为什么样本方差(sample variance)的分母是 n-1?
为什么样本方差(sample variance)的分母是 n-1?
(補充一句哦,題主問的方差 estimator 通常用 moments 方法估計。如果用的是 ML 方法,請不要多想不是你們想的那樣, 方差的 estimator 的期望一樣是有 bias 的,有興趣的同學可以自己用正態分佈算算看。)
本來,按照定義,方差的 estimator 應該是這個: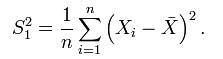 但,這個 estimator 有 bias,因為:
但,這個 estimator 有 bias,因為: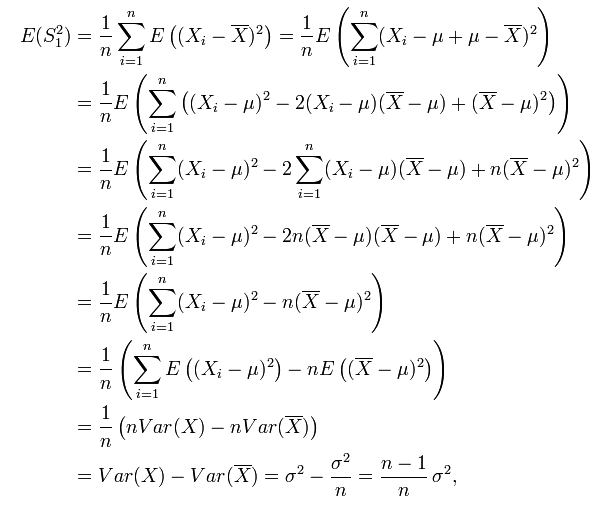
而 (n-1)/n * σ² != σ² ,所以,為了避免使用有 bias 的 estimator,我們通常使用它的修正值 S²: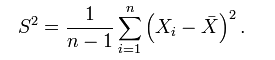
上面有答案解释得很明确,即样本方差计算公式里分母为的目的是为了让方差的估计是无偏的。无偏的估计(unbiased estimator)比有偏估计(biased estimator)更好是符合直觉的,尽管有的统计学家认为让mean square error即MSE最小才更有意义,这个问题我们不在这里探讨;不符合直觉的是,为什么分母必须得是
而不是
才能使得该估计无偏。我相信这是题主真正困惑的地方。
要回答这个问题,偷懒的办法是让困惑的题主去看下面这个等式的数学证明:.
但是这个答案显然不够直观(教材里面统计学家像变魔法似的不知怎么就得到了上面这个等式)。
下面我将提供一个略微更友善一点的解释。
==================================================================
===================== 答案的分割线 ===================================
==================================================================
首先,我们假定随机变量的数学期望
是已知的,然而方差
未知。在这个条件下,根据方差的定义我们有
由此可得.
因此是方差
的一个无偏估计,注意式中的分母不偏不倚正好是
!
这个结果符合直觉,并且在数学上也是显而易见的。
现在,我们考虑随机变量的数学期望
是未知的情形。这时,我们会倾向于无脑直接用样本均值
替换掉上面式子中的
。这样做有什么后果呢?后果就是,
如果直接使用作为估计,那么你会倾向于低估方差!
这是因为:
换言之,除非正好,否则我们一定有
,
而不等式右边的那位才是的对方差的“正确”估计!
这个不等式说明了,为什么直接使用会导致对方差的低估。
那么,在不知道随机变量真实数学期望的前提下,如何“正确”的估计方差呢?答案是把上式中的分母换成
,通过这种方法把原来的偏小的估计“放大”一点点,我们就能获得对方差的正确估计了:
至于为什么分母是而不是
或者别的什么数,最好还是去看真正的数学证明,因为数学证明的根本目的就是告诉人们“为什么”;暂时我没有办法给出更“初等”的解释了。
样本方差与样本均值,都是随机变量,都有自己的分布,也都可能有自己的期望与方差。取分母n-1,可使样本方差的期望等于总体方差,即这种定义的样本方差是总体方差的无偏估计。 简单理解,因为算方差用到了均值,所以自由度就少了1,自然就是除以(n-1)了。
再不能理解的话,形象一点,对于样本方差来说,假如从总体中只取一个样本,即n=1,那么样本方差公式的分子分母都为0,方差完全不确定。这个好理解,因为样本方差是用来估计总体中个体之间的变化大小,只拿到一个个体,当然完全看不出变化大小。反之,如果公式的分母不是n-1而是n,计算出的方差就是0——这是不合理的,因为不能只看到一个个体就断定总体的个体之间变化大小为0。
我不知道是不是说清楚了,详细的推导相关书上有,可以查阅。
因为样本均值与实际均值有差别。
如果分母用n,样本估计出的就方差会小于真实方差。
维基上有具体计算过程:
http://en.wikipedia.org/wiki/Unbiased_estimator#Sample_variance
Sample variance[edit]
The sample variance of a random variable demonstrates two aspects of estimator bias: firstly, the naive estimator is biased, which can be corrected by a scale factor; second, the unbiased estimator is not optimal in terms of mean squared error (MSE), which can be minimized by using a different scale factor, resulting in a biased estimator with lower MSE than the unbiased estimator. Concretely, the naive estimator sums the squared deviations and divides by n, which is biased. Dividing instead by n − 1 yields an unbiased estimator. Conversely, MSE can be minimized by dividing by a different number (depending on distribution), but this results in a biased estimator. This number is always larger than n − 1, so this is known as a shrinkage estimator, as it "shrinks" the unbiased estimator towards zero; for the normal distribution the optimal value is n + 1.
Suppose X1, ..., Xn are independent and identically distributed (i.i.d.) random variables with expectation μ and variance σ2. If the sample mean and uncorrected sample variance are defined as
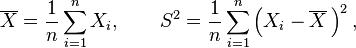
then S2 is a biased estimator of σ2, because
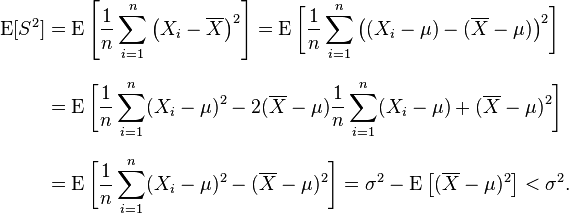
In other words, the expected value of the uncorrected sample variance does not equal the population variance σ2, unless multiplied by a normalization factor. The sample mean, on the other hand, is an unbiased[1] estimator of the population mean μ.
The reason that S2 is biased stems from the fact that the sample mean is an ordinary least squares (OLS) estimator for μ: 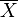 is the number that makes the sum
is the number that makes the sum  as small as possible. That is, when any other number is plugged into this sum, the sum can only increase. In particular, the choice
as small as possible. That is, when any other number is plugged into this sum, the sum can only increase. In particular, the choice  gives,
gives,

and then

Note that the usual definition of sample variance is

and this is an unbiased estimator of the population variance. This can be seen by noting the following formula, which follows from the Bienaymé formula, for the term in the inequality for the expectation of the uncorrected sample variance above:

The ratio between the biased (uncorrected) and unbiased estimates of the variance is known as Bessel's correction.
为什么样本方差(sample variance)的分母是 n-1?的更多相关文章
- 样本方差:为嘛分母是n-1
在样本方差计算式中,我们使用Xbar代替随机变量均值μ. 容易证明(参考随便一本会讲述样本方差的教材),只要Xbar不等于μ,sigma(Xi-Xbar)2必定小于sigma(Xi-μ)2. 然而,要 ...
- Reading | 《DEEP LEARNING》
目录 一.引言 1.什么是.为什么需要深度学习 2.简单的机器学习算法对数据表示的依赖 3.深度学习的历史趋势 最早的人工神经网络:旨在模拟生物学习的计算模型 神经网络第二次浪潮:联结主义connec ...
- 描述性统计分析-用脚本将统计量函数批量化&分步骤逐一写出
计算各种描述性统计量函数脚本(myDescriptStat.R)如下: myDescriptStat <- function(x){ n <- length(x) #样本数据个数 m &l ...
- R提高篇(五): 描述性统计分析
数据作为信息的载体,要分析数据中包含的主要信息,即要分析数据的主要特征(即数据的数字特征), 对于数据的数字特征, 包含数据的集中位置.分散程度和数据分布,常用统计项目如下: 集中趋势统计量: 均值 ...
- 使用java计算数组方差和标准差
使用java计算数组方差和标准差 觉得有用的话,欢迎一起讨论相互学习~Follow Me 首先给出方差和标准差的计算公式 代码 public class Cal_sta { double Sum(do ...
- 为什么方差的分母有时是n,有时是n-1 源于总体方差和样本方差的不同
为什么样本方差(sample variance)的分母是 n-1? 样本方差计算公式里分母为n-1的目的是为了让方差的估计是无偏的.无偏的估计(unbiased estimator)比有偏估计(bia ...
- Variance
http://mathworld.wolfram.com/Variance.html Variance For a single variate having a distribution with ...
- range|Sample Standard Deviation|标准差几何意义
Measures of Variation 方差:measures of variation or measures of spread 源于range发现range不足以评估整个set(因为只用到l ...
- Hive2.0函数大全(中文版)
摘要 Hive内部提供了很多函数给开发者使用,包括数学函数,类型转换函数,条件函数,字符函数,聚合函数,表生成函数等等,这些函数都统称为内置函数. 目录 数学函数 集合函数 类型转换函数 日期函数 条 ...
随机推荐
- Java Servlet-http协议
---恢复内容开始--- 互联网三大基石: url:定位数据 html:显示数据 http:传输数据
- Ajax-Demo
index.jsp 1 <%@ page language="java" contentType="text/html; charset=UTF-8" p ...
- Android之帧动画
MySurfaceView类: package com.fm; import android.content.Context; import android.graphics.Bitmap; impo ...
- SecureCRT连接虚拟机中的Linux系统(Ubuntu)
最近在学习Linux,看了网上很多SecureCRT连接本地虚拟机当中的Linux系统,很多都是需要设置Linux的配置文件,有点繁琐,所以自己就摸索了一下,把相关操作贴出来分享一下. SecureC ...
- 配置tomcat免安装版服务器
一.首先,确保服务器已经安装java环境,没有tomcat的可以到这里下载 http://tomcat.apache.org/ 二.解压下载的压缩包,我是解压到D盘根目录下的.记住这个目录,后面会用到 ...
- 改变UITextField placeHolder 字体 颜色
[_textSearchField setValue:[UIColor redColor] forKeyPath:@"_placeholderLabel.textColor"]; ...
- OC9_字符串的内存管理
// // main.m // OC9_字符串的内存管理 // // Created by zhangxueming on 15/6/18. // Copyright (c) 2015年 zhangx ...
- (转)Ehcache作为分布式缓存的研究
ehcache支持两种拓扑结构,一种是Distributed Caching,另一种是Replicated Caching Distributed Caching 这和一般意义上的分布式缓存非常类似, ...
- Koajs原理
Koajs让习惯阻塞式代码写法的同学感到很舒服,再也不用盖楼式的callback了,而且也不需要学习Promise的then,catch这些新东西. 但实际上,Koajs这样的写法有点像是语言的语法糖 ...
- reduce + Promise 顺序执行代码
本文地址: http://www.cnblogs.com/jasonxuli/p/4398742.html 下午的太阳晒得昏昏沉沉,和上周五一样迷糊,看一段代码半天没看明白,刚才不知不觉眯了几分钟,醒 ...