使用Lucene.net提升网站搜索速度整合记录
1.随着网站数据量达到500万条的时候,发现SQL数据库如果使用LIKE语句来查询,总是占用CPU很忙,不管怎么优化,速度还是上不来;
2.经过网上收集资料,HUBBLE.net目前虽然做得不错,但需要配置内存给他,由于服务器4G内存,而且运行了好几个网站,所以考虑采用Lucene.net来做为搜索引擎;
3.虽然本地测试没有问题,但是部署到64位的服务器上还是经过了好几天的折腾,在此都记录一下.
在此记录搜片神器的整个开发过程中遇到的问题和相关的解决方案,希望大家一起交流.
Lucene软件下载编译整合的问题
网站采用了最新Lucene.Net.3.0.3版本的代码,然后配置盘古分词来进行.
由于Lucene.Net升级到了3.0.3后接口发生了很大变化,原来好多分词库都不能用了,
.Net下还有一个盘古分词(http://pangusegment.codeplex.com/),但也不支持Lucene.Net 3.0.3,园子里的大哥们修改的项目地址:
https://github.com/JimLiu/Lucene.Net.Analysis.PanGu
下载后里面有DEMO代码进行整合.
Lucene在软件中集成处理
由于实时处理数据程序是WINFORM程序,所以需要采用软件代码来实时更新索引数据,这样可控性高一些.
引用头文件
using Lucene.Net.Analysis;
using Lucene.Net.Analysis.Standard;
using Lucene.Net.Documents;
using Lucene.Net.Index;
using Lucene.Net.QueryParsers;
using Lucene.Net.Search;
using Lucene.Net.Store;
using Lucene.Net.Util;
using PanGu;
using Lucene.Net.Analysis.PanGu;
using PanGu.HighLight;
using FSDirectory = Lucene.Net.Store.FSDirectory;
using Version = Lucene.Net.Util.Version;
创建索引
public static class H31Index
{
private static Analyzer analyzer = new PanGuAnalyzer(); //MMSegAnalyzer //StandardAnalyzer
private static int ONEPAGENUM = ;
private static string m_indexPath = "";
private static IndexWriter iw = null;
public static void Init(string indexpath)
{
m_indexPath = indexpath;
} public static bool OpenIndex()
{
try
{ DirectoryInfo INDEX_DIR = new DirectoryInfo(m_indexPath+"//Index");
bool iscreate = true;
if (INDEX_DIR.Exists)
iscreate = false;
Int32 time21 = System.Environment.TickCount;
if (iw == null)
{
iw = new IndexWriter(FSDirectory.Open(INDEX_DIR), analyzer, iscreate, new IndexWriter.MaxFieldLength());
Int32 time22 = System.Environment.TickCount;
H31Debug.PrintLn("IndexWriter2[" + type.ToString() + "]:" + " IndexWriter:" + (time22 - time21).ToString() + "ms");
return true;
}
}
catch (System.Exception ex)
{
H31Debug.PrintLn("OpenIndex" + ex.Message);
}
return false;
} public static void CloseIndex()
{
try
{
if (iw != null)
{
//if (count > 0)
{
iw.Commit();
iw.Optimize();
}
iw.Dispose();
iw = null;
}
}
catch (System.Exception ex)
{
H31Debug.PrintLn("CloseIndex" + ex.Message);
} } //建立索引
public static int AddIndexFromDB()
{
int res = ;
int count = ;
try
{
Int32 time0 = System.Environment.TickCount;
while (count < OneTimeMax && iw != null)
{
Int32 time11 = System.Environment.TickCount;
DataSet ds = H31SQL.GetHashListFromDB(type, startnum, startnum + ONEPAGENUM - , NewOrUpdate);
Int32 time12 = System.Environment.TickCount;
int cnt = ds.Tables[].Rows.Count;
if (ds != null&& cnt>)
{
Int32 time1 = System.Environment.TickCount;
count = count + cnt;
for (int i = ; i < cnt; i++)
{
//ID,hashKey,recvTime,updateTime,keyContent,keyType,recvTimes,fileCnt,filetotalSize,Detail,viewTimes,viewLevel
Document doc = new Document();
doc.Add(new Field("ID", ds.Tables[].Rows[i]["ID"].ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));//存储,索引
doc.Add(new Field("hashKey", ds.Tables[].Rows[i]["hashKey"].ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));//存储,索引
doc.Add(new Field("recvTime", ds.Tables[].Rows[i]["recvTime"].ToString(), Field.Store.YES, Field.Index.NO));//存储,不索引
doc.Add(new Field("updateTime", ds.Tables[].Rows[i]["updateTime"].ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));//存储,索引
doc.Add(new Field("keyContent", ds.Tables[].Rows[i]["keyContent"].ToString(), Field.Store.YES, Field.Index.ANALYZED));//存储,索引
//PanGuFenCiTest(ds.Tables[0].Rows[i]["keyContent"].ToString());
string typeid=ds.Tables[].Rows[i]["keyType"].ToString();
if(typeid.Length<)
typeid=type.ToString();
doc.Add(new Field("keyType", typeid, Field.Store.YES, Field.Index.NO));//存储,不索引
doc.Add(new Field("recvTimes", ds.Tables[].Rows[i]["recvTimes"].ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED));//存储,索引
doc.Add(new Field("fileCnt", ds.Tables[].Rows[i]["fileCnt"].ToString(), Field.Store.YES, Field.Index.NO));//存储,不索引
doc.Add(new Field("filetotalSize", ds.Tables[].Rows[i]["filetotalSize"].ToString(), Field.Store.YES, Field.Index.NO));//存储,不索引
doc.Add(new Field("Detail", ds.Tables[].Rows[i]["Detail"].ToString(), Field.Store.YES, Field.Index.NO));//存储,不索引
doc.Add(new Field("viewTimes", ds.Tables[].Rows[i]["viewTimes"].ToString(), Field.Store.YES, Field.Index.NO));//存储,不索引
doc.Add(new Field("viewLevel", ds.Tables[].Rows[i]["viewLevel"].ToString(), Field.Store.YES, Field.Index.NO));//存储,不索引
iw.AddDocument(doc);
}
ds = null;
Thread.Sleep();
}
else
{
res = ;
break;
}
} Int32 time10 = System.Environment.TickCount;
H31Debug.PrintLn("AddIndexFromDB[" + type.ToString() + "],Building index done:" + startnum.ToString() + " Time:" + (time10 - time0).ToString() + "ms"); }
catch (System.Exception ex)
{
H31Debug.PrintLn(ex.StackTrace);
} return res;
}
创建索引代码
查询代码
//网站搜索代码
public static void Search(string keyword,int typeid,int pageNo)
{
int onePage=;//一页多少
int TotalNum=;//一次加载多少 if (pageNo < ) pageNo = ;
if (pageNo * onePage > TotalNum)
pageNo = TotalNum / onePage; //索引加载的目录
DirectoryInfo INDEX_DIR = new DirectoryInfo(m_indexPath+"//Index//index1");
IndexSearcher searcher = new IndexSearcher(FSDirectory.Open(INDEX_DIR), true);
QueryParser qp = new QueryParser(Version.LUCENE_30, "keyContent", analyzer);
Query query = qp.Parse(keyword);
//Console.WriteLine("query> {0}", query); //设置排序问题
Sort sort = new Sort(new SortField[]{new SortField("recvTimes", SortField.INT, true),new SortField("updateTime", SortField.STRING, true)}); //设置高亮显示的问题
PanGu.HighLight.SimpleHTMLFormatter simpleHTMLFormatter = new PanGu.HighLight.SimpleHTMLFormatter("<font color=\"red\">", "</font>");
PanGu.HighLight.Highlighter highlighter =new PanGu.HighLight.Highlighter(simpleHTMLFormatter,new Segment());
highlighter.FragmentSize = ; TopFieldDocs tds = searcher.Search(query,null, , sort);
Console.WriteLine("TotalHits: " + tds.TotalHits); /* 计算显示的条目 */
int count = tds.ScoreDocs.Length;
int start = (pageNo - ) * onePage;
int end = pageNo * onePage > count ? count : pageNo * onePage;
//返回集合列表
for (int i = start; i < end; i++)
{
Document doc = searcher.Doc(tds.ScoreDocs[i].Doc);
string contentResult = highlighter.GetBestFragment(keyword, doc.Get("keyContent").ToString());
Console.WriteLine(contentResult + ">>" + doc.Get("recvTimes") + "<<" + doc.Get("updateTime"));
} searcher.Dispose();
}
服务器部署的问题
当你觉得本地都运行的好好的时候,发现到服务器上根本就运行不了,一直报错.
由于Lucene.net最新版本直接使用了net4.0,服务器是64们的WIN2003,而且运行的网站都还是32位的net2.0的DLL,所以升级到4.0怎么也出不来
1.运行显示的错误是提示没有.net4.0的框架,需要注册.net4.0
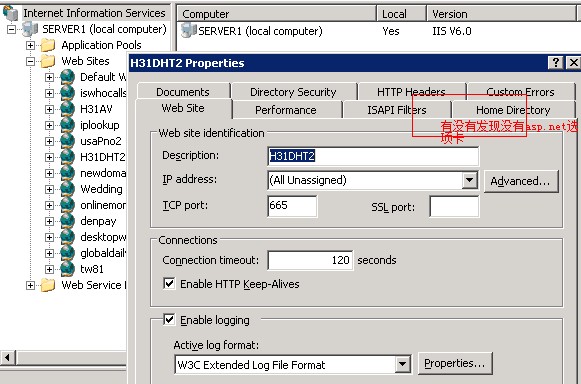
直接到网上找如何搞定显示ASP.NET选项卡的问题,最后找到文章方法是:
停止iis直接删除C:/WINDOWS/system32/inetsrv/MetaBase.xml中的Enable32BitAppOnWin64="TRUE" 行
重启IIS后选项卡到是出来了,但net.2.0的网站全部挂掉,运行不起来,sosobta.com网站也运行不起来,
Enable32BitAppOnWin64的意思是允许运行32们的程序,所以此方法不行.
2.另外找的文章都是重新注册net 4.0
C:\WINDOWS\Microsoft.NET\Framework\v4.0.30319\aspnet_regiis.exe -i
开始执行试了好多次,没有效果,这里也允许了,重新安装了好几次Net4.0.
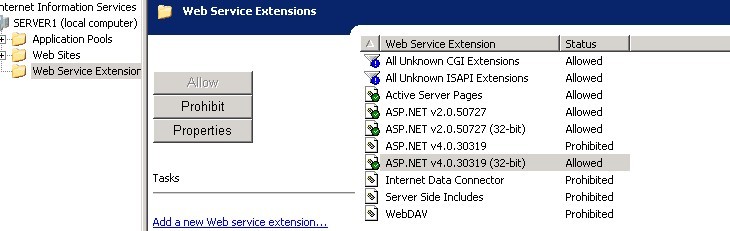
3.最后一次在停止IIS后,再次全部注册net2.0,4.0,然后
cscript %SYSTEMDRIVE%\inetpub\adminscripts\adsutil.vbs SET W3SVC/AppPools/Enable32bitAppOnWin64 1
重启IIS后,出现的错误终于不再是上面的.
新错误是:
Server Application Unavailable
4.通过网上查找资料
解决办法: 在IIS中新建一个应用程序池,然后选中你的 基于.net
framework4.0的虚拟目录,点“属性”-》在“应用程序池” 中选择刚才新建的的应用程序池,点击“确定”。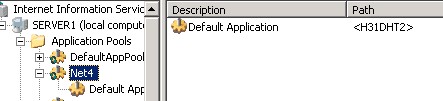
最后服务器网站sosobt.com终于运行起来了.
Lucene.net搜索的效果
1.经过目前测试,目前服务器4G的内存搜索速度比以前需要5S左右的LIKE强了很多倍,基本上都在1S以内;
2.由于Lucene索引是基于文件的索引,从而使SQL数据库的使用压力减轻不少,这样给其它程序的整体压力减少不少,网站效果还行.
3.目前500万的数据重新建立一次索引需要1小时左右,但是网站运行的时候去更新索引速度目前感觉比较慢.比如要更新点击次数和更新时间等时,发现新的问题来了,这块的时间比较长.
4.目前考虑的方案是几天一次全部重新建立索引一次,平时只是添加数据.
希望有了解的朋友在此留言指教下lucene.net方面的性能优化问题,大家一起共同学习进步.
大家看累了,就移步到娱乐区http://www.sosobta.com 去看看速度如何,休息下...
希望大家多多推荐哦...大家的推荐才是下一篇介绍的动力...
使用Lucene.net提升网站搜索速度整合记录的更多相关文章
- 使用 Nginx 提升网站访问速度
使用 Nginx 提升网站访问速度 http://www.ibm.com/developerworks/cn/web/wa-lo-nginx/ Nginx 简介 Nginx ("engine ...
- Nginx——使用 Nginx 提升网站访问速度【转载+整理】
原文地址 本文是写于 2008 年,文中提到 Nginx 不支持 Windows 操作系统,但是现在它已经支持了,此外还支持 FreeBSD,Solaris,MacOS X~ Nginx(" ...
- 使用 Nginx 提升网站访问速度(转)
Nginx 简介 Nginx ("engine x") 是一个高性能的 HTTP 和 反向代理 服务器,也是一个 IMAP/POP3/SMTP 代理服务器. Nginx 是由 Ig ...
- 加速 lucene 的搜索速度 ImproveSearchingSpeed
* Be sure you really need to speed things up. Many of the ideas here are simple to try, but others w ...
- 13 nginx gzip压缩提升网站速度
一:nginx gzip压缩提升网站速度 我们观察news.163.com的头信息 请求: Accept-Encoding:gzip,deflate,sdch 响应: Content-Encoding ...
- nginx之gzip压缩提升网站速度
目录: 为啥使用gzip压缩 nginx使用gzip gzip的常用配置参数 nginx配置gzip 注意 为啥使用gzip压缩 开启nginx的gzip压缩,网页中的js,css等静态资源的大小会大 ...
- lucene正向索引(续)——域(Field)的元数据信息在.fnm里,在倒排表里,利用跳跃表,有利于大大提高搜索速度。
4.1.2. 域(Field)的元数据信息(.fnm) 一个段(Segment)包含多个域,每个域都有一些元数据信息,保存在.fnm文件中,.fnm文件的格式如下: FNMVersion 是fnm文件 ...
- Nginx网络架构实战学习笔记(三):nginx gzip压缩提升网站速度、expires缓存提升网站负载、反向代理实现nginx+apache动静分离、nginx实现负载均衡
文章目录 nginx gzip压缩提升网站速度 expires缓存提升网站负载 反向代理实现nginx+apache动静分离 nginx实现负载均衡 nginx gzip压缩提升网站速度 网页内容的压 ...
- Lucene.net站内搜索—6、站内搜索第二版
目录 Lucene.net站内搜索—1.SEO优化 Lucene.net站内搜索—2.Lucene.Net简介和分词Lucene.net站内搜索—3.最简单搜索引擎代码Lucene.net站内搜索—4 ...
随机推荐
- 简直喝血!H.265要被专利费活活玩死
转自 http://news.mydrivers.com/1/440/440145.htm H.264是如今最流行的视频编码格式之一,不但技术先进,而且专利费很低,企业每年只需支付650万美元,而个人 ...
- 【学习笔记】【C语言】字符串数组
1.使用场合 * 一维字符数组中存放一个字符串,比如一个名字char name[20] = "mj" * 如果要存储多个字符串,比如一个班所有学生的名字,则需要二维字符数组,cha ...
- python常错: join() 方法
描述 Python join() 方法用于将序列中的元素以指定的字符连接生成一个新的字符串. 语法 join()方法语法: str.join(sequence) 参数 sequence -- 要连接的 ...
- javascript之Array基础篇
整理了 Array 中很基础的要掌握的知识点,希望可以帮助初学者,也希望自己以后多用多融会贯通. 创建数组 使用Array构造函数: var a=new Array();//创建一个空数组 var a ...
- Eclipse+GitHub
之前一直想研究github的使用,但一直没时间,今天抽空学习了一下,发现真的是非常好用!!! 准备材料 1.你要有最新版的Eclipse(不要问我为什么要最新版的,反正我用的是最新版本) 2.一个gi ...
- hdu 3665 Seaside floyd+超级汇点
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3665 题意分析:以0为起点,求到Sea的最短路径. 所以可以N为超级汇点,使用floyd求0到N的最短 ...
- Codevs 1231 最优布线问题
题目描述 Description 学校需要将n台计算机连接起来,不同的2台计算机之间的连接费用可能是不同的.为了节省费用,我们考虑采用间接数据传输结束,就是一台计算机可以间接地通过其他计算机实现和另外 ...
- C指针赋值
Node* p = A; Node* f = B; Node* t; t = p; t = f 本人试图让p指向B,但这样操作是不行的.如下图:只是改变了t的指向,p并没有变
- 从零开始搭建TestCpp工程
目标: 创建一个测试工程,测试工程以列表的方式展示,没一个列表项对应一个场景 1. 创建cocos2d-x工程 现在采用脚本的方式来创建,好处是一次可以创建N个项目的工程. 首先 ...
- 《搭建DNS内外网的解析服务》RHEL6
首先说下: 搭建的这个dns内外网的解析,是正向解析,反向解析自己根据正向解析把文件颠倒下就ok了 第一步我们先搭建一个DNS的正反向解析(参考上篇DNS正反向解析,这是上篇做过的) 第二部才是搭建内 ...