人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型
经过前面稍显罗嗦的准备工作,现在,我们终于可以尝试训练我们自己的卷积神经网络模型了。CNN擅长图像处理,keras库的tensorflow版亦支持此种网络模型,万事俱备,就放开手做吧。前面说过,我们需要通过大量的训练数据训练我们的模型,因此首先要做的就是把训练数据准备好,并将其输入给CNN。前面我们已经准备好了2000张脸部图像,但没有进行标注,并且还需要将数据加载到内存,以方便输入给CNN。因此,第一步工作就是加载并标注数据到内存。
首先我们建立一个空白的python文件,文件名为:load_face_dataset.py,代码如下:
# -*- coding: utf-8 -*- import os
import sys
import numpy as np
import cv2 IMAGE_SIZE = 64 #按照指定图像大小调整尺寸
def resize_image(image, height = IMAGE_SIZE, width = IMAGE_SIZE):
top, bottom, left, right = (0, 0, 0, 0) #获取图像尺寸
h, w, _ = image.shape #对于长宽不相等的图片,找到最长的一边
longest_edge = max(h, w) #计算短边需要增加多上像素宽度使其与长边等长
if h < longest_edge:
dh = longest_edge - h
top = dh // 2
bottom = dh - top
elif w < longest_edge:
dw = longest_edge - w
left = dw // 2
right = dw - left
else:
pass #RGB颜色
BLACK = [0, 0, 0] #给图像增加边界,是图片长、宽等长,cv2.BORDER_CONSTANT指定边界颜色由value指定
constant = cv2.copyMakeBorder(image, top , bottom, left, right, cv2.BORDER_CONSTANT, value = BLACK) #调整图像大小并返回
return cv2.resize(constant, (height, width)) #读取训练数据
images = []
labels = []
def read_path(path_name):
for dir_item in os.listdir(path_name):
#从初始路径开始叠加,合并成可识别的操作路径
full_path = os.path.abspath(os.path.join(path_name, dir_item)) if os.path.isdir(full_path): #如果是文件夹,继续递归调用
read_path(full_path)
else: #文件
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE) #放开这个代码,可以看到resize_image()函数的实际调用效果
#cv2.imwrite('1.jpg', image) images.append(image)
labels.append(path_name) return images,labels #从指定路径读取训练数据
def load_dataset(path_name):
images,labels = read_path(path_name) #将输入的所有图片转成四维数组,尺寸为(图片数量*IMAGE_SIZE*IMAGE_SIZE*3)
#我和闺女两个人共1200张图片,IMAGE_SIZE为64,故对我来说尺寸为1200 * 64 * 64 * 3
#图片为64 * 64像素,一个像素3个颜色值(RGB)
images = np.array(images)
print(images.shape) #标注数据,'me'文件夹下都是我的脸部图像,全部指定为0,另外一个文件夹下是闺女的,全部指定为1
labels = np.array([0 if label.endswith('me') else 1 for label in labels]) return images, labels if __name__ == '__main__':
if len(sys.argv) != 2:
print("Usage:%s path_name\r\n" % (sys.argv[0]))
else:
images, labels = load_dataset(sys.argv[1])
上面给出的代码主函数就是load_dataset(),它将图片数据进行标注并以多维数组的形式加载到内存中。我实际用于训练的脸部数据共1200张,我去掉了一些模糊的或者表情基本一致的头像,留下了清晰、脸部表情有些区别的,我和闺女各留了600张,所以训练数据变成了1200。上述代码注释很清楚,不多讲,唯一一个理解起来稍微有点难度的就是resize_image()函数。这个函数其实就做了一件事情,判断图片是不是四边等长,也就是图片是不是正方形。如果不是,则短的那两边增加两条黑色的边框,使图像变成正方形,这样再调用cv2.resize()函数就可以实现等比例缩放了。因为我们指定缩放的比例就是64 x 64,只有缩放之前图像为正方形才能确保图像不失真。resize_image()函数的执行结果如下所示:

上图为200 x 300的图片,宽度小于高度,因此,需要增加宽度,正常应该是两边各增加宽50像素的黑边:

如我们所愿,成了一个300 x 300的正方形图片,这时我们再缩放到64 x 64就可以了:

上图就是我们将要输入到CNN中的图片,之所以缩放到这么小,主要是为了减少计算量及内存占用,提升训练速度。执行程序之前,请把图片组织一下,结构参见下图:

load_face_dataset.py所在文件夹下建立一个data文件夹,在data下再建立me和other两个文件夹,me放本人的图像,other放其他人的,对我来说就是闺女的。我各放了600张图片。
这些工作做完之后,我们就可以开始构建训练代码了。
同样,在load_face_dataset.py所在文件夹下新建一个python空白文件face_train_use_keras.py,然后我们先把需要的库文件添加到代码中:
#-*- coding: utf-8 -*-
import random import numpy as np
from sklearn.cross_validation import train_test_split
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import SGD
from keras.utils import np_utils
from keras.models import load_model
from keras import backend as K from load_face_dataset import load_dataset, resize_image, IMAGE_SIZE
我们先不管导入的这些库是干啥的,你只要知道接下来的代码要用到这些库就够了,用到了我们再讲。到目前为止,数据加载的工作已经完成,我们只需调用这个接口即可。关于训练集的使用,我们需要拿出一部分用于训练网络,建立识别模型;另一部分用于验证模型。同时我们还有一些其它的比如数据归一化等预处理的工作要做,因此,我们把这些工作封装成一个dataset类来完成:
class Dataset:
def __init__(self, path_name):
#训练集
self.train_images = None
self.train_labels = None #验证集
self.valid_images = None
self.valid_labels = None #测试集
self.test_images = None
self.test_labels = None #数据集加载路径
self.path_name = path_name #当前库采用的维度顺序
self.input_shape = None #加载数据集并按照交叉验证的原则划分数据集并进行相关预处理工作
def load(self, img_rows = IMAGE_SIZE, img_cols = IMAGE_SIZE,
img_channels = 3, nb_classes = 2):
#加载数据集到内存
images, labels = load_dataset(self.path_name) train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size = 0.3, random_state = random.randint(0, 100))
_, test_images, _, test_labels = train_test_split(images, labels, test_size = 0.5, random_state = random.randint(0, 100)) #当前的维度顺序如果为'th',则输入图片数据时的顺序为:channels,rows,cols,否则:rows,cols,channels
#这部分代码就是根据keras库要求的维度顺序重组训练数据集
if K.image_dim_ordering() == 'th':
train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols)
valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols)
test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols)
self.input_shape = (img_channels, img_rows, img_cols)
else:
train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels) #输出训练集、验证集、测试集的数量
print(train_images.shape[0], 'train samples')
print(valid_images.shape[0], 'valid samples')
print(test_images.shape[0], 'test samples') #我们的模型使用categorical_crossentropy作为损失函数,因此需要根据类别数量nb_classes将
#类别标签进行one-hot编码使其向量化,在这里我们的类别只有两种,经过转化后标签数据变为二维
train_labels = np_utils.to_categorical(train_labels, nb_classes)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
test_labels = np_utils.to_categorical(test_labels, nb_classes) #像素数据浮点化以便归一化
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
test_images = test_images.astype('float32') #将其归一化,图像的各像素值归一化到0~1区间
train_images /= 255
valid_images /= 255
test_images /= 255 self.train_images = train_images
self.valid_images = valid_images
self.test_images = test_images
self.train_labels = train_labels
self.valid_labels = valid_labels
self.test_labels = test_labels
我们构建了一个Dataset类,用于数据加载及预处理。其中,__init__()为类的初始化函数,load()则完成实际的数据加载及预处理工作。加载前面已经说过很多了,就不多说了。关于预处理,我们做了几项工作:
1)按照交叉验证的原则将数据集划分成三部分:训练集、验证集、测试集;
2)按照keras库运行的后端系统要求改变图像数据的维度顺序;
3)将数据标签进行one-hot编码,使其向量化
4)归一化图像数据
关于第一项工作,先简单说说什么是交叉验证?交叉验证属于机器学习中常用的精度测试方法,它的目的是提升模型的可靠和稳定性。我们会拿出大部分数据用于模型训练,小部分数据用于对训练后的模型验证,验证结果会与验证集真实值(即标签值)比较并计算出差平方和,此项工作重复进行,直至所有验证结果与真实值相同,交叉验证结束,模型交付使用。在这里我们导入了sklearn库的交叉验证模块,利用函数train_test_split()来划分训练集和验证集,具体语句如下:
train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size = 0.2,
random_state = random.randint(0, 100))
train_test_split()会根据test_size参数按比例划分数据集(不要被test_size的外表所迷惑,它只是用来指定数据集划分比例的,本质上与测试无关,划分完了你爱咋用就咋用),在这里我们划分出了30%的数据用于验证,70%用于训练模型。参数random_state用于指定一个随机数种子,从全部数据中随机选取数据建立训练集和验证集,所以你将会看到每次训练的结果都会稍有不同。当然,为了省事,测试集我也调用了这个函数:
_, test_images, _, test_labels = train_test_split(images, labels, test_size = 0.5,
random_state = random.randint(0, 100))
在这里,测试集我选择的比例为0.5,所以前面的“_, test_images, _, test_labels”语句你调个顺序也成,即“test_images, _, test_labels, _”,但是如果你改成其它数值,就必须严格按照代码给出的顺序才能得到你想要的结果。train_test_split()函数会按照训练集特征数据(这里就是图像数据)、测试集特征数据、训练集标签、测试集标签的顺序返回各数据集。所以,看你的选择了。
关于第二项工作,我们前面不止一次说过keras建立在tensorflow或theano基础上,换句话说,keras的后端系统可以是tensorflow也可以是theano。后端系统决定了图像数据输入CNN网络时的维度顺序,tensorflow的维度顺序为行数(rows)、列数(cols)、通道数(颜色通道,channels);theano则是通道数、行数、列数。所以,我们通过调用image_dim_ordering()函数来确定后端系统的类型(‘th’代表theano,'tf'代表tensorflow),然后我们再通过numpy提供的reshape()函数重新调整数组维度。
关于第三项工作,对标签集进行one-hot编码的原因是我们的训练模型采用categorical_crossentropy作为损失函数(多分类问题的常用函数,后面会详解),这个函数要求标签集必须采用one-hot编码形式。所以,我们对训练集、验证集和测试集标签均做了编码转换。那么什么是one-hot编码呢?one-hot有的翻译成独热,有的翻译成一位有效,个人感觉一位有效更直白一些。因为one-hot编码采用状态寄存器的组织方式对状态进行编码,每个状态值对应一个寄存器位,且任意时刻,只有一位有效。对于我们的程序来说,我们类别状态只有两种(nb_classes = 2):0和1,0代表我,1代表闺女。one-hot编码会提供两个寄存器位保存这两个状态,如果标签值为0,则编码后值为[1 0],代表第一位有效;如果为1,则编码后值为[0 1],代表第2为有效。换句话说,one-hot编码将数值变成了位置信息,使其向量化,这样更方便CNN操作。
关于第四项工作,数据集先浮点后归一化的目的是提升网络收敛速度,减少训练时间,同时适应值域在(0,1)之间的激活函数,增大区分度。其实归一化有一个特别重要的原因是确保特征值权重一致。举个例子,我们使用mse这样的均方误差函数时,大的特征数值比如(5000-1000)2与小的特征值(3-1)2相加再求平均得到的误差值,显然大值对误差值的影响最大,但大部分情况下,特征值的权重应该是一样的,只是因为单位不同才导致数值相差甚大。因此,我们提前对特征数据做归一化处理,以解决此类问题。关于归一化的详细介绍有兴趣的请参考如下链接:
数据准备工作到此完成,接下来就要进入整个系列最关键的一个节点——建立我们自己的卷积神经网络模型,激动吧;)?与数据集加载及预处理模块一样,我们依然将模型构建成一个类来使用,新建的这个模型类添加在Dataset类的下面:
#CNN网络模型类
class Model:
def __init__(self):
self.model = None #建立模型
def build_model(self, dataset, nb_classes = 2):
#构建一个空的网络模型,它是一个线性堆叠模型,各神经网络层会被顺序添加,专业名称为序贯模型或线性堆叠模型
self.model = Sequential() #以下代码将顺序添加CNN网络需要的各层,一个add就是一个网络层
self.model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape = dataset.input_shape)) #1 2维卷积层
self.model.add(Activation('relu')) #2 激活函数层 self.model.add(Convolution2D(32, 3, 3)) #3 2维卷积层
self.model.add(Activation('relu')) #4 激活函数层 self.model.add(MaxPooling2D(pool_size=(2, 2))) #5 池化层
self.model.add(Dropout(0.25)) #6 Dropout层 self.model.add(Convolution2D(64, 3, 3, border_mode='same')) #7 2维卷积层
self.model.add(Activation('relu')) #8 激活函数层 self.model.add(Convolution2D(64, 3, 3)) #9 2维卷积层
self.model.add(Activation('relu')) #10 激活函数层 self.model.add(MaxPooling2D(pool_size=(2, 2))) #11 池化层
self.model.add(Dropout(0.25)) #12 Dropout层 self.model.add(Flatten()) #13 Flatten层
self.model.add(Dense(512)) #14 Dense层,又被称作全连接层
self.model.add(Activation('relu')) #15 激活函数层
self.model.add(Dropout(0.5)) #16 Dropout层
self.model.add(Dense(nb_classes)) #17 Dense层
self.model.add(Activation('softmax')) #18 分类层,输出最终结果 #输出模型概况
self.model.summary()
先不解释代码,咱先看看上述代码的运行情况,接着再添加几行测试代码:
if __name__ == '__main__':
dataset = Dataset('./data/')
dataset.load() model = Model()
model.build_model(dataset)
然后在控制台输入:
python3 face_train_use_keras.py
如果你没敲错代码,一切顺利的话,你应该看到类似下面这样的输出内容:
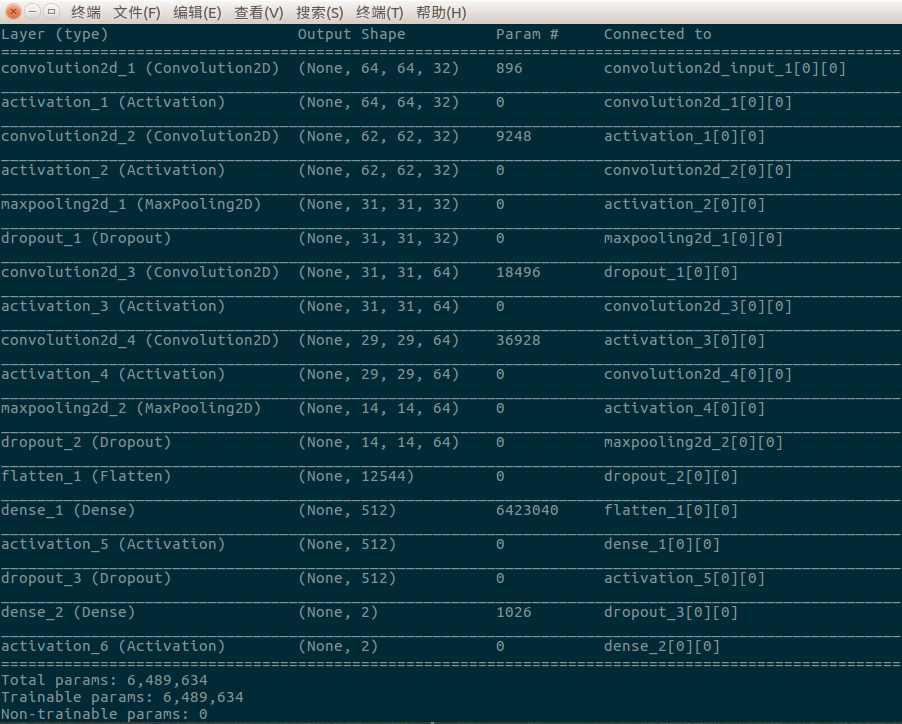
我们通过调用self.model.summary()函数将网络模型基本结构信息展示在我们面前,包括层类型、维度、参数个数、层连接等信息,一目了然,简洁、清晰。通过上图我们可以看出,这个网络模型共18层,包括4个卷积层、5个激活函数层、2个池化层(pooling layer)、3个Dropout层、2个全连接层、1个Flatten层、1个分类层,训练参数为6,489,634个,还是很可观的。
你看,这个实际运作的网络比我们上次给出的那个3层卷积的网络复杂多了,多了池化、Dropout、Dense、Flatten以及最终的分类层,这些都是些什么鬼东西,需要我们逐个理一理:
卷积层(convolution layer):这一层前面讲了太多,这里重点讲讲Convolution2D()函数。根据keras官方文档描述,2D代表这是一个2维卷积,其功能为对2维输入进行滑窗卷积计算。我们的脸部图像尺寸为64*64,拥有长、宽两维,所以在这里我们使用2维卷积函数计算卷积。所谓的滑窗计算,其实就是利用卷积核逐个像素、顺序进行计算,如下图:

上图选择了最简单的均值卷积核,3x3大小,我们用这个卷积核作为掩模对前面4x4大小的图像逐个像素作卷积运算。首先我们将卷积核中心对准图像第一个像素,在这里就是像素值为237的那个像素。卷积核覆盖的区域(掩模之称即由此来),其下所有像素取均值然后相加:
C(1) = 0 * 0.5 + 0 * 0.5 + 0 * 0.5 + 0 * 0.5 + 237 * 0.5 + 203 * 0.5 + 0 * 0.5 + 123 * 0.5 + 112 * 0.5
结果直接替换卷积核中心覆盖的像素值,接着是第二个像素、然后第三个,从左至右,由上到下……以此类推,卷积核逐个覆盖所有像素。整个操作过程就像一个滑动的窗口逐个滑过所有像素,最终生成一副尺寸相同但已经过卷积处理的图像。上图我们采用的是均值卷积核,实际效果就是将图像变模糊了。显然,卷积核覆盖图像边界像素时,会有部分区域越界,越界的部分我们以0填充,如上图。对于此种情况,还有一种处理方法,就是丢掉边界像素,从覆盖区域不越界的像素开始计算。像上图,如果采用丢掉边界像素的方法,3x3的卷积核就应该从第2行第2列的像素(值为112)开始,到第3行第3列结束,最终我们会得到一个2x2的图像。这种处理方式会丢掉图像的边界特征;而第一种方式则保留了图像的边界特征。在我们建立的模型中,卷积层采用哪种方式处理图像边界,卷积核尺寸有多大等参数都可以通过Convolution2D()函数来指定:
self.model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape = dataset.input_shape))
第一个卷积层包含32个卷积核,每个卷积核大小为3x3,border_mode值为“same”意味着我们采用保留边界特征的方式滑窗,而值“valid”则指定丢掉边界像素。根据keras开发文档的说明,当我们将卷积层作为网络的第一层时,我们还应指定input_shape参数,显式地告知输入数据的形状,对我们的程序来说,input_shape的值为(64,64,3),来自Dataset类,代表64x64的彩色RGB图像。
激活函数层:它的作用前面已经说了,这里讲一下代码中采用的relu(Rectified Linear Units,修正线性单元)函数,它的数学形式如下:
ƒ(x) = max(0, x)
这个函数非常简单,其输出一目了然,小于0的输入,输出全部为0,大于0的则输入与输出相等。该函数的优点是收敛速度快,除了它,keras库还支持其它几种激活函数,如下:
- softplus
- softsign
- tanh
- sigmoid
- hard_sigmoid
- linear
它们的函数式、优缺点度娘会告诉你,不多说。对于不同的需求,我们可以选择不同的激活函数,这也是模型训练可调整的一部分,运用之妙,存乎一心,请自忖之。另外再交代一句,其实激活函数层按照我们前文所讲,其属于人工神经元的一部分,所以我们亦可以在构造层对象时通过传递activation参数设置,如下:
self.model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape = dataset.input_shape))
self.model.add(Activation('relu')) #设置为单独的激活层 #通过传递activation参数设置,与上两行代码的作用相同
self.model.add(Convolution2D(32, 3, 3, border_mode='same', input_shape = dataset.input_shape, activation='relu'))
池化层(pooling layer):池化层存在的目的是缩小输入的特征图,简化网络计算复杂度;同时进行特征压缩,突出主要特征。我们通过调用MaxPooling2D()函数建立了池化层,这个函数采用了最大值池化法,这个方法选取覆盖区域的最大值作为区域主要特征组成新的缩小后的特征图:
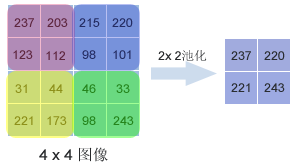
显然,池化层与卷积层覆盖区域的方法不同,前者按照池化尺寸逐块覆盖特征图,卷积层则是逐个像素滑动覆盖。对于我们输入的64x64的脸部特征图来说,经过2x2池化后,图像变为32x32大小。
Dropout层:随机断开一定百分比的输入神经元链接,以防止过拟合。那么什么是过拟合呢?一句话解释就是训练数据预测准确率很高,测试数据预测准确率很低,用图形表示就是拟合曲线较尖,不平滑。导致这种现象的原因是模型的参数很多,但训练样本太少,导致模型拟合过度。为了解决这个问题,Dropout层将有意识的随机减少模型参数,让模型变得简单,而越简单的模型越不容易产生过拟合。代码中Dropout()函数只有一个输入参数——指定抛弃比率,范围为0~1之间的浮点数,其实就是百分比。这个参数亦是一个可调参数,我们可以根据训练结果调整它以达到更好的模型成熟度。
Flatten层:截止到Flatten层之前,在网络中流动的数据还是多维的(对于我们的程序就是2维的),经过多次的卷积、池化、Dropout之后,到了这里就可以进入全连接层做最后的处理了。全连接层要求输入的数据必须是一维的,因此,我们必须把输入数据“压扁”成一维后才能进入全连接层,Flatten层的作用即在于此。该层的作用如此纯粹,因此反映到代码上我们看到它不需要任何输入参数。
全连接层(dense layer):全连接层的作用就是用于分类或回归,对于我们来说就是分类。keras将全连接层定义为Dense层,其含义就是这里的神经元连接非常“稠密”。我们通过Dense()函数定义全连接层。这个函数的一个必填参数就是神经元个数,其实就是指定该层有多少个输出。在我们的代码中,第一个全连接层(#14 Dense层)指定了512个神经元,也就是保留了512个特征输出到下一层。这个参数可以根据实际训练情况进行调整,依然是没有可参考的调整标准,自调之。
分类层:全连接层最终的目的就是完成我们的分类要求:0或者1,模型构建代码的最后两行完成此项工作:
self.model.add(Dense(nb_classes)) #17 Dense层
self.model.add(Activation('softmax')) #18 分类层,输出最终结果
第17层我们按照实际的分类要求指定神经元个数,对我们来说就是2,18层我们通过softmax函数完成最终分类。关于softmax函数,其函数式如下:
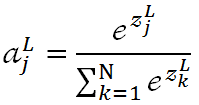
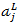 代表第L层第j个神经元的输出,
代表第L层第j个神经元的输出,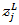 代表第L层第j个神经元的输入,我们用单个神经元的输入结合自然常数e做指数运算,运算结果除以所有L层神经元输入的指数运算之和,就得到了一个介于0~1之间的浮点值。显然,从上述公式很容易看出,所有神经元输出之和肯定为1:
代表第L层第j个神经元的输入,我们用单个神经元的输入结合自然常数e做指数运算,运算结果除以所有L层神经元输入的指数运算之和,就得到了一个介于0~1之间的浮点值。显然,从上述公式很容易看出,所有神经元输出之和肯定为1:
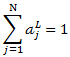
这个值其实就是第j个神经元在所有神经元输出中所占的百分比。从分类的角度来说,该神经元的输出值越大,其对应的类别为真实类别的可能性就越大。因此,经过softmax函数,上层的N个输入被映射成N个概率分布,概率之和为1,概率值最大者即为模型预测的类别。
好了,模型构建完毕,接下来构建训练代码,在build_model()函数下面继续添加如下代码:
#训练模型
def train(self, dataset, batch_size = 20, nb_epoch = 10, data_augmentation = True):
sgd = SGD(lr = 0.01, decay = 1e-6,
momentum = 0.9, nesterov = True) #采用SGD+momentum的优化器进行训练,首先生成一个优化器对象
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy']) #完成实际的模型配置工作 #不使用数据提升,所谓的提升就是从我们提供的训练数据中利用旋转、翻转、加噪声等方法创造新的
#训练数据,有意识的提升训练数据规模,增加模型训练量
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size = batch_size,
nb_epoch = nb_epoch,
validation_data = (dataset.valid_images, dataset.valid_labels),
shuffle = True)
#使用实时数据提升
else:
#定义数据生成器用于数据提升,其返回一个生成器对象datagen,datagen每被调用一
#次其生成一组数据(顺序生成),节省内存,其实就是python的数据生成器
datagen = ImageDataGenerator(
featurewise_center = False, #是否使输入数据去中心化(均值为0),
samplewise_center = False, #是否使输入数据的每个样本均值为0
featurewise_std_normalization = False, #是否数据标准化(输入数据除以数据集的标准差)
samplewise_std_normalization = False, #是否将每个样本数据除以自身的标准差
zca_whitening = False, #是否对输入数据施以ZCA白化
rotation_range = 20, #数据提升时图片随机转动的角度(范围为0~180)
width_shift_range = 0.2, #数据提升时图片水平偏移的幅度(单位为图片宽度的占比,0~1之间的浮点数)
height_shift_range = 0.2, #同上,只不过这里是垂直
horizontal_flip = True, #是否进行随机水平翻转
vertical_flip = False) #是否进行随机垂直翻转 #计算整个训练样本集的数量以用于特征值归一化、ZCA白化等处理
datagen.fit(dataset.train_images) #利用生成器开始训练模型
self.model.fit_generator(datagen.flow(dataset.train_images, dataset.train_labels,
batch_size = batch_size),
samples_per_epoch = dataset.train_images.shape[0],
nb_epoch = nb_epoch,
validation_data = (dataset.valid_images, dataset.valid_labels))
按照我们的习惯,依然先不解释代码,先看执行结果,程序执行前添加如下一行代码:
#先前添加的测试build_model()函数的代码
model.build_model(dataset) #测试训练函数的代码
model.train(dataset)
保存,控制台输入:
python3 face_train_use_keras.py
训练结果如下:
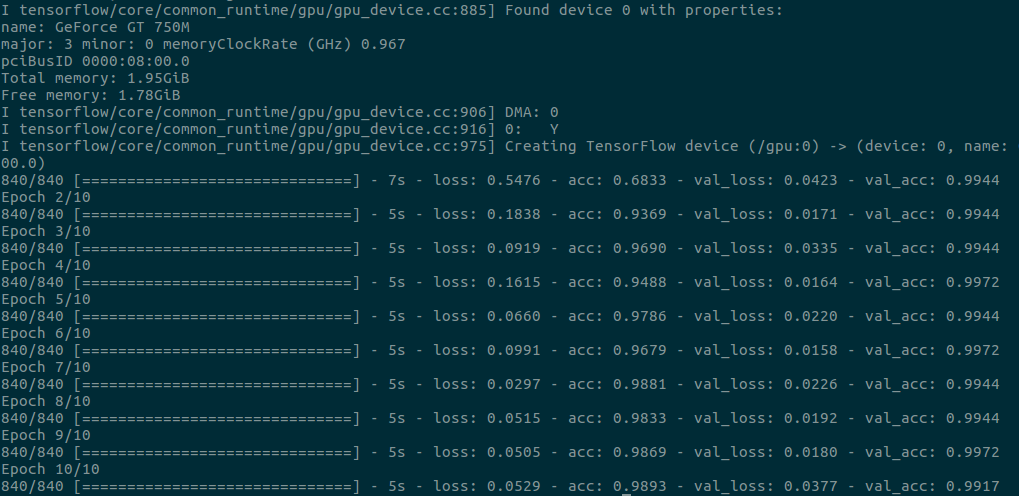
我们共进行了10轮次训练(nb_epoch = 10),每轮42次迭代(840 / 20,训练集1200 x (1-0.3) = 840),每次迭代训练使用20个样本(batch_size = 20),得到的训练结果还不错(以第10轮次训练结果为例):
训练误差(loss):0.0529
训练准确率(acc):0.9893
验证误差(val_loass):0.0377
验证准确率(val_acc):0.9917
验证集准确率高达99%,至少从验证结果上看模型已达实用化要求,下一步可以用测试数据集对其进行测试了。添加测试代码之前,我们需要对训练代码中几个关键函数交代一下。首先是优化器函数,优化器用于训练模型,它的作用就是调整训练参数(权重和偏置值)使其最优,确保e值最小(参见系列4——CNN入门)。keras提供了很多优化器,我们在这里采用的SGD就是其中一种,它就是机器学习领域最著名的随机梯度下降法。函数第一个参数lr用于指定学习效率(lr,Learning Rate,参见系列4),其值为大于0的浮点数。decay指定每次更新后学习效率的衰减值,这个值一定很小(1e-6,0.000 001),否则速率会衰减很快。momentum指定动量值。SGD方法有一个明显的缺点就是,它的下降方向完全依赖当前的训练样本(batch),因此其优化十分不稳定。为了解决这个问题,大牛们引进了动量(momentum),用它来模拟物体运动时的惯性,让优化器在一定程度上保留之前的优化方向,同时利用当前样本微调最终的优化方向,这样即能增加稳定性,提高学习速度,又在一定程度上避免了陷入局部最优陷阱。参数momentum即用于指定在多大程度上保留原有方向,其值为0~1之间的浮点数。一般来说,选择一个在0.5~0.9之间的数即可。代码中SGD函数的最后一个参数nesterov则用于指定是否采用nesterov动量方法,nesterov momentum是对传统动量法的一个改进方法,其效率更高,关于它的详细介绍可参考如下链接:
http://www.360doc.com/content/16/1010/08/36492363_597225745.shtml
对于compile()函数,其作用就是编译模型以完成实际的配置工作,为接下来的模型训练做好准备。换句话说,compile之后模型就可以开始训练了。这个函数有一个很重要的参数:loss,它用于指定一个损失函数。所谓损失函数,通俗地说,它是统计学中衡量损失和错误程度的函数,显然,其值越小,模型就越好。如果你仔细阅读了系列4——CNN入门,那么,你肯定能猜到这个函数其实就是我们的优化对象。代码中loss的值为“categorical_crossentropy”,常用于多分类问题,其与激活函数softmax配对使用(我们的类别只有两种,也可采用‘binary_crossentropy’二值分类函数,该函数与sigmoid配对使用,注意如果采用它就不需要one-hot编码)。参数metrics用于指定模型评价指标,参数值”accuracy“表示用准确率来评价(keras官方文档目前没有查到第2种评价指标,有知道的请告知)。
接着就是数据提升,我们可以选择不提升,也就是采用原始训练集和验证集,这时我们直接调用model.fit()函数即可开始模型训练。该函数shuffle参数用于指定是否随机打乱数据集。一般来说选择数据提升要比不提升好,这样可以让我们利用有限数量的图片获得无限数量的训练图片。因为我们一旦选择数据提升,ImageDataGenerator()函数返回的生成器会在模型训练时无限生成训练数据,直至所有训练轮次(epoch)结束(对我们的代码来说就是840 x 10,生成了8400张图片)。model.fit_generator()函数使用生成器开始模型训练。
在这里需要重点交代一下batch_size和nb_epoch两个参数。nb_epoch指定模型需要训练多少轮次,使用训练集全部样本训练一次为一个训练轮次。根据模型成熟度,我们可以适当调整该值以增加或减少训练次数。batch_size则是一个影响模型训练结果的重要参数。我们知道,一个训练轮次要经过多次迭代训练才能让模型逐渐趋向本轮最优,这是因为理论上每次迭代训练结束后,模型都应该朝着梯度下降的方向前进一步,直至全部样本训练完毕,模型梯度到达本轮最小点。之所以说理论上,是因为决定梯度方向的是训练样本,每次迭代训练选取的样本——其决定的下降方向能否很好的代表样本全体,直接决定了模型能否到达正确的极值点。对于小的训练集,我们完全可以采用全数据集的方式进行训练,因为,全数据集确定的方向肯定能代表正确方向。但这样做对大的训练集就很不现实,因为内存有限,无法一次载入全部数据。于是,批梯度下降法(Mini-batches Learning)应运而生。我们一次选取适当数量的训练样本(视内存大小,可多可少),逐批次迭代,直至本轮全部样本训练完毕。参数batch_size的作用即在于此,其指定每次迭代训练样本的数量。该值的选取非常讲究,不能盲目的增大或减小,因为batch_size太大或太小都会让模型训练效率变慢。显然,batch_size肯定存在一个局部最优值,这需要我们慢慢调试,调试时可从一个小值开始,慢慢加大,直至到达一个合理值(建议编码实现该参数调优)。
现在模型训练的工作已经完成,接下来我们就要考虑模型使用的问题了。要想使用模型,我们必须能够把模型保存下来,因此,我们继续为Model类添加两个函数:
MODEL_PATH = './me.face.model.h5'
def save_model(self, file_path = MODEL_PATH):
self.model.save(file_path) def load_model(self, file_path = MODEL_PATH):
self.model = load_model(file_path)
一个函数用于保存模型,一个函数用于加载模型。keras库利用了压缩效率更高的HDF5保存模型,所以我们用“.h5”作为文件后缀。上述代码添加完毕后,我们接着在文件尾部添加测试代码,把模型训练好并把模型保存下来:
if __name__ == '__main__':
dataset = Dataset('./data/')
dataset.load() model = Model()
model.build_model(dataset)
model.train(dataset)
model.save_model(file_path = './model/me.face.model.h5')
执行上述代码,顺利的话,我们应当看到模型保存文件出现在model文件夹下了:

好了,接下来我们就要用前面Dataset类提供的测试集测试模型了。首先,我们为Model类添加一个模型评估函数:
def evaluate(self, dataset):
score = self.model.evaluate(dataset.test_images, dataset.test_labels, verbose = 1)
print("%s: %.2f%%" % (self.model.metrics_names[1], score[1] * 100))
然后,继续添加测试代码:
if __name__ == '__main__':
dataset = Dataset('./data/')
dataset.load() '''
#训练模型,这段代码不用,注释掉
model = Model()
model.build_model(dataset)
model.train(dataset)
model.save_model(file_path = './model/me.face.model.h5')
''' #评估模型
model = Model()
model.load_model(file_path = './model/me.face.model.h5')
model.evaluate(dataset)
执行结果如下:

准确率99.5%,相当高的评估结果了。
至此,我们完成了模型建立工作,下一篇博文讨论如何用它识别出“我”了。
人脸检测及识别python实现系列(5)——利用keras库训练人脸识别模型的更多相关文章
- 人脸检测及识别python实现系列(2)——识别出人脸
人脸检测及识别python实现系列(2)——识别出人脸 http://www.cnblogs.com/neo-T/p/6430583.html
- 人脸检测及识别python实现系列(6)——终篇:从实时视频流识别出“我”
人脸检测及识别python实现系列(6)——终篇:从实时视频流识别出“我” 终于到了最后一步,激动时刻就要来临了,先平复一下心情,把剩下的代码加上,首先是为Model类增加一个预测函数: #识别人脸 ...
- 人脸检测及识别python实现系列(4)——卷积神经网络(CNN)入门
人脸检测及识别python实现系列(4)——卷积神经网络(CNN)入门 上篇博文我们准备好了2000张训练数据,接下来的几节我们将详细讲述如何利用这些数据训练我们的识别模型.前面说过,原博文给出的训练 ...
- 人脸检测及识别python实现系列(3)——为模型训练准备人脸数据
人脸检测及识别python实现系列(3)——为模型训练准备人脸数据 机器学习最本质的地方就是基于海量数据统计的学习,说白了,机器学习其实就是在模拟人类儿童的学习行为.举一个简单的例子,成年人并没有主动 ...
- 人脸检测及识别python实现系列(1)——配置、获取实时视频流
人脸检测及识别python实现系列(1)——配置.获取实时视频流 1. 前言 今天用多半天的时间把QQ空间里的几篇年前的旧文搬到了这里,算是完成了博客搬家.QQ空间里还剩下一些记录自己数学学习路线的学 ...
- OpenCV实践之路——人脸检测(C++/Python) 【转】
转自:http://blog.csdn.net/xingchenbingbuyu/article/details/51105159 版权声明:本文为博主原创文章,转载请联系作者取得授权. 本文由@星沉 ...
- 人脸检测数据源制作与基于caffe构架的ALEXNET神经网络训练
本篇文章主要记录的是人脸检测数据源制作与ALEXNET网络训练实现检测到人脸(基于caffe). 1.数据获取 数据获取: ① benchmark是一个行业的基准(数据库.论文.源码.结果),例如WI ...
- opencv利用Cascade Classifier训练人脸检测器
opencv默认提供了haar特征和lbp特征训练的人脸分类器,但是效果不太好,所以我们可以用opencv提供的跑opencv_traincascade函数来训练一个LBP特征的分类器.(由于open ...
- Python机器学习笔记:利用Keras进行分类预测
Keras是一个用于深度学习的Python库,它包含高效的数值库Theano和TensorFlow. 本文的目的是学习如何从csv中加载数据并使其可供Keras使用,如何用神经网络建立多类分类的数据进 ...
随机推荐
- rabbitmq关于guest用户登录失败解决方法
刚安装完rabbitmq,登录的时候出现了: login failed问题: 查看rabbitmq的文档,发现在3.3.1以后的版中,处于安全的考虑,guest这个默认的用户只能通过localhos ...
- vue每次请求加头部(shiro+vue)
前后台分离,全局请求加头部 设置全局请求为ajax请求 _axios.interceptors.request.use( function(config) { var accessToken = lo ...
- Dubbo实践(一)入门示例
dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案.简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需要用的,只有在分布式的时候 ...
- [LuoguP1360][USACP07MAR]黄金阵容均衡
[LuoguP1360][USACP07MAR]黄金阵容均衡(Link) 每天会增加一个数\(A\),将\(A\)二进制分解为\(a[i]\),对于每一个\(i\)都增加\(a[i]\),如果一段时间 ...
- 字符型设备驱动程序-first-printf以及点亮LED灯(一)
学习使用 Linux 的 字符型设备驱动 来 进行 . 学习地址:http://edu.51cto.com/lesson/id-25710.html 第一步: 首先写 三个函数 ,2017年5月17 ...
- spring boot++jpa+ mysql +maven
项目结构图: 一. 添加mysql 配置 1 在pom.xml中添加 maven依赖 <!--mysql--> <dependency> <groupId>mysq ...
- sql-case when 条件1 then 取值1 when 条件2 then 取值2 else 取值3 end
遇到 XXX情况 就 XXX 遇不到就 XXX 结束case when …… then …… else …… end 例如一个3条件取值的字段: case when 条件1 then 取值1 when ...
- SQL分页过多时, 如何优化
问题: 我们经常会使用到分页操作,这里有个问题,在偏移量非常大的时候,它会导致MySQL扫描大量不需要的行然后再抛弃掉.如: , ; 上述这条SQL语句需要查询10020条记录然后只返回最后20条.前 ...
- CentOS6安装各种大数据软件 第七章:Flume安装与配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- MySQL学习之路(二)——数据类型和操作数据表
数据类型和操作数据表 2.1 MySQL类型之整型 2.2 MySQL数据类型之浮点型 2.3 日期时间型 DATE 1支持时间:1000年1月1日~9999年12月31日 DATETIME 3 支持 ...