hadoop之 Hadoop1.x和Hadoop2.x构成对比
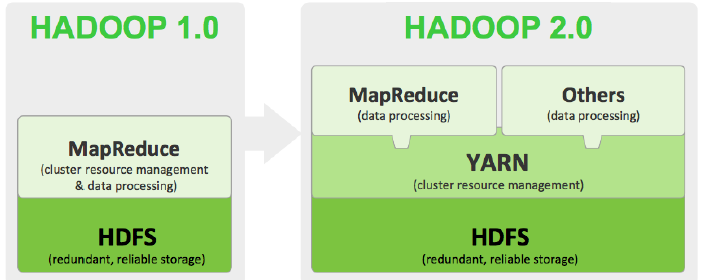
Hadoop1.x构成: HDFS、MapReduce(资源管理和任务调度);运行时环境为JobTracker和TaskTracker;
Hadoop2.0构成:HDFS、MapReduce/其他计算框架、YARN; 运行时环境为YARN
1、HDFS:HA、NameNode Federation
2、MapReduce/其他计算框架:运行在YARN之上的MapReduce通常称之为MapReduce2.0(MRv2)
3、YARN:资源管理系统(Yet Another Resource Negotiator),在其之上可以运行各种计算框架,如:MapReduce、Storm、Spark等;
HDFS2.0
解决HDFS1.0中单点故障和内存受限问题
解决单点故障: HDFS HA(High Available)
通过主备NameNode,当主NameNode发生故障时则切换到备NameNode;
解决内存受限问题: HDFS Federation
水平扩展,支持多个NameNode;
每个NameNode分管一部分目录;不同的NameNode可以分管不同的应用;
所有NameNode共享所有DataNode存储的资源;
HDFS2.0和HDFS1.0相比、仅是架构上发生了变化,使用方式不变,对HDFS使用者来说是透明的。比如说hdfs shell命令:
hadoop fs -ls /luogankun
hadoop fs -mkdir /luogankun/data
在HDFS1.0和HDFS2.0中用法是一致的。
YARN
Hadoop2.0新引入的资源管理系统
YARN核心思想:将MRv1中JobTracker的资源管理和任务调度分开,分别由ResourceManager和ApplicationMaster进程实现;
ResourceManager:负责整个集群的资源管理;整个集群只有一个;
ApplicationMaster:负责应用程序相关的事务,比如:任务调度、任务监控和任务容错;一个应用程序对应一个ApplicationMaster;
YARN引入的好处:使得多个计算框架可以运行在一个集群中,比如:MapReduce、Spark、Storm等;
MapReduce On YARN
运行在YARN之上的MapReduce称为MRv2;
将MapReduce作业直接运行在YARN上,而不是运行在由JobTracker和TaskTracker构建的MRv1之上;在Hadoop2.0中并不存在JobTracker和TaskTracker;
MRv2的模块基本功能:
1、YARN:负责资源管理和调度;
2、MRAppMaster:负责一个应用程序/作业的任务切分、任务调度、任务监控和容错;
3、Map/Reduce Task:任务驱动引擎,与MRv1一致;
每个应用程序/作业对应一个MRAppMaster,所以:
1、单个应用程序/作业运行失败,不会影响其他应用程序/作业;
2、负责应用程序/作业相关的事务,包括将从YARN分配得到的资源二次分配给内部的任务、任务切分、任务健康和容错等;
source : http://www.cnblogs.com/luogankun/p/3886989.html
hadoop之 Hadoop1.x和Hadoop2.x构成对比的更多相关文章
- 从零自学Hadoop(10):Hadoop1.x与Hadoop2.x
阅读目录 序 里程碑 Hadoop1.x与Hadoop2.x 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的 ...
- Hadoop入门进阶步步高(六)-Hadoop1.x与Hadoop2的差别
六.Hadoop1.x与Hadoop2的差别 1.变更介绍 Hadoop2相比較于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了非常大的提高,Ha ...
- Hadoop第3周练习--Hadoop2.X编译安装和实验
作业题目 位系统下进行本地编译的安装方式 选2 (1) 能否给web监控界面加上安全机制,怎样实现?抓图过程 (2)模拟namenode崩溃,例如将name目录的内容全部删除,然后通过secondar ...
- Hadoop学习(5)-- Hadoop2
在Hadoop1(版本<=0.22)中,由于NameNode和JobTracker存在单点中,这制约了hadoop的发展,当集群规模超过2000台时,NameNode和JobTracker已经不 ...
- Hadoop1.x与Hadoop2的区别
转自:http://blog.csdn.net/fenglibing/article/details/32916445 六.Hadoop1.x与Hadoop2的区别 1.变更介绍 Hadoop2相比较 ...
- Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
前段时间搭建Hadoop分布式集群,踩了不少坑,网上很多资料都写得不够详细,对于新手来说搭建起来会遇到很多问题.以下是自己根据搭建Hadoop分布式集群的经验希望给新手一些帮助.当然,建议先把HDFS ...
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Hadoop1.0 与Hadoop2.0
Hadoop1.0的局限-MapReduce •扩展性 –集群最大节点数–4000 –最大并发任务数–40000 (当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增 ...
- Hadoop1.0 和 Hadoop2.0
date: 2018-11-16 18:54:37 updated: 2018-11-16 18:54:37 1.从Hadoop整体框架来说 1.1 Hadoop1.0即第一代Hadoop,由分布式存 ...
随机推荐
- springcloud10---feign-with-hystrix_factory
package com.itmuch.cloud; import org.springframework.boot.SpringApplication; import org.springframew ...
- BootStrap一页通(样式+组件+插件)
bootstrap是一种前端框架,实现美观的页面效果.使用BootStrap的前期工作(注意顺序): <!DOCTYPT html>:因为Bootstrap用到了h5的特性,所以需要此步. ...
- JavaScript 预编译(变量提升和函数提升的原理)
本文部分内容转自https://www.cnblogs.com/CBDoctor/p/3745246.html 1.变量提升 console.log(global); // undefined var ...
- zabbix-2.4.7环境部署与初始化安装
一.zabbix简介: zabbix的特点: - 安装与配置简单,学习成本低 - 支持多语言(包括中文) - 免费开源 - 自动发现服务器与网络设备 - 分布式监视以及WEB集中管理功能 - 可以无a ...
- 20145335郝昊《网络攻防》Bof逆向基础——ShellCode注入与执行
20145335郝昊<网络攻防>Bof逆向基础--ShellCode注入与执行 实验原理 关于ShellCode:ShellCode是一段代码,作为数据发送给受攻击服务器,是溢出程序和蠕虫 ...
- 2018-2019-1 20189215 《Linux内核原理与分析》第七周作业
<庖丁解牛>第六章书本知识总结 操作系统内个实现操作系统的三大管理功能:进程管理.内存管理.文件系统.分别对应<操作系统原理>中最重要的3个抽象概念是进程.虚拟内存和文件. L ...
- imx6------watchdog导致不进系统
刚上板子,把大部分驱动都停了,不过watchdog的驱动没停,当时想没应用程序所以watchdog不用管,没想到 就是watchdog卡住了,有程序open了watchdog但是没有write,结果t ...
- QT+qtablewidget自定义表头【合并单元格】
1.把下列文件放在工程中[已上传到我的文件中] 2.代码 auto *headview = new HHeadViewClass(Qt::Horizontal, ui.tableWidget); he ...
- TypeScript 照猫画虎
定义变量类型 const num: number = 1 定义函数参数类型 const init: (p: str) => void = function(param) { alert(para ...
- openwrt下使用wget出现Failed to allocate uclient context
一.场景重现 root@OpenWrt:/# wget www.baidu.com Downloading 'www.baidu.com' Failed to allocate uclient con ...