Python数据聚合和分组运算(1)-GroupBy Mechanics
前言
Python的pandas包提供的数据聚合与分组运算功能很强大,也很灵活。《Python for Data Analysis》这本书第9章详细的介绍了这方面的用法,但是有些细节不常用就容易忘记,遂打算把书中这部分内容总结在博客里,以便复习查看。根据书中的章节,这部分知识包括以下四部分:
1.GroupBy Mechanics(groupby技术)
2.Data Aggregation(数据聚合)
3.Group-wise Operation and Transformation(分组级运算和转换)
4.Pivot Tables and Cross-Tabulation(透视表和交叉表)
本文是第一部分,介绍groupby技术。
一、分组原理
核心:
1.不论分组键是数组、列表、字典、Series、函数,只要其与待分组变量的轴长度一致都可以传入groupby进行分组。
2.默认axis=0按行分组,可指定axis=1对列分组。
对数据进行分组操作的过程可以概括为:split-apply-combine三步:
1.按照键值(key)或者分组变量将数据分组。
2.对于每组应用我们的函数,这一步非常灵活,可以是python自带函数,可以是我们自己编写的函数。
3.将函数计算后的结果聚合。
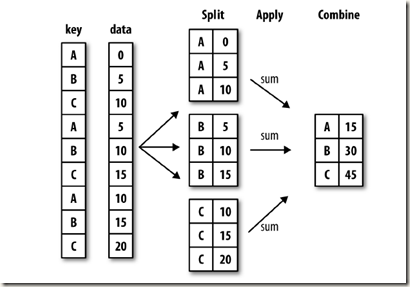
图1:分组聚合原理(图片来自《Python for Data Analysis》page 252)
import pandas as pd
import numpy as np df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.random.randn(5),
'data2' : np.random.randn(5)})
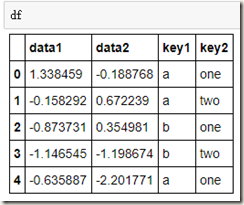
我们将key1当做我们的分组键值,对data1进行分组,再求每组的均值:
grouped = df['data1'].groupby(df['key1'])
语法很简单,但是这里需要注意grouped的数据类型,它不在是一个数据框,而是一个GroupBy对象。
grouped

实际上,在这一步,我们并没有进行任何计算仅仅是创建用key1分组后创建了一个GroupBy对象,我们后面函数的任何操作都是基于这个对象的。
求均值:
grouped.mean()

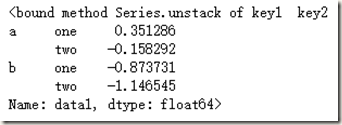
刚刚我们只是用了key1进行了分组,我们也可以使用两个分组变量,并且通过unstack方法进行结果重塑:
means = df['data1'].groupby([df['key1'], df['key2']]).mean()
means

means.unstack
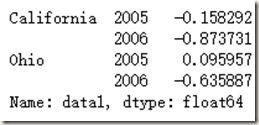
以上我们的分组变量都是df内部的Series,实际上只要是和key1等长的数组也可以:
states = np.array(['Ohio', 'California', 'California', 'Ohio', 'Ohio'])
years = np.array([2005, 2005, 2006, 2005, 2006])
df['data1'].groupby([states, years]).mean()
二、对分组进行迭代
GroupBy对象支持迭代操作,会产生一个由分组变量名和数据块组成的二元元组:
for name, group in df.groupby('key1'):
print name
print group
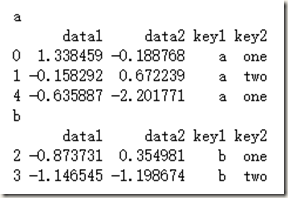
如果分组变量有两个:
for (k1,k2), group in df.groupby(['key1','key2']):
print k1,k2
print group

我们可以将上面的结果转化为list或者dict,来看看结果是什么样的:
list(df.groupby(['key1','key2']))
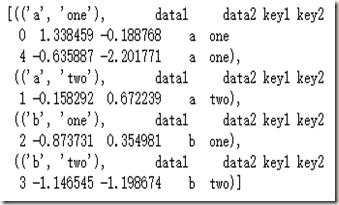
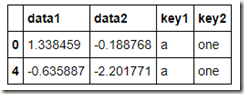
看不太清楚,我们来看看这个列表的第一个元素:
list(df.groupby(['key1','key2']))[0]

同样,我们也可以将结果转化为dict(字典):
dict(list(df.groupby(['key1','key2'])))

dict(list(df.groupby(['key1','key2'])))[('a','one')]
以上都是基于行进行分组,因为默认情况下groupby是在axis=0方向(行方向)进行分组,我们可以指定axis=1方向(列方向)进行分组:
grouped=df.groupby(df.dtypes,axis=1)
list(grouped)[0]
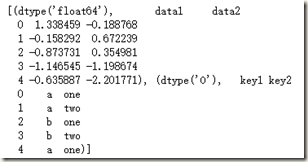
dict(list(grouped))
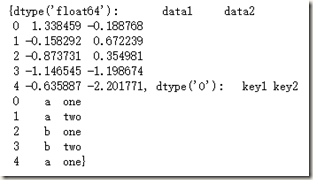
注意,
'''下面两段语句功能一样'''
df.groupby('key1')['data1']
df.data1.groupby(df.key1)
三、通过字典进行分组
people = pd.DataFrame(np.random.randn(5, 5),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis'])
people.ix[2:3, ['b', 'c']] = np.nan # 添加缺失值
people
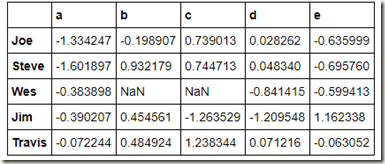
假如,我们想按列进行聚合,该怎么操作呢?
我们根据实际情况,对列名建立字典,然后将此字典传入groupby,切记指定axis=1,因为我们是对列进行分组聚合:
mapping = {'a': 'red', 'b': 'red', 'c': 'blue',
'd': 'blue', 'e': 'red', 'f' : 'orange'}
by_columns=people.groupby(mapping,axis=1)
by_columns.mean()
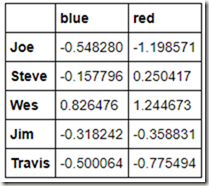
既然我们可以通过传入字典来对列进行分组,那么肯定也可以通过传入Series来对列进行分组了(Series中的index就相当字典中的key嘛):
map_series = pd.Series(mapping)
people.groupby(map_series,axis=1).count()
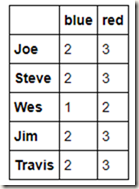
四、通过函数进行分组
刚刚我们分组时利用了dict和series建立映射,对于一些复杂的需求,我们可以直接对groupby函数传递函数名来进行分组,以刚才的people数据为例,如果我们想按行分组,分组的key是每个人名的字母长度,该怎么做呢?比较直接的想法是相对每个名字求长度,建立一个数组,然后将这个数组传入groupby,我们来试验一下:
l=[len(x) for x in people.index]
people.groupby(l).count()
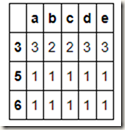
方案可行,那么有没有更快捷更优美的方法呢?当然有啦,我们只需将len这个函数名传给groupby即可:
people.groupby(len).count()
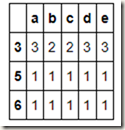
除了传递函数,我们也可以将函数和dict,series,array一起使用,毕竟最后都会统统转化为数组:
key_list = ['one', 'one', 'one', 'two', 'two']
people.groupby([len, key_list]).min()
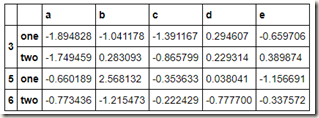
五、根据索引级别分组
刚刚我们的数据索引只有一级,当数据有多级索引时,可以通过level指定我们想要分组的索引,注意要使用axis=1表示按列:
columns = pd.MultiIndex.from_arrays([['Asian', 'Asian', 'Asian', 'America', 'America'],
['China','Japan','Singapore','United States','Canada']], names=['continent', 'country'])
hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns)
hier_df
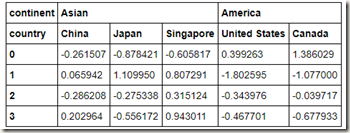
我们按洲进行分组求和:
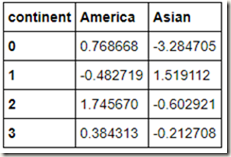
Python数据聚合和分组运算(1)-GroupBy Mechanics的更多相关文章
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- 【学习】数据聚合和分组运算【groupby】
分组键可以有多种方式,且类型不必相同 列表或数组, 某长度与待分组的轴一样 表示DataFrame某个列名的值 字典或Series,给出待分组轴上的值与分组名之间的对应关系 函数用于处理轴索引或索引中 ...
- Python数据聚合和分组运算(2)-Data Aggregation
在上一篇博客里我们讲解了在python里运用pandas对数据进行分组,这篇博客将接着讲解对分组后的数据进行聚合. 1.python 中经过优化的groupy方法 先读入本文要使用的数据集tips. ...
- 《python for data analysis》第九章,数据聚合与分组运算
# -*- coding:utf-8 -*-# <python for data analysis>第九章# 数据聚合与分组运算import pandas as pdimport nump ...
- Python之数据聚合与分组运算
Python之数据聚合与分组运算 1. 关系型数据库方便对数据进行连接.过滤.转换和聚合. 2. Hadley Wickham创建了用于表示分组运算术语"split-apply-combin ...
- Python 数据分析—第九章 数据聚合与分组运算
打算从后往前来做笔记 第九章 数据聚合与分组运算 分组 #生成数据,五行四列 df = pd.DataFrame({'key1':['a','a','b','b','a'], 'key2':['one ...
- 《利用python进行数据分析》读书笔记--第九章 数据聚合与分组运算(一)
http://www.cnblogs.com/batteryhp/p/5046450.html 对数据进行分组并对各组应用一个函数,是数据分析的重要环节.数据准备好之后,通常的任务就是计算分组统计或生 ...
- 利用python进行数据分析之数据聚合和分组运算
对数据集进行分组并对各分组应用函数是数据分析中的重要环节. group by技术 pandas对象中的数据会根据你所提供的一个或多个键被拆分为多组,拆分操作是在对象的特定轴上执行的,然后将一个函数应用 ...
- 利用Python进行数据分析-Pandas(第六部分-数据聚合与分组运算)
对数据集进行分组并对各组应用一个函数(无论是聚合还是转换),通常是数据分析工作中的重要环节.在将数据集加载.融合.准备好之后,通常是计算分组统计或生成透视表.pandas提供了一个灵活高效的group ...
随机推荐
- java中抽象类跟接口的区别
额,好吧,本来是打算转载些神马的,但是搜资料的过程中发现了一个专注与java的人,那就关注啦,以后多进他blog学习学习:http://www.cnblogs.com/chenssy/p/337670 ...
- oracle自动创建表分区
创建一个table,记录哪些表需要创建表分区 create table STAT_TABLE ( tablename VARCHAR2(), pre_partition_name VARCHAR2() ...
- 5.solr学习速成之语法
常用查询参数 q - 查询字符串,必须的. fl - 指定返回那些字段内容,用逗号或空格分隔多个. start - 返回第一条记录在完整找到结果中的偏移位置,0开始. rows - 指定返回 ...
- Mybites和hibernate的优缺点和区别
Hibernate 是当前最流行的O/R mapping框架,它出身于sf.net,现在已经成为Jboss的一部分. Mybatis 是另外一种优秀的O/R mapping框架.目前属于apache的 ...
- 3.Periodic Tasks
celery beat是一个调度器,它可以周期内指定某个worker来执行某个任务.如果我们想周期执行某个任务需要增加beat_schedule配置信息. broker_url='redis:/ ...
- peerconnection_client分析笔记
Windows版本的peerconnection_client demo是一个win32程序,入口函数为main.cc里面的wWinMain,程序整体流程就从这个入口函数下手开始分析. 1.peer ...
- idea将项目导出为war包
idea 那么好用,早就把eclipse抛弃了.不过每次都是在给项目发包的时候,不得不重新打开eclipse导出为war包.感觉自己蠢蠢的.上网查了一下教程,按照网上的教程设置好了之后,运行项目发现并 ...
- SSH免密登陆配置过程和原理解析
SSH免密登陆配置过程和原理解析 SSH免密登陆配置过很多次,但是对它的认识只限于配置,对它认证的过程和基本的原理并没有什么认识,最近又看了一下,这里对学习的结果进行记录. 提纲: 1.SSH免密登陆 ...
- Perl 变量:标量变量、数组变量、哈希变量和变量上下文
一.Perl 变量变量是存储在内存中的数据,创建一个变量即会在内存上开辟一个空间.解释器会根据变量的类型来决定其在内存中的存储空间,因此你可以为变量分配不同的数据类型,如整型.浮点型.字符串等.上一章 ...
- java Web 请求servlet绘制验证码简单例子
主要用来了解java代码怎么绘制验证码图片,实际开发中不会这样用 protected void doGet(HttpServletRequest request, HttpServletRespons ...