Hadoop守护进程的作用(转)
概述:
<ignore_js_op>
Hadoop是一个能够对大量数据进行分布式处理的软件框架,实现了Google的MapReduce编程模型和框架,能够把应用程序分割成许多的 小的工作单元,并把这些单元放到任何集群节点上执行。在MapReduce中,一个准备提交执行的应用程序称为“作业(job)”,而从一个作业划分出 得、运行于各个计算节点的工作单元称为“任务(task)”。此外,Hadoop提供的分布式文件系统(HDFS)主要负责各个节点的数据存储,并实现了 高吞吐率的数据读写。
在分布式存储和分布式计算方面,Hadoop都是用从/从(Master/Slave)架构。在一个配置完整的集群上,想让Hadoop这头大 象奔跑起来,需要在集群中运行一系列后台(deamon)程序。不同的后台程序扮演不用的角色,这些角色由NameNode、DataNode、 Secondary NameNode、JobTracker、TaskTracker组成。其中NameNode、Secondary NameNode、JobTracker运行在Master节点上,而在每个Slave节点上,部署一个DataNode和TaskTracker,以便 这个Slave服务器运行的数据处理程序能尽可能直接处理本机的数据。对Master节点需要特别说明的是,在小集群中,Secondary NameNode可以属于某个从节点;在大型集群中,NameNode和JobTracker被分别部署在两台服务器上。
我们已经很熟悉这个5个进程,但是在使用的过程中,我们经常遇到问题,那么该如何入手解决这些问题。那么首先我们需了解的他们的原理和作用。
1.Namenode介绍
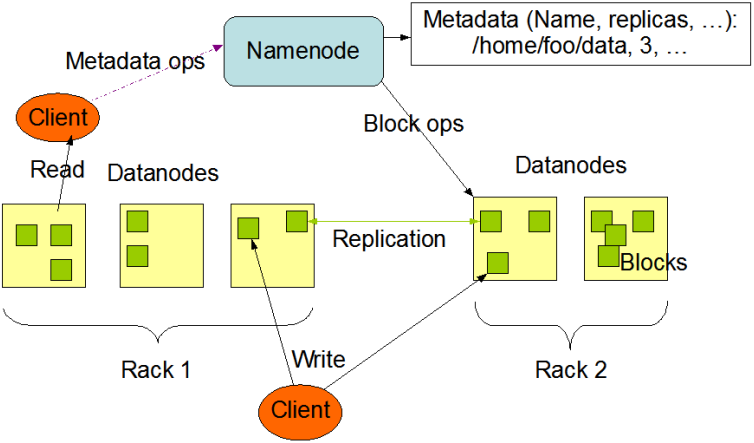
2、Datanode介绍
3、Secondary NameNode介绍
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的 快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
3.1NameNode的目录结构如下:
3.2Secondary NameNode的目录结构如下:

4、JobTracker介绍
4.1JobClient

在Hadoop中,作业是使用Job对象来抽象的,对于Job,我首先不得不介绍它的一个大家伙JobClient——客户端的实际工作者。JobClient除了自己完成一部分必要的工作外,还负责与JobTracker进行交互。所以客户端对Job的提交,绝大部分都是JobClient完成的,从上图中,我们可以得知JobClient提交Job的详细流程主要如下:

4.2JobTracker
上面谈到了客户端的JobClient对一个作业的提交所做的工作,那么这里,就要好好的谈一谈JobTracker为作业的提交到底干了那些个事情——一.为作业生成一个Job;二.接受该作业。
我们都知道,客户端的JobClient把作业的所有相关信息都保存到了JobTracker的系统目录下(当然是HDFS了),这样做的一个最大的好处就是客户端干了它所能干的事情同时也减少了服务器端JobTracker的负载。下面就来看看JobTracker是如何来完成客户端作业的提交的吧!哦。对了,在这里我不得不提的是客户端的JobClient向JobTracker正式提交作业时直传给了它一个改作业的JobId,这是因为与Job相关的所有信息已经存在于JobTracker的系统目录下,JobTracker只要根据JobId就能得到这个Job目录。
<ignore_js_op>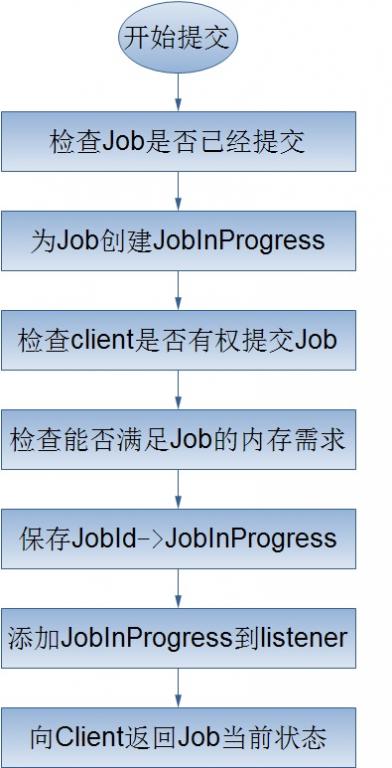
对于上面的Job的提交处理流程,我将简单的介绍以下几个过程:
1.创建Job的JobInProgress
JobInProgress对象详细的记录了Job的配置信息,以及它的执行情况,确切的来说应该是Job被分解的map、reduce任务。在JobInProgress对象的创建过程中,它主要干了两件事,一是把Job的job.xml、job.jar文件从Job目录copy到JobTracker的本地文件系统(job.xml->*/jobTracker/jobid.xml,job.jar->*/jobTracker/jobid.jar);二是创建JobStatus和Job的mapTask、reduceTask存队列来跟踪Job的状态信息。
2.检查客户端是否有权限提交Job
JobTracker验证客户端是否有权限提交Job实际上是交给QueueManager来处理的。
3.检查当前mapreduce集群能够满足Job的内存需求
客户端提交作业之前,会根据实际的应用情况配置作业任务的内存需求,同时JobTracker为了提高作业的吞吐量会限制作业任务的内存需求,所以在Job的提交时,JobTracker需要检查Job的内存需求是否满足JobTracker的设置。
上面流程已经完毕,可以总结为下图:
<ignore_js_op>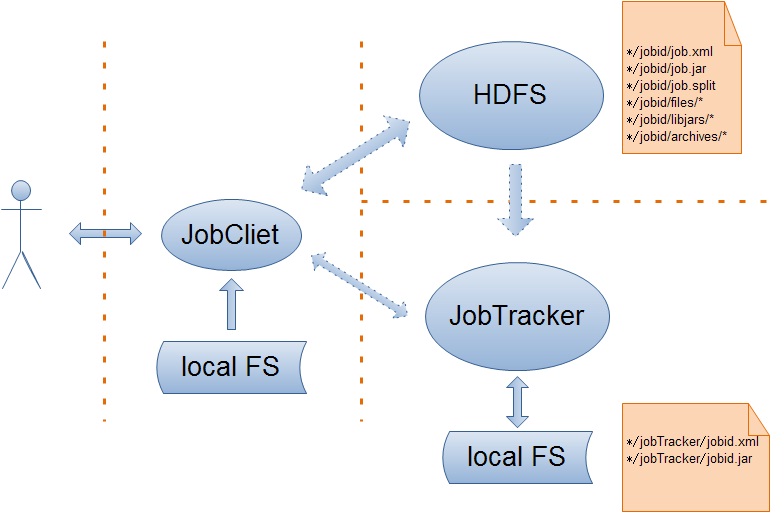
--------------------------------------------------------------------------------------------------------------------------
5、TaskTracker介绍
TaskTracker与负责存储数据的DataNode相结合,其处理结构上也遵循主/从架构。JobTracker位于主节点,统领 MapReduce工作;而TaskTrackers位于从节点,独立管理各自的task。每个TaskTracker负责独立执行具体的task,而 JobTracker负责分配task。虽然每个从节点仅有一个唯一的一个TaskTracker,但是每个TaskTracker可以产生多个java 虚拟机(JVM),用于并行处理多个map以及reduce任务。TaskTracker的一个重要职责就是与JobTracker交互。如果 JobTracker无法准时地获取TaskTracker提交的信息,JobTracker就判定TaskTracker已经崩溃,并将任务分配给其他 节点处理。
5.1TaskTracker内部设计与实现
Hadoop采用master-slave的架构设计来实现Map-Reduce框架,它的JobTracker节点作为主控节点来管理和调度用户提交的作业,TaskTracker节点作为工作节点来负责执行JobTracker节点分配的Map/Reduce任务。整个集群由一个JobTracker节点和若干个TaskTracker节点组成,当然,JobTracker节点也负责对TaskTracker节点进行管理。在前面一系列的博文中,我已经比较系统地讲述了JobTracker节点内部的设计与实现,而在本文,我将对TaskTracker节点的内部设计与实现进行一次全面的概述。
TaskTracker节点作为工作节点不仅要和JobTracker节点进行频繁的交互来获取作业的任务并负责在本地执行他们,而且也要和其它的TaskTracker节点交互来协同完成同一个作业。因此,在目前的Hadoop-0.20.2.0实现版本中,对工作节点TaskTracker的设计主要包含三类组件:服务组件、管理组件、工作组件。服务组件不仅负责与其它的TaskTracker节点而且还负责与JobTracker节点之间的通信服务,管理组件负责对该节点上的任务、作业、JVM实例以及内存进行管理,工作组件则负责调度Map/Reduce任务的执行。这三大组件的详细构成如下:

下面来详细的介绍这三类组件:
服务组件
TaskTracker节点内部的服务组件不仅用来为TaskTracker节点、客户端提供服务,而且还负责向TaskTracker节点请求服务,这一类组件主要包括HttpServer、TaskReportServer、JobClient三大组件。
1.HttpServer
TaskTracker节点在其内部使用Jetty Web容器来开启http服务,这个http服务一是用来为客户端提供Task日志查询服务,二是用来提供数据传输服务,即在执行Reduce任务时是通过TaskTracker节点提供的该http服务来获取属于自己的map输出数据。这里需要详细介绍的是与该服务相关的配置参数,集群管理者可以通过TaskTracker节点的配置文件来配置该服务地址和端口号,对应的配置项为:mapred.task.tracker.http.address。同时,为了能够灵活的控制该该服务的吞吐量,管理者还可以设置该http服务的内部工作线程数量,对应的配置为:tasktracker.http.threads。
2.Task Reporter
TaskTracker节点在接收到JobTracker节点发送过来的Map/Reduce任务之后,会把它们交给JVM实例来执行,而自己则需要收集这些任务的执行进度信息,这就使得Task在JVM实例中执行的时候需要不断地向TaskTracker节点报告当前的执行情况。虽然TaskTracker节点和JVM实例在同一台机器上,但是它们之间的进程通信却是通过网络I/O来完成的(此处并不讨论这种通信方式的性能),也就是TaskTracker节点在其内部开启一个端口来专门为任务实例提供进度报告服务。该服务地址可以通过配置项mapred.task.tracker.report.address来设置,而服务内部的工作线程的数量取2倍于该TaskTracker节点上的Map/Reduce Slot数量中的大者。
Hadoop守护进程的作用(转)的更多相关文章
- Hadoop守护进程【简--】
[转自]http://blog.sina.com.cn/s/blog_81e6c30b01019po3.html 守护进程,也就是通常说的Daemon进程,是Linux中的后台服务进程. 一般如果正常 ...
- Hadoop守护进程【简】
[转自]http://xzx4959.blog.163.com/blog/static/47868170201311901848348/ 一般如果正常启动hadoop,我们可以在master上通过jp ...
- Linux Guard Service - 守护进程的作用、用途、父进程标识的特点
让test2直接成为守护进程 [root@localhost 02]# cat test2.c //test2 #include<stdio.h> #include<unistd.h ...
- cloudera learning3:Hadoop配置和守护进程logs
Services:Haddoop cluster上可以部署的组件,比如HDFS,YARN,HBase等. Roles:在service配置时,由Cloudera Manager创建.比如NameNod ...
- 【Linux】守护进程的定义,作用,创建流程
本文内容: 1.守护进程的定义 2.守护进程的作用 3.守护进程的创建过程 一.守护进程的定义 1.守护进程是脱离于终端并且在后台运行的进程 2.守护进程脱离终端是为了避免在执行过程中的信息在任何终端 ...
- hadoop地址配置、内存配置、守护进程设置、环境设置
1.1 hadoop配置 hadoop配置文件在安装包的etc/hadoop目录下,但是为了方便升级,配置不被覆盖一般放在其他地方,并用环境变量HADOOP_CONF_DIR指定目录. 1.1.1 ...
- Redis守护进程作用+数据类型
Redis开启守护进程的作用: 在 linux 中,每一个系统与用户进行交流的界面称为终端 如果没有开启守护进程,相当于知识在前台开启了Redis,当终端关闭时,Reids服务也会跟着关闭 而开启守护 ...
- linux分享六:nohup与&,守护进程
contab每秒执行脚本,然后将把标准错误重定向到标准输出(2>&1)以追加的方式写入log_cronjob.txt.补充:试想2>1代表什么,2与>结合代表错误重定向,而1 ...
- Unix环境高级编程(十三)守护进程
守护进程也称为精灵进程是一种生存期较长的一种进程.它们独立于控制终端并且周期性的执行某种任务或等待处理某些发生的事件.他们常常在系统引导装入时启动,在系统关闭时终止.unix系统有很多守护进程,大多数 ...
随机推荐
- 用valgrind检测php扩展内存泄露
原文:https://bugs.php.net/bugs-getting-valgrind-log.php 前提 1,编译php的时候,必须要带上--enable-debug选项. 2,禁用php的内 ...
- 有关js弹出提示框几种方法
1直接提示只有确定功能的提示框 只显示提示信息 alert(“提示信息”); alert ();的参数只有一个就是提示信息,无返回值 2 弹出输入框让你输入内容 prompt() ; 有两个参数:第一 ...
- 协议森林08 不放弃 (TCP协议与流通信)
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! TCP(Transportation Control Protocol)协议与IP ...
- BZOJ2599:[IOI2011]Race(点分治)
Description 给一棵树,每条边有权.求一条简单路径,权值和等于K,且边的数量最小.N <= 200000, K <= 1000000 Input 第一行 两个整数 n, k 第二 ...
- [USACO09MAR]Sand Castle
嘟嘟嘟 太水了,大佬们就绕道吧…… 就是m, b数组分别排个序,然后更改对应位置的m[i]和b[i],就行了. 因为如果m[i]不改为b[i]而是b[i + 1]的话,那么必定要将m[j] (j &g ...
- 日常踩坑——rand()总是出现重复数据
写了一个生成随机数组的函数,然后跑出来,结果总是…… 然后,很奇怪的是一步一步调试,它就没问题了,WTF??? 问题出在:重复写了srand(time(NULL)),只保留一个就好了. int* ge ...
- DOM操作怎样添加、移除、移动、复制。创建和查找节点?
(1)创建新节点 createDocumentFragment() //创建一个DOM片段 createElement() //创建一个具体的元素 createTextNode() //创建一个文本节 ...
- HTTP 错误 401.0 - Unauthorized 的解决方案
1.安装vs2015后,以前做的项目中Forms身份验证,竟然不能使用了 2.打开当前项目属性,将windows身份验证属性改为启用 3.vs2015生成的mvc项目中,webconfig缺失auth ...
- No.4 - 3D 空间的卡片翻转动效
参考 ①张鑫旭http://www.zhangxinxu.com/wordpress/2012/09/css3-3d-transform-perspective-animate-transition/ ...
- 阅读AuTO利用深度强化学习自动优化数据中心流量工程(一)
目录 问题 解决方法 模型选择 框架构建 Sigcomm'18 AuTO: Scaling Deep Reinforcement Learning for Datacenter-Scale Autom ...