hadoop(二)hadoop集群的搭建
一、集群环境准备工作
1、修改主机名
在root 账户下 vi /etc/sysconfig/network 或者 sudo vi /etc/sysconfig/network
2、设置系统默认启动级别
在 root 账号下输入 vi /etc/inittab 将默认的5改为3即可
3、配置hadoop用户 sudoer权限
在 root 账号下,命令终端输入: vi /etc/sudoers
添加一行 hadoop ALL=(ALL) ALL
4、配置IP
5、关闭防火墙
查看防火墙状态: service iptables status
关闭防火墙: service iptables stop
开启防火墙: service iptables start
重启防火墙: service iptables restart
关闭防火墙开机启动: chkconfig iptables off
开启防火墙开机启动: chkconfig iptables on
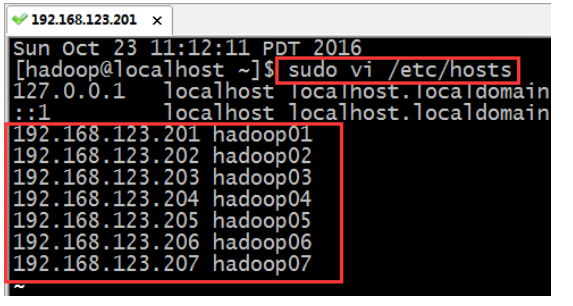
6、添加内网域名映射
vi /etc/hosts
7、安装JDK

做完以上步骤就开始克隆虚拟机了
二、hadoop集群安装
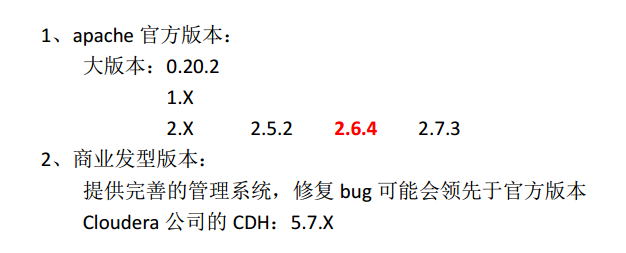
1、hadoop版本选择
2、同步服务器时间 设置crontab
ntpdate 202.120.2.101
3、配置免密登录
4、hadoop分布式集群安装(伪分布式)
4、hadoop分布式集群安装
总共三个datanode,设置副本数为2,是为了观察数据块分布方便
集群规划:
HDFS YARN
hadoop01 NameNode+DataNode NodeManager
hadoop02 DataNode+SecondaryNameNode NodeManager
hadoop03 DataNode NodeManager+ResourceManager
hadoop01是HDFS的主节点(namenode进程)、hadoop03是Yarn的主节点(ResourceManager进程)
具体安装步骤:




三、集群初步使用
1、hadoop集群启动
DFS 集群启动: sbin/start-dfs.sh
DFS 集群关闭: sbin/stop-dfs.sh
YARN 集群启动: sbin/start-yarn.sh
YARN 集群启动: sbin/stop-yarn.sh
2、HDFS初步使用
查看集群文件: hadoop fs –ls /
上传文件: hadoop fs –put filepath destpath
下载文件: hadoop fs –get destpath
创建文件夹: hadoop fs –mkdir /hadoopdata
查看文件内容: hadoop fs –cat /hadoopdata/mysecret.txt
3、mapreduce 初步使用

四、hadoop集群安装高级知识
1、为什么会有hadoop HA机制呢
HA: High Available,高可用
在 Hadoop 2.0 之前,在 HDFS 集群中 NameNode 存在单点故障 (SPOF:A single point of failure)。 对于只有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件 升级),那么整个集群将无法使用,直到 NameNode 重新启动
那如何解决呢?
HDFS 的 HA 功能通过配置 Active/Standby 两个 NameNodes 实现在集群中对 NameNode 的 热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方 式将 NameNode 很快的切换到另外一台机器。
在一个典型的 HDFS(HA) 集群中,使用两台单独的机器配置为 NameNodes 。在任何时间点, 确保 NameNodes 中只有一个处于 Active 状态,其他的处在 Standby 状态。其中 ActiveNameNode 负责集群中的所有客户端操作, StandbyNameNode 仅仅充当备机,保证一
旦 ActiveNameNode 出现问题能够快速切换。
为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提 供一个共享存储系统,可以是 NFS、 QJM( Quorum Journal Manager)或者 Zookeeper, Active Namenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则
读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。为了实现快速切换, Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标, DataNode 需要配置
NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。 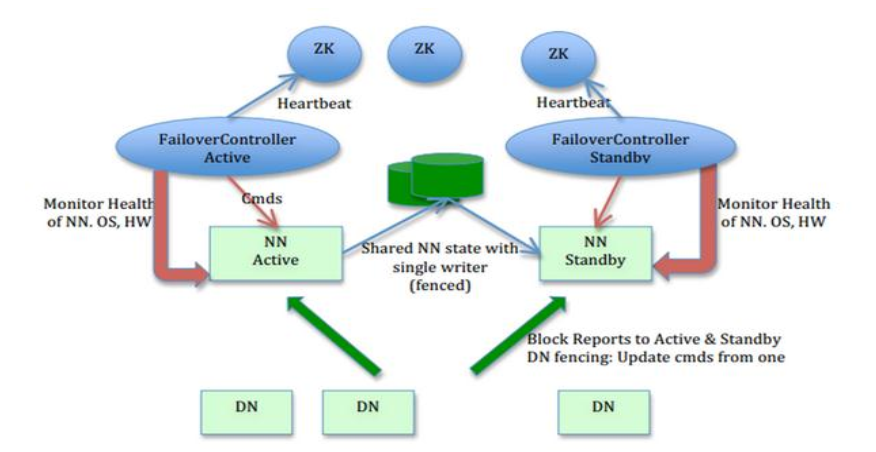
2、思考问题:secondarynamenode 和standbynamenode的区别?
Secondary NameNode不是NameNode的备份。它的作用是:定期合并fsimage与edits文件,并推送给NameNode,以及辅助恢复NameNode。
standbynamenode仅仅充当active的备机,保证一 旦 ActiveNameNode 出现问题能够快速切换,并且Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog)是同步的
3、hadoop配置机架感知
Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。这样如果本地数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;
同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,
那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,Hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,
此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,
成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务
如何配置:http://blog.csdn.net/l1028386804/article/details/51935169
4、hadoop Fedaration
(1)为什么要有Fedaration机制呢
在 Hadoop 2.0 之前, HDFS 的单 NameNode 设计带来很多问题,包括单点故障、内存受限, 制约集群扩展性和缺乏隔离机制(不同业务使用同一个 NameNode 导致业务相互影响)等。为了解决这些问题,除了用基于共享存储的 HA 解决方案,我们还可以用 HDFS 的 Federation
机制来解决这个问题。
(2)什么是Fedaration机制?
HDFS Federation 是指 HDFS 集群可同时存在多个 NameNode。这些 NameNode 分别管理一部 分数据,且共享所有 DataNode 的存储资源。
这种设计可解决单 NameNode 存在的以下几个问题:
1、 HDFS 集群扩展性。多个 NameNode 分管一部分目录,使得一个集群可以扩展到更多节 点,不再像 1.0 中那样由于内存的限制制约文件存储数目。
2、 性能更高效。多个 NameNode 管理不同的数据,且同时对外提供服务,将为用户提供 更高的读写吞吐率。
3、 良好的隔离性。用户可根据需要将不同业务数据交由不同 NameNode 管理,这样不同 业务之间影响很小。
注意问题: HDFS Federation 并不能解决单点故障问题,也就是说,每个 NameNode 都存在 在单点故障问题,你需要为每个 namenode 部署一个 backup namenode 以应对 NameNode 挂掉对业务产生的影响。
补充:
1、数据丢失 hadoop会处于安全模式
强制退出安全模式命令 bin/hadoop dfsadmin -safemode leave
hadoop(二)hadoop集群的搭建的更多相关文章
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- hadoop完全分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 准备三台虚拟机master,slave01,slave02 hado ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- Hadoop、Spark 集群环境搭建
1.基础环境搭建 1.1运行环境说明 1.1.1硬软件环境 主机操作系统:Windows 64位,四核8线程,主频3.2G,8G内存 虚拟软件:VMware Workstation Pro 虚拟机操作 ...
- Hadoop、Spark 集群环境搭建问题汇总
Hadoop 问题1: Hadoop Slave节点 NodeManager 无法启动 解决方法: yarn-site.xml reducer取数据的方式是mapreduce_shuffle 问题2: ...
- hadoop(八) - hbase集群环境搭建
1. 上传hbase安装包hbase-0.96.2-hadoop2-bin.tar.gz 2. 解压 tar -zxvf hbase-0.96.2-hadoop2-bin.tar.gz -C /clo ...
- Hadoop 学习之路(四)—— Hadoop单机伪集群环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
随机推荐
- AtCoder Grand Contest 026 D - Histogram Coloring
一列中有两个连续的元素,那么下一列只能选择选择正好相反的填色方案(因为连续的地方填色方案已经确定,其他地方也就确定了) 我们现将高度进行离散化到Has数组中,然后定义dp数组 dp[i][j] 表示前 ...
- JAVA学习笔记--接口
一.抽象类和抽象方法 在谈论接口之前,我们先了解一下抽象类和抽象方法.我们知道,在继承结构中,越往下继承,类会变得越来越明确和具体,而往上回溯,越往上,类会变得越抽象和通用.我们有时候可能会需要这样一 ...
- jQuery 判断浏览器
jQuery 浏览器判断,jQuery提供了一个 jQuery.browser 方法 来判断浏览器 可用值: safari opera msie mozilla 例如:if($.brows ...
- 亚马逊与Twitter携手电子商务
亚马逊(Amazon)与Twitter开展了合作,允许用户以Twitter消息的形式将喜欢的商品发送到购物篮中.这些高科技企业正在想办法把社交媒体和电子商务融为一体. 这一功能旨在将Twitter转变 ...
- 20162328蔡文琛 week06 大二
20162328 2017-2018-1 <程序设计与数据结构>第6周学习总结 教材学习内容总结 队列元素按FIFO的方式处理----最先进入的元素最先离开. 队列是保存重复编码k值得一种 ...
- KNN算法之图像处理二
1.看了诸多博客,初步得到结论是:KNN不适合做图像分类. 2.如果偏要用此方法进行图像分类,距离计算为:对应的每个像素代表的像素值进行绝对差值计算,最后求和.这就是“图像的距离”
- BETA事后总结
目录 所有成员 项目宣传视频链接 贡献比例 工作流程 组员分工 本组 Beta 冲刺站立会议博客链接汇总 燃尽图 原计划.达成情况及原因分析 组员:胡绪佩 组员:周政演 组员:庄卉 组员:何家伟 组员 ...
- lintcode-248-统计比给定整数小的数的个数
248-统计比给定整数小的数的个数 给定一个整数数组 (下标由 0 到 n-1,其中 n 表示数组的规模,数值范围由 0 到 10000),以及一个 查询列表.对于每一个查询,将会给你一个整数,请你返 ...
- C++ Primer Plus学习:第六章
C++入门第六章:分支语句和逻辑运算符 if语句 语法: if (test-condition) statement if else语句 if (test-condition) statement1 ...
- Visual C++ 8.0对象布局
哈哈,从M$ Visual C++ Team的Andy Rich那里又偷学到一招:VC8的隐含编译项/d1reportSingleClassLayout和/d1reportAllClassLayout ...