DataStage 七、在DS中使用配置文件分配资源
DataStage序列文章
DataStage 一、安装
DataStage 二、InfoSphere Information Server进程的启动和停止
DataStage 三、配置ODBC
DataStage 错误集(持续更新)
DataStage 四和五因为包含大量图片发布不便,有兴趣学习和研究者请联系索要!!!
DataStage 六、安装和部署集群环境
1 配置文件的用途
配置文件在DS运行时第一时间被读取,如果JOB属性中设置了$APT_CONFIG_FILE参数,则DS读取该参数中配置的配置文件信息;如果没有配置则读取项目属性$APT_CONFIG_FILE参数中配置的配置文件信息;如果没有则读取默认的配置文件default.apt;配置文件告诉了DS怎么分配所需要的系统资源,如逻辑处理节点信息、temporary store、dataset storage,在某些情况同样可以在配置文件中配置更高级的资源信息,如buffer storage;使用配置文件的好处在于可以在修改了配置文件(比如增加节点或增加其它资源)的情况不修改或重新设计JOB,使其保持可用状态,而处理这些你仅仅需要在job属性或项目属性中设置$APT_CONFIG_FILE参数。在创建配置文件时我们主要要考虑的两个重要因素有:逻辑处理节点和优化并行。
2 逻辑处理节点(Logical Processing Node)
在并行作业中配置文件可以定义一个或多个逻辑处理节点,这些定义的逻辑节点信息会在并行作业运行时由Engine分配使用,如下面的逻辑节点定义:
{
node "node1"
{
fastname "dsconductor01"
pools ""
resource disk "/disk2/IBM/EngineTier/Server/Datasets" {pools ""}
resource scratchdisk "/disk2/IBM/EngineTier/Server/Scratch" {pools ""}
}
node "node2"
{
fastname "dsconductor01"
pools ""
resource disk "/disk2/IBM/EngineTier/Server/Datasets" {pools ""}
resource scratchdisk "/disk2/IBM/EngineTier/Server/Scratch" {pools ""}
}
}
注意:处理节点node1和node2是逻辑节点不是物理节点,它不代表物理CPU的个数,可以在一个物理机器中定义一个或多个逻辑节点。逻辑节点的定义决定了在并行作用运行时可以产生多少个并行进程和有多少的资源可用,等同于Unix上的物理进程数,逻辑节点越多产生的进程和使用的内存或磁盘空间(如排序操作)就越多。在IBM的官方文档中建议创建逻辑节点的个数为物理CUP数的一半,当然这还要取决于系统配置、资源可用性、资源共享、硬件和JOB设计,比如如果JOB需要高的IO操作或者要从数据库中获取大量的数据,这时可能要考虑定义多个逻辑节点来完成操作。
3 优化并行(Optimizing parallelism)
并行的个数取决于在配置文件中配置的逻辑处理节点个数,并行应该在考虑系统和JOB设计的情况下进行优化而不是最大化,并行数越多可能会很好的分布负载,但同时也增加了系统的进程数和资源的消耗,背后也隐示的增加了系统整体负载;所以并非并行越多越好,所以一定要综合考虑CPU、内存、磁盘、JOB方面因素,使并行对系统的影响和效率可维护。
**注意:如果stage中包含联结或者sort,你可能会使用Partition,比如Hash分区,如果数据的量接近等于分区数,比如下面的数据:
在这样的情况下等量的并行数会显著提高整体的性能。
3 创建配置文件示例
当安装DS时系统默认创建default.apt文件,并且该配置文件默认应用于创建的DS项目,该文件创建的规则:
- 逻辑节点数=1/2的物理CUP个数
- disk和scratchdisk 使用DS安装目录下的子目录
你要创建新的配置文件去优化并行作业,使其能够充分的使用硬件资源和系统资源,因为不同的job所需要的资源是不一样的,比如说JOB中包含排序和保存数据到磁盘文件的stage,需要高的IO操作,这时根据系统情况分配多个scratchdisk可以显著提高排序效率。做为示例我做了这样一个job;
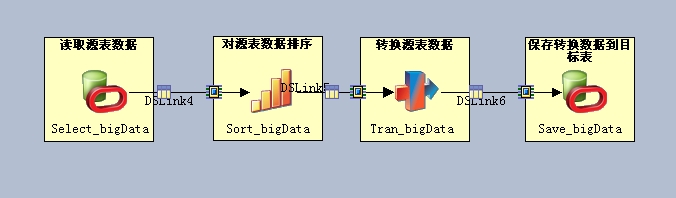
Select_bigData 从源表中读取一张包含1亿数据的表;
Sort_bigData 对源表的数据进行复杂的排序操作;
Tran_bigData 对排好序的数据进行转换;
最后将数据保存到目标表。
我为该job定义了一个config file:
/* beging of config */
{
node "node1"
{
fastname "domain01"
pools ""
resource disk "/Data/SHAREDATA/Datasets" {pools ""}
resource scratchdisk "/Data/scratch01" {pools ""}
}
node "node2"
{
fastname "domain01"
pools ""
resource disk "/Data/SHAREDATA/Datasets" {pools ""}
resource scratchdisk "/Data/scratch02" {pools ""}
}
node "node3"
{
fastname "domain01"
pools ""
resource disk "/Data/SHAREDATA/Datasets" {pools ""}
resource scratchdisk "/Data/scratch03" {pools ""}
}
node "node4"
{
fastname "domain01"
pools ""
resource disk "/Data/SHAREDATA/Datasets" {pools ""}
resource scratchdisk "/Data/scratch04" {pools ""}
}
}/* end of entire config */
在config file 中包含4个逻辑节点,so 当运行job时ds会创建4个进程并行处理;4个逻辑节点中分别分配了不同的scratchdisk,这样并行进程即可将数据以集合的方式分别写入4个scratchdisk中完成排序操作。so 在job开始前,检查了系统的ds进程情况,只有一个正在连接的dsapi_slave;
phantom printer segments!
DSnum Uid Pid Ppid C Stime Tty Time Command
sywu 12431 12430 0 11:02 ? 00:00:07 dsapi_slave 7 6 0 4
当job启动运行时,ds便读取配置文件,然后计算和分配资源;

4 phantom printer segments!
DSnum Uid Pid Ppid C Stime Tty Time Command
49932 sywu 15604 15564 0 11:52 ? 00:00:00 phantom DSD.OshMonitor Clu
49937 sywu 15599 15564 0 11:52 ? 00:00:00 phantom SH -c '/software/I
49972 sywu 15564 12431 1 11:52 ? 00:00:00 phantom DSD.RUN ClusterRea
53105 sywu 12431 12430 0 11:02 ? 00:00:10 dsapi_slave 7 6 0 4
这些并行进程同时处理不同的操作:
[domain01:dsadm]ps -ef|grep 15604
sywu 15604 15564 0 11:52 ? 00:00:00 phantom DSD.OshMonitor ClusterReadBigDataAndSaveToTab 15603 MSEVENTS.FALSE
dsadm 16816 17037 0 11:52 pts/0 00:00:00 grep 15604
[domain01:dsadm]ps -ef|grep 15599
sywu 15599 15564 0 11:52 ? 00:00:00 phantom SH -c '/software/IBM/InformationServer/Server/DSEngine/bin/OshWrapper RT_SCTEMP/ClusterReadBigDataAndSaveToTab.fifo RT_SC3/OshExecuter.sh R DUMMY -f RT_SC3/OshScript.osh -monitorport 13400 -pf RT_SC3/jpfile -impexp_charset UTF-8 -string_charset UTF-8 -input_charset UTF-8 -output_charset UTF-8 -collation_sequence OFF'
sywu 15602 15599 0 11:52 ? 00:00:00 /software/IBM/InformationServer/Server/DSEngine/bin/OshWrapper RT_SCTEMP/ClusterReadBigDataAndSaveToTab.fifo RT_SC3/OshExecuter.sh R DUMMY -f RT_SC3/OshScript.osh -monitorport 13400 -pf RT_SC3/jpfile -impexp_charset UTF-8 -string_charset UTF-8 -input_charset UTF-8 -output_charset UTF-8 -collation_sequence OFF
dsadm 16819 17037 0 11:53 pts/0 00:00:00 grep 15599
[domain01:dsadm]ps -ef|grep 15564
sywu 15564 12431 0 11:52 ? 00:00:00 phantom DSD.RUN ClusterReadBigDataAndSaveToTab 0/0/1/0/0/0/0/
sywu 15599 15564 0 11:52 ? 00:00:00 phantom SH -c '/software/IBM/InformationServer/Server/DSEngine/bin/OshWrapper RT_SCTEMP/ClusterReadBigDataAndSaveToTab.fifo RT_SC3/OshExecuter.sh R DUMMY -f RT_SC3/OshScript.osh -monitorport 13400 -pf RT_SC3/jpfile -impexp_charset UTF-8 -string_charset UTF-8 -input_charset UTF-8 -output_charset UTF-8 -collation_sequence OFF'
sywu 15604 15564 0 11:52 ? 00:00:00 phantom DSD.OshMonitor ClusterReadBigDataAndSaveToTab 15603 MSEVENTS.FALSE
dsadm 16822 17037 0 11:53 pts/0 00:00:00 grep 15564
[domain01:dsadm]ps -ef|grep 12431
sywu 12431 12430 0 11:02 ? 00:00:10 dsapi_slave 7 6 0 4
sywu 15564 12431 0 11:52 ? 00:00:00 phantom DSD.RUN ClusterReadBigDataAndSaveToTab 0/0/1/0/0/0/0/
dsadm 16826 17037 0 11:53 pts/0 00:00:00 grep 12431
每一个并行进程向相应的scratchdisk中写临时数据;
[domain01:dsadm]ls /Data/scratch01
tsort50d0A7CB tsort50db8yql tsort50d_Dflj tsort50dfY9VY tsort50djuws6 tsort50dPpmTS tsort50dTwSkn tsort50dxaZhz
tsort50d0K6rw tsort50dBD7Lr tsort50dDl1hJ tsort50dGM1PK tsort50dk3CQP tsort50dpS_7P tsort50dtWx6t tsort50dX@oqU
....
[domain01:dsadm]ls /Data/scratch02
tsort40d0A7CB tsort40dBD7Lr tsort40ddrQKv tsort40dgoGBU tsort40dKj8K3 tsort40d__Rs8 tsort40duZ4Zu tsort40dZ2z@z
tsort40d0K6rw tsort40dbEMco tsort40degDYO tsort40dgVgZs tsort40d@kl2X tsort40dSAMWF tsort40dVAwRI tsort40dzpg0g
...
[domain01:dsadm]ls /Data/scratch03
tsort90d0A7CB tsort90dBD7Lr tsort90ddrQKv tsort90dgoGBU tsort90dKj8K3 tsort90d__Rs8 tsort90duZ4Zu tsort90dZ2z@z
tsort90d0K6rw tsort90dbEMco tsort90degDYO tsort90dgVgZs tsort90d@kl2X tsort90dSAMWF tsort90dVAwRI tsort90dzpg0g
...
[domain01:dsadm]ls /Data/scratch04
tsort70d0A7CB tsort70dBD7Lr tsort70ddrQKv tsort70dgoGBU tsort70dKj8K3 tsort70d__Rs8 tsort70duZ4Zu tsort70dZ2z@z
tsort70d0K6rw tsort70dbEMco tsort70degDYO tsort70dgVgZs tsort70d@kl2X tsort70dSAMWF tsort70dVAwRI tsort70dzpg0g
tsort70d_0oKX tsort70dbo642 tsort70deP8o7 tsort70dH6oYi tsort70dL9Gnu tsort70dSG2rc tsort70dVUr3y tsort70dZrp8k
...
3.1 SMP Server配置文件
当系统运行在共享共享memory,多进程系统中,比如SMP server,假设系统有4个cpu,有4个分离的文件系统磁盘(/fdisk01,/fdisk02,/fdisk03,/fdisk04),为了更好的优化并行资源,创建如下的配置文件:
/* beging of config */
{
node "node1"
{
fastname "domain01"
pools ""
resource disk "/fdisk01/disk" {}
resource disk "/fdisk02/disk" {}
resource disk "/fdisk03/disk" {}
resource disk "/fdisk04/disk" {}
resource scratchdisk "/fdisk01/scratch" {}
resource scratchdisk "/fdisk02/scratch" {}
resource scratchdisk "/fdisk03/scratch" {}
resource scratchdisk "/fdisk04/scratch" {}
}
node "node2"
{
fastname "domain01"
pools ""
resource disk "/fdisk01/disk" {}
resource disk "/fdisk02/disk" {}
resource disk "/fdisk03/disk" {}
resource disk "/fdisk04/disk" {}
resource scratchdisk "/fdisk01/scratch" {}
resource scratchdisk "/fdisk02/scratch" {}
resource scratchdisk "/fdisk03/scratch" {}
resource scratchdisk "/fdisk04/scratch" {}
}
node "node3"
{
fastname "domain01"
pools ""
resource disk "/fdisk01/disk" {}
resource disk "/fdisk02/disk" {}
resource disk "/fdisk03/disk" {}
resource disk "/fdisk04/disk" {}
resource scratchdisk "/fdisk01/scratch" {}
resource scratchdisk "/fdisk02/scratch" {}
resource scratchdisk "/fdisk03/scratch" {}
resource scratchdisk "/fdisk04/scratch" {}
}
node "node4"
{
fastname "domain01"
pools ""
resource disk "/fdisk01/disk" {}
resource disk "/fdisk02/disk" {}
resource disk "/fdisk03/disk" {}
resource disk "/fdisk04/disk" {}
resource scratchdisk "/fdisk01/scratch" {}
resource scratchdisk "/fdisk02/scratch" {}
resource scratchdisk "/fdisk03/scratch" {}
resource scratchdisk "/fdisk04/scratch" {}
}
}/* end of entire config */
这样的配置适用于当job中包含比较复杂很难决定资源分配方式和stage需要较高的IO操作,ds计算指定的disk和scratchdisk,最大化的降低IO。
4 总结
很多情况下需要根据job的复杂程度、包含的stage以及数据量情况来创建相应的配置文件,不同的操作所需的系统、硬件资源不同,对于大数据的排序、保存到文件可能需要到较高的IO资源,对于运算、逻辑处理可能需要较高的CUP资源;创建配置文件时应综合考虑这些因素来创建;配置文件中的逻辑节点越多,可能提高并行作业效率,但同时它也增加了系统的负载。
--The end(2015-11-11)
DataStage 七、在DS中使用配置文件分配资源的更多相关文章
- springboot配置静态资源访问路径
其实在springboot中静态资源的映射文件是在resources目录下的static文件夹,springboot推荐我们将静态资源放在static文件夹下,因为默认配置就是classpath:/s ...
- SpringBoot学习(七)-->SpringBoot在web开发中的配置
SpringBoot在web开发中的配置 Web开发的自动配置类:在Maven Dependencies-->spring-boot-1.5.2.RELEASE.jar-->org.spr ...
- 聊聊并发(七)——Java中的阻塞队列
3. 阻塞队列的实现原理 聊聊并发(七)--Java中的阻塞队列 作者 方腾飞 发布于 2013年12月18日 | ArchSummit全球架构师峰会(北京站)2016年12月02-03日举办,了解更 ...
- JNDI在server.xml中的配置(全局和局部的)
总结: 全局就是在数据源server.xml中配置,然后通过和项目名相同的xml来进行映射.对所有的项目都起作用.那个项目需要就在对应的tomcat下配置一个与项目名相同的xml映射文件. 局部的就是 ...
- git在eclipse中的配置 转载
git在eclipse中的配置 转载 一_安装EGIT插件 http://download.eclipse.org/egit/updates/ 或者使用Eclipse Marketplace,搜索EG ...
- Spring Boot干货系列:(七)默认日志框架配置
Spring Boot干货系列:(七)默认日志框架配置 原创 2017-04-05 嘟嘟MD 嘟爷java超神学堂 前言 今天来介绍下Spring Boot如何配置日志logback,我刚学习的时候, ...
- struts2的占位符*在action中的配置方法
转自:https://blog.csdn.net/u012546338/article/details/68946633 在配置<action> 时,可以在 name,class,meth ...
- 关于spring中bean配置的几件小事
一.IOC和DI 1.IOC(Inversion of Control) 其思想是反转资源获取的方向.传统的资源查找方式要求组件向容器发起请求查找资源,作为回应,容器适时的返回资源:而应用了IOC之后 ...
- 详解在Linux中安装配置MySQL
最近在整理自己私人服务器上的各种阿猫阿狗,正好就顺手详细记录一下清理之后重装的步骤,今天先写点数据库的内容,关于在Linux中安装配置MySQL 安装环境 CentOS7 + MySQL5.7 下载安 ...
随机推荐
- 7-8 List Leaves(25 分)
Given a tree, you are supposed to list all the leaves in the order of top down, and left to right. I ...
- 使用ndk-stack来查找崩溃
logcat报错 Fatal signal 6 (SIGABRT) at 0x000025c9 (code=-6), thread 9703 (Thread-1277) 都是一些寄存器以及函数地址,真 ...
- 3.Appium运行时出现:Original error: Android devices must be of API level 17 or higher. Please change your device to Selendroid or upgrade Android on your device
参考博客:https://blog.csdn.net/niubitianping/article/details/52624417 1.错误信息:Original error: Android dev ...
- 黑马Python——学习之前
学习清单 学习态度
- 删除TFS项目上的文件
1.用vs(版本)开发人员命令提示输入命令进行删除 1.
- JSP Servlet之间交换数据
摘自:<轻量级Java EE企业应用实战>第三版 对于每次客户端请求而言,web服务器大致需要完成以下步骤: 1.启动单独线程 2.使用I/O流读取用户的请求参数 3.从请求数据中解析参数 ...
- Pthreads n 体问题
▶ <并行程序设计导论>第六章中讨论了 n 体问题,分别使用了 MPI,Pthreads,OpenMP 来进行实现,这里是 Pthreads 的代码,分为基本算法和简化算法(引力计算量为基 ...
- 372. Super Pow.txt
▶ 指数取模运算 ab % m ▶ 参考维基 https://en.wikipedia.org/wiki/Modular_exponentiation,给了几种计算方法:暴力计算法,保存中间结果法(分 ...
- python新里程
为什么要学Python: 2018年6月开始自学Python.因为自己目前做Linux运维,感觉自己还需要掌握一门开发语言,在Java.python.php之间毫不犹豫的选择了Python,因为Pyt ...
- C#中StreamWriter与BinaryWriter的区别兼谈编码。
原文:http://www.cnblogs.com/ybwang/archive/2010/06/12/1757409.html 参考: 1. <C#高级编程>第六版 2. 文件流和数据 ...