牛客网Java刷题知识点之拥塞发生的主要原因、TCP拥塞控制、TCP流量控制、TCP拥塞控制的四大过程(慢启动、拥塞避免、快速重传、快速恢复)
不多说,直接上干货!
福利 => 每天都推送
什么是拥塞?
当大量的分组进入通信子网,超出了网络的处理能力时,就会引起网络局部或整体性能下降,这种现象称为拥塞。拥塞常常使问题趋于恶化。
另一种对拥塞的解释,即对资源的需求超过了可用的资源。若网络中许多资源同时供应不足,网络的性能就要明显变坏,整个网络的吞吐量随之负荷的增大而下降。
拥塞其实是一个动态问题,我们没有办法用一个静态方案去解决,从这个意义上来说,拥塞是不可避免的。
静态解决问题办法1:
例如:增加缓存空间到一定程度时,只会加重拥塞,而不是减轻拥塞,这是因为当数据包经过长时间排队完成转发时,它们很可能早已超时,从而引起源端超时重发,而这些数据包还会继续传输到下一路由器,从而浪费网络资源,加重网络拥塞。事实上,缓存空间不足导致的丢包更多的是拥塞的“症状”而非原因。另外,增加链路带宽及提高处理能力也不能解决拥塞问题。
静态解决问题办法2:
例如:我们有四台主机ABCD连接路由器R,所有链路带宽都是1Gbps,如果A和B同时向C以1Gbps的速率发送数据,则路由器R的输入速率为2Gbps,而输出速率只能为1Gbps,从而产生拥塞。避免拥塞的方法只能是控制AB的速率,例如,都是0.5Gbps,但是,这只是一种情况,倘若D也向R发送数据,且速率为1Gbps,那么,我们先前的修正又是不成立的。
TCP的拥塞控制
为什么需要拥塞控制?
答:由于TCP采用了超时重传机制,如果拥塞不加以控制,将导致大量的报文重传,并再度引起大量的数据报丢弃,直到整个网络瘫痪。这种现象称为拥塞崩溃。
在网络实际的传输过程中,会出现拥塞的现象,网络上充斥着非常多的数据包,但是却不能按时被传送,形成网络拥塞,其实就是和平时的堵车一个性质了。TCP设计中也考虑到这一点,使用了一些算法来检测网络拥塞现象,如果拥塞产生,变会调整发送策略,减少数据包的发送来缓解网络的压力。
拥塞控制:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提:网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机、路由器,以及与降低网络传输性能有关的所有因素。
- 早期的TCP协议只有基于窗口的流控制(flow control)机制,我们简单介绍一下,并分析其不足。 在TCP中,为了实现可靠性,发送方发出一个数据段之后要等待接受方相应的确认信息,而不是直接发送下一个分组。
- 具体的技术是采用滑动窗口,以便通信双方能够充分利用带宽。滑动窗口允许发送方在收到接收方的确认之前发送多个数据段。窗口大小决定了在收到目的地确认之前,一次可以传送的数据段的最大数目。窗口大小越大,主机一次可以传输的数据段就越多。当主机传输窗口大小数目的数据段后,就必须等收到确认,才可以再传下面的数据段。例如,若视窗的大小为 1,则传完数据段后,都必须经过确认,才可以再传下一个数据段;当窗口大小等于3时,发送方可以一次传输3个数据段,等待对方确认后,再传输下面三个数据段。
- 窗口的大小在通信双方连接期间是可变的,通信双方可以通过协商动态地修改窗口大小。在TCP的每个确认中,除了指出希望收到的下一个数据段的序列号之外,还包括一个窗口通告,通告中指出了接收方还能再收多少数据段(我们可以把通告看成接收缓冲区大小)。如果通告值增大,窗口大小也相应增大;通告值减小,窗口大小也相应减小。但是我们可以发现,接收端并没有特别合适的方法来判断当前网络是否拥塞,因为它只是被动得接收,不像发送端,当发出一个数据段后,会等待对方得确认信息,如果超时,就可以认为网络已经拥塞了。
- 所以,改变窗口大小的唯一根据,就是接收端缓冲区的大小了。
- 流量控制作为接受方管理发送方发送数据的方式,用来防止接受方可用的数据缓存空间的溢出。
- 流控制是一种局部控制机制,其参与者仅仅是发送方和接收方,它只考虑了接收端的接收能力,而没有考虑到网络的传输能力;
- 而拥塞控制则注重于整体,其考虑的是整个网络的传输能力,是一种全局控制机制。正因为流控制的这种局限性,从而导致了拥塞崩溃现象的发生。
TCP拥塞控制的四大过程(慢启动、拥塞避免、快速重传、快速恢复)
为了方便起见,把发送端叫做client,接收端为server,每个segment长度为512字节,阻塞窗口长度为cwnd(简化起见,下面以segment为单位),sequence number为seq_num,acknowledges number为ack_num。通常情况下,TCP每接收到两个segment,发送一个ack。

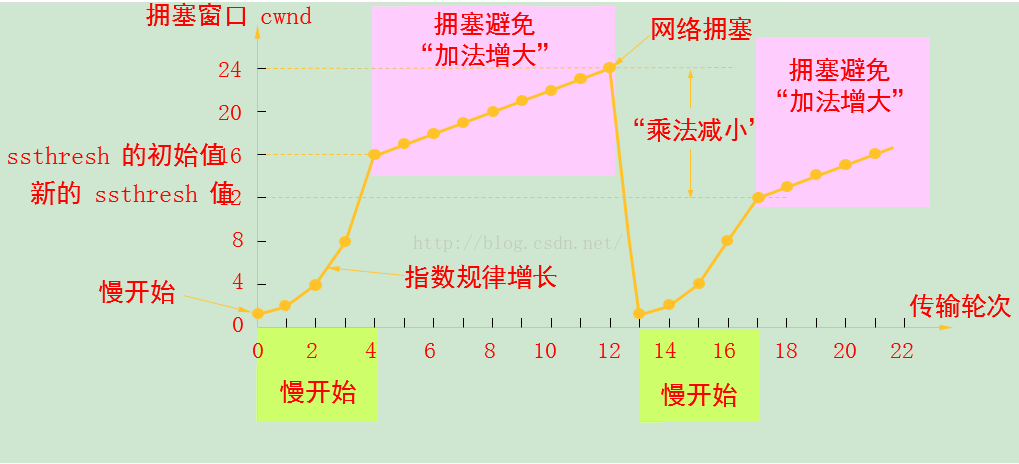
(1)慢启动算法是一个在连接上发起数据流的方法。
(2)慢启动过程:
初始时将拥塞窗口的初始为一个MSS,每次收到一个报文段的确认时发送方将拥塞窗口增大一个MSS,并发送两个最大长度的报文段。两个报文段被确认后,则发送方复每个报文段的确认增加一个MSS,使得拥塞窗口变为4个MSS,这样每过一个RTT,发送速率就翻番。因此,在慢启动阶段以指数增长。
(3)慢启动的结束:
当出现一个由超时指示的丢包事件,TCP发送方将cwnd设置为1,并重新开始慢启动。
(1)拥塞避免算法是一种处理丢失分组的方法。(当到达中间路由器的极限时,分组将被丢弃。)
(2)拥塞避免过程:
进入拥塞避免时,拥塞窗口的值大约是上次遇到拥塞时值的一半,每个RTT只将拥塞窗口的值增加1个MSS.
(3)结束条件:超时或丢包。
(1)执行条件及过程
当收到3个或3个以上的重复ACK时,就非常有可能是一个报文段丢失了。于是我们就重传丢失的数据报文段,而不等待超时定时器溢出。这就是快速重传。接下来执行的不是慢启动,而是拥塞避免,这就是快速恢复。
(2)原因:
没有执行慢启动的原因是由于收到的重复的ACK不仅仅告诉我们一个分组丢失了。由于接收方只有在收到另一个报文段时才会产生重复的ACK,而该报文段已经离开网络并进入了接收方的缓存。也就是说在收发两端之间仍然有流动的数据,而我们不想执行慢启动来突然减少数据流。
真实例子
想想看,能不能把TCP解决拥塞的方法应用到交通拥塞呢? 我们有两个原则:一是拥塞不可避免,单纯增加资源并不能避免拥塞的发生,只能用动态的方法加以解决;二是数据包守恒原则。政府花费很大资金修路,并不能避免堵车,只能从源头控制,例如首先限制车辆进入主路,根据实际情况,再慢慢增加每一个路口的车流量,但是,当达到一个阀值,增加速度要放缓,并不时探测整个主路的拥堵情况,如果情况危急,立刻封闭半个路口,并将车流量降到最低,也就是重新回复到慢启动状态。 呵呵,有趣!
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()




打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯
牛客网Java刷题知识点之拥塞发生的主要原因、TCP拥塞控制、TCP流量控制、TCP拥塞控制的四大过程(慢启动、拥塞避免、快速重传、快速恢复)的更多相关文章
- 牛客网Java刷题知识点之为什么HashMap和HashSet区别
不多说,直接上干货! HashMap 和 HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的 ...
- 牛客网Java刷题知识点之为什么HashMap不支持线程的同步,不是线程安全的?如何实现HashMap的同步?
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之Map的两种取值方式keySet和entrySet、HashMap 、Hashtable、TreeMap、LinkedHashMap、ConcurrentHashMap 、WeakHashMap
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之ArrayList 、LinkedList 、Vector 的底层实现和区别
不多说,直接上干货! 这篇我是从整体出发去写的. 牛客网Java刷题知识点之Java 集合框架的构成.集合框架中的迭代器Iterator.集合框架中的集合接口Collection(List和Set). ...
- 牛客网Java刷题知识点之垃圾回收算法过程、哪些内存需要回收、被标记需要清除对象的自我救赎、对象将根据存活的时间被分为:年轻代、年老代(Old Generation)、永久代、垃圾回收器的分类
不多说,直接上干货! 首先,大家要搞清楚,java里的内存是怎么分配的.详细见 牛客网Java刷题知识点之内存的划分(寄存器.本地方法区.方法区.栈内存和堆内存) 哪些内存需要回收 其实,一般是对堆内 ...
- 牛客网Java刷题知识点之HashMap的实现原理、HashMap的存储结构、HashMap在JDK1.6、JDK1.7、JDK1.8之间的差异以及带来的性能影响
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- 牛客网Java刷题知识点之UDP协议是否支持HTTP和HTTPS协议?为什么?TCP协议支持吗?
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- 牛客网Java刷题知识点之TCP、UDP、TCP和UDP的区别、socket、TCP编程的客户端一般步骤、TCP编程的服务器端一般步骤、UDP编程的客户端一般步骤、UDP编程的服务器端一般步骤
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- 牛客网Java刷题知识点之Java 集合框架的构成、集合框架中的迭代器Iterator、集合框架中的集合接口Collection(List和Set)、集合框架中的Map集合
不多说,直接上干货! 集合框架中包含了大量集合接口.这些接口的实现类和操作它们的算法. 集合容器因为内部的数据结构不同,有多种具体容器. 不断的向上抽取,就形成了集合框架. Map是一次添加一对元素. ...
- 牛客网Java刷题知识点之泛型概念的提出、什么是泛型、泛型在集合中的应用、泛型类、泛型方法、泛型接口、泛型限定上限、泛型限定下限、 什么时候使用上限?泛型限定通配符的体现
不多说,直接上干货! 先来看个泛型概念提出的背景的例子. GenericDemo.java package zhouls.bigdata.DataFeatureSelection; import ja ...
随机推荐
- 【留用】C#的一些好的书籍
浏览博客的时候发现一篇推荐的C#书籍,感觉真的不错,涉略过几本,水平问题,没看的很深入,正在努力,留用了!!! http://www.cnblogs.com/tongming/p/3879752.ht ...
- [转]Marshaling a SAFEARRAY of Managed Structures by P/Invoke Part 6.
1. Introduction. 1.1 Starting from part 4 I have started to discuss how to interop marshal a managed ...
- Agreement has been updated--Edit Phone Number最便捷解决办法(不需要安全提示问题和双重认证)
2018年06月04日亲测有效: CSDN博客跳转网址:
- Tensorflow报错:InvalidArgumentError: You must feed a value for placeholder tensor 'input_y' with dtype
此错误神奇之处是每次第一次运行不会报错,第二次.第三次第四次....就都报错了.关掉重启,又不报错了,运行完再运行一次立马报错!搞笑! 折磨了我半天,终于被我给解决了! 问题解决来源于这边博客:htt ...
- [agc014d] Black and White Tree
Description 有一颗n个点的树,刚开始每个点都没有颜色. Alice和Bob会轮流对这棵树的一个点涂色,Alice涂白,Bob涂黑,Alice先手. 若最后存在一个白点,使得这个 ...
- Java面向对象之接口interface 入门实例
一.基础概念 (一)接口可以简单的理解为,是一个特殊的抽象类,该抽象类中的方法都是抽象的. 接口中的成员有两种:1.全局常量 2.抽象方法 定义接口用关键字interface,接口中的成员都用固定的修 ...
- nginx公网IP无法访问浏览器
配置服务器时候发现的问题,真的是搜肠刮肚的找答案,找一下午,终于找到了答案. 一.开始找原因 在浏览器输入:http://ip,正常的话,会有页面,welcome to nginx 我这里是浏览器访问 ...
- Scanner类的用法
Scanner类,一个可以使用正则表达式来解析基本类型和字符串的简单文本扫描器. 用于扫描输入文本的实用程序.位于java.util包中. 使用Scanner接收键盘输入的字符,步骤: 1.导入Sca ...
- HTML的相关路径与绝对路径的问题---通过网络搜索整理
问题描述: 在webroot中有个index.jsp 在index.jsp中写个表单. 现在在webroot中有个sub文件夹,sub文件夹中有个submit.jsp想得到index.jsp表单 ...
- SDUT OJ 数据结构实验之二叉树三:统计叶子数
数据结构实验之二叉树三:统计叶子数 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Discuss Problem Descr ...