scrapy初探
一 创建scrapy项目
运行命令:
scrapy startproject 项目名称
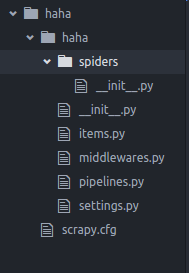
目录结构
二 定义Item容器
Item是保存爬取到数据的容器,其使用方法和python字典类似,并且提供了额外的保护机制来避免拼写错误导致的未定义字段错误
item的内容示例如下:

三 编写爬虫
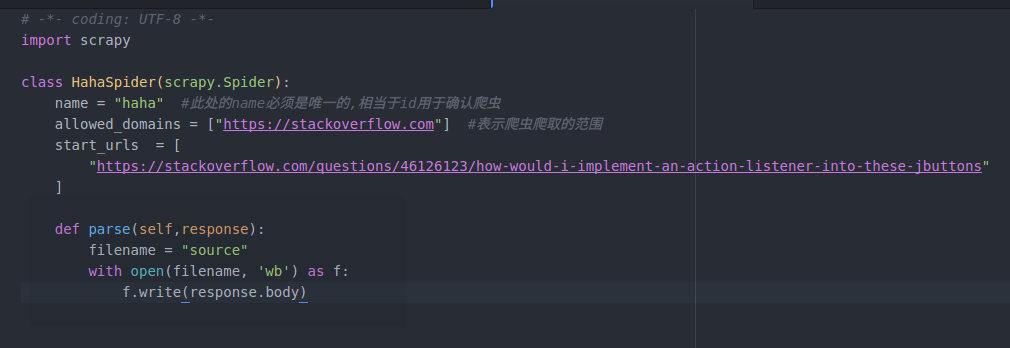
写在spiders文件夹下: Spider是用户编写用于从网站上爬取数据的类,其包含了一个用于下载的初始URL,然后是如何跟进网页中的链接以及如何分析页面中的内容,还有提取生成item的方法.
spider文件的具体内容:
在命令行运行:
scrapy crawl 爬虫名称(此处即为spider中name的名称,这也是为什么name不能重复的原因)
对页面进行爬取
注:
一 第一行的 # -*- coding: UTF-8 -*- 是当出现“Non-ASCII character 'xe5' in file”报错问题时加上,
出现问题的原因:
Python默认是以ASCII作为编码方式的,如果在自己的Python源码中包含了中文(或者其他非英语系的语言),此时即使你把自己编写的Python源文件以UTF-8格式保存了,但实际上,这依然是不行的。解决的办法只要在上面的开头部分加上上面的那一句话即可
从爬取下来的页面源码中找出我们所需要的信息的方法:
一 使用正则表达式
二 在scrapy中, 我们可以使用一种基于XPath 和 CSS 的表达机制:Scrapy Selectors(选择器)
Selectors(选择器),四个基本的方法:
xpath():传入xpath表达式,返回表达式所对应的所有节点的selector list 列表
css(): 传入css表达式,返回表达式所对应的所有节点的selector list 列表
extract():序列化该节点为unicode字符串并返回list
re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串的列表
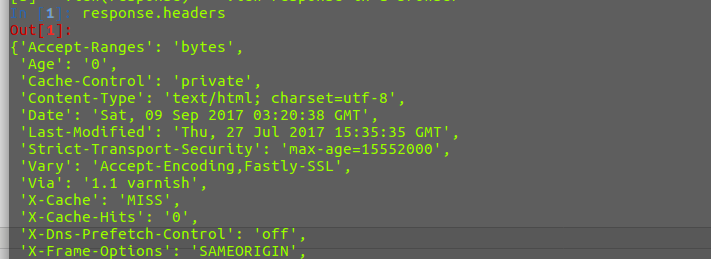
在命令行中运行scrapy shell 对爬取的网页进行分析

在shell 中输入response.headers,正确返回网页的头部信息即可
接下来可以是使用上述的四个方法对页面进行分析
使用XPath对页面进行分析:
XPath是一门在网页中查找特定信息的语言,所以用XPath来筛选数据,要比正则表达式容易些
XPath 的用法如下:
/html/head/title: 表示选择HTML文档中<head>标签内的<title>元素
/html/head/title/text():表示选择上面提到的<title>元素的文字
//td: 表示选择所有的<td>元素
//div[@class="mine"]: 表示所以具有class="mine"属性的div元素
response.xpath() == response.selector.xpath()
例如:使用response.xpath('//title'), //后面跟着一个标签的名字,表示选出所以标签为title的元素,如下,返回的是一个selector对象的列表

下面对返回的列表进行字符串化,可以使用extract()方法,返回的是一个unicode 的字符串

获取title中的文字,在后面加上/text()即可

取出所有的tag标签
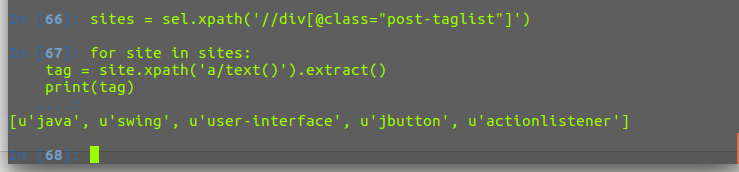
获取所有的标题和链接

四 存储内容
使用item容器,将上述爬取和筛选后的内容存入到item容器之中,在使用之前我们必须将item导入到spider中
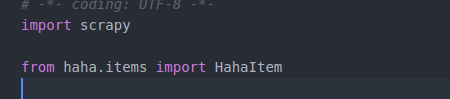
然后修改parse函数
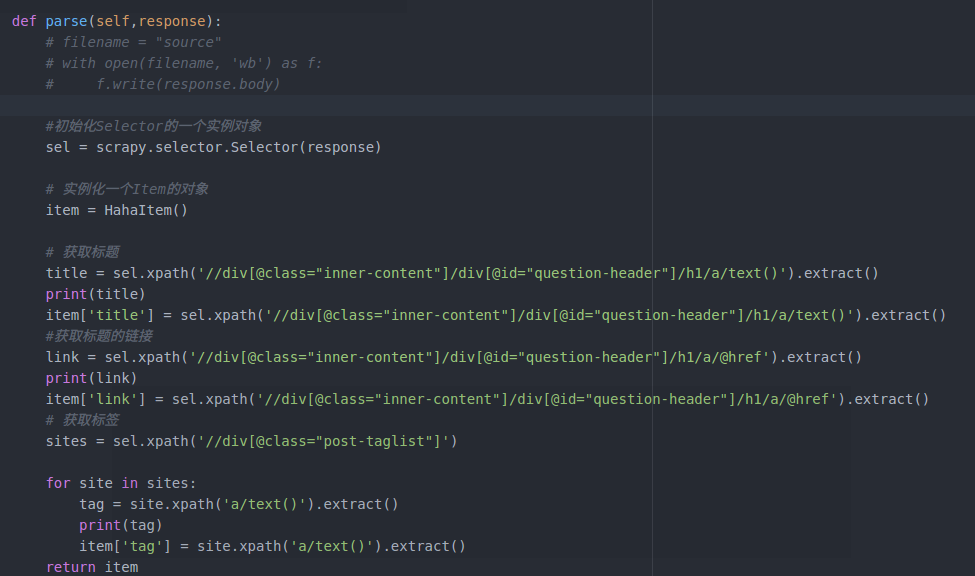
最后将数据导出,导出爬取的数据有四种格式(json,csv,xml等)
运行如下命令:
scrapy crawl haha -o items.json -t json # 此处 -o 后面跟导出的文件名 -t 后面跟的是导出的形式
成功生成item.json文件

至此,第一个scrapy爬虫就宣告完毕了!!!
scrapy初探的更多相关文章
- scrapy初探(一)-斗鱼TV直播信息抓取
由于有相关需求,最近两天开始学了一下scrapy 这次我们就以爬取斗鱼直播间为例,我们准备爬取斗鱼所有的在线直播信息, 包括1.主播昵称 2.直播领域 3.所在页面数 4.直播观看人数 5.直播间ur ...
- python之scrapy初探
1.知识点 """ Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取 Scrapy模块: 1.schedul ...
- scrapy架构初探
scrapy架构初探 引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是"开放的思想",聚合最好的想法.技术.人员, ...
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- 第一节:Scrapy开源框架初探
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 具体开发流程如下: 一.确定待抓取网站 当您需要从某 ...
- Scrapy的架构初探
Scrapy,Python开发的一个web抓取框架. 1,引言 Python即时网络爬虫启动的目标是一起把互联网变成大数据库.单纯的开放源代码并不是开源的全部,开源的核心是“开放的思想”,聚合最好的想 ...
- Scrapy框架初探
Scrapy 貌似是 Python 最出名的爬虫框架 0. 文档 中文文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.ht ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- Python爬虫 ---scrapy框架初探及实战
目录 Scrapy框架安装 操作环境介绍 安装scrapy框架(linux系统下) 检测安装是否成功 Scrapy框架爬取原理 Scrapy框架的主体结构分为五个部分: 它还有两个可以自定义下载功能的 ...
随机推荐
- deploy a ec2 and join into domain with terraform
Below is the example to convert the ps script into userdata for terraform to create instance and aut ...
- delegate, event - 里面涉及的参数类型必须完全一致,子类是不行的
public void TestF() { Test += Fun; } public void Fun(Person p) { } // 如 Person变成 SubPerson,则报错..pub ...
- CSS中的块级元素、内联元素(行内元素)
Block element 块级元素 顾名思义就是以块显示的元素,高度宽度都是可以设置的.比如我们常用 的<div>.<p>.<ul>默认状态下都是属于块级元 ...
- CSS3学习笔记之立体线框球形动画
效果截图: HTML代码: <div class="ball-box"> <div class="ball"> <div clas ...
- 51Nod 1421
1421 最大MOD值 有一个a数组,里面有n个整数.现在要从中找到两个数字(可以是同一个) ai,aj ,使得 ai mod aj 最大并且 ai ≥ aj. Input 单组测试数据. 第一行包含 ...
- DotNETCore 学习笔记 依赖注入和多环境
Dependency Injection ------------------------------------------------------------------------ ASP.NE ...
- 会议中心[APIO2009]
会议中心 思路 这一题的正解是倍增的,但是由于我太蒟蒻了,所以我选了一个不算正解但是有可以拿满分的题目学习 思路和我考场上其实差不多,只是我无法实现.... 下面我先来介绍几个数组的用途 1.s,s数 ...
- mysql导入数据库出现:Incorrect string value: '\xE7\x82\xB9\xE9\x92\x9F' for column 'chinese' at row 1
mysql导入数据库出现:Incorrect string value: '\xE7\x82\xB9\xE9\x92\x9F' for column 'chinese' at row 1 使用 sho ...
- Linux管道符、重定向与环境变量
——<Linux就该这么学>笔记 输入输出重定向输入重定向 指把文件导入到命令中输出重定向 指把原本要输出到屏幕的数据信息写入到指定文件中 输出重定向 分为标准输出重定向和错误输出重定向 ...
- 【python】python2.x 与 python3.x区别对照+缩进错误解决方法
仅仅列出我用到的,不全. 划重点: 1. urllib2 用 urllib.request 代替 2. urllib.urlencode 用 urllib.parse.urlencode 代替 3. ...