Python拼接多张图片

写机器学习相关博文,经常会碰到很多公式,而Latex正式编辑公式的利器。目前国内常用的博客系统,好像只有博客园支持,所以当初选择落户博客园。我现在基本都是用Latex写博文,然后要发表到博客园上与大家共享,就又得经历一番功夫:首先,将Latex源码拷贝到博文的HTML源码编辑器中;然后,修改部分HTML不支持的Latex源码,使得最后的博文跟我生成的PDF文档几乎一摸一样。这里面设计到图标的引用,论文的引用,文字颜色的调整,部分段落的标号等一些列问题。一旦文档有些长了,做这些工作就挺让人郁闷的。最讨厌的是,发现最后修改完工的HTML显示出来的文章也很部美观,而且文字大小和标题什么的也会随着博客主题的变化而变化,就美观性而言完全比不上Latex生成的PDF。对于我这种比较挑剔的人,我还希望看到的东西都是很美的,即便是博文!人嘛,都是有惰性的,我愿意跟大家分享学习的心得,但是不想把太多时间浪费在这些琐碎的事情上面。
人都是有惰性的,请原谅我总是有那么些偷懒的点子。那么如何非常便捷的将PDF文档的内容与大家共享呢?貌似没有博客支持直接浏览PDF文档的,但是几乎所有博客都支持图片。所以,我们可以用Adobe之类的软件将PDF转成JPG或PNG等格式的图片,但是转换得到的是每一页PDF对应一张图片。我甚至懒得将那十几页的图片一个个上传到博文中,然后如图图片大小不合适的话还得挨个调整,着实没有这个耐心啦!我希望可以直接有个工具帮我合并这些所有的图片。想了想,貌似没有现成的工具可用用。不过好像不难,自己完全可以搞定的。上述这些原因,也就促成了这篇短小的博文。
我计划以后的博文都如下操作:
- 用Latex写原始博文,生成PDF文档;
- 将PDF转成高清的PNG格式的图片;
- 将多个PNG格式的图片合并成一大张图片;
- 将最终的大图片直接上传到博文编辑器中
- 啊哈,大功告成!
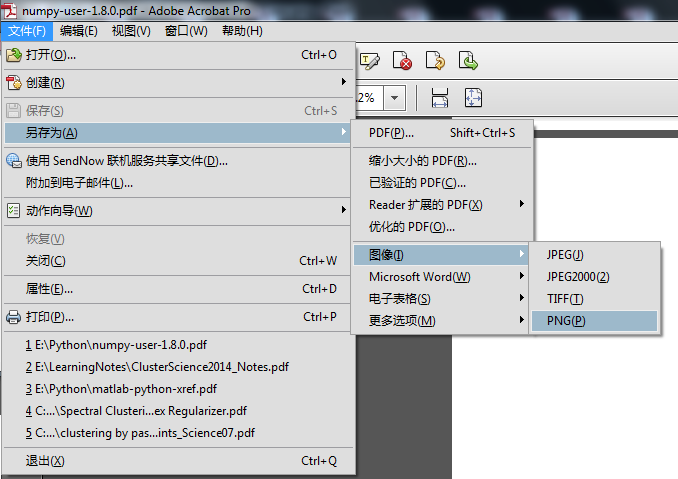
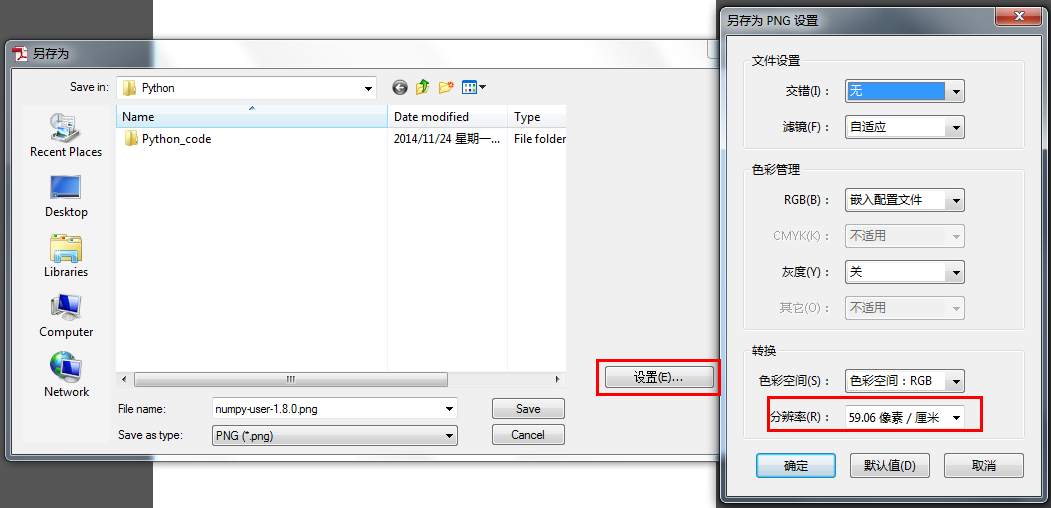
如何将PDF文档转换成其他的图片格式呢?我建议windowns下可用Adobe Acrobat X Pro软件完成这个工作,操作步骤如下面两图所示。注意在图二中一定要自己指定一个分辨率,不用用自动的,否则生成的图片大小会有差异的。就我的多次尝试来看,分辨率设置得太大了,虽然图片放大后仍然很清晰,但是贴到博文中仍然需要不断地调整大小,选择“59.06像素/厘米”就非常合适了;彩色空间最好还是选择RGB吧,如果选自动的生成的图片的通道数目可能会不一样。需要注意的是,博客的主题要选那种供博文显示的页面比较宽的,否则贴图片上去也不怎么好看的。这样做的弊端在哪呢?最明显的就是其他用户通过搜索引擎查找某些关键词的方式搜到博文的概率要降低很多。弥补的方式就是把博文的摘要、标题和Tag信息好好写一下,尤其是摘要部分。
将PDF文档用Adobe Acrobat X Pro另存为图片后,就会在PDF文档所在的目录下生成一系列的名为“PDFfilename_页面_XX.png"的一系列图片。我们接下来的任务就是要将这些图片合并成一张图片。我选用了强大便捷的Python来完成这项任务。刚开始用matplotlib库来操作,可是最终发现matplotlib中的保存图片的函数(无论是Image.imsave()还是pyplot.imsave())都有一定的限制,那就是图片的长或宽都不能超过32768。这个限制让我很不满意,继续尝试其他的图像操作的库,最终发现PIL库不存在这个限制,问题也得到了解决。下面这段Python代码默认所有图片对应的顺序是文件名末尾序号的升序,序号可以不连续,能处理的图片名字必须是形如xx_1.png ... xx_100.png或者xx_001.png ... xx_100.png。最后短小精悍的Python代码如下:
#!/usr/bin/python3
#encoding=utf-8 import numpy as np
from PIL import Image
import glob,os if __name__=='__main__':
prefix=input('Input the prefix of images:')
files=glob.glob(prefix+'_*')
num=len(files) filename_lens=[len(x) for x in files] #length of the files
min_len=min(filename_lens) #minimal length of filenames
max_len=max(filename_lens) #maximal length of filenames
if min_len==max_len:#the last number of each filename has the same length
files=sorted(files) #sort the files in ascending order
else:#maybe the filenames are:x_0.png ... x_10.png ... x_100.png
index=[0 for x in range(num)]
for i in range(num):
filename=files[i]
start=filename.rfind('_')+1
end=filename.rfind('.')
file_no=int(filename[start:end])
index[i]=file_no
index=sorted(index)
files=[prefix+'_'+str(x)+'.png' for x in index] print(files[0])
baseimg=Image.open(files[0])
sz=baseimg.size
basemat=np.atleast_2d(baseimg)
for i in range(1,num):
file=files[i]
im=Image.open(file)
im=im.resize(sz,Image.ANTIALIAS)
mat=np.atleast_2d(im)
print(file)
basemat=np.append(basemat,mat,axis=0)
final_img=Image.fromarray(basemat)
final_img.save('merged.png')
Python拼接多张图片的更多相关文章
- 使用python拼接多张图片.二三事
前几日在博客上看到一篇“使用python拼接多张图片”的Blog[具体是能将的图片名字必须是形如xx_1.png ... xx_100.png或者xx_001.png ... xx_100.png,拼 ...
- 使用Python拼接多张图片
写机器学习相关博文,经常会碰到很多公式,而Latex正式编辑公式的利器.目前国内常用的博客系统,好像只有博客园支持,所以当初选择落户博客园.我现在基本都是用Latex写博文,然后要发表到博客园上与大家 ...
- 如何用python下载一张图片
如何用python下载一张图片 这里要用到的主要工具是requests这个工具,需要先安装这个库才能使用,该库衍生自urllib这个库,但是要比它更好用.多数人在做爬虫的时候选择它,是个不错的选择. ...
- python拼接字符串方法汇总
python拼接字符串一般有以下几种方法: 1.直接通过(+)操作符拼接 s = 'Hello'+' '+'World'+'!' print(s) 输出结果:Hello World! 这种方式最常用. ...
- python拼接字符串
python拼接字符串一般有以下几种方法: 1.直接通过(+)操作符拼接 s = 'Hello' + ' ' + 'World' + '!' print(s) 输出结果:Hello World! 使用 ...
- Python拼接字符串的七种方式
忘了在哪看到一位编程大牛调侃,他说程序员每天就做两件事,其中之一就是处理字符串.相信不少同学会有同感. 几乎任何一种编程语言,都把字符串列为最基础和不可或缺的数据类型.而拼接字符串是必备的一种技能.今 ...
- Python 拼接字符串的几种方式
在学习Python(3x)的过程中,在拼接字符串的时候遇到了些问题,所以抽点时间整理一下Python 拼接字符串的几种方式. 方式1,使用加号(+)连接,使用加号连接各个变量或者元素必须是字符串类型( ...
- Python将多张图片进行合并拼接
import PIL.Image as Image import os IMAGES_PATH = r'D:\pics22223\\' # 图片集地址 IMAGES_FORMAT = ['.jpg', ...
- python拼接变量、字符串的3种方法
第一种,加号(“+”): print 'py'+'thon' # output python str = 'py' print str+'thon' # output python 第二种 ,空格: ...
随机推荐
- 有关SQLite的substr函数的笔记
官方参考文档:SQLite Query Language: Core Functions http://www.sqlite.org/lang_corefunc.html 测试SQL语句: ,) AS ...
- IAR编译信息分析
1.怎么设置可以查看单片的内存(消耗)使用状况? IAR的菜单栏 -->Tools -->IDE Options -->Messages -->Show build messa ...
- VS中使用QT调用R脚本
一开始想直接把R编译成库然后调用R,后来查了n多资料,发现VS中是无法办到的,官方也给出了一句话,大概意思就是没可能在VS中使用R提供的C++接口,大概是涉及到了底层的ABI的原因,具体也不太清楚. ...
- bzoj 3620 似乎在梦中见过的样子(KMP)
[题目链接] http://www.lydsy.com/JudgeOnline/problem.php?id=3620 [题意] 给定一个字符串,统计有多少形如A+B+A的子串,要求A>=K,B ...
- ***JAVA多线程的应用场景和应用目的举例
多线程使用的主要目的在于: 1.吞吐量:你做WEB,容器帮你做了多线程,但是他只能帮你做请求层面的.简单的说,可能就是一个请求一个线程.或多个请求一个线程.如果是单线程,那同时只能处理一个用户的请求. ...
- [Hive - LanguageManual] Hive Concurrency Model (待)
Hive Concurrency Model Hive Concurrency Model Use Cases Turn Off Concurrency Debugging Configuration ...
- J2SE7规范_2013.2_类型_命名
3.1 字面量:包括整型,实型,字符,字符串,布尔,null 整形: 除非后面有个l或L,一般总是int类型 除非是0x,0,0b开头,一般总是十进制 无论什么进制,中间都可以有_,无意义,只是看 ...
- 安装 RabbitMQ C#使用-摘自网络(包括RabbitMQ的配置)
1.什么是RabbitMQ.详见 http://www.rabbitmq.com/ . 作用就是提高系统的并发性,将一些不需要及时响应客户端且占用较多资源的操作,放入队列,再由另外一个线程,去异步处理 ...
- linux 系统常用命令
临时性的完全关闭防火墙,可以不重启机器: #/etc/init.d/iptables status ##查看防火墙状态 #/etc/init.d/iptable stop ...
- 第二百三十七天 how can I 坚持
最近好像迷上看小说了,<灵域>,而且也感觉会看小说了. 话说,今天好冷啊,真怕在路上冻着就冻萌了,寒风赤骨啊. 好想买个帽子.好想让送个帽子. 睡觉.