第二百八十八节,MySQL数据库-索引、limit分页、执行计划、慢日志查询
MySQL数据库-索引、limit分页、执行计划、慢日志查询
索引,是数据库中专门用于帮助用户快速查询数据的一种数据结构。类似于字典中的目录,查找字典内容时可以根据目录查找到数据的存放位置,然后直接获取即可。
如果没有创建索引查找数据时,是全表扫描的,也就是向查字典一样没有目录,靠一页一页的翻到目标数据位置,这样如果数据量大会相当耗时,
索引就是快速帮助用户找到目标数据,节省时间
索引简介
索引是以B+tree方式的树形结构存放数据的
详情,可以网上搜索一下B+tree
MySQL中常见索引有:
普通索引
唯一索引
主键索引
组合索引
全文索引
1、普通索引
普通索引仅有一个功能:加速查询
创建表时创建普通索引
index(创建普通索引) 索引名称 (创建索引的字段、可以是多个字段)
create table in1( -- 创建表
nid int not null auto_increment primary key, -- 创建nid字段,自增,主键
name varchar(32) not null, -- 创建字段
email varchar(64) not null, -- 创建字段
extra text,
index ix_name (name) -- 创建普通索引
) -- index(创建普通索引) 索引名称 (创建索引的字段、可以是多个字段)
向已有表创建普通索引
create(创建) index(索引) 索引名称 on 表名称(字段)
-- create(创建) index(索引) 索引名称 on 表名称(字段) create index index_name on table_name(column_name)
删除表的普通索引
drop(删除) INDEX(索引) 索引名称 on 表名称
-- drop(删除) INDEX(索引) 索引名称 on 表名称; drop INDEX index_name on table_name;
查看索引
show(查看) index(索引) 表名称;
-- show(查看) index(索引) 表名称; show index from usr;
当创建索引后,执行一个sql查询语句,用执行计划验证这个查询语句是否使用索引找到的数据【重点】
EXPLAIN表示执行计划,后面跟sql查询语句,返回的type的值如果是ref表示当前查询使用索引查询的,如果值是ALL表示当前查询使用的全表扫描
EXPLAIN执行计划返回ref
EXPLAIN SELECT * FROM usr WHERE nl = 19;

如果是全表扫描

注意:对于创建索引时如果是BLOB 和 TEXT 类型,必须指定length。
create index ix_extra on in1(extra(32));
2、唯一索引
唯一索引有两个功能:加速查询 和 唯一约束(可含null),也就是约束此列类容不允许重复
创建表时创建唯一索引
unique唯一索引
create table in1(
nid int not null auto_increment primary key,
name varchar(32) not null,
email varchar(64) not null,
extra text,
unique ix_name (name) -- 创建字段
)
-- unique(唯一) 索引名称 (索引字段)
向已有表创建唯一索引
-- create unique index 索引名 on 表名(字段、多个字段,隔开) create unique index index_usr on usr(nl,zij);
删除唯一索引
-- drop INDEX 索引名 on 表名 drop INDEX index_usr on usr;
3、主键索引
主键有两个功能:加速查询 和 唯一约束(不允许有null),也就是约束此列类容不允许重复,一张表只能有一个主键
primary key(字段名称,多个字段将组合成一个主键索引)
CREATE TABLE `usr` (
`id` int(20) NOT NULL AUTO_INCREMENT COMMENT 'id',
`yhm` char(255) NOT NULL COMMENT '用户名',
`xb` char(255) NOT NULL COMMENT '性别',
`nl` int(255) NOT NULL COMMENT '年龄',
`zij` int(255) unsigned NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8 COMMENT='用户表';
给已有表创建主键索引
alter table 表名 add primary key(列名);
-- alter table 表名 add primary key(列名); alter table usr add primary key(id);
删除主键索引
-- alter table 表名 modify 主键索引字段 字段数据类型, drop primary key; alter table usr modify id int, drop primary key;
4、组合索引
组合索引是将n个列组合成一个索引
其应用场景为:频繁的同时使用n列来进行查询,如:where n1 = 'alex' and n2 = 666。
index 索引名称 (字段1,字段2)组合普通索引
unique 索引名称 (字段1,字段2)组合唯一索引
PRIMARY KEY (字段1,字段2)组合主键索引
-- index 索引名称 (字段1,字段2)组合普通索引
index ix_name (n1,n2)
create index index_name on table_name(n1,n2) -- unique 索引名称 (字段1,字段2)组合唯一索引
unique ix_name (n1,n2)
create unique index index_usr on usr(n1,n2) -- PRIMARY KEY (字段1,字段2)组合主键索引
PRIMARY KEY (n1,n2)
alter table usr add primary key(n1,n2);
组合索引注意事项,最左前缀【重点】
1、也就是说如果是多个字段组合成一个索引,当查询字段时只查询的组合字段的左边第一个字段,是走索引的。
2、如果查询的组合字段的所有字段,也是走索引的
3、如果查询的不是索引组合字段,也不是只查询的左边第一个字段,是不走索引的
如:
create index index_usr on usr(n1,n2); -- 创建组合普通索引 SELECT * FROM usr WHERE n1 = 'x'; -- 走索引 SELECT * FROM usr WHERE n1 = 'x' AND n2 = 'x'; -- 走索引 SELECT * FROM usr WHERE n2 = 'x'; -- 不走索引
5、全文索引
全文索引,也就是向搜索引擎那样,根据一个关键词,搜索出所有数据里包含此关键词的数据,但是对中文支持不好,因为是根据空格或者分隔符分词的,所以一般我们不用这个方案
全文索引对中文起不了什么作用,索引就不说了
索引补充
1、索引
索引是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据。对于索引,会保存在额外的文件中。
2、索引种类
普通索引:仅加速查询
唯一索引:加速查询 + 列值唯一(可以有null)
主键索引:加速查询 + 列值唯一 + 表中只有一个(不可以有null)
组合索引:多列值组成一个索引,组合索引要比索引合并效率高
专门用于组合搜索,其效率大于索引合并
全文索引:对文本的内容进行分词,进行搜索
索引合并,使用多个单列索引组合搜索
覆盖索引,select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖
3、相关命令
- 查看表结构
desc 表名 - 查看生成表的SQL
show create table 表名 - 查看索引
show index from 表名 - 查看执行时间
set profiling = 1;
SQL...
show profiles;
4、使用索引和不使用索引
由于索引是专门用于加速搜索而生,所以加上索引之后,查询效率会快到飞起来。 # 有索引
mysql> select * from tb1 where name = 'wupeiqi-888';
+-----+-------------+---------------------+----------------------------------+---------------------+
| nid | name | email | radom | ctime |
+-----+-------------+---------------------+----------------------------------+---------------------+
| 889 | wupeiqi-888 | wupeiqi888@live.com | 5312269e76a16a90b8a8301d5314204b | 2016-08-03 09:33:35 |
+-----+-------------+---------------------+----------------------------------+---------------------+
1 row in set (0.00 sec) # 无索引
mysql> select * from tb1 where email = 'wupeiqi888@live.com';
+-----+-------------+---------------------+----------------------------------+---------------------+
| nid | name | email | radom | ctime |
+-----+-------------+---------------------+----------------------------------+---------------------+
| 889 | wupeiqi-888 | wupeiqi888@live.com | 5312269e76a16a90b8a8301d5314204b | 2016-08-03 09:33:35 |
+-----+-------------+---------------------+----------------------------------+---------------------+
1 row in set (1.23 sec)
5、正确使用索引
数据库表中添加索引后确实会让查询速度起飞,但前提必须是正确的使用索引来查询,如果以错误的方式使用,则即使建立索引也会不奏效。
即使建立索引,索引也不会生效:
-- like '%xx' 模糊查询
select * from tb1 where name like '%cn'; -- 表示查询tb1表里name字段里,前面可以是多个任意字符后面包含cn的所有数据,%写在前面不走索引
select * from tb1 where name like 'cn%'; -- 表示查询tb1表里name字段里,后面可以是多个任意字符前面包含cn的所有数据,%写在后面走索引 -- 使用函数
select * from tb1 where reverse(name) = 'wupeiqi'; -- 在查询条件里,对索引字段使用了函数,不走索引 -- or 条件或
select * from tb1 where nid = 1 or email = 'seven@live.com'; -- 条件或,如果两个字段都建了索引,那就走索引。如果只有一个字段建了索引,那就不走索引
-- 特别的:当or条件中有未建立索引的列才失效,以下会走索引
select * from tb1 where nid = 1 or name = 'seven'; -- 如果两个字段都建了索引,那就走索引
select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex' -- 如果只有email没建索引,其他字段都建了索引,这样是走索引的 -- 类型不一致
-- 如果列是字符串类型,传入条件是必须用引号引起来,不然也不走索引
select * from tb1 where name = 999; -- !=
select * from tb1 where name != 'alex' -- 不等于、因为取反全部,所以不走索引
-- 特别的:如果是主键,则还是会走索引
select * from tb1 where nid != 123 -- 如果不等于,取反主键索引,会走索引的 -- >
select * from tb1 where name > 'alex' -- 这种大于,不走索引
-- 特别的:如果是主键或索引是整数类型,则还是会走索引
select * from tb1 where nid > 123 -- 主键大于,走索引
select * from tb1 where num > 123 -- 索引字段整数类型,走索引 -- order by 排序
select email from tb1 order by name desc; -- 当根据索引排序时候,选择的映射如果不是索引,则不走索引 select * from tb1 order by nid desc; -- 特别的:如果对主键排序,则还是走索引: -- 组合索引最左前缀
-- 如果组合索引为:(name,email) 将这两个字段组合成一个索引
name and email -- 使用索引
name -- 使用索引
email -- 不使用索引
6、其他注意事项
避免使用select * -- 避免使用*,在取字段时能少就少取字段 count(1)或count(列) 代替 count(*) -- 因为*效率低 创建表时尽量时 char 代替 varchar -- 因为char效率高查询快 表的字段顺序固定长度的字段优先前放 -- 这样效率高点 组合索引代替多个单列索引(经常使用多个条件查询时)-- 因为组合索引要比,多个单列索引合并查询效率高 尽量使用短索引 -- 如果只有前8位字符不一样,后面都是一样的,就没必要将整个字段全部键索引,只需要将字段里的前8位建索引即可
create index index_name on table_name(nl(8)); 使用连接(JOIN)来代替子查询(Sub-Queries) -- JOIN链表查询效率高 连表时注意条件类型需一致 -- 也就是条件的数据类型一致效率高 索引散列值(重复多)不适合建索引,例:性别不适合 -- 一共就两个值男、女,基本都是重复的,建索引也不起作用 避免过度创建索引 如果大数据表导入另外的数据库时,建议先将索引去掉,导入后重建索引
7、limit分页
无论是否有索引,limit分页是一个值得关注的问题
假如一张表有5000000条数据
-- 不可取
SELECT * FROM usr LIMIT 2000000,5; -- 从两百万条,开始取5条,那么会全表扫描到两百万条的位置开始取5条,效率很低 -- 这个办法也不可取,比上面好
SELECT * FROM usr id > (SELECT id FROM usr LIMIT 2000000,1) LIMIT 5; -- 先从ID找两百万条的位置取一条id,id有索引只查ID会走索引到两百万的位置,得到ID后将ID作为查询条件,会直接从这个ID查找,不在全表扫描
分页优化方案
每页显示10条:
当前 118 120, 125 倒序:
大 小
980 970 7 6 6 5 54 43 32 21 19 98
下一页:
-- 有页面
select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid < 当前页最小值 order by nid desc limit 每页数据 *【页码-当前页】) A order by A.nid asc limit 1)
order by
nid desc
limit 10; -- 无页面
select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid < 970 order by nid desc limit 40) A order by A.nid asc limit 1)
order by
nid desc
limit 10; 上一页:
-- 有页面
select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid > 当前页最大值 order by nid asc limit 每页数据 *【当前页-页码】) A order by A.nid asc limit 1)
order by
nid desc
limit 10; -- 无页面
select
*
from
tb1
where
nid < (select nid from (select nid from tb1 where nid > 980 order by nid asc limit 20) A order by A.nid desc limit 1)
order by
nid desc
limit 10;
8、执行计划
explain + 查询SQL - 用于显示SQL执行信息参数,根据参考信息可以进行SQL优化
mysql> explain select * from tb2;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | tb2 | ALL | NULL | NULL | NULL | NULL | 2 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
1 row in set (0.00 sec)
执行计划详情
id
查询顺序标识
如:mysql> explain select * from (select nid,name from tb1 where nid < 10) as B;
+----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 9 | NULL |
| 2 | DERIVED | tb1 | range | PRIMARY | PRIMARY | 8 | NULL | 9 | Using where |
+----+-------------+------------+-------+---------------+---------+---------+------+------+-------------+
特别的:如果使用union连接气值可能为null select_type
查询类型
SIMPLE 简单查询
PRIMARY 最外层查询
SUBQUERY 映射为子查询
DERIVED 子查询
UNION 联合
UNION RESULT 使用联合的结果
...
table
正在访问的表名 type
查询时的访问方式,性能:all < index < range < index_merge < ref_or_null < ref < eq_ref < system/const
ALL 全表扫描,对于数据表从头到尾找一遍
select * from tb1;
特别的:如果有limit限制,则找到之后就不在继续向下扫描
select * from tb1 where email = 'seven@live.com'
select * from tb1 where email = 'seven@live.com' limit 1;
虽然上述两个语句都会进行全表扫描,第二句使用了limit,则找到一个后就不再继续扫描。 INDEX 全索引扫描,对索引从头到尾找一遍
select nid from tb1; RANGE 对索引列进行范围查找
select * from tb1 where name < 'alex';
PS:
between and
in
> >= < <= 操作
注意:!= 和 > 符号 除外 INDEX_MERGE 合并索引,使用多个单列索引搜索
select * from tb1 where name = 'alex' or nid in (11,22,33); REF 根据索引查找一个或多个值
select * from tb1 where name = 'seven'; EQ_REF 连接时使用primary key 或 unique类型
select tb2.nid,tb1.name from tb2 left join tb1 on tb2.nid = tb1.nid; CONST 常量
表最多有一个匹配行,因为仅有一行,在这行的列值可被优化器剩余部分认为是常数,const表很快,因为它们只读取一次。
select nid from tb1 where nid = 2 ; SYSTEM 系统
表仅有一行(=系统表)。这是const联接类型的一个特例。
select * from (select nid from tb1 where nid = 1) as A;
possible_keys
可能使用的索引 key
真实使用的 key_len
MySQL中使用索引字节长度 rows
mysql估计为了找到所需的行而要读取的行数 ------ 只是预估值,表示扫描了多少行 extra
该列包含MySQL解决查询的详细信息
“Using index”
此值表示mysql将使用覆盖索引,以避免访问表。不要把覆盖索引和index访问类型弄混了。
“Using where”
这意味着mysql服务器将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。有时“Using where”的出现就是一个暗示:查询可受益于不同的索引。
“Using temporary”
这意味着mysql在对查询结果排序时会使用一个临时表。
“Using filesort”
这意味着mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成。
“Range checked for each record(index map: N)”
这个意味着没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的。
9、慢日志查询
慢日志查询,就是用一个日志文件记录,sql语句查询数据库时,耗时比较长的,或者没有使用索引的情况记录一下,我们可以根据这个日志记录情况来对数据库进行优化。
数据库自带记录慢日志功能,默认没有开启,需要我们手动开启一下
开启慢日志相关全局变量
slow_query_log = OFF -- 是否开启慢日志记录
long_query_time = 2 -- 时间限制,sql查询超过此时间,则记录,默认是10秒
slow_query_log_file = /usr/slow.log -- 日志文件,日志文件路径
log_queries_not_using_indexes = OFF -- 未使用索引的搜索是否记录
开启记录慢日志功能有两种方法:
1、在数据库配置文件my-default.ini文件里配置,在文件里写入相关全局变量,保存后需要重启数据库【推荐】
my-default.ini文件在安装的数据库目录里

# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
# *** DO NOT EDIT THIS FILE. It's a template which will be copied to the
# *** default location during install, and will be replaced if you
# *** upgrade to a newer version of MySQL. [mysqld] # Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M # Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin # These are commonly set, remove the # and set as required.
# basedir = .....
# datadir = .....
# port = .....
# server_id = ..... slow_query_log = ON
long_query_time = 1
slow_query_log_file = /usr/slow.log
log_queries_not_using_indexes = ON # Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
2、使用命令开启,记录日志,不需要重启数据库
首先使用命令查看相关的全局变量是否开始
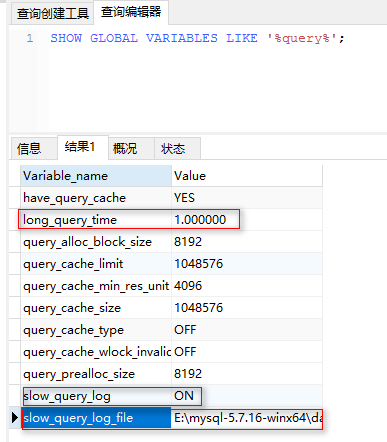
SHOW GLOBAL VARIABLES LIKE '%query%'; -- 使用模糊查询全局变量情况

查看未使用索引的搜索是否记录
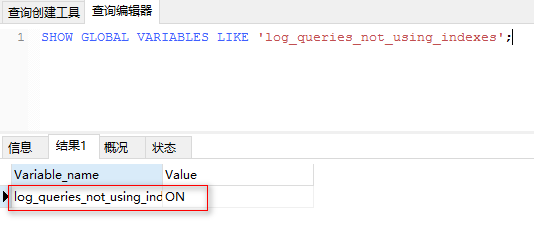
SHOW GLOBAL VARIABLES LIKE 'log_queries_not_using_indexes'; -- 未使用索引的搜索是否记录

使用命令开启慢日志记录相关全局变量,注意使用命令开启的全局变量数据库重启后变量将恢复默认
如果想要数据库重启后慢日志变量也是开启的,建议在my-default.ini文件里配置
SET GLOBAL slow_query_log = on; -- 开启慢日志记录
SET GLOBAL long_query_time = 1; -- 设置sql语句查询耗时超过1秒的记录
SET GLOBAL log_queries_not_using_indexes = on; -- 开启记录没有使用索引的sql查询记录
查看MySQL慢日志文件
win版本没有mysqldumpslow解释器来执行mysqldumpslow.pl文件,索引需要安装ActivePerl_5.16.2.3010812913.msi,软件来执行mysqldumpslow.pl文件
双击下一步,下一步安装好ActivePerl_5.16.2.3010812913.msi,软件
linu版本就不需要了,linu版本自带了mysqldumpslow解释器
安装好ActivePerl_5.16.2.3010812913.msi,软件后,管理员方式运行cmd命令
cd E:\mysql-5.7.-winx64\bin #进入mysql安装目录的bin目录里

注意:以下操作,linu版本不需要加perl,win版本加perl表示用安装的ActivePerl来执行mysqldumpslow.pl文件
查看解析慢日志文件的mysqldumpslow.pl文件说明
perl mysqldumpslow.pl --help #查看解析慢日志文件的mysqldumpslow.pl文件说明
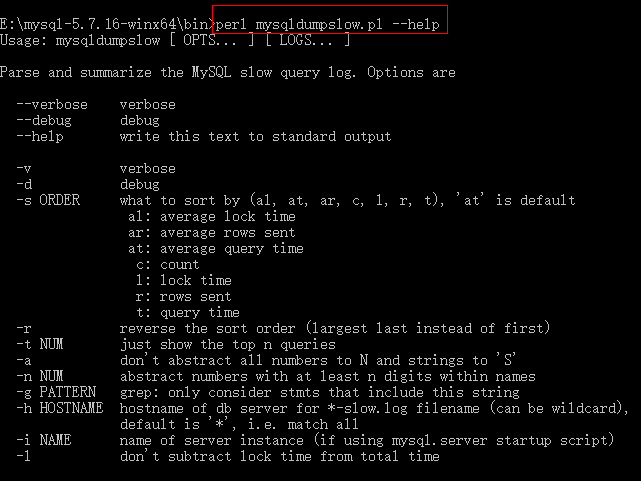
mysqldumpslow.pl文件说明
"""
--verbose 版本
--debug 调试
--help 帮助 -v 版本
-d 调试模式
-s ORDER 排序方式
what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time -- 平均锁时间
ar: average rows sent -- 返回值时间
at: average query time -- sql查询时间
c: count
l: lock time
r: rows sent
t: query time
-r 反转顺序,默认文件倒序拍。reverse the sort order (largest last instead of first)
-t NUM 显示前N条just show the top n queries -- 显示多少条数据
-a 不要将SQL中数字转换成N,字符串转换成S。don't abstract all numbers to N and strings to 'S' -- 默认会转换数字和字符串,-a表示不转换
-n NUM abstract numbers with at least n digits within names
-g PATTERN 正则匹配;grep: only consider stmts that include this string -g表示支持正则匹配,后面就可以跟正则
-h HOSTNAME mysql机器名或者IP;hostname of db server for *-slow.log filename (can be wildcard),
default is '*', i.e. match all
-i NAME name of server instance (if using mysql.server startup script)
-l 总时间中不减去锁定时间;don't subtract lock time from total time
"""
下面我们开始查看日志
CHCP 65001 -- 设置cmd为utf-8变量,因为可能有中文,65001为utf-8编码号
CHCP 65001 -- 设置cmd为utf-8变量,因为可能有中文,65001为utf-8编码号
输入查看日志命令
注意:组合命令时按照上面的说明顺序进行
-- mysqldumpslow.pl -s(排序方式) at(按照sql查询时间) -t 5 -a(转换数字和字符串) 日志路径
mysqldumpslow.pl -s at -t 5 -a E:\mysql-5.7.16-winx64\data\SKY-20160816NYP-slow.log
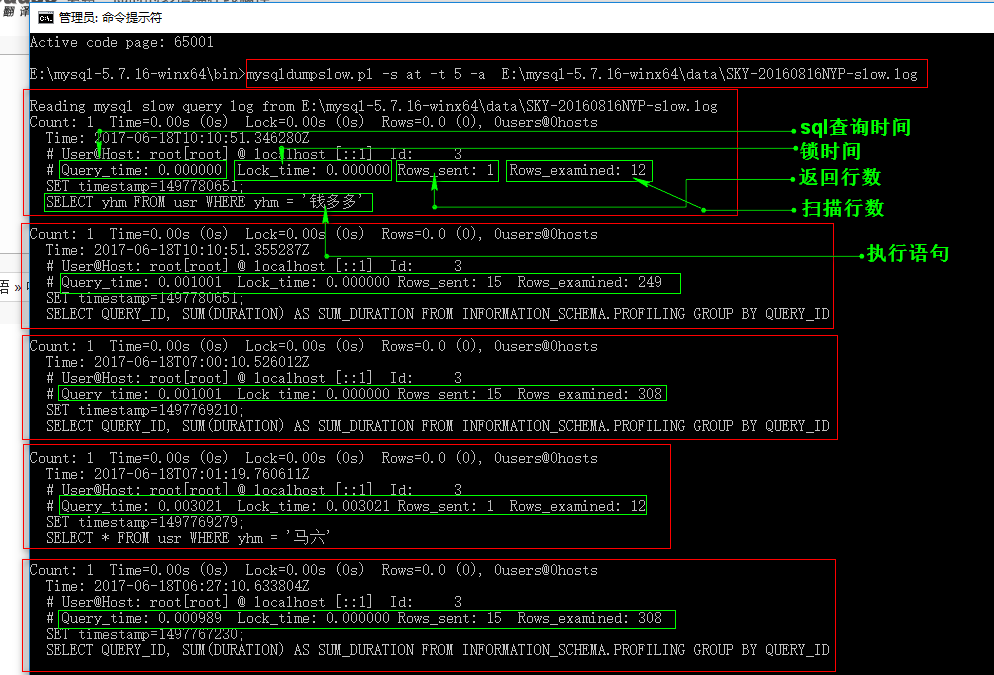
这样就可以根据查询数据,和扫描了多少行来进行数据库表优化
第二百八十八节,MySQL数据库-索引、limit分页、执行计划、慢日志查询的更多相关文章
- 第二百八十二节,MySQL数据库-MySQL视图
MySQL数据库-MySQL视图 1.视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,并可以将其当作表来使用. 2.也 ...
- 第三百八十八节,Django+Xadmin打造上线标准的在线教育平台—网站列表分页
第三百八十八节,Django+Xadmin打造上线标准的在线教育平台—网站列表分页 分页可以用一个第三方分页模块django-pure-pagination 下载地址:https://github.c ...
- 第二百八十三节,MySQL数据库-MySQL存储过程
MySQL数据库-MySQL存储过程 MySQL存储过程,也就是有点像MySQL函数,但是他与MySQL函数是有区别的,后面会讲到函数,所以注意区分 注意:函数与存储过程的区别 存储过程是:CREAT ...
- 第二百八十九节,MySQL数据库-ORM之sqlalchemy模块操作数据库
MySQL数据库-ORM之sqlalchemy模块操作数据库 sqlalchemy第三方模块 sqlalchemysqlalchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API ...
- 第二百八十六节,MySQL数据库-MySQL事务操作(回滚)
MySQL数据库-MySQL事务操作(回滚) 事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,即可回滚到原来的状态,从而保证数据库数据完整性. 举例:有这样一张表 从表里可以看出张 ...
- 第二百八十五节,MySQL数据库-MySQL函数
MySQL数据库-MySQL函数 1.MySQL内置函数 SELECT执行函数,后面跟要执行的函数 CHAR_LENGTH(str)函数:返回字符串的字符长度 -- CHAR_LENGTH(str)函 ...
- 第二百八十节,MySQL数据库-外键链表之一对多,多对多
MySQL数据库-外键链表之一对多,多对多 外键链表之一对多 外键链表:就是a表通过外键连接b表的主键,建立链表关系,需要注意的是a表外键字段类型,必须与要关联的b表的主键字段类型一致,否则无法创建索 ...
- 第二百八十四节,MySQL数据库-MySQL触发器
MySQL数据库-MySQL触发器 对某个表进行[增/删/改]操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行[增/删/改]前后的行为. 1.创建触发器基本语法 ...
- 第二百七十八节,MySQL数据库-表内容操作
MySQL数据库-表内容操作 1.表内容增加 insert into 表 (列名,列名...) values (值,值,值...); 添加表内容添加一条数据 insert into 表 (列名,列名. ...
随机推荐
- tomcat支持https的历程
tomcat真是业界良心啊,文档写的详细无比. 一.https是什么? 简单的说,就是http+SSL/TLS 协议还是http,但是在传输层过程中使用了加密(涉及握手.秘钥分发.加密.解密等过程). ...
- BZOJ 2466 中山市选2009 树 高斯消元+暴力
题目大意:树上拉灯游戏 高斯消元解异或方程组,对于全部的自由元暴力2^n枚举状态,代入计算 这做法真是一点也不优雅... #include <cstdio> #include <cs ...
- .NET设计模式(4):建造者模式(Builder Pattern)(转载)
概述 在 软件系统中,有时候面临着“一个复杂对象”的创建工作,其通常由各个部分的子对象用一定的算法构成:由于需求的变化,这个复杂对象的各个部分经常面临着剧 烈的变化,但是将它们组合在一起的算法确相对稳 ...
- Java:HttpClient篇,Cookie概述,及其在HttpClient4.2中的应用
1. Cookie 概述 Cookie是什么? Cookie 是一小段文本信息,伴随着用户请求和页面在 Web 服务器和浏览器之间传递.Cookie 包含每次用户访问站点时 Web 应用程序都可以读取 ...
- Windows XP忘记密码的几种解决方法
1. 问题 朋友一Windows XP系统的密码忘记了,让给解决一下.网上搜索了几种解决方案,列在下面,记一下. 2. 解决 2.1 使用“Administrator”帐户 前提:当前用户名不是“Ad ...
- silverlight打开和保存文件
因为Silverlight是运行在浏览器中的客户端,所以对于程序的操作权限要求比较严格,以本篇的主题来说,一个表现就是不能够随意的进行文件打开和保存操作,如果在代码中直接使用Stream来操作文件,会 ...
- 【Unity3D游戏开发】NGUI之DrawCall数量 (四)
看了非常多关于NGUI drawCall的文章.见得比較多的一个观点是:一个 Atlas 相应一个Drawcall. 但事实上NGUI内部有自己的一套对DrawCall的处理规则. 相关的规则有: 1 ...
- atitit.ajax上传文件的实现原理 与设计
atitit.ajax上传文件的实现原理 与设计 1. 上传文件的三大难题 1 1.1. 本地预览 1 1.2. 无刷新 1 1.3. 进度显示 1 2. 传统的html4 + ajax 是无法直 ...
- Django内置过滤器详解附代码附效果图--附全部内置过滤器帮助文档
前言 基本环境 Django版本:1.11.8 Python版本:3.6 OS: win10 x64 本文摘要 提供了常用的Django内置过滤器的详细介绍,包括过滤器的功能.语法.代码和效果示例. ...
- Ubuntu下安装JDK1.7
Ubuntu操作系统下如何手动安装JDK1.7呢?本文是我经历的全过程. Ubuntu版本:12.04 LTS JDK版本:1.7.0_04 安装目录:/usr/local/development/j ...