Mysql读写分离,主从同步实现
随着用户量的增多,数据库操作往往会成为一个系统的瓶颈所在,因此我们可以通过实现数据库的读写分离来提高系统的性能。
通过设置主从数据库实现读写分离,主库负责“写”操作,从库负责“读”操作,根据压力情况,从库可以部署多个已提高“读”的速度,借此来提高系统总体的性能。
要实现读写分离,就要解决主从数据库数据同步的问题,在主数据库写入数据后要保证从数据库的数据也要更新。
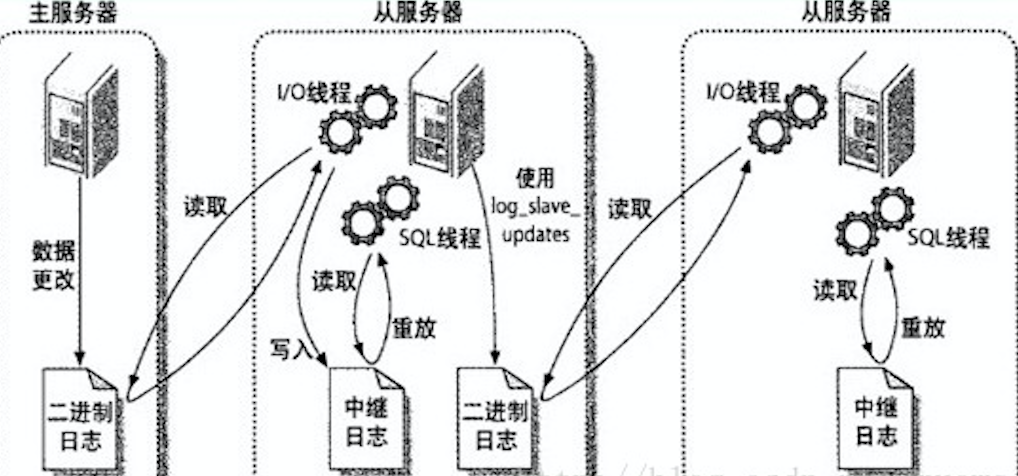
主服务器(master)记录数据库操作日志到二进制日志(Binary log),从服务器开启i/o线程将二进制日志记录的操作同步到relay log中继日志(存在从服务器的缓存中),另外sql线程将relay log(中继日志)记录的操作在从服务器执行。
记住这张图,接下来基于这个图实际设置主从数据库。
首先要有两个数据库服务器master(主库)、slave(从库)(也可以用一个服务器安装两套数据库环境运行在不同端口,slave也可以举一反三设置多个)。以下操作假设你的两台服务器上都已经安装好了mysql服务。
1.打开mysql数据库配置文件
vim /etc/my.cnf
2.在主服务器master上配置开启Binary log,主要是在[mysqld]下面添加:
#日志文件名
log-bin = mysql-bin
#主数据库端ID号
server-id = 1
3.重启mysql,并创建用于同步的账户
service mysqld restart
# 创建slave从库帐号slave_account,密码123456
mysql>grant replication slave on *.* to 'slave_account'@'从库ip' identified by '123456'; # 更新数据库权限
mysql>flush privileges;
4.检查配置效果,进入主数据库并执行
mysql> SHOW MASTER STATUS;

注:执行完这个步骤后不要再操作主数据库了,防止主数据库状态值变化
5.配置从服务器的 my.cnf
在[mysqld]节点下面添加:
server-id = 2
这里面的server-id 一定要和主库的不同。
6.重启从数据库
service mysql restart
7.执行同步命令(进入从数据库执行)
mysql>change master to master_host='主库ip',master_port=端口号,master_user='slave_account',master_password='123456',master_log_file='mysql-bin.000003',master_log_pos=9049;
8.开启同步
mysql> start slave;
检查从数据库状态
mysql > show slave status \G
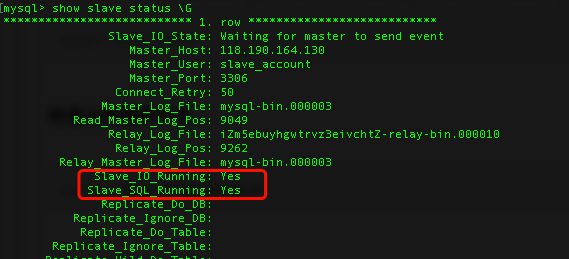
Slave_IO_Running及Slave_SQL_Running进程必须正常运行,即YES状态,否则说明同步失败。
接下来在主库的操作,在从库都会执行了。我们可以主库负责写,从库负责读,达到读写分离的效果。
Mysql读写分离,主从同步实现的更多相关文章
- mysql读写分离 主从同步
MySQL主从复制与读写分离的实现 转载 2013年01月17日 18:20:12 MySQL主从复制与读写分离 MySQL主从复制(Master-Slave)与读写分离(MySQL-Proxy) ...
- Mysql读写分离——主从数据库+Atlas
mysql集群 最近在参加项目开发微信小程序后台,由于用户数量巨大,且后台程序并不是很完美,所以对用户的体验很是不友好(简单说就是很卡).赶巧最近正在翻阅<大型网站系统与Java中间件实践> ...
- mysql数据库的主从同步,实现读写分离 g
https://blog.csdn.net/qq_15092079/article/details/81672920 前言 1 分别在两台centos 7系统上安装mysql 5.7 2 master ...
- mysql数据库的主从同步,实现读写分离
大型网站为了软解大量的并发访问,除了在网站实现分布式负载均衡,远远不够.到了数据业务层.数据访问层,如果还是传统的数据结构,或者只是单单靠一台服务器来处理如此多的数据库连接操作,数据库必然会崩溃,特别 ...
- Mysql读写分离与主从数据库设置方案
Mysql读写分离与主从数据库设置方案 亿仁网 18-10-0711:31 Mysql无非四个功能:增,删,改,读.而将增删改和读分离操作.这样有利于提高系统性能.下面是非常直观的操作: 1.配置: ...
- amoeba实现MySQL读写分离
amoeba实现MySQL读写分离 准备环境:主机A和主机B作主从配置,IP地址为192.168.131.129和192.168.131.130,主机C作为中间件,也就是作为代理服务器,IP地址为19 ...
- 使用Atlas实现MySQL读写分离+MySQL-(Master-Slave)配置
参考博文: MySQL-(Master-Slave)配置 本人按照博友北在北方的配置已成功 我使用的是 mysql5.6.27版本. 使用Atlas实现MySQL读写分离 数据切分——Atlas读 ...
- [记录]MySQL读写分离(Atlas和MySQL-proxy)
MySQL读写分离(Atlas和MySQL-proxy) 一.阿里云使用Atlas从外网访问MySQL(RDS) (同样的方式修改配置文件可以实现代理也可以实现读写分离,具体看使用场景) 1.在跳板机 ...
- docker环境 mysql读写分离 mycat maxscale
#mysql读写分离测试 环境centos 7.4 ,docker 17.12 ,docker-compose mysql 5.7 主从 mycat 1.6 读写分离 maxscale 2.2.4 读 ...
- YII配置mysql读写分离
Mysql 读写分离 YIi 配置 <?php return [ 'class' => 'yii\db\Connection', 'masterConfig' => [ // 'ds ...
随机推荐
- caffe-windows之手写体数字识别例程mnist
caffe-windows之手写体数字识别例程mnist 一.训练测试网络模型 1.准备数据 Caffe不是直接处理原始数据的,而是由预处理程序将原始数据变换存储为LMDB格式,这种方式可以保持较高的 ...
- 使用 iframe + postMessage 实现跨域通信
在实际项目开发中可能会碰到在 a.com 页面中嵌套 b.com 页面,这时第一反应是使用 iframe,但是产品又提出在 a.com 中操作,b.com 中进行显示,或者相反. 1.postMess ...
- TiDB, Distributed Database
https://www.zhihu.com/topic/20062171/top-answers
- 解析angularjs中的绑定策略
一.首先回顾一下有哪些绑定策略? 看这个实在是有点抽象了,我们来看具体的实例分析吧! 二.简单的Demo实例 @绑定:传递一个字符串作为属性的值.比如 str : ‘@string’ 控制器中代码部分 ...
- javascript Object与Array用法
引用类型:引用类型是一种数据结构,用于将数据和功能组织在一起.引用类型的值是引用类型的一个实例. 一.Object ECMAScript中的对象其实就是一组数据和功能的结合. Object类型其实是所 ...
- 使用describe命令进行Kubernetes pod错误排查
我有一个pod名叫another,用kubectl create创建后发现过了29分钟,状态还是处于ContainerCreating阶段. 使用kubectl describe命令检查: 从错误消息 ...
- HDU 2795 Billboard 【线段树维护区间最大值&&查询变形】
任意门:http://acm.hdu.edu.cn/showproblem.php?pid=2795 Billboard Time Limit: 20000/8000 MS (Java/Others) ...
- Vue状态管理-Bus
1.父子组件之间进行通讯: 父组件通过属性和子组件通讯,子组件通过事件和父组件通讯.vue2.x只允许单向数据传递. 先定义一个子组件AInput.vue: <template> < ...
- PyCharm Notes | PyCharm 使用笔记(远程访问服务器code配置指南)
PyCharm is a strong IDE for python programmer. Not only because it has a similar face with VS or som ...
- java基础知识一览(二)
一.java基础知识 1.一个文件中只能有一个public的类,因为他的类名要求和文件名相同. 2.classpath变量可以设置其它目录下的类. 例如:类文件所在目录是:F:\Javajdk,那么没 ...