[Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一、介绍
本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息。
给定关键字:视频;融合;电视
二、网站信息
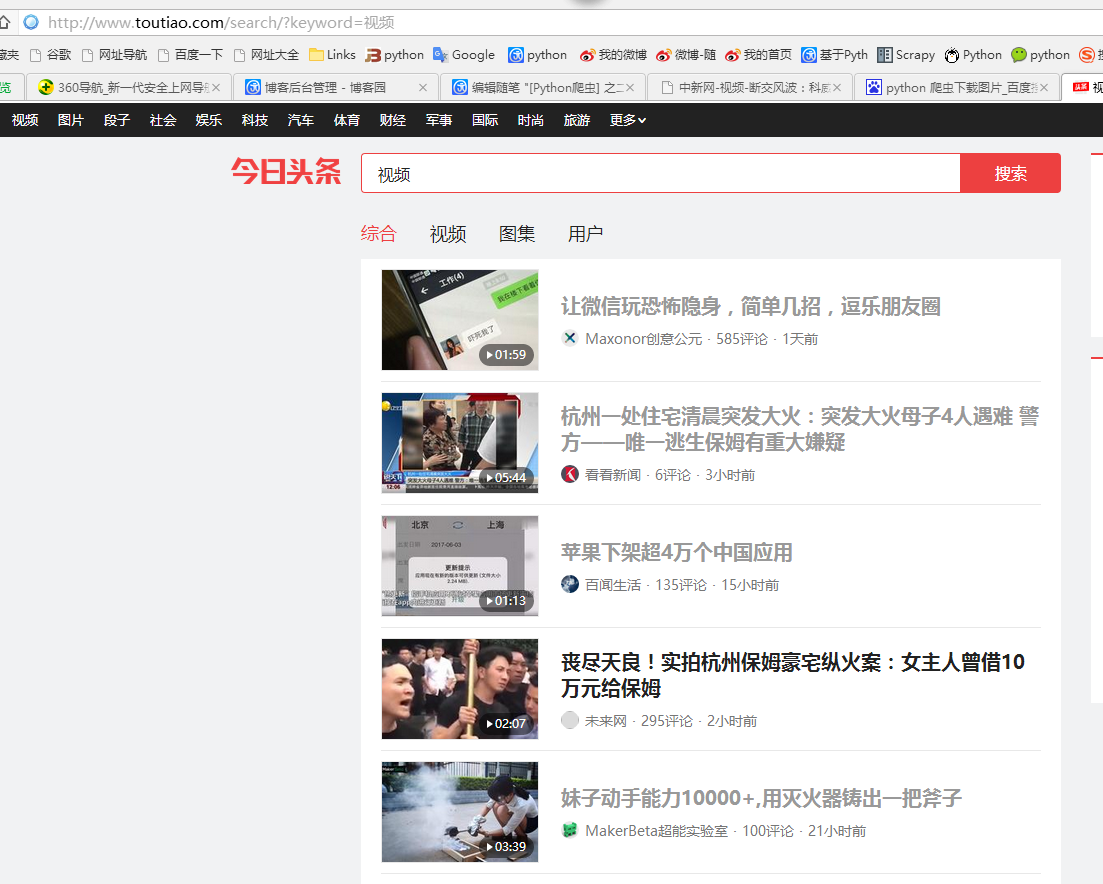
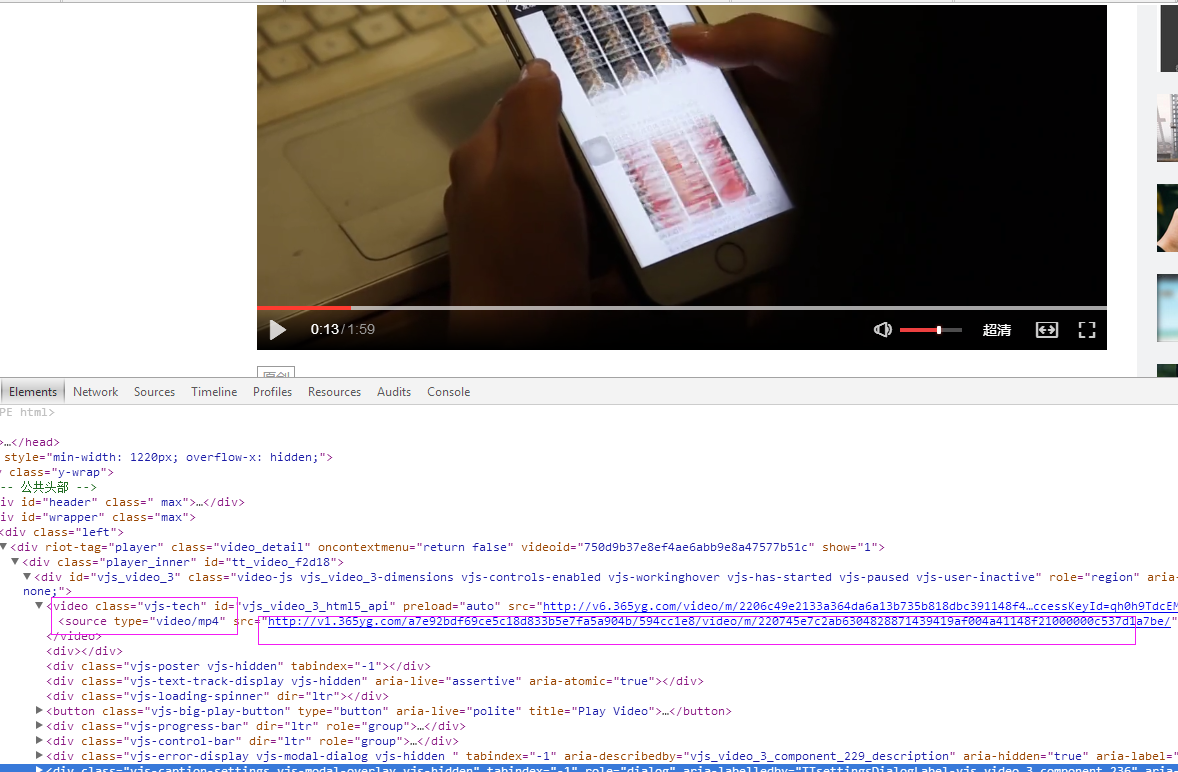
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取视频信息列表
抓取代码:Elements = doc('div[class="articleCard"]')
2、抓取图片
视频url:url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href')
videourl = dochtml('video[class="vjs-tech"]').find('source').attr('src')
四、完整代码
# coding=utf-8
import os
import re
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
from datetime import datetime
import IniFile
# from threading import Thread
from pyquery import PyQuery as pq
import LogFile
import mongoDB
import urllib
class toutiaoSpider(object):
def __init__(self): logfile = os.path.join(os.path.dirname(os.getcwd()), time.strftime('%Y-%m-%d') + '.txt')
self.log = LogFile.LogFile(logfile)
configfile = os.path.join(os.path.dirname(os.getcwd()), 'setting.conf')
cf = IniFile.ConfigFile(configfile)
webSearchUrl = cf.GetValue("toutiao", "webSearchUrl")
self.keyword_list = cf.GetValue("section", "information_keywords").split(';')
self.db = mongoDB.mongoDbBase()
self.start_urls = [] for word in self.keyword_list:
self.start_urls.append(webSearchUrl + urllib.quote(word)) self.driver = webdriver.PhantomJS()
self.wait = ui.WebDriverWait(self.driver, 2)
self.driver.maximize_window() def down_video(self, videourl):
"""
下载视频到本地
:param videourl: 视频url
"""
# http://img.tvhomeimg.com/uploads/2017/06/23/144910c41de4781ccfe9435e736ef72b.jpg
if len(videourl) > 0:
fileName = ''
if videourl.rfind('/') > 0:
fileName = time.strftime('%Y%m%d%H%M%S') + '.mp4'
u = urllib.urlopen(videourl)
data = u.read() strpath = os.path.join(os.path.dirname(os.getcwd()), 'video')
with open(os.path.join(strpath, fileName), 'wb') as f:
f.write(data) def scrapy_date(self):
strsplit = '------------------------------------------------------------------------------------'
index = 0
for link in self.start_urls:
self.driver.get(link) keyword = self.keyword_list[index]
index = index + 1
time.sleep(1) #数据比较多,延迟下,否则会出现查不到数据的情况 selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = []
self.log.WriteLog(strsplit)
self.log_print(strsplit) Elements = doc('div[class="articleCard"]') for element in Elements.items():
url = 'http://www.toutiao.com' + element.find('a[class="link title"]').attr('href')
infoList.append(url)
if len(infoList)>0:
for url in infoList:
self.driver.get(url)
htext = self.driver.execute_script("return document.documentElement.outerHTML")
dochtml = pq(htext)
videourl = dochtml('video[class="vjs-tech"]').find('source').attr('src')
if videourl:
self.down_video(videourl) self.driver.close()
self.driver.quit() obj = toutiaoSpider()
obj.scrapy_date()
[Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频的更多相关文章
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
一.介绍 本例子用Selenium +phantomjs爬取界面(https://a.jiemian.com/index.php?m=search&a=index&type=news& ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一.介绍 本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息 二.网站信息 三.数据抓 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
随机推荐
- adt 运行时,显示no target selected.
检查adt\adt-bundle-windows-x86-20131030\sdk\system-images下面是否有相关image文件.
- 【Linux驱动学习】SD卡规范学习
摘要: 学习SD卡的相关规范,包括定义,硬件特性,数据传输,命令系统等.不涉及代码. 文章针对Linux驱动开发而写,以助于理解SD卡驱动,不会涉及过多硬件内容. 纲要: 1. SD卡介绍 2. SD ...
- js向标签中添加文本或其他的简例
1.如何用js 在div内插入内容? 不是改变内容,而是插入,就是在保留原内容的基础上,在尾部添加.举个例子. 元内容<div>你好</div> 插入后<div>你 ...
- servletcontext.getRealPath()
getRealPath方法已经不建议使用了: http://blog.csdn.net/lzynihao/article/details/8315796 另外:http://veryls.iteye. ...
- js 集合
[深入理解javascript原型和闭包系列 ] 历时半月完稿,求推荐 jQuery 学习笔记(未完待续) JavaScript作用域原理(三)——作用域根据函数划分
- AC日记——平衡树练习 codevs 4244
4244 平衡树练习 思路: 有节操的人不用set也不用map: 代码: #include <cstdio> #include <cstring> #include <i ...
- C#实现HTML转图片(网页快照)
有时候我们需要将网页转成图片,那么可以使用WebBrowser来生成网页快照,废话不多说,代码如下 1.网页快照帮助类(如果是BS或控制台需要引用System.Windows.Forms类库): pu ...
- SecureCRT 的上传和下载操作
在网上找了两篇文章,分别关于ftp和ssh的上传下载,如果有好的大家可以留言分享,不胜感谢~ 因为关于ftp的比较少,就copy上面,本人并没有验证.关于ssh用sr和sz发现一条错误,而且网上也有解 ...
- NYOJ 914 Yougth的最大化【二分/最大化平均值模板/01分数规划】
914-Yougth的最大化 内存限制:64MB 时间限制:1000ms 特判: No 通过数:3 提交数:4 难度:4 题目描述: Yougth现在有n个物品的重量和价值分别是Wi和Vi,你能帮他从 ...
- ZOJ 3332 Strange Country II (竞赛图构造哈密顿通路)
链接:http://www.icpc.moe/onlinejudge/showProblem.do?problemCode=3332 本文链接:http://www.cnblogs.com/Ash-l ...