Hadoop介绍及集群搭建
简介
Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。它的核心组件有HDFS(分布式文件系统)解决海量数据存储、YARN(作业调度和集群资源管理框架)解决资源任务调度和MapReduce(分布式运算编程框架)解决海量数据计算。另外Hadoop如今拥有一个庞大的体系,成长为Hadoop生态圈,新出现的项目越来越多,比如zk、hive、flume等。
Hadoop的特性优点
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop集群搭建
集群简介
HADOOP 集群具体来说包含两个集群:HDFS 集群和 YARN 集群,两者逻辑上分离,但物理上常在一起。
HDFS 集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode。YARN 集群负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager。
我们以三节点为例进行搭建,角色分配如下:
bigdata-01: NameNode DataNode | ResourceManager NodeManager
bigdata-02: DataNode SecondaryNameNode| NodeManager
bigdata-03: DataNode | NodeManager
服务器准备
三台linux虚拟机,同步时间,设置主机名和域名映射,关闭防火墙,安装jdk1.8,配置ssh免密登录。
搭建步骤
1 新建文件夹,分别用来存放压缩包、解压后的文件及运行的数据
mkdir -p /export/software
mkdir -p /export/servers
mkdir -p /export/data
2 把安装文件(最好是根据linux系统版本编译好的)放到服务器上的software文件夹内 然后解压到servers文件夹内
cd /export/software
tar -zxvf hadoop-2.7.4.tar -C /export/servers/
3 修改配置文件
#转到配置文件目录
cd /export/servers/hadoop-2.7.4/etc/hadoop
修改hadoop-env.sh
#修改JAVA_HOME路径为自己jdk安装了路径
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改core-site.xml(在configuration标签里面添加)
<!--指定默认文件系统是谁 以及文件系统访问方式 并指定了hdfs的namenode在哪-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata-01:9000</value>
</property>
<!--指定hadoop运行时数据保存的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hddata</value> <!--该目录不需要自己提前创建-->
</property>
修改hdfs-site.xml(在configuration标签里面添加)
<!--指定文件副本数 默认3-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定secondarynamenode所在机器-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata-02:50090</value>
</property>
修改mapred-site.xml(在configuration标签里面添加)
<!-- 指定mr运行模式 使用yarn进行资源管理-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改yarn-site.xml(在configuration标签里面添加)
<!--指定yarn老大ResourceManager所在的机器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改slaves文件 指定集群从角色所在机器
bigdata-01
bigdata-02
bigdata-03
4 修改并重新source环境变量
vi /etc/profile
export JAVA_HOME=/export/servers/jdk1.8.0_141
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
5 格式化(初始化)集群
1、格式化准备来说是hdfs系统的初始化 创建一些自己运行所需要目录和文件
2、格式件在集群首次启动之前进行
3、只能格式化一次(本质在于格式件的时候会创建集群ID 如果多次格式化 使得主从之间集群ID标识不一致)
#以下两种格式化方式选一即可,不要两个都运行
hdfs namenode -format
hadoop namenode -format
6 启动/停止集群
cd /export/servers/hadoop-2.7.4/sbin #启动/停止HDFS集群
start-dfs.sh stop.dfs.sh
#启动/停止YARN集群
start-yarn.sh stop.yarn.sh
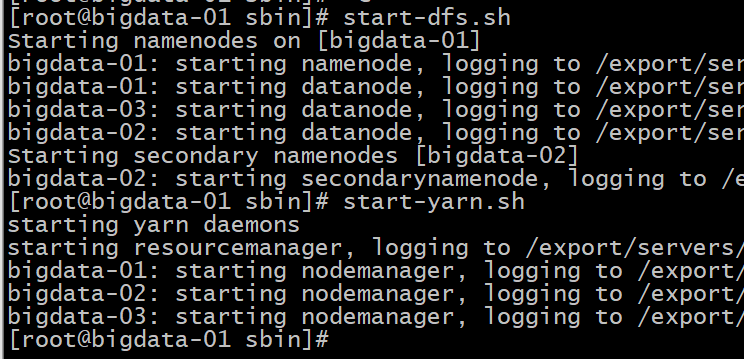
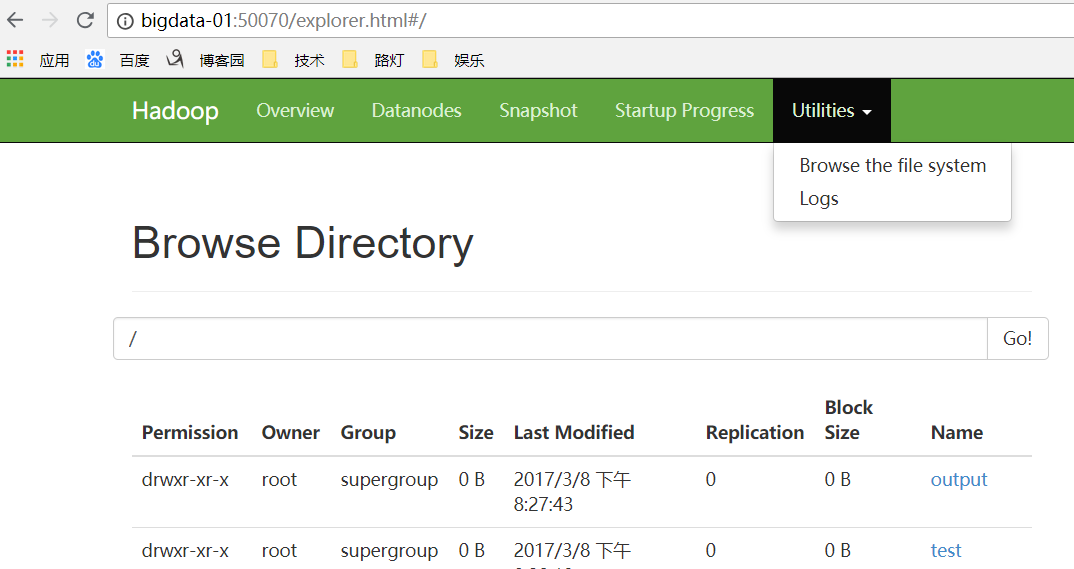
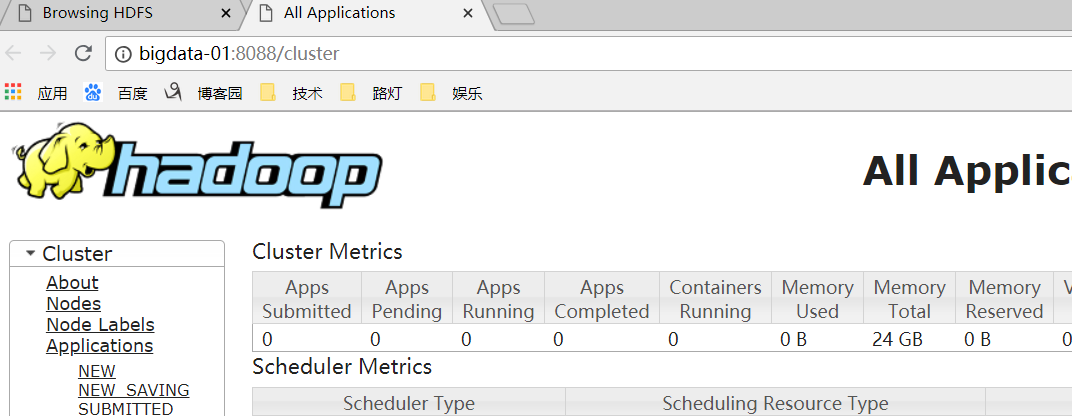
访问bigdata-01:50070 (namenode) 及 bigdata-01:8088 (resourcemanager)(windows电脑上没有配置host 就输ip+port):
Hadoop介绍及集群搭建的更多相关文章
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- 从零自学Hadoop(06):集群搭建
阅读目录 序 集群搭建 监控 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- 2. zookeeper介绍及集群搭建
ZooKeeper 概述 Zookeeper 是一个分布式协调服务的开源框架. 主要用来解决分布式集群中 应用系统的一致性问题,例如怎样避免同时操作同一数据造成脏读的问题. ZooKeeper 本质上 ...
- 物联网微消息队列MQTT介绍-EMQX集群搭建以及与SpringBoot整合
项目全部代码地址:https://github.com/Tom-shushu/work-study.git (mqtt-emqt 项目) 先看我们最后实现的一个效果 1.手机端向主题 topic111 ...
随机推荐
- C++函数模版实现
若一个程序的功能是对某种特定的数据类型进行处理,则将所处理的数据类型说明为参数,那么就可以把这个程序改写成为模版,模版可以让程序对任何其他数据类型进行同样方式的处理. 本节主要是说一下C++的函数模版 ...
- Developing on Windows Phone 8 Devices
Developing on Windows Phone 8 Deviceshttp://docs.madewithmarmalade.com/native/platformguides/wp8guid ...
- mac地址常识及获取
mac常识: 网卡地址这个概念有点混淆不清.因为实际上有两个地址,mac地址和物理地址,一般说网卡地址我是指物理地址,不知道别人怎么看?物理地址指的是网卡上的存放地址的ROM里的地址,mac地址是这块 ...
- linux之epoll
1. epoll简介 epoll 是Linux内核中的一种可扩展IO事件处理机制,最早在 Linux 2.5.44内核中引入,可被用于代替POSIX select 和 poll 系统调用,并且在具有大 ...
- bzoj 5369 最大前缀和
Written with StackEdit. Description 小\(C\)是一个算法竞赛爱好者,有一天小\(C\)遇到了一个非常难的问题:求一个序列的最大子段和. 但是小\(C\)并不会做这 ...
- 剑指offer-第四章解决面试题的思路(从上往下打印二叉树)
题目:从上往下打印二叉树的每一个节点,同一层的节点按照从左到右的顺序打印 思路:这是一个层序遍历的问题,因此要借用到队列.我们可以在打印第一个节点的同时将这个节点的左右子节点都放入队列,同样打印左右子 ...
- LeetCode Delete Operation for Two Strings
原题链接在这里:https://leetcode.com/problems/delete-operation-for-two-strings/description/ 题目: Given two wo ...
- IE兼容模式与非兼容模式下jq的写法
1. $("#LabelRepeatType").removeAttr("disabled"); $("#LabelF ...
- nagios(centreon)监控lvs
客户端配置:让nagios账户有权限查看ipvsadminvim /etc/sudoers[root@SSAVL2318 etc]# visodu /etc/sudoers加入 nagios ALL ...
- 数据科学:Pandas 和 Series 的 describe() 方法
一.Pandas 和 Series 的 describe() 方法 1)功能 功能:对数据中每一列数进行统计分析:(以“列”为单位进行统计分析) 默认只先对“number”的列进行统计分析: 一列数据 ...