用Python深入理解跳跃表原理及实现
最近看 Redis 的实现原理,其中讲到 Redis 中的有序数据结构是通过跳跃表来进行实现的。第一次听说跳跃表的概念,感到比较新奇,所以查了不少资料。其中,网上有部分文章是按照如下方式描述跳跃表的:

这种描述便于理解,很容易让人理解到跳跃表是建立了类似索引的东西,从而提高效率的。但是,这样描述给人的感觉是,数据有多份存储,每份数据有两个指针,指向下层数据的指针和指向右面数据的指针。然而实际并不是这样的,实际的数据结构如下:

即:并非由多份数据,而是每份数据有多层指针。
那么,什么是跳跃表,跳跃表有什么特点呢?
- Skip lists are data structures that use probabilistic balancing rather than strictly enforced balancing. As a result, the algorithms for insertion and deletion in skip lists are much simpler and significantly faster than equivalent algorithms for balanced trees.
从定义中可以看出,跳跃表是为了解决平衡树插入或者删除操作过于复杂而进行设计的。的确,平衡树在插入或者删除时,需要维持平衡而进行过多的操作,学过数据结构的同学想到平衡树、红黑树等都不寒而栗吧。而跳跃表则没有这种问题,采用了随机的思想简化了维持平衡的过程,而保持查找的时间复杂度依旧是O(log N)。
跳跃表有如下特点:
(1) 每个跳跃表由很多层结构组成;
(2) 每一层都是一个有序链表,且第一个节点是头节点;
(3) 最底层的有序链表包含所有节点;
(4) 每个节点可能有多个指针,这与节点所包含的层数有关;
(5) 跳跃表的查找、插入、删除的时间复杂度均为O(log N)。
从上面的结构也可以看出,跳跃表的核心思想就是,每一个节点既包含指向下一个节点的指针,也可能包含很多个指向后续节点的指针,这样在查找、插入、删除某个节点的过程中,可以避免一些不必要的节点,从而提高效率。
所以,每个节点的数据结构设计如下:
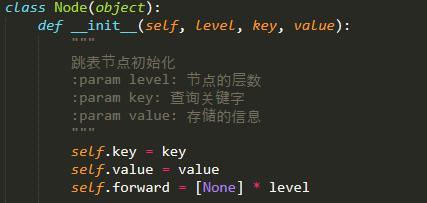
跳跃表的设计如下:

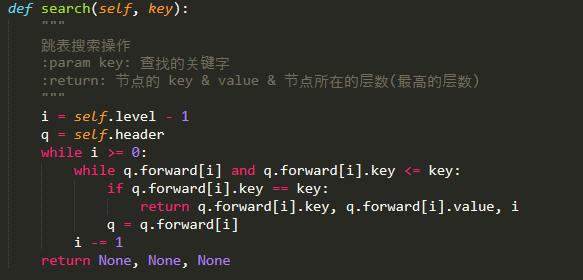
那么,如何进行查找呢?
假设查找5,那么在查找的过程中,需要从最高层开始查找(毕竟,越高层越表示索引嘛,很可能一下子就找到数据了),如果元素小于5,则一直向右查找。若遇到大于5的,则降低一层,在下一层继续查找。查找的流程如下图所示:

查找的代码如下:
插入的过程是怎么样的呢?
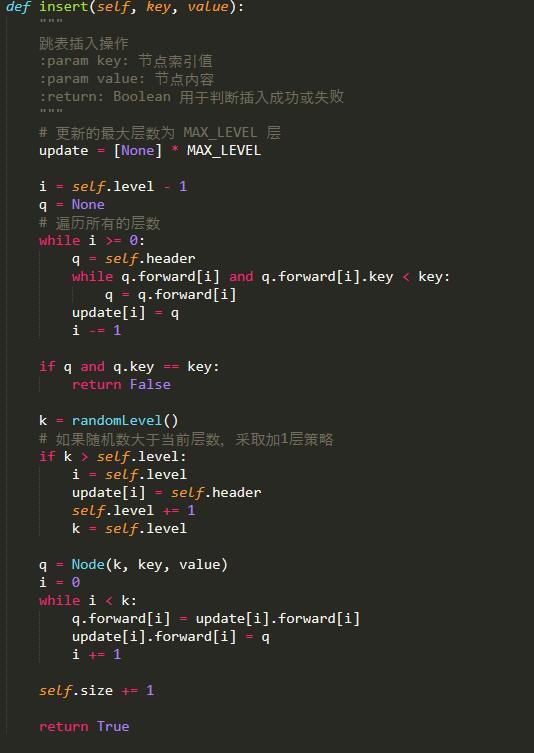
插入的过程包括如下4个步骤:
1、首先,需要找到每一层要插入节点的位置,并保存(用于后续调整指针);
2、确定该节点包含的层数,初始化要插入的节点;
3、相关的指针的调整;
4、若跳跃表层数增加,需要调整Header节点。
如下图,若要插入key 为4.5的节点,先要找到需要插入的位置,如图中黄线所示,然后随机生成一个层数(范围是1层到当前跳跃表层数+1,随机数生成器可以自行设计),初始化该节点,然后进行调整指针。

假设随机生成的层数为3,那么插入后为:

是不是比平衡树简单多了?当然,如果随机生成的层数为 当前跳跃表层数+1,那么跳跃表层数增加一层,header节点需要增加一层。
Python实现如下:
删除操作呢?跟插入操作类似,但是更为简单,只需要如下3个步骤:
1、首先,需要找到每一层要删除节点的位置,并保存(用于后续调整指针);
2、相关的指针的调整;
3、若层数减少,需要调整跳跃表层数和Header节点。
如果删除6这个节点,找到相应的位置,然后调整指针即可:

删除后的结果为:

Python代码实现为:
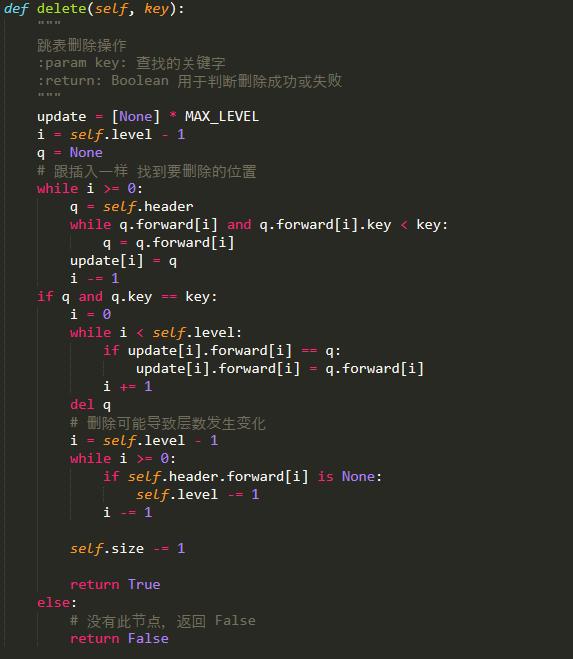
这里需要注意,如果删除元素后导致层数发生变化,那么需要对header节点进行调整的,即降低一层。
跳跃表的原理及实现你是否深入理解了?
用Python深入理解跳跃表原理及实现的更多相关文章
- 跳跃表-原理及Java实现
跳跃表-原理及Java实现 引言: 上周现场面试阿里巴巴研发工程师终面,被问到如何让链表的元素查询接近线性时间.笔者苦思良久,缴械投降.面试官告知回去可以看一下跳跃表,遂出此文. 跳跃表的引入 我们知 ...
- 浅析SkipList跳跃表原理及代码实现
本文将总结一种数据结构:跳跃表.前半部分跳跃表性质和操作的介绍直接摘自<让算法的效率跳起来--浅谈“跳跃表”的相关操作及其应用>上海市华东师范大学第二附属中学 魏冉.之后将附上跳跃表的源代 ...
- 【Redis】跳跃表原理分析与基本代码实现(java)
最近开始看Redis设计原理,碰到一个从未遇见的数据结构:跳跃表(skiplist).于是花时间学习了跳表的原理,并用java对其实现. 主要参考以下两本书: <Redis设计与实现>跳表 ...
- 【转】浅析SkipList跳跃表原理及代码实现
SkipList在Leveldb以及lucence中都广为使用,是比较高效的数据结构.由于它的代码以及原理实现的简单性,更为人们所接受.首先看看SkipList的定义,为什么叫跳跃表? "S ...
- 查找——图文翔解SkipList(跳跃表)
跳跃表 跳跃列表(也称跳表)是一种随机化数据结构,基于并联的链表,其效率可比拟于二叉查找树(对于大多数操作须要O(logn)平均时间). 基本上.跳跃列表是对有序的链表添加上附加的前进链接,添加是以随 ...
- 跳跃表Skip List的原理和实现
>>二分查找和AVL树查找 二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存.这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了.如果 ...
- 跳跃表Skip List的原理
1.二分查找和AVL树查找 二分查找要求元素可以随机访问,所以决定了需要把元素存储在连续内存.这样查找确实很快,但是插入和删除元素的时候,为了保证元素的有序性,就需要大量的移动元素了.如果需要的是一个 ...
- python模块之HTMLParser之穆雪峰的案例(理解其用法原理)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之HTMLParser之穆雪峰的案例(理解其用法原理) #http://www.cnblog ...
- Skip List(跳跃表)原理详解与实现【转】
转自:http://dsqiu.iteye.com/blog/1705530 Skip List(跳跃表)原理详解与实现 本文内容框架: §1 Skip List 介绍 §2 Skip List 定义 ...
随机推荐
- 博客存档TensorFlow入门一 1.4编程练习
import tensorflow as tf import numpy import matplotlib.pyplot as plt #from sklearn.model_selecti ...
- [Luogu1282]多米诺骨牌(DP)
#\(\color{red}{\mathcal{Description}}\) \(Link\) 我们有一堆多米诺骨牌,上下两个部分都有点数,\(But\)我们有一个操作是可以对调上下的点数.若记一块 ...
- HDU 1050(楼道搬桌子问题)(不是贪心解法,思路很新颖)
Moving Tables Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tot ...
- C# 中的#if、#elif、#else、#endif等条件编译符号 (转载)
这些是C#中的条件编译符号.这些指令我在项目中遇到过,查过网络,问过人(当然,既不认识大牛,也不认识小牛,所以没什么收获).今天翻看一本资料,有提到这个方面的东西,所以写下来和能看到这篇文章的人一起学 ...
- iOS:多媒体(18-01-25更)
1.音频 2.视频 1. 2.AVPlayer 1.音频 2.视频 1. 2.AVPlayer 0).写在前面 AVPlayer 主要包含 AVPlayer.AVPlayerItem.AVPlayer ...
- 菜鸟级渣渣 关于MAC系统开发java的吐槽
最开始买电脑的时候不知道为什么脑子一抽买了个苹果.因为不知道和谁聊的.后期服务器大部分都是linux系统,后期也要学linux系统.mac系统类似linux系统.然后就买了个mac,感觉凭借自己的聪明 ...
- urllib库使用方法1 request
urllib是可以模仿浏览器发送请求的库,Python自带 Python3中urllib分为:urllib.request和urllib.parse import urllib.request url ...
- 在vim编辑器中实现python的tab补全
在vim编辑器中实现python的tab补全 在vim编辑器中实现python tab补全插件有Pydiction,Pydiction可以实现下面python代码的自动补全: 1.简单python ...
- ASP.NET <% %>的各种形式用法
1.<% %>用来绑定后台代码 < % ;i<;i++) { Reaponse.Write(i.ToString()); } %> 2.<%# %> 是在绑定 ...
- typedef和define一些问题
1. 四个用途 用途一: 定义一种类型的别名,而不只是简单的宏替换.可以用作同时声明指针型的多个对象.比如: char* pa, pb; // 这多数不符合我们的意图,它只声明了一个指向字符变量的指针 ...