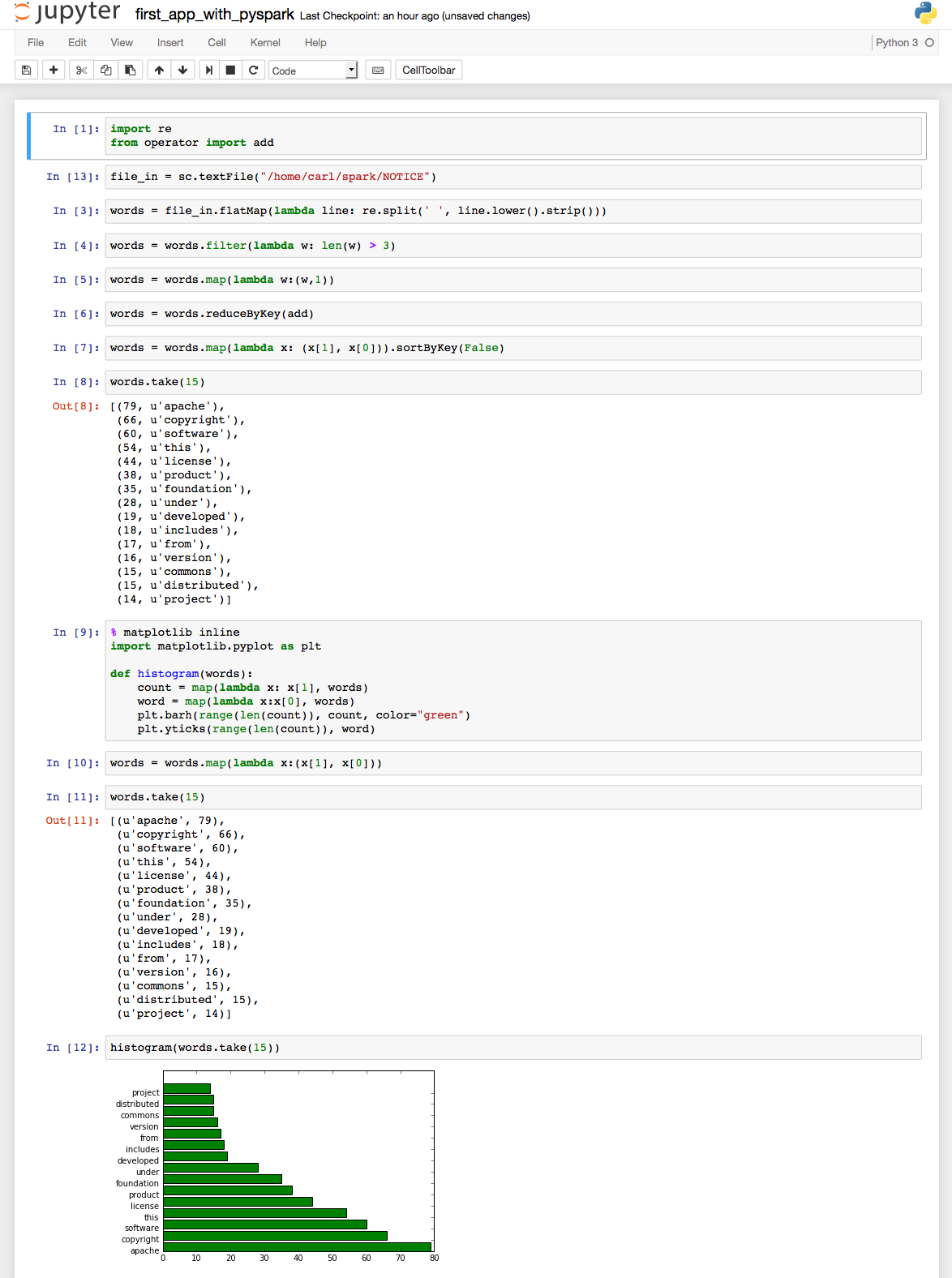
# coding: utf-8 # In[1]: import re
from operator import add # In[13]: file_in = sc.textFile("/home/carl/spark/NOTICE") # In[3]: words = file_in.flatMap(lambda line: re.split(' ', line.lower().strip())) # In[4]: words = words.filter(lambda w: len(w) > 3) # In[5]: words = words.map(lambda w:(w,1)) # In[6]: words = words.reduceByKey(add) # In[7]: words = words.map(lambda x: (x[1], x[0])).sortByKey(False) # In[8]: words.take(15) # In[9]: get_ipython().magic(u'matplotlib inline')
import matplotlib.pyplot as plt def histogram(words):
count = map(lambda x: x[1], words)
word = map(lambda x:x[0], words)
plt.barh(range(len(count)), count, color="green")
plt.yticks(range(len(count)), word) # In[10]: words = words.map(lambda x:(x[1], x[0])) # In[11]: words.take(15) # In[12]: histogram(words.take(15))
如果你对网络爬虫感兴趣,请查看另一篇随笔: 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
Apache Spark简单介绍、安装及使用的更多相关文章
- Spark简单介绍,Windows下安装Scala+Hadoop+Spark运行环境,集成到IDEA中
一.前言 近几年大数据是异常的火爆,今天小编以java开发的身份来会会大数据,提高一下自己的层面! 大数据技术也是有很多: Hadoop Spark Flink 小编也只知道这些了,由于Hadoop, ...
- Mongodb简单介绍安装
具体详细内容,请查阅 Mongodb官方文档 一.简单介绍 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性能. M ...
- Apache Flume的介绍安装及简单案例
概述 Flume 是 一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件.Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink).为了保证 ...
- 在linux上安装elasticsearch简称ES 简单介绍安装步骤
1.简介 Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 ...
- Spark(二) -- Spark简单介绍
spark是什么? spark开源的类Hadoop MapReduce的通用的并行计算框架 spark基于map reduce算法实现的分布式计算 拥有Hadoop MapReduce所具有的优点 但 ...
- Apache Shiro简单介绍
1. 概念 Apache Shiro 是一个开源安全框架,提供身份验证.授权.密码学和会话管理.Shiro 框架具有直观.易用等特性,同时也能提供健壮的安全性,虽然它的功能不如 SpringSecur ...
- web服务的简单介绍及apache服务的安装
一,web服务的作用: 是指驻留于因特网上某种类型计算机的程序,可以向浏览器等Web客户端提供文档.可以放置网站文件,让全世界浏览: 可以放置数据让全世界下载.目前最主流的三个Web服务器是Ap ...
- 3.如何安装Apache Spark
如何安装Apache Spark 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹 ...
- 分享一个.NET平台开源免费跨平台的大数据分析框架.NET for Apache Spark
今天早上六点半左右微信群里就看到张队发的关于.NET Spark大数据的链接https://devblogs.microsoft.com/dotnet/introducing-net-for-apac ...
随机推荐
- 高性能IO模型浅析
高性能IO模型浅析 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking ...
- 解决cookie跨域访问
一.前言 随着项目模块越来越多,很多模块现在都是独立部署.模块之间的交流有时可能会通过cookie来完成.比如说门户和应用,分别部署在不同的机器或者web容器中,假如用户登陆之后会在浏览器客户端写入c ...
- WebGIS中等值线前端生成绘制简析
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 等值线是GIS制图中常见的功能,一般有两种思路:一种是先进行插 ...
- 程序猿都没对象,JS竟然有对象?
现在做项目基本是套用框架,不论是网上的前端还是后端框架,也会寻找一些封装好的插件拿来即用,但还是希望拿来时最好自己过后再回过头了解里面的原理,学习里面优秀的东西,不论代码封装性,还是小到命名. 好吧, ...
- [EasyUI美化换肤]更换EasyUi图标
前言 本篇文章主要是记录一些换EasyUI皮肤的过程,备忘.也欢迎美工大神各路UI给点好意见,EasyUI我就不介绍了,自行百度吧..(So..所以别问我是不是响应式..本身EasyUI就不是响应式. ...
- bzoj1901--树状数组套主席树
树状数组套主席树模板题... 题目大意: 给定一个含有n个数的序列a[1],a[2],a[3]--a[n],程序必须回答这样的询问:对于给定的i,j,k,在a[i],a[i+1],a[i+2]--a[ ...
- 纯javaScript、jQuery实现个性化图片轮播
纯javaScript实现个性化图片轮播 轮播原理说明<如上图所示>: 1. 画布部分(可视区域)属性说明:overflow:hidden使得超出画布部分隐藏或说不可见.position: ...
- Atitit.如何建立研发体系
Atitit.如何建立研发体系 组织,流程,prj..Mana oppm 发管理是一个完整的管理体系,从结构上来讲,它主要由四个方面的内容构架而成:组织结构与岗位设置 管理流程与工作流程..项目及管 ...
- hibernate-mapping-3.0.dtd;hibernate-configuration-3.0.dtd;hibernate.properties所在路径
hibernate-mapping-3.0.dtd 所在路径:hibernate-release-5.2.5.Final\project\hibernate-core\src\main\resourc ...
- 我的MYSQL学习心得(七) 查询
我的MYSQL学习心得(七) 查询 我的MYSQL学习心得(一) 简单语法 我的MYSQL学习心得(二) 数据类型宽度 我的MYSQL学习心得(三) 查看字段长度 我的MYSQL学习心得(四) 数据类 ...