HDFS学习总结
1.什么是Hadoop
管理网络中跨多台计算机存储的文件系统称为分布式文件系统
面临的挑战:使文件系统能容忍节点故障且不丢失任何数据
不适合的特点:低时间延迟的数据访问&大量的小文件&多用户写入,任意修改文件
2. HDFS的概念
元数据
hdfs的目录结构及每一个文件的块信息(块的ID,块的副本数量,块的存放位置)
由namenode负责
数据块
默认为64MB,最小化寻址开销
#分块的好处:
1. 一个文件的大小可以大于网络中任意一个磁盘的容量
2. 使用块抽象而非整个文件作为存储单元,大大简化了存储子系统的设计。
3. 适用于数据备份,提供数据容错能力和可用性。将每个块复制到少数几个独立的机器上,默认为3个。
namenode和datanode
管理者-工作者模式运行
namenode:
管理文件系统的命名空间,(永久)命名空间镜像文件和编辑日志文件
(不永久,系统启动时由数据节点重建)记录每个文件中各个块所在的数据节点信息
datanode:
存储并检索数据块,定期向namenode发送它们所存储的块的列表。
如何对namenode进行容错:
1. 备份那些组成文件系统元数据持久状态的文件。将持久状态写入本地磁盘的同时,写入一个远程挂载的网络文件系统(NFS)。
2. 辅助namenode,定期通过编辑日志合并命名空间镜像,防止编辑日志过大。
#节点全部失效,怎么办?
一般把NFS上的namenode元数据复制到辅助namenode并作为新的主namenode运行。
3.namenode元数据管理机制示意图
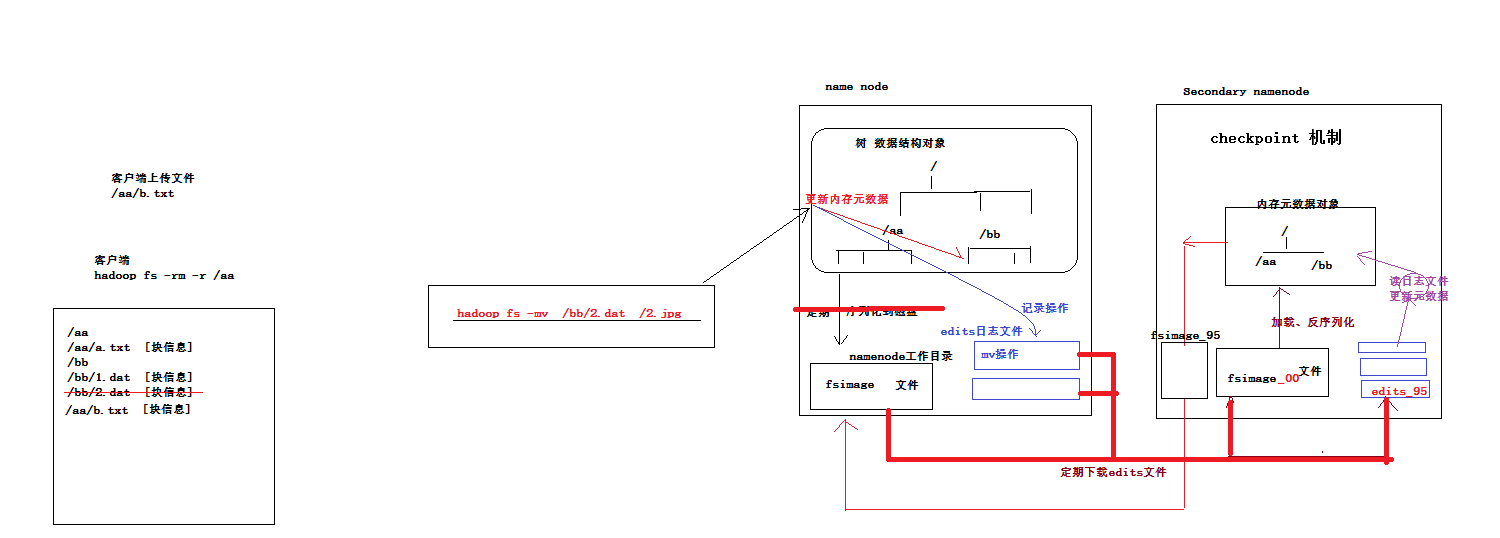
内存中有一份完整的元数据(内存meta data)
磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
用于衔接内存meta data和持久化元数据镜像fsimage之间的操作日志(edits文件)注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta data中
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage(只有第一次需要下载)下载到本地,并加载到内存进行merge(这个过程称为checkpoint)。
4.向HDFS写入数据时的流程
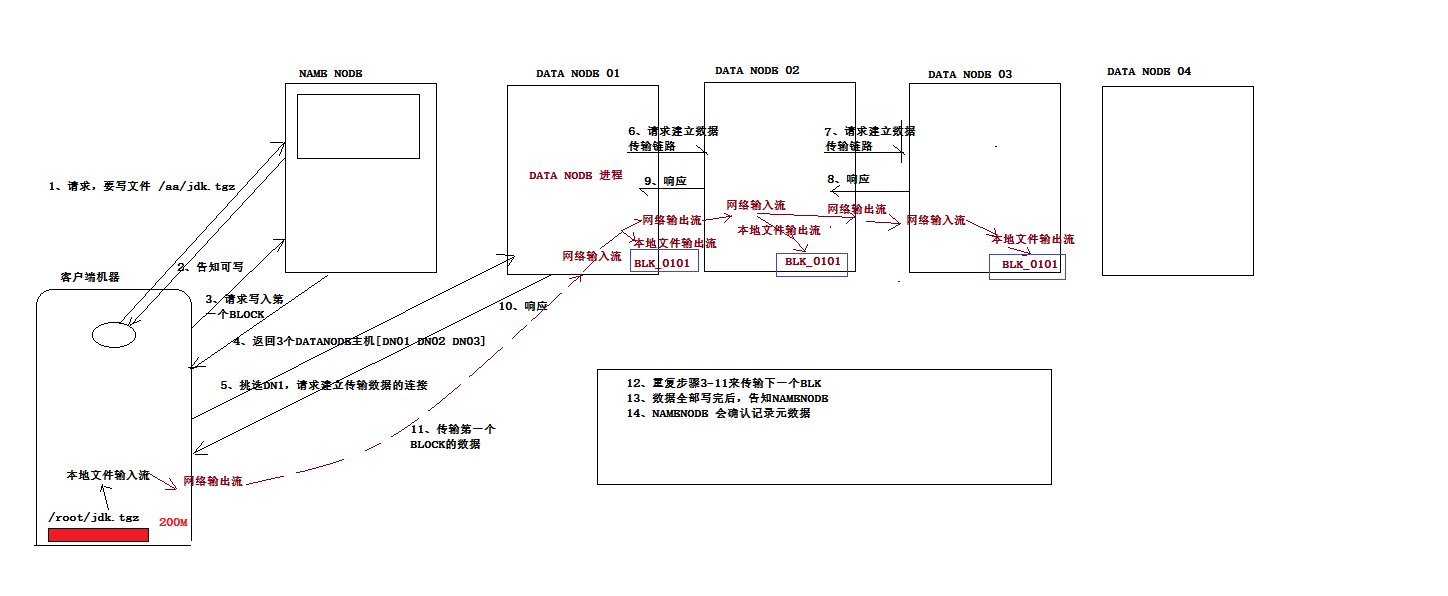
写入期间如果发生故障,则执行:
(1)关闭管线,确认把队列中的任何数据包都添加回数据队列的最前端,以确保故障节点下游的节点不会漏掉数据包。
(2)为存储在另一正常节点的当前数据块指定一个新的标识,并将该标识传送给namenode,以便故障节点在恢复后可以删除存储的部分数据包。
(3)从管线中删除故障节点,并把余下的数据块写入管线中的两个正常的节点。namenode注意到复本量不足时,会在另一个节点上创建一个新的复本。
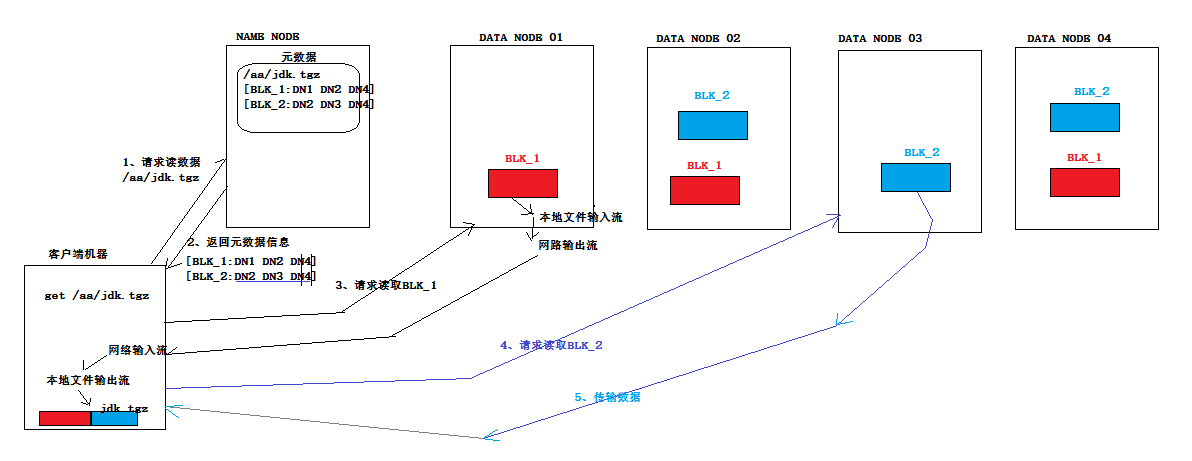
5.从HDFS读取数据时的流程
6.网络拓补和Hadoop
如何计算两个节点间的距离?
同一节点中的进程<同一机架上的不同节点<同一数据中心中不同机架上的节点<不同数据中心中的节点
7.复本的布局
可靠性、写入带宽和读取带宽
默认的策略:
在运行客户端的节点/随机选一个节点 作为第一个
和第一个不同的机架中的节点 作为第二个
和第二个相同的机架,不同节点 作为第三个
一旦选定后,会根据网络拓补创建一个管线。
稳定性:两个机架
写入带宽:写入操作只需要遍历一个交换机
读取性能:可以从两个机架中进行选择读取
集群中块的均匀分布:客户端只在本地机架写入一个块
8.数据完整性
检测数据是否损坏的常见措施:
在数据第一次引入系统时计算校验和,并在数据通过一个不可靠通道进行传输时再次计算校验和,如果不匹配,则说明有损坏,但不能修复数据,常用的错误检测码为CRC-32.
HDFS的数据完整性
对写入和读取的数据分别计算与验证校验和
数据校验的几种场景:
(1)客户端向datanode发送数据,最后一个datanode收到数据后,验证数据的验证和与客户端的是否一致。
(2)客户端从datanode读取数据时,也会验证校验和,并记录在datanode上。(这些对检测损坏的磁盘很有价值)
(3)datanode会在后台线程中运行一个datablockscanner,从而定期验证存储在这个datanode上的所有数据块。
HDFS常见面试题:
1. HDFS 中的 block 默认保存3份
2. HDFS 默认 BlockSize 是 64MB(2.7.2版本,本地模式)128MB(2.7.2版本,分布式模式)
3. Client 端上传文件的时候下列哪项正确:
- Client端将文件切分为Block,依次上传
- Client只上传数据到一台DataNode,然后由NameNode负责Block复制工作
4.DataNode负责 HDFS 数据存储
5.关于SecondaryNameNode 哪项是正确的?(C)
A.它是NameNode的热备
B.它对内存没有要求
C.他的目的使帮助NameNode合并编辑日志,减少NameNode 启动时间
6.下列哪个程序通常与 NameNode 在一个节点启动?(D)
A.SecondaryNameNode
B.DataNode
C.TaskTracker
D.JobTracker
*****
hadoop的集群是基于master/slave模式,namenode和jobtracker属于master,datanode和tasktracker属于slave,master只有一个,而slave有多个。
SecondaryNameNode内存需求和NameNode在一个数量级上,所以通常secondary NameNode(运行在单独的物理机器上)和 NameNode 运行在不同的机器上。
JobTracker对应于NameNode,TaskTracker对应于DataNode。
DataNode和NameNode是针对数据存放来而言的。JobTracker和TaskTracker是对于MapReduce执行而言的。
mapreduce中几个主要概念,mapreduce 整体上可以分为这么几条执行线索:
jobclient,JobTracker与TaskTracker。
1)JobClient会在用户端通过JobClient类将已经配置参数打包成jar文件的应用存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每一个Task(即 MapTask 和 ReduceTask)并将它们分发到各个TaskTracker服务中去执行。
2)JobTracker是一master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务。task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。一般情况应该把JobTracker 部署在单独的机器上。
3)TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。TaskTracker 都需要运行在HDFS的DataNode上。
*****
7.文件大小默认为 64M,改为 128M 有啥影响?
增加文件块大小,需要增加磁盘的传输速率。
8.HDFS的存储机制(读取和写入)
9.secondarynamenode工作机制
1)第一阶段:namenode启动
(1)第一次启动namenode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求
(3)namenode记录操作日志,更新滚动日志。
(4)namenode在内存中对数据进行增删改查
2)第二阶段:Secondary NameNode工作
(1)SecondaryNameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
(2)SecondaryNameNode请求执行checkpoint。
(3)namenode滚动正在写的edits日志
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode
(5)SecondaryNameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint
(7)拷贝fsimage.chkpoint到namenode
(8)namenode将fsimage.chkpoint重新命名成fsimage
10. NameNode与SecondaryNameNode 的区别与联系?
1)机制流程同上;
2)区别
(1)NameNode负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
(2)SecondaryNameNode主要用于定期合并命名空间镜像和命名空间镜像的编辑日志。
3)联系:
(1)SecondaryNameNode中保存了一份和namenode一致的镜像文件(fsimage)和编辑日志(edits)。
(2)在主namenode发生故障时(假设没有及时备份数据),可以从SecondaryNameNode恢复数据。
11. namenode内存包含哪些,具体如何分配
NameNode整个内存结构大致可以分成四大部分:Namespace、BlocksMap、NetworkTopology及其它。
1)Namespace:维护整个文件系统的目录树结构及目录树上的状态变化;
2)BlockManager:维护整个文件系统中与数据块相关的信息及数据块的状态变化;
3)NetworkTopology:维护机架拓扑及DataNode信息,机架感知的基础;
4)其它:
LeaseManager:读写的互斥同步就是靠Lease实现,支持HDFS的Write-Once-Read-Many的核心数据结构;
CacheManager:Hadoop 2.3.0引入的集中式缓存新特性,支持集中式缓存的管理,实现memory-locality提升读性能;
SnapshotManager:Hadoop 2.1.0引入的Snapshot新特性,用于数据备份、回滚,以防止因用户误操作导致集群出现数据问题;
DelegationTokenSecretManager:管理HDFS的安全访问;
另外还有临时数据信息、统计信息metrics等等。
NameNode常驻内存主要被Namespace和BlockManager使用,二者使用占比分别接近50%。其它部分内存开销较小且相对固定,与Namespace和BlockManager相比基本可以忽略。
HDFS学习总结的更多相关文章
- hadoop之HDFS学习笔记(二)
主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制:数据上传下载流程 1.hdfs的核心工作原理 1.1.namenode元数据管理要点 1.什么是元数据? h ...
- hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令:业务系统中日志生成机制,HDFS的java客户端api基本使用. 1.什么是 ...
- hadoop之hdfs学习
简介 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Go ...
- 二、HDFS学习
Hadoop Distributed File System 简称HDFS 一.HDFS设计目标 1.支持海量的数据,硬件错误是常态,因此需要 ,就是备份 2.一次写多次读 ...
- HDFS学习
HDFS体系结构 HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)(如图所示).名称节点作为中心服务器, ...
- HDFS学习指南
本篇HDFS组件基于CDH5进行安装,安装过程:https://www.cnblogs.com/dmjx/p/10037066.html 角色分布 hdp02.yxdev.wx:HDFS server ...
- HDFS学习笔记(2)hdfs_shell & JavaAPI
FileSystem shell指令 官方文档: HDFS Commands Reference appendToFile cat checksum chgrp chmod chown copyFro ...
- HDFS学习笔记(1)初探HDFS
Hadoop分布式文件系统(Hadoop Distributed File System, HDFS) 分布式文件系统是一种同意文件通过网络在多台主机上分享的文件系统.可让多机器上的多用户分享文件和存 ...
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
随机推荐
- js匿名函数使用&传参
function () { alert("error"); } //报错:匿名函数不能直接调用 使用 0x01 (function () { alert("Success ...
- .NET开源工作流RoadFlow-表单设计-数据表格
数据表格即在表单中显示一个table,该table数据可以来自任意自定义的来源: 数据类型:指定表格的数据源类型 1.datatable,即.net中的System.Data.DataTable 2. ...
- Hadoop的安装与配置(虚拟机中的伪分布模式)
1引言 hadoop如今已经成为大数据处理中不可缺少的关键技术,在如今大数据爆炸的时代,hadoop给我们处理海量数据提供了强有力的技术支撑.因此,了解hadoop的原理与应用方法是必要的技术知识. ...
- SharePoint 2013 - Client Side Rendering
1. Client side rendering 代码结构为: (function () { // Create object that have the context information ab ...
- XUtils3 的 环境搭建与简单使用
XUtils3 的 环境搭建 环境搭建三部曲 ----------------------- 说明 : author 修雨轩陈 使用andorid Studio 已经创建了一个项目 并且自己需要使用 ...
- CSS3布局样式
CSS3多列布局columns 为了能在Web页面中方便实现类似报纸.杂志那种多列排版的布局,W3C特意给CSS3增加了一个多列布局模块(CSS Multi Column Layout Module) ...
- Unity Android 真机调试
官方文档 https://docs.unity3d.com/Manual/AttachingMonoDevelopDebuggerToAnAndroidDevice.html 然而 按照官方文档 很多 ...
- Mantis去掉登录界面的“注册一个新账号”链接
Mantis1.1.2主界面提供了新账号注册功能,但是只能注册默认权限的帐号.不是很实用,那就干脆去掉吧. (1) 打开Mantis目录下的login_page.php和lost_pwd_page.p ...
- percona mysql 5.7再centerOS 7上的安装
第一次测试装的,还不是很熟练.很多东西不太对,以后还回改进 一.卸载包检查是否安装有MySQL Server: rpm -qa | grep mysql rpm -qa | grep mariadb ...
- aws查看官方centos镜像imageid
aws ec2 describe-images --owners aws-marketplace --filters Name=product-code,Values=aw0evgkw8e5c1q41 ...