生成对抗式网络 GAN的理解
转自:https://zhuanlan.zhihu.com/p/24767059,感谢分享
生成式对抗网络(GAN)是近年来大热的深度学习模型。最近正好有空看了这方面的一些论文,跑了一个GAN的代码,于是写了这篇文章来介绍一下GAN。
本文主要分为三个部分:
- 介绍原始的GAN的原理
- 同样非常重要的DCGAN的原理
- 如何在Tensorflow跑DCGAN的代码,生成如题图所示的动漫头像,附送数据集哦 :-)
一、GAN原理介绍
说到GAN第一篇要看的paper当然是Ian Goodfellow大牛的Generative Adversarial Networks(arxiv:https://arxiv.org/abs/1406.2661),这篇paper算是这个领域的开山之作。
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
- G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
- D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
以上只是大致说了一下GAN的核心原理,如何用数学语言描述呢?这里直接摘录论文里的公式:
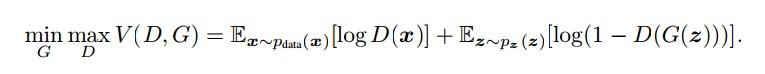 简单分析一下这个公式:
简单分析一下这个公式:
- 整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
- D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
- G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
- D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)
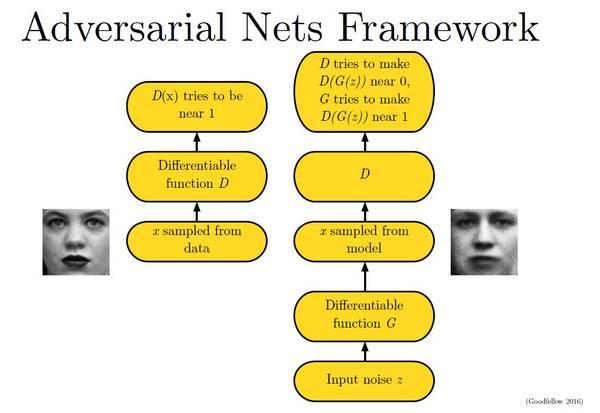
下面这幅图片很好地描述了这个过程:
那么如何用随机梯度下降法训练D和G?论文中也给出了算法:
 这里红框圈出的部分是我们要额外注意的。第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。
这里红框圈出的部分是我们要额外注意的。第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。
二、DCGAN原理介绍
我们知道深度学习中对图像处理应用最好的模型是CNN,那么如何把CNN与GAN结合?DCGAN是这方面最好的尝试之一(论文地址:[1511.06434] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)
DCGAN的原理和GAN是一样的,这里就不在赘述。它只是把上述的G和D换成了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
- 取消所有pooling层。G网络中使用转置卷积(transposed convolutional layer)进行上采样,D网络中用加入stride的卷积代替pooling。
- 在D和G中均使用batch normalization
- 去掉FC层,使网络变为全卷积网络
- G网络中使用ReLU作为激活函数,最后一层使用tanh
- D网络中使用LeakyReLU作为激活函数
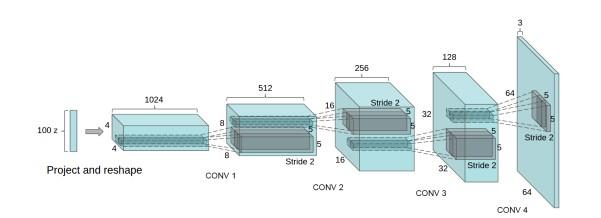
DCGAN中的G网络示意:
三、DCGAN in Tensorflow
好了,上面说了一通原理,下面说点有意思的实践部分的内容。
DCGAN的原作者用DCGAN生成LSUN的卧室图片,这并不是特别有意思。之前在网上看到一篇文章 Chainerで顔イラストの自動生成 - Qiita ,是用DCGAN生成动漫人物头像的,效果如下:

这是个很有趣的实践内容。可惜原文是用Chainer做的,这个框架使用的人不多。下面我们就在Tensorflow中复现这个结果。
1. 原始数据集的搜集
首先我们需要用爬虫爬取大量的动漫图片,原文是在这个网站:http://safebooru.donmai.us/中爬取的。我尝试的时候,发现在我的网络环境下无法访问这个网站,于是我就写了一个简单的爬虫爬了另外一个著名的动漫图库网站:konachan.net - Konachan.com Anime Wallpapers。
爬虫代码如下:
import requests
from bs4 import BeautifulSoup
import os
import traceback
def download(url, filename):
if os.path.exists(filename):
print('file exists!')
return
try:
r = requests.get(url, stream=True, timeout=60)
r.raise_for_status()
with open(filename, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
f.flush()
return filename
except KeyboardInterrupt:
if os.path.exists(filename):
os.remove(filename)
raise KeyboardInterrupt
except Exception:
traceback.print_exc()
if os.path.exists(filename):
os.remove(filename)
if os.path.exists('imgs') is False:
os.makedirs('imgs')
start = 1
end = 8000
for i in range(start, end + 1):
url = 'http://konachan.net/post?page=%d&tags=' % i
html = requests.get(url).text
soup = BeautifulSoup(html, 'html.parser')
for img in soup.find_all('img', class_="preview"):
target_url = 'http:' + img['src']
filename = os.path.join('imgs', target_url.split('/')[-1])
download(target_url, filename)
print('%d / %d' % (i, end))
这个爬虫大概跑了一天,爬下来12万张图片,大概是这样的:
可以看到这里面的图片大多数比较杂乱,还不能直接作为数据训练,我们需要用合适的工具,截取人物的头像进行训练。
2. 头像截取
截取头像和原文一样,直接使用github上一个基于opencv的工具:nagadomi/lbpcascade_animeface。
简单包装下代码:
import cv2
import sys
import os.path
from glob import glob
def detect(filename, cascade_file="lbpcascade_animeface.xml"):
if not os.path.isfile(cascade_file):
raise RuntimeError("%s: not found" % cascade_file)
cascade = cv2.CascadeClassifier(cascade_file)
image = cv2.imread(filename)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
faces = cascade.detectMultiScale(gray,
# detector options
scaleFactor=1.1,
minNeighbors=5,
minSize=(48, 48))
for i, (x, y, w, h) in enumerate(faces):
face = image[y: y + h, x:x + w, :]
face = cv2.resize(face, (96, 96))
save_filename = '%s-%d.jpg' % (os.path.basename(filename).split('.')[0], i)
cv2.imwrite("faces/" + save_filename, face)
if __name__ == '__main__':
if os.path.exists('faces') is False:
os.makedirs('faces')
file_list = glob('imgs/*.jpg')
for filename in file_list:
detect(filename)
截取头像后的人物数据:
 这样就可以用来训练了!
这样就可以用来训练了!
如果你不想从头开始爬图片,可以直接使用我爬好的头像数据(275M,约5万多张图片):https://pan.baidu.com/s/1eSifHcA 提取码:g5qa
3. 训练
DCGAN在Tensorflow中已经有人造好了轮子:carpedm20/DCGAN-tensorflow,我们直接使用这个代码就可以了。
不过原始代码中只提供了有限的几个数据库,如何训练自己的数据?在model.py中我们找到读数据的几行代码:
if config.dataset == 'mnist':
data_X, data_y = self.load_mnist()
else:
data = glob(os.path.join("./data", config.dataset, "*.jpg"))
这样读数据的逻辑就很清楚了,我们在data文件夹中再新建一个anime文件夹,把图片直接放到这个文件夹里,运行时指定--dataset anime即可。
运行指令(参数含义:指定生成的图片的尺寸为48x48,我们图片的大小是96x96,跑300个epoch):
python main.py --image_size 96 --output_size 48 --dataset anime --is_crop True --is_train True --epoch 300 --input_fname_pattern "*.jpg"
4. 结果
第1个epoch跑完(只有一点点轮廓):
 第5个epoch之后的结果:
第5个epoch之后的结果: 第10个epoch:
第10个epoch:
 200个epoch,仔细看有些图片确实是足以以假乱真的:
200个epoch,仔细看有些图片确实是足以以假乱真的:

题图是我从第300个epoch生成的。
四、总结和后续
简单介绍了一下GAN和DCGAN的原理。以及如何使用Tensorflow做一个简单的生成图片的demo。
一些后续阅读:
- Ian Goodfellow对GAN一系列工作总结的ppt,确实精彩,推荐:独家 | GAN之父NIPS 2016演讲现场直击:全方位解读生成对抗网络的原理及未来(附PPT)
- GAN论文汇总,包含code:zhangqianhui/AdversarialNetsPapers
生成对抗式网络 GAN的理解的更多相关文章
- gan对抗式网络
感觉好厉害,由上图噪声,生成左图噪声生成右图以假乱真的图片, gan网络原理: 本弱又盗了一坨博文,不是我写的,如下:(跪膜各路大神) 前面我们已经讲完了一般的深层网络,适用于图像的卷积神经网络,适用 ...
- 生成对抗网络GAN与DCGAN的理解
作者在进行GAN学习中遇到的问题汇总到下方,并进行解读讲解,下面提到的题目是李宏毅老师机器学习课程的作业6(GAN) 一.GAN 网络上有关GAN和DCGAN的讲解已经很多,在这里不再加以赘述,放几个 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- AI佳作解读系列(六) - 生成对抗网络(GAN)综述精华
注:本文来自机器之心的PaperWeekly系列:万字综述之生成对抗网络(GAN),如有侵权,请联系删除,谢谢! 前阵子学习 GAN 的过程发现现在的 GAN 综述文章大都是 2016 年 Ian G ...
- 生成对抗网络(GAN)的18个绝妙应用
https://juejin.im/post/5d3fb44e6fb9a06b2e3ccd4e 生成对抗网络(GAN)是生成模型的一种神经网络架构. 生成模型指在现存样本的基础上,使用模型来生成新案例 ...
- GAN实战笔记——第四章深度卷积生成对抗网络(DCGAN)
深度卷积生成对抗网络(DCGAN) 我们在第3章实现了一个GAN,其生成器和判别器是具有单个隐藏层的简单前馈神经网络.尽管很简单,但GAN的生成器充分训练后得到的手写数字图像的真实性有些还是很具说服力 ...
- GAN实战笔记——第六章渐进式增长生成对抗网络(PGGAN)
渐进式增长生成对抗网络(PGGAN) 使用 TensorFlow和 TensorFlow Hub( TFHUB)构建渐进式增长生成对抗网络( Progressive GAN, PGGAN或 PROGA ...
- [ZZ] Valse 2017 | 生成对抗网络(GAN)研究年度进展评述
Valse 2017 | 生成对抗网络(GAN)研究年度进展评述 https://www.leiphone.com/news/201704/fcG0rTSZWqgI31eY.html?viewType ...
- 生成对抗网络(GAN)相关链接汇总
1.基础知识 创始人的介绍: “GANs之父”Goodfellow 38分钟视频亲授:如何完善生成对抗网络?(上) “GAN之父”Goodfellow与网友互动:关于GAN的11个问题(附视频) 进一 ...
随机推荐
- jeesite模块解析,功能实现
做为十分优秀的开源框架,JeeSite拥有着很多实用性的东西. 默认根路径跳转 定义了无Controller的path<->view直接映射 <mvc:view-controller ...
- 64位的notepad++没有插件管理
下载的64位的notepad++没有插件管理:需要自己下载这个插件: - plugin manager的下载地址为:https://github.com/bruderstein/nppPluginMa ...
- codeforces1073d Berland Fair 思维(暴力删除)
题目传送门 题目大意:一圈人围起来卖糖果,标号从1-n,每个位置的糖果都有自己的价格,一个人拿着钱从q开始走,能买则买,不能买则走到下一家,问最多能买多少件物品. 思路:此题的关键是不能买则走到下一家 ...
- C#工具类之XmlNode扩展类
using System; using System.Linq; using System.Xml; /// <summary> /// XmlNodeHelper /// </su ...
- Highcharts的一些属性
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- [转] Spring Boot 揭秘与实战(二) 数据存储篇 - ElasticSearch
[From] http://www.tuicool.com/articles/JBvQrmj 本文讲解Spring Boot基础下,如何使用 ElasticSearch,实现全文搜索. 版本须知 sp ...
- django contenttype 表应用
Django contenttypes 应用 contenttypes 是Django内置的一个应用,可以追踪项目中所有app和model的对应关系,并记录在ContentType表中. 每当我们创建 ...
- PIE SDK主/次要分析
1.算法功能简介 主要分析功能是采用类似卷积滤波的方法将较大类别中的虚假像元归到该类中,首先定义一个变换核尺寸,然后用变换核中占主要地位(像元最多)类别数代替中心像元的类别数,次要分析相反,用变换核中 ...
- 理解fig,ax = plt.subplots()
fig = plt.figure() ax = fig.add_subplot(1,1,1) fig, ax = plt.subplots(1,3),其中参数1和3分别代表子图的行数和列数,一共有 1 ...
- 关于i18n
现在工作主要负责小程序端,很少负责backend.最近的一个任务是配置多语言.因为一开始都是写死的中文,现在需要把那些变成英文. 狂搜了一波,其实网上的方法都不怎好.(可能就是一开始看的时候觉得好.) ...