ng-深度学习-课程笔记-4: 浅层神经网络(Week3)
1 神经网络概览( Neural Networks Overview )
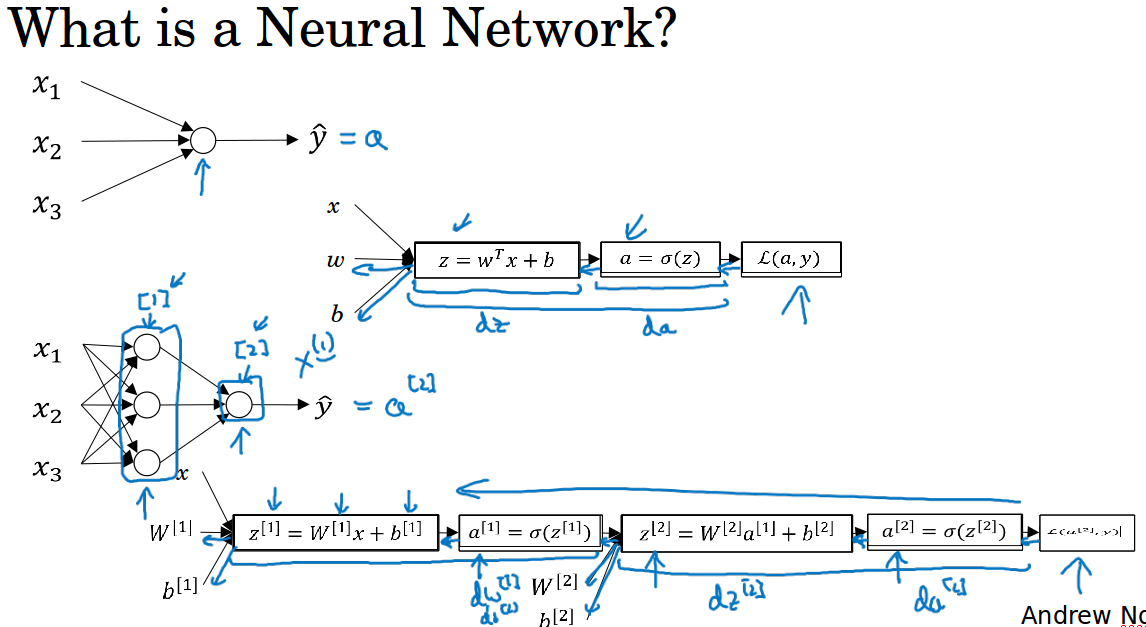
先来快速过一遍如何实现神经网络。
首先需要输入特征x,参数w和b,计算出z,然后用激活函数计算出a,在神经网络中我们要做多次这样的计算,反复计算z和a,然后用损失函数计算最后的a和y的差异。
可以把很多sigmoid单元堆叠起来构成一个神经网络。我们用上标方括号表示第几层,用上标圆括号表示第几个样本。
训练的时候通过反向传播来计算导数,先计算da,再计算dz,再到dw,db。
2 神经网络表示( Neural Network Representation )
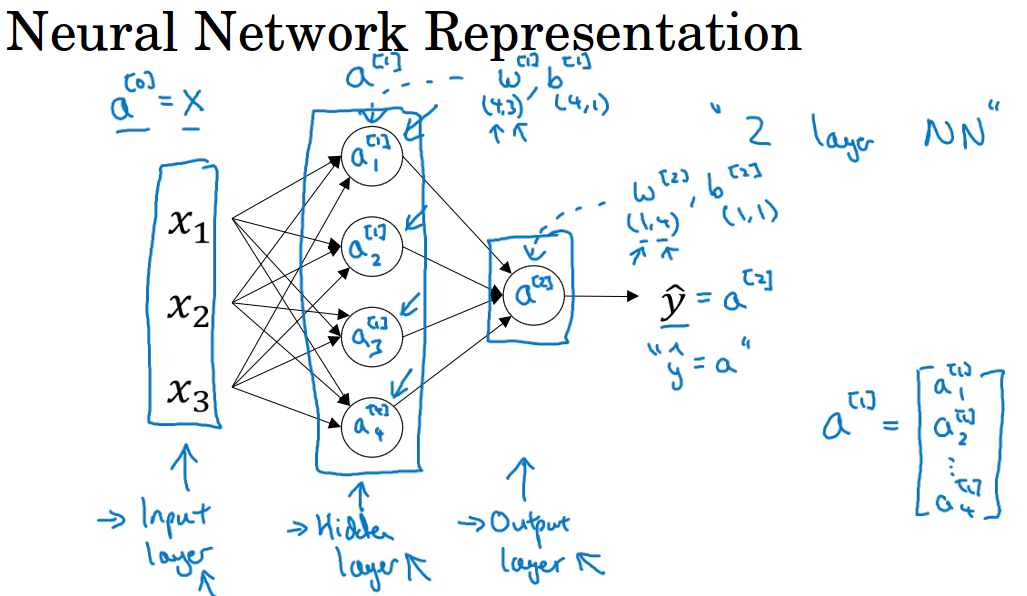
先集中看看只有一层隐藏层的神经网络。x1, x2, x3是神经网络的输入层,中间一层叫隐藏层,最后一个节点的层叫输出层。
为什么叫隐含层呢?它表示的是,在训练集中,这些中间节点的真正数值,我们是不知道的。我们能看到输入和输出,但是隐藏层的数值我们无法看到。
可以用$a^{[0]}$来表示输入x, $a^{[0]}$表示的是第0层输入层的输出。
相应的,隐藏层的输出就是$a^{[1]}$,下标则表示该层的第几个单元,图中有4个节点则代表有4个隐藏层输出。
输出层的输出就是$a^{[2]}$,表示最后的预测输出$\;\hat{y}\;$。这和之前提到的逻辑回归类似,只是这里明确地指出这些值来自哪一层。
在我们的约定中,输入层称为第0层,隐藏层称为第1层,这里的输出层称为第2层,这个网络是两层的神经网络,我们不把输入层看作一个标准的层。
隐藏层中的参数为$w^{[1]}$,$b^{[1]}$。w是一个4*3的矩阵,b是一个4*1的矩阵。4代表隐藏层的单元数量,3代表输入层的特征数量。
类似的,输出层的参数为$w^{[2]}$,$b^{[2]}$。它们的shape分别为1*4和1*1。
3 计算神经网络的输出( Computing a Neural Network's Output )
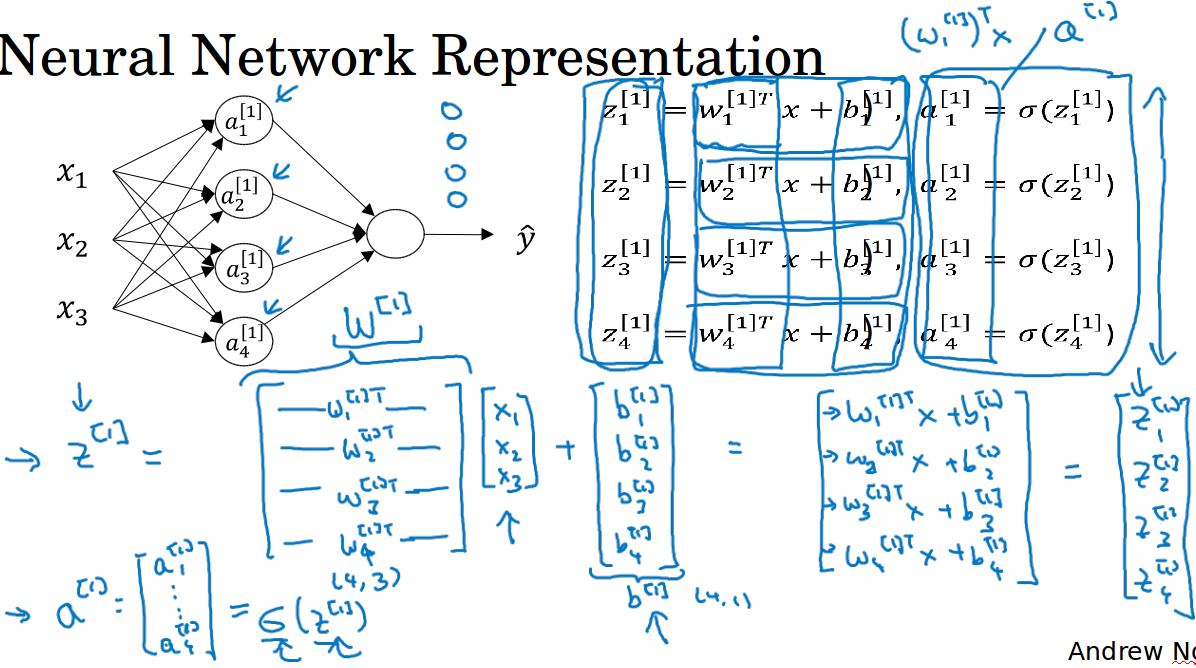
对于每一个神经单元,就是做一个加权和然后使用激活函数,即从x到z,从z得到a。神经网络不过是重复计算这个步骤很多次。
对于隐藏层四个节点的计算如图所示,后面的层也是类似地依次计算,最终得到输出。
4 多个例子中的向量化( Vectorizing across multiple examples )
多样本的输出计算也就是多次进行单样本的输出计算,用向量化的形式可以很好的理解这个过程。
比如,本来x的shape是3*1,w是4*3,得到的z就是4*1,其中4代表4个隐藏层的单元数,1代表1个样本。
现在X是多个样本,是3*m,w还是4*3,得到的Z就是4*m,4代表隐藏层的单元数,m代表的是样本数。

5 激活函数( Activation functions )
之前使用的激活函数都是sigmoid函数,我们还可以使用其它激活函数。
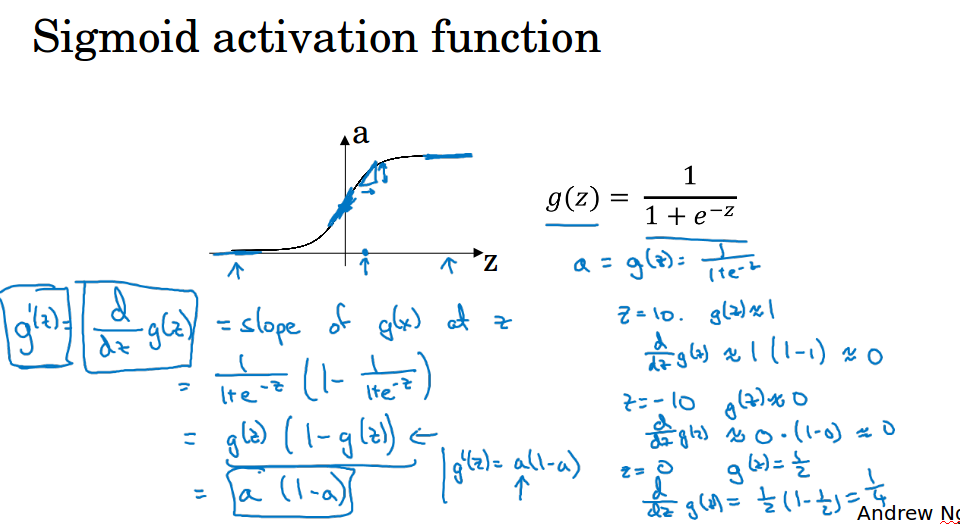
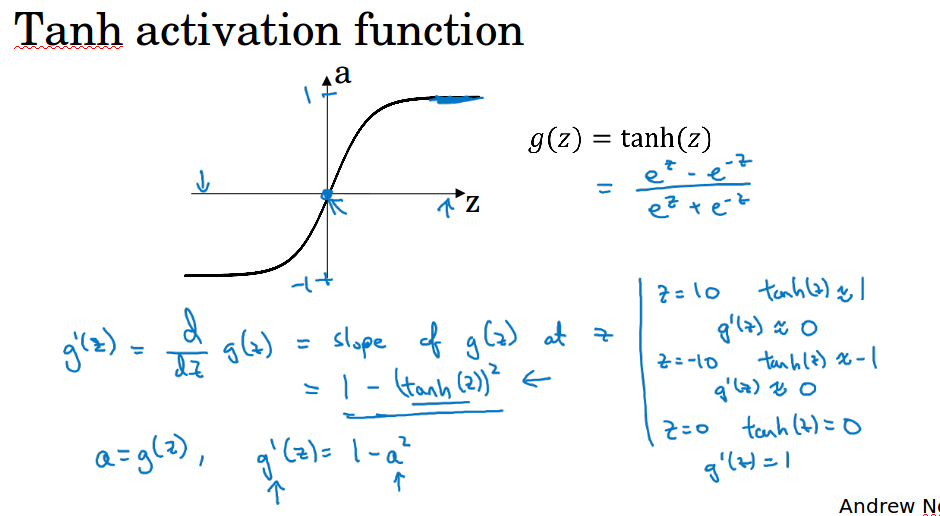
tanh( hyperbolic tangent 双曲正切),函数值介于-1到1之间,实际上这是sigmoid函数平移后的版本。
使用tanh几乎总比sigmoid表现更好,因为它的平均值为0,可以使得计算结果的平均值接近于0,起到了类似数据中心化的效果,它使得下一层的学习更方便。
ng表示他几乎不用sigmoid了,tanh几乎在任何场合都优于sigmoid,不过注意在输出层还是使用sigmoid,因为它输出[0,1]更符合概率分布。
sigmoid和tanh都有一个缺点,就是当自变量很大或者很小的时候,函数的导数特别小接近于0,这样会拖慢梯度下降的迭代,ng这里提到的问题应该就是梯度消失的问题了。
梯度消失是由于神经网络层数很多的时候,求导多次,导致梯度变得很小很小,这样前面的层就会学的很慢很慢,最后造成表现不好的结果。
可以用relu( rectified linear unit修正线性单元 ) 来解决这个问题。
选择激活函数有一些经验法则:做二分类的时候,sigmoid很适合做输出层的激活,其它层使用relu。
relu已经变成激活函数的默认选择了,如果你不确定隐层应该用哪个,就用relu作为激活,虽然人们有时候也会使用tanh。
relu的缺点是当z小于等于0时导数为0,所以有一个leakly relu,z小于等于0时导数不为0,但实践中很少使用。
现实中导数不会总是等于0,实践上神经网络有很多单元,总会有些单元导数不为0,所以通常使用relu,神经网络的学习会快很多,比tanh和sigmoid快,主要是它不会衰减梯度。
深度学习的其中一个特点就是在建立神经网络时经常有很多不同的选择,比如隐层个数,单元个数,激活函数,如何初始化权重,你很难去定下一个准则来确定什么参数最适合你的问题,有时候真的很难。
ng会在接下来这三门课中让我们了解到他在行业里见到的热门选择或冷门选择,但对于你的应用,事实上很难预先准备知道什么参数最有效。
所以一个建议是你不确定哪个激活函数的话,先试试,在验证集上跑跑,看看哪个参数效果好就用那个。
这里不会建议你一定要用relu而不用其它的,这对你目前或未来的问题中,可能管用也可能不管用。

6 为什么需要非线性激活函数( Why do you need non-linear activation functions )
如果你使用线性激活函数,或者没有激活函数,无论你的神经网络有多少层,你一直在做的只是计算线性激活函数。
这样做不如直接去掉所有隐藏层,因为你在这个过程中只是在做一个w的乘法,$w^{[1]}*w^{[2]}*w^{[3]}*...$,这里的123指的是层数。
在两层神经网络,如果你在隐藏层用线性激活,在输出层用sigmoid,这和没有隐层的逻辑回归是一样的。线性隐层一点意义都没有,因为线性函数的组合还是线性函数。
除非你引入非线性函数,否则你无法学习到更有趣的函数,层数再多也不行。
一般只有一个地方会用线性函数,就是在线性回归的输出层,因为它要预测的是一个实数,负无穷到正无穷。

7 激活函数的导数( Derivatives of activation functions )
这一节ng帮我们计算出了几个常用激活函数的导数,可以直接拿来用,当然可以自行推导验证一下。
sigmoid:导数为a * ( 1 - a)
tanh:导数为1 - a*a
relu:导数为,z大于等于0时为1,z小于0时为0

8 神经网络的梯度下降( Gradient descent for Neural Networks )
做几个符号约定,$n^{[0]}$代表特征数,即输入层的单元个数,$n^{[1]}$代表隐层的单元个数,$n^{[2]}$代表输出层的单元个数。
$w^{[1]}$代表第0层到第1层的权重,shape为( $n^{[1]}$,$n^{[0]}$ ),$b^{[1]}$的shape为( $n^{[1]}$,1),后面的层以此类推。
根据前面讲的内容,可以列出代价函数的式子进行梯度下降的计算,之前讲过梯度下降,也讲过向量化的实现,所以关键在于如何计算偏导,利用前向计算和反向传播可以得到。
显然,除了求导的时候需要链式求导,其它的都和逻辑回归中做的东西差不多。
图中np.sum中参数axis为1代表按行相加(0按列相加),keepdim为True表示最后得到(n, 1)的列向量


9 随机初始化( Random Initizlization )
在神经网络中随机初始化很重要(而不是初始化为0),如果全部初始化为0的话,隐层的每个单元学习到的权重w都是一样的(对称的),这种情况下多个隐藏单元没有任何意义,因为它们做的是一样的事情,而我们需要不同的隐藏单元去计算不同的函数。
所以要随机初始化,可以用$np.random.randn( (2,2) ) * 0.01$ 和$np.zeros( (2,1) )$初始化w1和b1,通常喜欢把w初始化为很小的随机数,因为如果用sigmoid或tanh时权值太大会导致梯度特别小,学习缓慢。
ng-深度学习-课程笔记-4: 浅层神经网络(Week3)的更多相关文章
- Andrew Ng - 深度学习工程师 - Part 1. 神经网络和深度学习(Week 3. 浅层神经网络)
=================第3周 浅层神经网络=============== ===3..1 神经网络概览=== ===3.2 神经网络表示=== ===3.3 计算神经网络的输出== ...
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- 深度学习课程笔记(一)CNN 卷积神经网络
深度学习课程笔记(一)CNN 解析篇 相关资料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html 首先提到 Why CNN for I ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
随机推荐
- 制作Windows U盘镜像
目的:制作windows server 2008 U盘镜像 需要的共具: 1.一个格式为FAT并且至少4G的U盘, 2.UltraISO软件, 3.一个windows server 2008 ISO文 ...
- Effective C++ —— 设计与声明(四)
条款18 : 让接口容易被正确使用,不易被误用 欲开发一个“容易被正确使用,不容易被误用”的接口,首先必须考虑客户可能做出什么样的错误操作. 1. 明智而审慎地导入新类型对预防“接口被误用”有神奇疗 ...
- [黑金原创教程] FPGA那些事儿《数学篇》- CORDIC 算法
简介 一本为完善<设计篇>的书,教你CORDIC算法以及定点数等,内容请看目录. 贴士 这本教程难度略高,请先用<时序篇>垫底. 目录 Experiment 01:认识CORD ...
- 【Android】TextView动态设置android:drawableLeft|Right|Top|Bottom,SetColor
Android中有时需动态设置控件四周的drawble图片,这个时候就需要调用 setCompoundDrawables(left, top, right, bottom),四个参数类型都是drawa ...
- java的synchronized有没有同步的类锁?
转自:http://langgufu.iteye.com/blog/2152608 http://www.cnblogs.com/beiyetengqing/p/6213437.html 没有... ...
- 爬虫实战【3】Python-如何将html转化为pdf(PdfKit)
前言 前面我们对博客园的文章进行了爬取,结果比较令人满意,可以一下子下载某个博主的所有文章了.但是,我们获取的只有文章中的文本内容,并且是没有排版的,看起来也比较费劲... 咋么办的?一个比较好的方法 ...
- Python中协程Event()函数
python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法wait.clear.set 事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 e ...
- javascript飞机大战-----002游戏引擎
基本html布局 <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- C++程序风格的思考
转载自:http://www.cppblog.com/weiym/archive/2013/04/27/199781.html 发现厚积薄发中有很多值得学习的东西 故引用之: 最近有机会看号称是公司最 ...
- Yii数据库子查询嵌入select中,而不是where条件语句中
$subQuery = (new Query())->select('COUNT(*)')->from('user'); // SELECT `id`, (SELECT COUNT(*) ...