SharePoint服务器端对象模型 之 使用CAML进行数据查询(Part 2)
(三)使用SPQuery进行列表查询
1、概述
列表查询主要是指在一个指定的列表(或文档库)中按照某些筛选、排序条件进行查询。列表查询主要使用SPQuery对象,以及SPList的GetItems方法,将SPQuery作为参数传递,返回查询到的列表条目集合,即SPListItemCollection类型。
在使用SPQuery进行列表查找的时候,其中一些属性指定了其查找的特性:
Query属性:通过该属性指定CAML格式的筛选条件和排序条件(见上文),如果不指定,则默认返回范围内的所有条目;
Folder属性:通过该属性指定在特定文件夹范围内进行查找,如果不指定,则为列表或文档库的根文件夹;
RowLimit属性:指定一次返回多少个条目,如果不指定,则返回所有条目;通过这个属性与ListItemCollectionPosition属性配合,可以实现列表条目的分页查找;出于性能考虑,建议在一般情况下,都指定一个合理的RowLimit值,在SharePoint 2010中,系统也会自动对查询返回结果的数量上进行一些限制和过滤(见后文关于查询阈值的描述);
ViewFields属性:指定CAML格式的返回字段(见上文),如果不指定,则默认返回所有字段;
ViewAttributes属性:这个属性主要和Folder属性配合使用,用于指定查询范围,如果不指定,则查找指定文件夹下的条目和子文件夹(详见后文)。
下面是一个列表查询的例子:
1: using(SPSite site = new SPSite("http://sp2010/book"))
2: {
3: using(SPWeb web = site.OpenWeb())
4: {
5: SPList list = web.Lists["Chapters"];
6: SPQuery query = new SPQuery();
7: query.Query = "<Where><Contains><FieldRef Name='Title'/>" +
8: "<Value Type='Text'>sp</Value></Contains></Where>" +
9: "<OrderBy><FieldRef Name='Created'/></OrderBy>";
10: query.ViewFields = "<FieldRef Name='Title'/>";
11: SPListItemCollection items = list.GetItems(query);
12: foreach(SPListItem itm in items)
13: Console.WriteLine(Convert.ToString(itm["Title"]));
14: }
15: }
这是一个比较简单的列表查询,查询了“Chapters”这个列表的根目录中,“标题”字段包含字符串“sp”(SharePoint查询中是否区分大小写,由内容数据库的相关规则指定,默认规则安装的数据库不区分字母的大小写)的那些列表条目(可能还有文件夹),并输出它们的标题。
2、查询范围(Scope)
通过配合使用SPQuery的Folder属性和ViewAttributes属性,可以控制查询时候的范围。
首先需要说明的是,在进行查询的时候,普通列表条目(或者文档库中的文件)与文件夹是划分查询范围的两个重要条件。在查询的时候,共有4种查询范围的设定:
- 不指定ViewAttributes,则查询的是Folder对应的文件夹下面的列表条目(或文档)以及子文件夹,就上面的例子来说,查询的就是列表的根目录,会返回根目录中标题包含“sp”的列表条目,以及名称包含“sp”的子文件夹。
- ViewAttributes = "Scope='FilesOnly'"。顾名思义,当指定了这个范围之后,查询的就是Folder对应文件夹下面的列表条目(或文档)。如果把这个属性加到上面的例子中,返回的将不再包括列表根目录下的子文件夹——即使它们的名称包含“sp”。
- ViewAttributes = "Scope='Recursive'"。当指定这个查询范围的时候,它查询的范围是Folder指定的文件夹及其子文件夹下的所有列表条目(或文档),不管它们在哪个子文件夹下。
- ViewAttributes = "Scope='RecursiveAll'"。同样的,它查询的范围是Folder指定的文件夹及其子文件夹下中的所有列表条目(或文档)以及文件夹。
注意:当查询结果同时包含了文件夹和普通条目(或文档)的时候,不论排序条件是如何指定的,在返回的结果中必然是文件夹在前、普通条目(或文档)在后。
3、分页查询
如果列表中一次查询返回的结果非常非常多,势必会造成一定的性能损失,通过RowLimit属性可以在一定程度上控制性能的降低,但是仅通过RowLimit属性,就只能返回查询结果中的前若干条结果,如果用户想要再查看后面的结果,就要配合使用到SPQuery的ListItemCollectionPosition属性进行分页查找。
在查找返回结果的SPListItemCollection对象中,有一个ListItemCollectionPosition属性,包含了当前查询结果的分页信息。将这个属性传递到下一次查找过程中使用的SPQuery的对应属性中,就可以直接返回下一页的查找结果,直到返回结果中的该属性为null,就表示已经查找到了最后一页。每页包含多少个结果由RowLimit属性来指定。
下面的程序就是在之前程序的基础上,增加了分页查找的例子:
1: using(SPSite site = new SPSite("http://sp2010/book"))
2: {
3: using(SPWeb web = site.OpenWeb())
4: {
5: SPList list = web.Lists["Chapters"];
6: SPQuery query = new SPQuery();
7: query.Query = "<Where><Contains><FieldRef Name='Title'/>" +
8: "<Value Type='Text'>sp</Value></Contains></Where>" +
9: "<OrderBy><FieldRef Name='Created'/></OrderBy>";
10: query.ViewFields = "<FieldRef Name='Title'/>";
11: query.RowLimit = 5;
12: SPListItemCollection items = null;
13: int currentPage = 1;
14: do
15: {
16: items = list.GetItems(query);
17: Console.WriteLine(string.Format("Page {0}:", currentPage));
18: foreach(SPListItem itm in items)
19: Console.WriteLine(Convert.ToString(itm["Title"]));
20: query.ListItemCollectionPostion =
21: items.ListItemCollectionPosition;
22: currentPage++;
23: }while(items.ListItemCollectionPosition != null);
24: }
25: }
细心的读者可能会注意到SharePoint内置的列表视图在进行分页的时候,只有上一页和下一页的链接按钮,而没有办法直接跳转到第x页,在翻到最后一页之前,也没有办法知道在这个视图下一共有多少个条目。在经过上面的介绍之后,现在您应当已经能想到这个现象背后的原因了。SharePoint内置提供了如上面程序那样向后翻页的机制,读者可以在前后翻页的时候注意一下Url地址的变化,自行思考如何来实现“上一页”的效果。实际上,在SharePoint 2003的时代,列表视图里面就只有“下一页”的按钮,而没有“上一页”的按钮。
4、通过查阅项进行列表关联查询
在进行列表查询的时候,使用之前介绍的CAML语法,可以很容易地在一个列表中根据其中字段的不同筛选条件进行查询。但是从应用的角度来讲,仅将查询局限在一个表中是远远不够的,我们在开发传统应用的时候必然会遇到多个表之间进行关联查询的场景。这里我们就将介绍,在SharePoint中,如何实现这种多表之间关联的查询。
为了能够更加清楚的说明问题,在这里我们不妨假定一个经过简化后的实际场景:一个软件销售公司拥有自己的销售人员列表,其中包含了销售人员的姓名、擅长的销售领域等等;同时也拥有一张订单列表,包含了所销售的产品的名称、数量、单价,以及这张订单的销售人员的姓名。于是我们不难设计出如下的数据表结构:
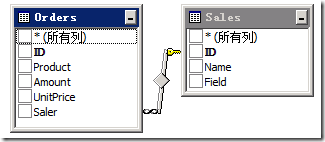
在SharePoint中实现这样的数据结构,我们可以想到创建“Sales”和“Orders”这两个列表,并在“Orders”列表中创建一个“Saler”查阅项来查阅“Sales”列表的姓名字段,如下图:
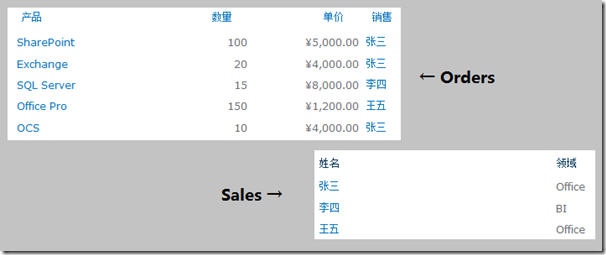
此时,如果我们需要查找“张三”这个销售卖出去的所有订单,可以使用如下的CAML:
1: <Where><Eq>
2: <FieldRef Name='Saler' /> <!--注意这里使用了字段内部名称 -->
3: <Value Type='Lookup'>张三</Value>
4: </Eq></Where>
或者更准确的(考虑到可能有多个名叫“张三”的销售):
1: <Where><Eq>
2: <FieldRef Name='Saler' LookupId='TRUE' />
3: <Value Type='Lookup'>1</Value> <!--1是我们关心的那个“张三”的ID-->
4: </Eq></Where>
于是,很自然地我们通过查阅项实现了最简单的两个列表关联查询。
直到有一天,老板希望能够查看一下那些专长领域是Office的销售都卖出过哪些订单。按照一般的思路,我们可以先在销售列表中找到那些专长领域是Office的销售有哪些,然后再分多次去订单列表中查询,最后把查询结果拼在一起。但是有没有更简单高效的方法呢?在SharePoint 2010中,为此提供了两种方式:
方法一:使用SharePoint 2010查阅项新增的映射栏(Project Fields)的功能,将姓名、领域两个字段同时映射到销售列表中,见下图:
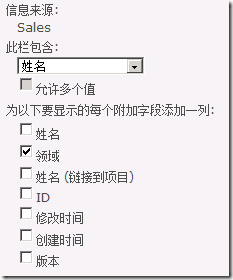
于是,我们就可以使用映射到销售列表中的“Sales:领域”这一字段进行查询了:
1: <Where><Eq>
2: <FieldRef Name='SalerField' /> <!--依然是字段的内部名称 -->
3: <Value Type='Lookup'>Office</Value>
4: </Eq></Where>
方法二:使用SharePoint 2010增加的SPQuery的列表关联查询功能。
这里,我们需要先借助SPQuery的Joins属性声明两个列表的关联,再使用ProjectedFields属性创建一个虚拟的映射字段,在这个虚拟字段上使用CAML进行查询。SPQuery的创建过程如下:
1: SPQuery query = new SPQuery();
2:
3: query.Joins = @"<Join Type='LEFT' ListAlias='Sales'>
4: <Eq>
5: <FieldRef Name='Saler' RefType='ID'/>
6: <FieldRef List='Sales' Name='ID'/>
7: </Eq>
8: </Join>";
9:
10: query.ProjectedFields = @"<Field Name='SalerField' Type='Lookup'
11: List='Sales' ShowField='Field'/>";
12:
13: query.Query = @"<Where><Eq>
14: <FieldRef Name='SalerField'/>
15: <Value Type='Lookup'>Office</Value>
16: </Eq></Where>";
在这段程序中,首先我们创建了一个列表关联(Join),其类型是左外连接(Type=LEFT),并将这个关联赋予一个列表别名(ListAlias='Sales'),关联是建立在当前列表(即订单列表)的“Saler”字段(查阅项,本质是查阅ID)与Sales列表(这个名称必须与Join中声明的列表别名相同)的ID字段。实际上,这一段CAML如果“翻译”成SQL语句的话(这里只是为了能够让传统的开发人员更容易理解这段CAML,并不表示SharePoint实际存储的数据表结构。),看上去就变得熟悉多了:
1: Orders LEFT JOIN Sales
2: ON
3: Orders.Saler = Sales.ID
接下来,为了能够在查询条件中使用“领域”这一字段,需要把销售表中的“领域”映射为订单表中的一个虚拟字段(ProjectedField),并给这个字段随意指定一个名称(比如程序中的“SalerField”。该字段来自Sales列表(List='Sales',同样要求与Join中定义的的列表别名相同)的“Field”字段(ShowField='Field',“领域”的内部名称),类型为查阅项(Type='Lookup')。
之后,我们就可以把这个映射字段“SalerField”当作订单列表中的字段在查询使用了。
这两种方法所达到的效果是完全一样的,区别只是在于创建一个真正的映射字段,还是创建一个虚拟的映射字段。
由于我们的程序工作良好,为公司提高了效率,公司不断壮大发展,在其它城市也成立了分部。此时,为了能够管理其他城市的销售人员,我们的数据结构就要发生变动了,需要引入一张新的“城市”列表,并且在销售列表上为每个销售附加上城市的信息:
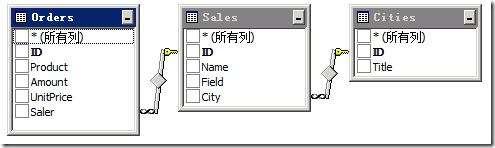
于是,在SharePoint中,我们也相应的创建了一个城市列表,并且在销售列表中创建了一个引用了城市列表的查阅项:
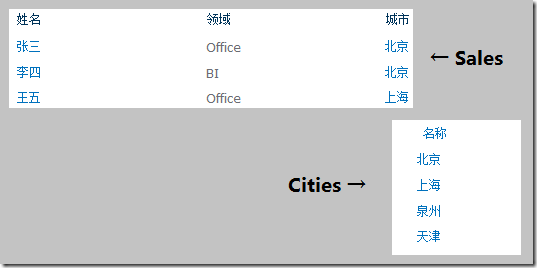
这个时候,老板必定会希望能够查看一下某个特定城市的所有订单的销售情况。当然,我们仍然可以先找到这个城市的所有销售,然后分别查找出他们的订单并把结果合并起来。不过在SharePoint 2010中,仍然有更直接的方法,那就是使用列表的关联查询。
遗憾的是,SharePoint的查阅项在映射多个列的时候,无法再从中选择一个查阅项,因此我们只能通过方法二中的技术来实现这一需求。这个SPQuery的创建程序片段如下:
1: SPQuery query = new SPQuery();
2:
3: query.Joins = @"<Join Type='LEFT' ListAlias='Sales'>
4: <Eq>
5: <FieldRef Name='Saler' RefType='Id' />
6: <FieldRef List='Sales' Name='ID' />
7: </Eq>
8: </Join>
9: <Join Type='LEFT' ListAlias='Cities'>
10: <Eq>
11: <FieldRef List='Sales' Name='City' RefType='Id' />
12: <FieldRef List='Cities' Name='ID' />
13: </Eq>
14: </Join>";
15:
16: query.ProjectedFields = @"<Field Name='SaleCity' Type='Lookup'
17: List='Cities' ShowField='Title'/>";
18:
19: query.Query = @"<Where>
20: <Eq>
21: <FieldRef Name='SaleCity' />
22: <Value Type='Text'>北京</Value>
23: </Eq>
24: </Where>";
与之前的程序相比,这段程序只是多做了一次Join,将关联的列表从两个变成了三个,它“相当于”如下的SQL语句(同样,这里只是为了方便传统的开发人员能够理解SharePoint中的Join的写法):
1: Orders LEFT JOIN Sales
2: ON
3: Orders.Saler = Sales.ID
4: LEFT JOIN Cities
5: ON
6: Sales.City = City.ID
程序的其他部分就不再赘述了。
我们可以看到,在SharePoint 2010中,列表查阅项的功能已经有了极大的增强,这代表着今天实现列表与列表之间的关联越来越方便,可以更便捷地搭建出我们所需的应用。不过也应当注意到,随着关联的日趋复杂,CAML的编写也跟着越来越复杂,即使是很有经验的程序员也难免在这个地方出现一些手误,而这种错误在程序调试过程中又是很难发现的。好在SharePoint 2010为我们提供了一项新的查询技术,我们将在下一节中对其进行详细介绍。
5、列表查询的注意事项
在进行列表查询的时候,有一点是特别需要注意的,那就是在进行不同列表的不同查询条件的查询情况下,必须每次重新构造SPQuery对象。换句话说,每做一次查询(只要查询条件不同),就要重新new一个SPQuery对象出来。否则,在程序运行的时候,仍会以最初的条件进行查询。
SharePoint服务器端对象模型 之 使用CAML进行数据查询(Part 2)的更多相关文章
- SharePoint服务器端对象模型 之 使用CAML进展数据查询
SharePoint服务器端对象模型 之 使用CAML进行数据查询 一.概述 在SharePoint的开发应用中,查询是非常常用的一种手段,根据某些筛选.排序条件,获得某个列表或者某一些列表中相应的列 ...
- SharePoint服务器端对象模型 之 使用CAML进行数据查询
(一)概述 在SharePoint的开发应用中,查询是非常常用的一种手段,根据某些筛选.排序条件,获得某个列表或者某一些列表中相应的列表条目的集合. 除去列表上的查询之外,在SharePoint中还大 ...
- SharePoint服务器端对象模型 之 使用CAML进行数据查询(Part 3)
(四)使用SPSiteDataQuery进行多列表查询 1.概述 前面介绍的列表查询有很多优势,但是它的一个缺点就是一次只能在一个列表中进行查询,在SharePoint中,提供了一个跨网站.跨列表查询 ...
- SharePoint服务器端对象模型 之 使用CAML进行数据查询(Part 4)
(五)列表查询中的阈值限制 在之前版本的SharePoint 中,如果在查询的时候没有指定返回数目,那么SharePoint将会查找该列表中所有的条目,这可能会造成在SQL表中需要返回大量的条目,极大 ...
- SharePoint 服务器端对象模型 之 使用LINQ进行数据访问操作(Part 2)
(四)使用LINQ进行列表查询 在生成实体类之后,就可以利用LINQ的强大查询能力进行SharePoint列表数据的查询了.在传统SharePoint对象模型编程中,需要首先获取网站对象,再进行其他操 ...
- SharePoint服务器端对象模型 之 使用LINQ进行数据访问操作(Part 4)
(六)高效合理的使用LINQ 1.DataContext中的两个属性 为了能够使用DataContext进行数据提交,在DataContext进行数据查询和操作的过程中,内部会进行数据状态的保持和追踪 ...
- SharePoint服务器端对象模型 完结
整个系列已完结,大概看了一眼,平均阅读量不到200.估计也没什么人看了,而且服务器端对象模型除了在某些企业开发中会用到,从2013时代开始其实已经不是SharePoint开发的最佳选择了.不过既然已经 ...
- 开启貌似已经过时很久的新坑:SharePoint服务器端对象模型
5年前(嗯,是5年前),SharePoint 2010刚发布的时候,曾经和kaneboy试图一起写一本关于SharePoint 2010开发的书,名字叫<SharePoint 2010 应用开发 ...
- SharePoint服务器端对象模型 之 序言
对于刚刚开始接触SharePoint的开发人员,即使之前有较为丰富的ASP.NET开发经验,在面对SharePoint时候可能也很难找到入手的方向.对于任何一种开发平台而言,学习开发的过程大致会包括: ...
随机推荐
- 香蕉派 Banana pi BPI-M1+ 双核开源单板计算机. 板载WIFI
Banana PI BPI-M1+是一款高性能双核开源硬件单板计算机,Banana PI BPI-M1+是一款比树莓派更强悍的双核Android4.4与Linux产品. Banana PI BP ...
- Excel 读取
using UnityEngine; using System.Collections; using NPOI; using Ionic.Zip; using System.IO; using NPO ...
- C指针解析 ------ 运算符&和*
本文是自己学习所做笔记,欢迎转载,但请注明出处:http://blog.csdn.net/jesson20121020 & 是取地址运算符.* 叫做指针运算符或间接运算符.&a 的运算 ...
- JSON基本概念及使用
JSON:JavaScript 对象表示法(JavaScript Object Notation). JSON 是存储和交换文本信息的语法.类似 XML. JSON 比 XML 更小.更快,更易解析. ...
- URAL 1750 Pakhom and the Gully 计算几何+floyd
题目链接:点击打开链接 gg.. . #pragma comment(linker, "/STACK:1024000000,1024000000") #include <cs ...
- HTML里面的文本标签
以下就是重要的标签: <html></html> 创建一个HTML文档,是网页源码的開始符和结束符,每一个网页的源码必然是以这两个标签開始和结束. <head>&l ...
- Atitit. atiJavaExConverter4js 新的特性
Atitit. atiJavaExConverter4js 新的特性 1.1. V1新特性1 1.2. V2 新特性1 2. Keyword1 3. Catch1 4. Convert n Thro ...
- Atitit.互联网 软件编程 数据库方面 架构 大牛 牛人 attilax总结
Atitit.互联网 软件编程 数据库方面 架构 大牛 牛人 attilax总结 Coolshell 称号.理论与c++ 阮一峰:: 理论高手与js高手 王银:理论高手 赵劼,网名老赵,c#高手 与理 ...
- awk overview
VARIABLES, RECORDS AND FIELDS AWK variables are dynamic; they come into existence when they are fir ...
- java - day15 - nstInner
匿名内部类 package com.javatest.mama; public class Mama { int x = 5; public static void main(String[] arg ...