沉淀再出发:ELK使用初探
沉淀再出发:ELK使用初探
一、前言
ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。
最近ElasticSearch可以说是非常火的一款开源软件了,自从上市之后,有了更大更远的场景,它最本质的作用就是为公司内部或者一个小的范围之内的系统提供搜索引擎的检索技术,使得检索可以更加的精细化和自动化,相比于其他的软件,es有着更加强大和简易的平台和使用方式,可以快速搭建出我们想要的搜索平台,因此受到了大家广泛的欢迎。Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
由于Logstash服务依赖ES服务,Kibana服务依赖Logstash和ES,所以ELK的服务启动顺序为:ES->Logstash->Kibana。
二、ElasticSearch初步了解
2.1、简介
ElasticSearch 的底层是开源的Lucene。Elastic提供了REST API的操作接口,是Lucene的扩展。底层依旧是索引,但是可以把大索引切成n片,放到不同的节点,所以就实现了分布式。也就理所当然的是读写负载均衡。此外,他还是一个分布式实时文档存储,其中每个field可被搜索。 ES 可以自动将海量数据分布到多台服务器上去存储和检索海量数据。可以在秒级别在每台服务器上分析数据。Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。Elasticsearch是一个近实时(Near Realtime[NRT])的搜索平台。这意味着当你导入一个文档并把它变成可搜索的时间仅会有轻微的延时。
基本组件:
().索引(index):文档容器,类似于关系型数据库中的库。索引名必须是小写字母。
().类型(type):类型是索引内部的逻辑分区。其意义完全取决与用户需求,一个索引内部可定义多个类型。类似于关系型数据库中的表结构,字段。
警告,Type在6.0.0版本中已经不赞成使用。
().文档(document):文档是Lucene索引和搜索的原子单位。它包含多个域。基于JSON格式存储。每个域的格式类似于字典。
().映射(mapping):原始内容存储为文档之前的分析,映射就是定义此映射过程该如何实现。(例如切词,过滤)
集群组件:
()Cluster:ES的集群标识为集群名称。默认为“elasticsearch”,节点靠此名字决定加入到哪一个集群中。一个节点只能属于一个集群。
().Node:运行单个ES实例的主机。节点的标识靠节点名。在一个集群中,你想启动多少节点就可以启动多少节点。此外,如果没有其它节点运行在当前网络中,
只启动一个节点将默认形成一个新的名称为“elasticsearch”单节点集群。
().Shard:将索引切割成为的物理存储组件,但每一个shared都是一个独立且完整的索引,创建索引时,ES默认分割为5个shard。
用户也可以按需自定义,创建完成后不可修改。shard有两种,primary和replica。用于负载均衡。
ES Cluster启动过程。通过多播(或单播)在9300/tcp查找同一集群中的其他节点,并建立通信。集群中所有节点会选举出一个主节点负责管理整个集群状态。以及在集群范围内决定shared的分布。
2.2、安装ElasticSearch
在使用es之前,我们要先确定已经安装和配置了java环境,之后我们下载ElasticSearch,根据不同的系统下载相应的版本,解压即可。
解压之后,我们使用cmd进入其中的bin目录,之后的命令在这个里面启动即可。
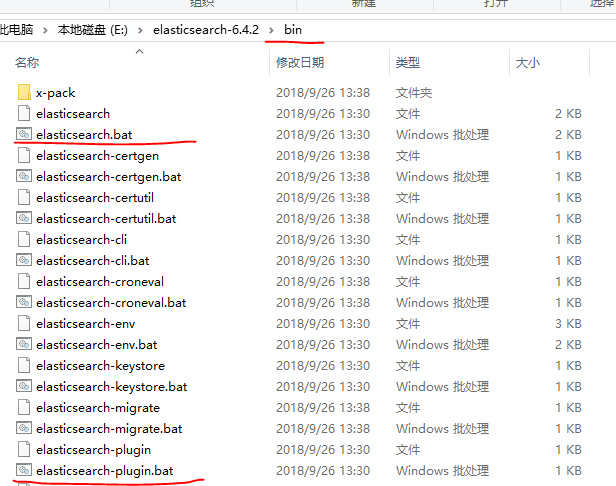
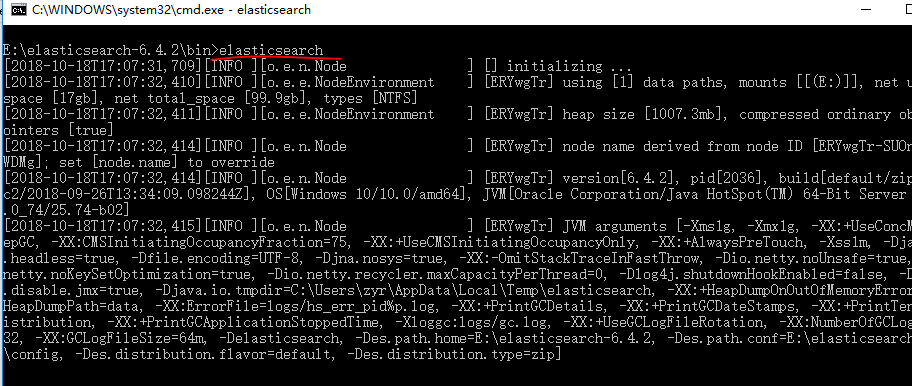
这样es服务器已经运行了,我们使用浏览器进行访问 http://127.0.0.1:9200/:
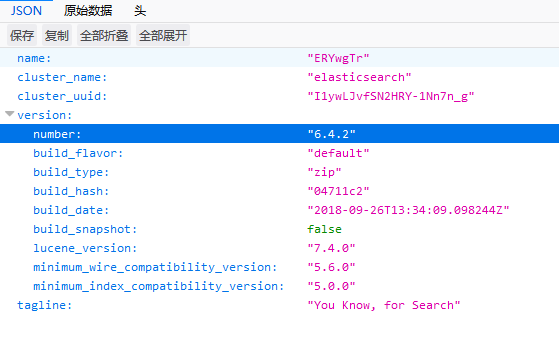
至此,es就安装好了,为了方便,我们可以把这个目录放到环境变量之中:
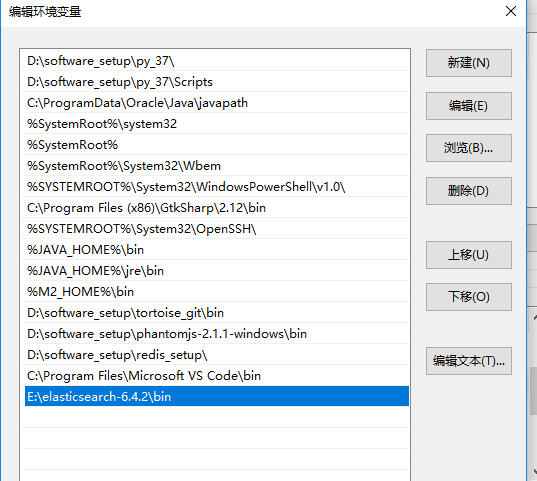
同样的我们使用git的curl命令,也可以进行访问:
curl localhost:
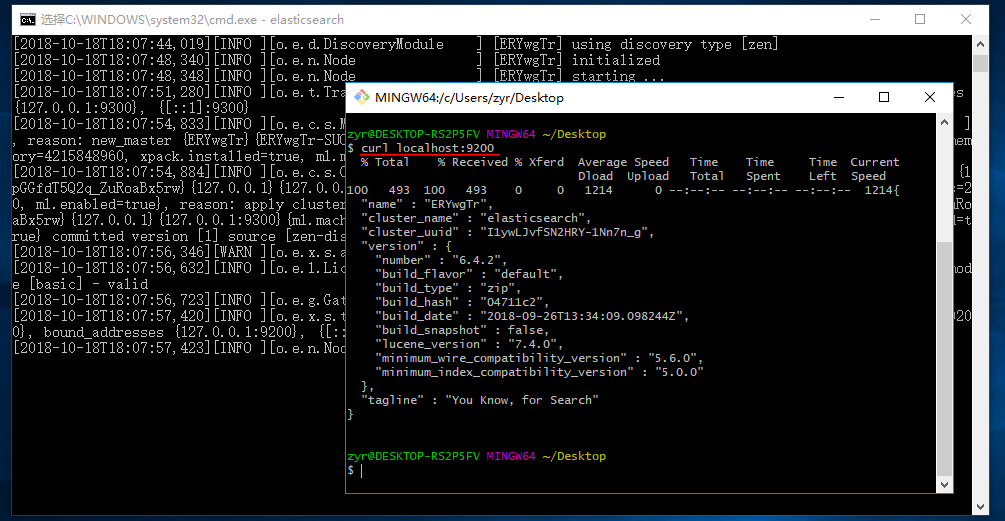
下面的命令可以查看当前节点的所有 Index。
curl -X GET 'http://localhost:9200/_cat/indices?v'

下面的命令可以列出每个 Index 所包含的 Type。根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
curl 'localhost:9200/_mapping?pretty=true'

作为配置的一部分,在集群之中,我们需要修改es的配置:
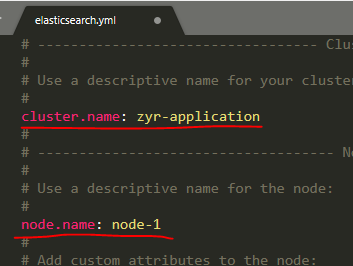
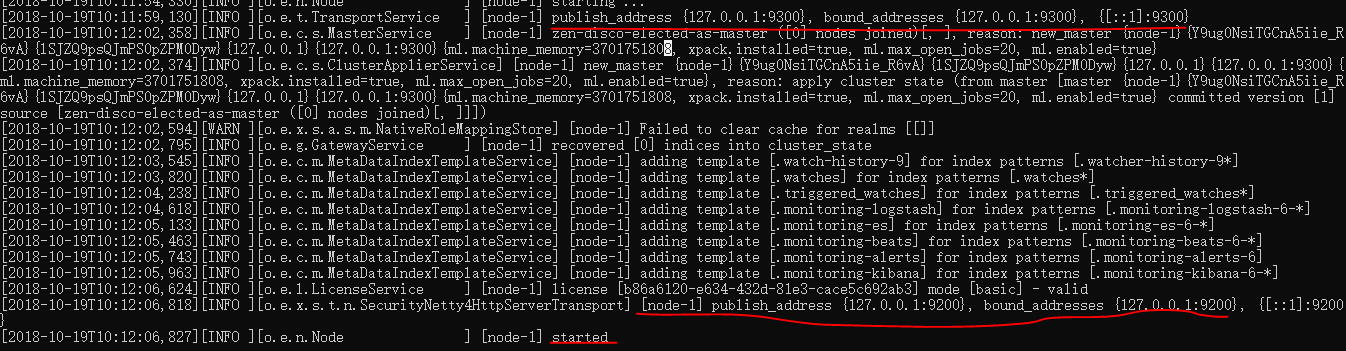

2.3、基本概念
(1)document
document是个文件,里面有很多file。比如
{
"name":"小红",
"age":""
}
这就一个文件,而name就是个file,age也是
(2)index
es里的index概念就像是个数据库,里面存放很多个document
新建 Index,可以直接向 Elastic 服务器发出 PUT 请求。下面的例子是新建一个名叫weather的 Index。
curl -X PUT 'localhost:9200/weather'
(3)type
比如document是存放动物的数据,那么type就是把动物的类型分类,比如猫科,狗科,鸟科等
(4)shard和replica
如果有个10T的数据,有5台服务器,每个服务器只能放2T的数据,怎么办?
分布式解决:那么就是理解10T为index,数据分成5份,每个服务器放2T的数据,而这5台服务器就是shard。
为了避免服务器宕机就为这5台服务器分别配了台备用服务器,称为replica。这样拿数据就可以在replica拿,也可以在shard拿,
基本上不用担心数据同步问题,因为es是实时性的。
三、安装logstash
3.1、下载和安装logstash
我们在官网上下载logstash,然后解压之后进行安装,为了服务的正常运行,建议logstash的版本和es的一致,同样的包括下面将要安装的kibana也是一样。
3.2、解压和配置
将下载好的安装包解压,之后在bin目录下新建配置文件logstash.conf,进行相应的配置:
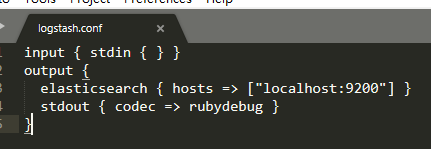
input { stdin { } }
output {
elasticsearch { hosts => ["localhost:9200"] }
stdout { codec => rubydebug }
}
然后使用logstash -f logstash.conf启动(注意不用再启动logstash,因为这个命令就是带着配置来启动的):
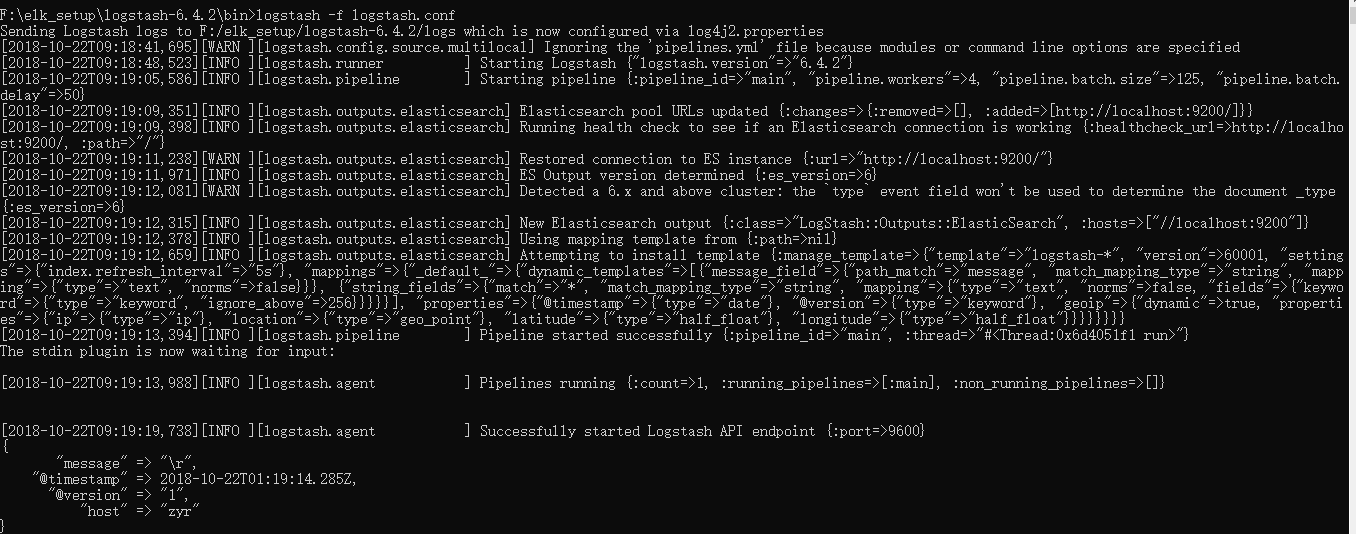
同样的es上面也有提示:

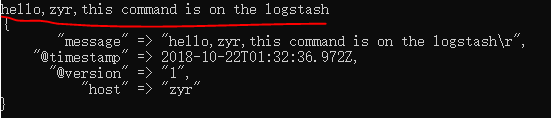
此时在logstash的cmd中输入消息,就能被logstash解析并且返回相应格式的结果:
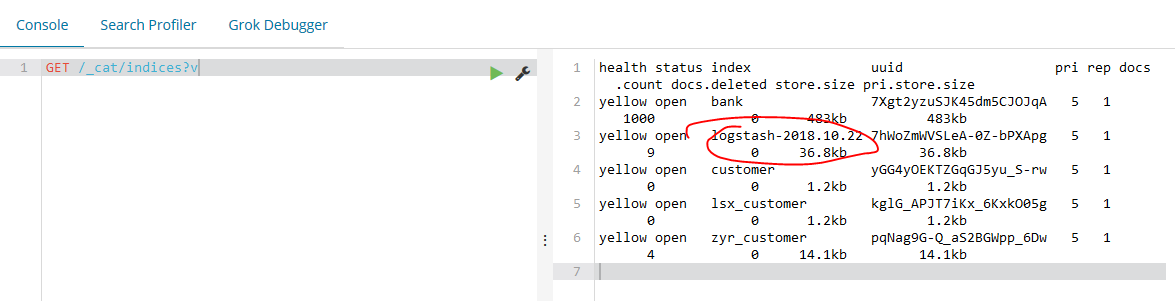
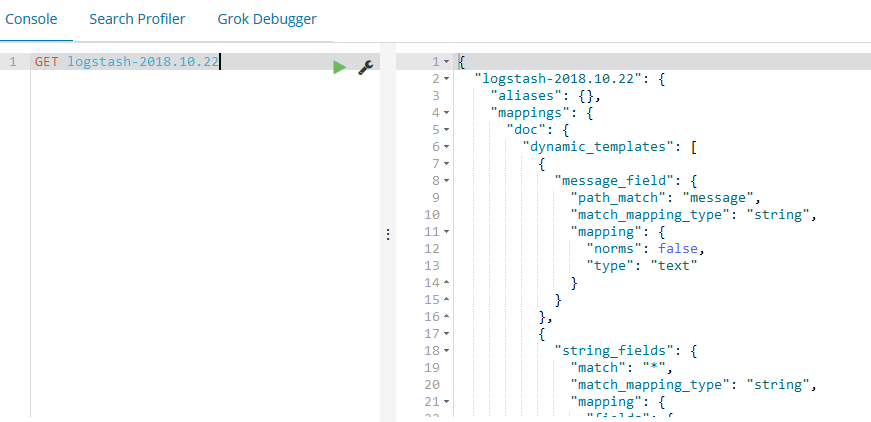
同时使用kibana查看日志输出到es的情况:
3.3、logstash本质
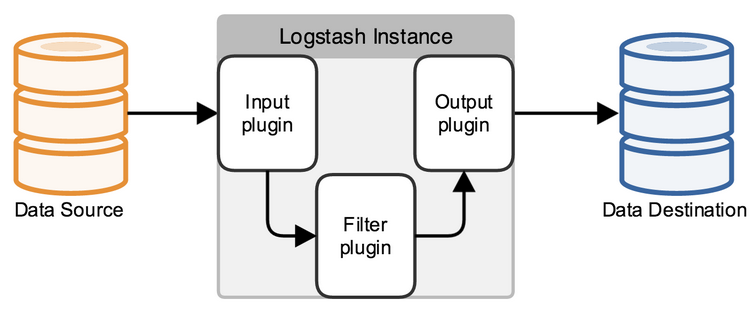
logstash使用管道方式进行日志的搜集处理和输出。在logstash中,包括了三个阶段:输入input --> 处理filter(不是必须的) --> 输出output;每个阶段都由很多的插件配合工作,比如file、elasticsearch、redis等等。每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。Logstash 每读取一次数据的行为叫做事件。
-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash;
-e:后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出);
-l:日志输出的地址(默认就是stdout直接在控制台中输出);
-t:测试配置文件是否正确,然后退出。
logstash基本上由三部分组成,input、output以及用户需要才添加的filter,因此标准的配置文件格式如下:
input {...}
filter {...}
output {...}
在每个部分中,也可以指定多个访问方式,如果在filter中添加了多种处理规则,则按照它的顺序一一处理,但是有一些插件并不是线程安全的。比如在filter中指定了两个一样的的插件,这两个任务并不能保证准确的按顺序执行,因此官方也推荐避免在filter中重复使用插件。
此外让我们再看一个例子,将文件作为输入,处理里面的内容,然后输出,注意这里的日志文件最后应该有一个空行,不然因为解析机制可能出错。
logstash_test.conf:
input {
file {
path => "E:/logstash-6.4.2/data/test.log"
start_position => beginning
}
}
filter {
}
output {
stdout {}
}
test.log:
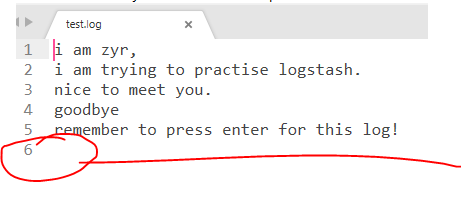
file 输入插件默认使用 “\n” 判断日志中每行的边界位置。如果没有“\n”将会导致日志数据无法导入到 Elasticsearch 中。
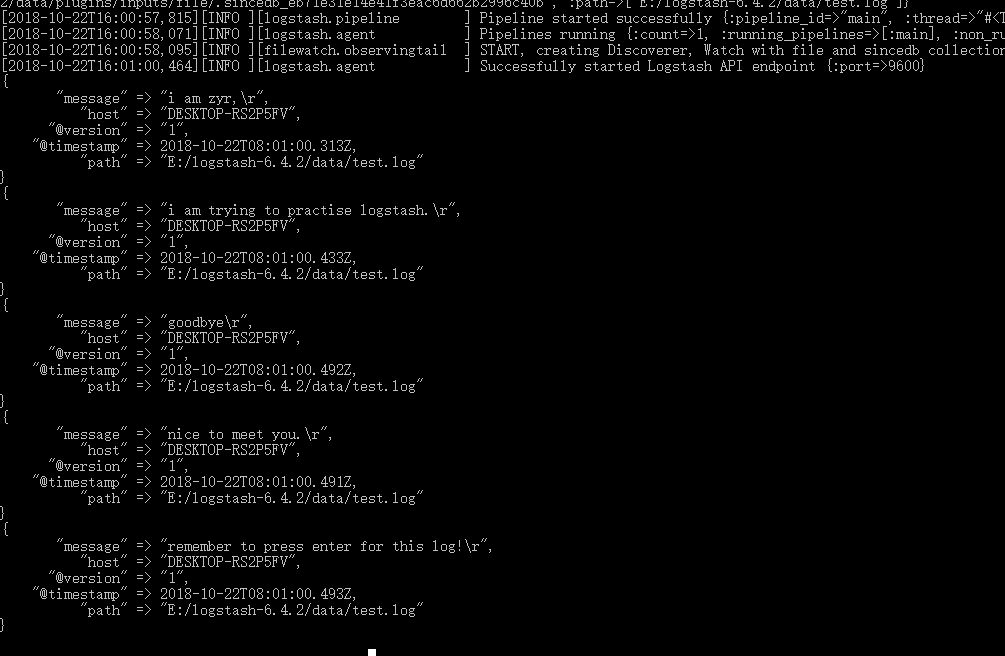
更多的设置可以查看https://www.elastic.co/guide/en/logstash/current/config-examples.html。
四、安装kibana
4.1、下载和安装
在官网上下载,之后解压、配置、启动即可:

等服务启动之后,我们访问http://127.0.0.1:5601界面,至此,我们可以灵活地对上面的两个软件进行操作和监控了。

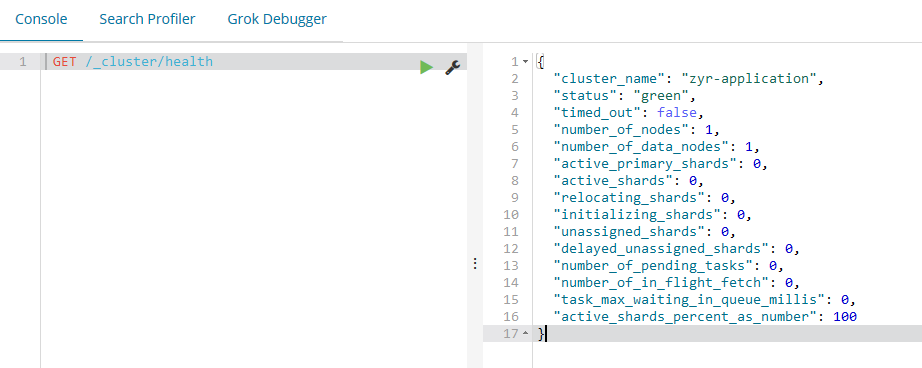
五、使用elasticsearch进行增删改查(CRUD)
5.1、查看es的运行状态是否健康
GET /_cat/health?v

或者使用git:
curl -XGET 'localhost:9200/_cat/health?v&pretty'
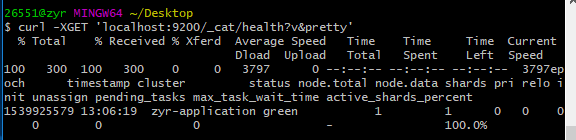
我们可以看到我们的名称为“elasticsearch”的集群正在运行,状态标识为green。无论何时查看集群健康状态,我们会得到green、yellow、red中的任何一个。
Green - 一切运行正常(集群功能齐全)
Yellow - 所有数据是可以获取的,但是一些复制品还没有被分配(集群功能齐全)
Red - 一些数据因为一些原因获取不到(集群部分功能不可用),当一个集群处于red状态时,它会通过可用的分片继续提供搜索服务,但是当有未分配的分片时,需要尽快的修复它。
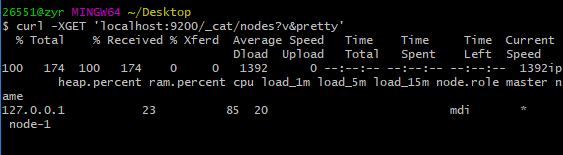
5.2、查看正在运行的节点
GET /_cat/nodes?v

curl -XGET 'localhost:9200/_cat/nodes?v&pretty'

5.3、列出所有的索引
GET /_cat/indices?v
curl -XGET 'localhost:9200/_cat/indices?v&pretty'


这个返回结果只是一个表头,就是我们的集群中还没有任何索引。
5.4、创建一个索引
现在让我们创建一个索引,名称为“customer”,然后再一次列出所有的索引:
PUT /customer?pretty
GET /_cat/indices?v
Curl命令:
curl -XPUT 'localhost:9200/customer?pretty&pretty'
curl -XGET 'localhost:9200/_cat/indices?v&pretty'
但是我的及其执行之后却显示超时,返回不了正常的结果,到底是什么地方出了问题呢?!查询都能正常运行,说明网络没问题,那么就是程序内部的问题了。
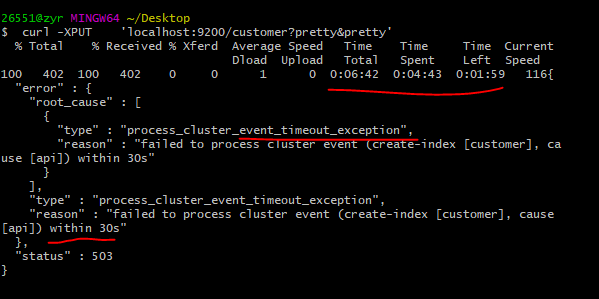
但是其实上,我们重启一下es就会发现这个index已经被创建了,原因可能是节点的相应有问题。
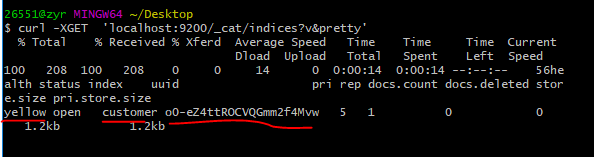
同样的,我们能看到,节点的状态由正常转变成了黄色,那就是因为这个index没有备份,因为我们只有一个节点,当我们配置了其他的节点,这个状态就会发生改变了。

此时,我们再次创建索引就会发现正常显示了,由此可以断定,以前的节点是有问题的,需要重启,在实际工程中遇到问题,我们需要沉着冷静的分析,在发现没有解决办法,网上也找不到的时候,我们可以尝试着缩小问题的范围,定位好问题,然后重新来过试一试。
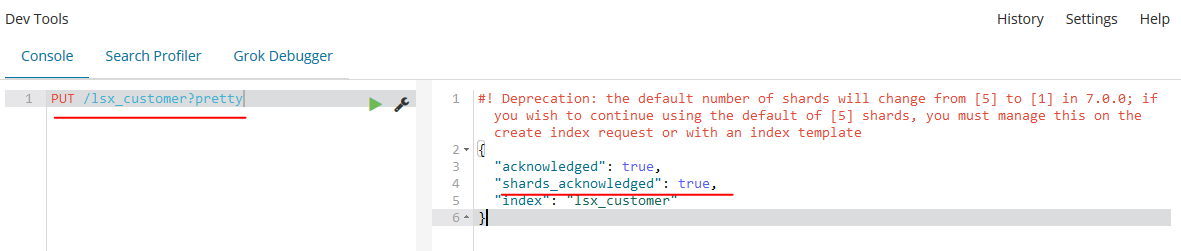
5.5、在索引中加入数据并查看
/<Index>/<Type>/<ID> ,pretty是为了让回显过来的数据美观。
PUT /customer/doc/?pretty
{
"name": "lsx,zyr"
}

curl -XPUT 'localhost:9200/customer/doc/1?pretty&pretty' -H 'Content-Type: application/json' -d '{"name": "John Doe"}'
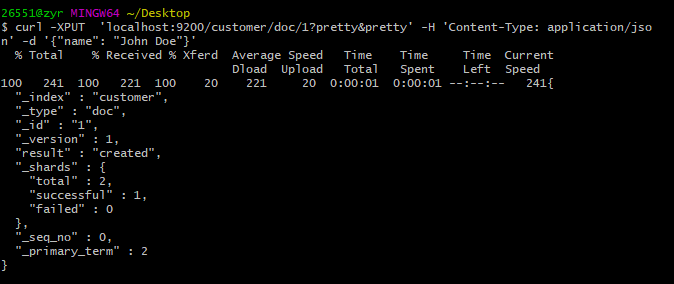

从上面我们可以看到,一个新的顾客文档已经在customer索引中成功创建。同时这个文档有一个自己的id,这个id就是我们在将文档加入索引时指定的。这里有一个重要的注意点,我们不需要在将一个文档加入一个索引前明确的将这个索引预先创建好。在上面我们创建文档的例子中,如果这个customer索引事先不存在,Elasticsearch会自动创建customer索引。比如:
curl -XPUT 'localhost:9200/zyr_customer/doc/1994?pretty&pretty' -H 'Content-Type: application/json' -d '{"name": "zyrlsx"}'
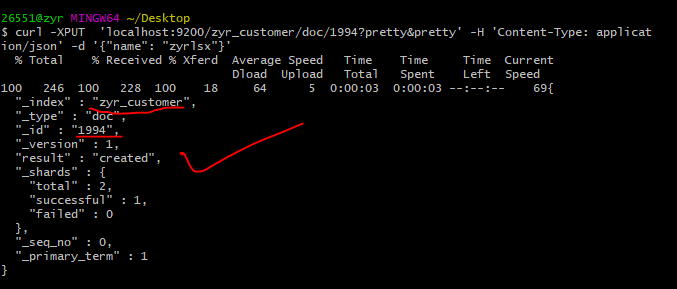
由此,我们可以确定上面的put不成功肯定是节点的问题,我们将节点重启一次就好了。

我们再次查看索引:
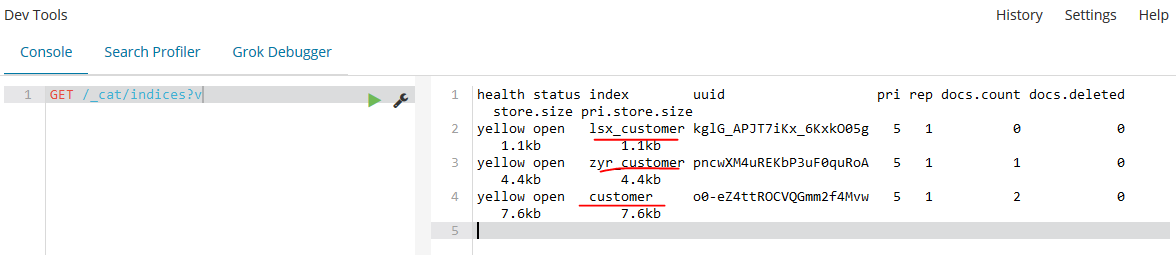
下面让我们查看插入的数据:
GET /customer/doc/(id)?pretty
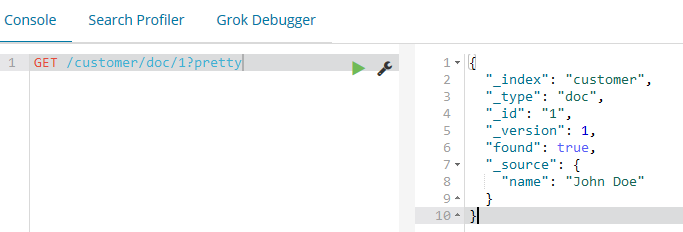
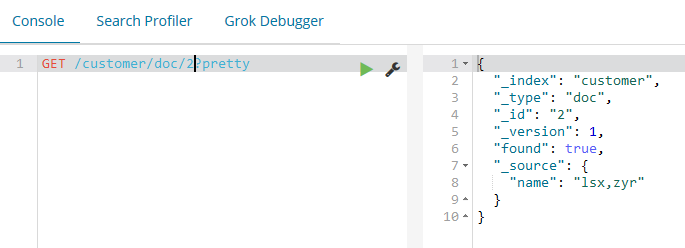
curl -XGET 'localhost:9200/customer/doc/1?pretty&pretty'

found属性表示我们通过请求ID为1发现了一个文档,还有另一个属性_source,_source属性返回我们在上一步中加入索引的完整JSON文档内容。
5.6、删除一个索引
DELETE /customer?pretty
GET /_cat/indices?v



curl -XDELETE 'localhost:9200/zyr_customer?pretty&pretty'
curl -XGET 'localhost:9200/_cat/indices?v&pretty'
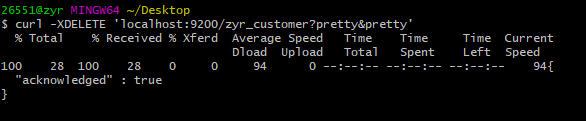


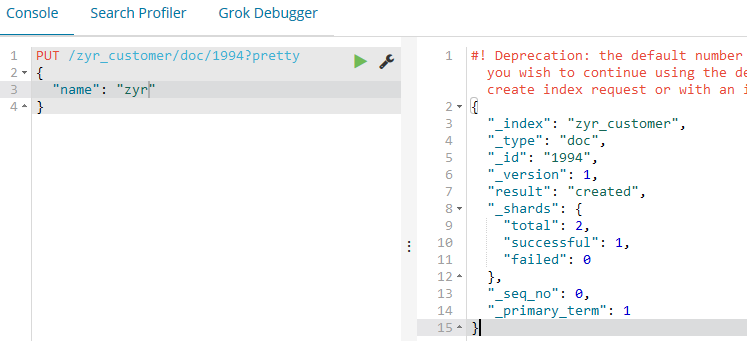
5.7、替换和更新索引中的文档
上面我们已经学习了,增、删、查,那么还有一个命令就是修改了。其实如果我们将id相同的命令,命令不变,参数修改之后再次put进去,那么结果就会被替换了,注意,这里的替换和更新的用法略微有所差异,比如:
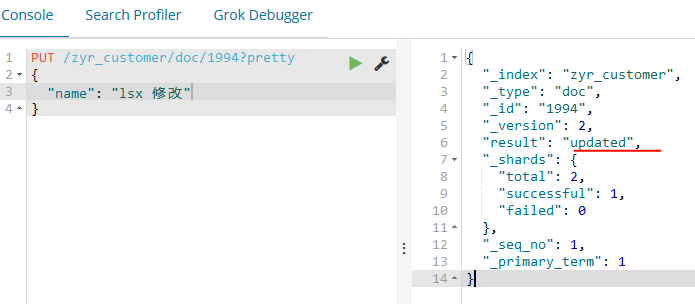
同时修改之后版本(_version)也会增加。

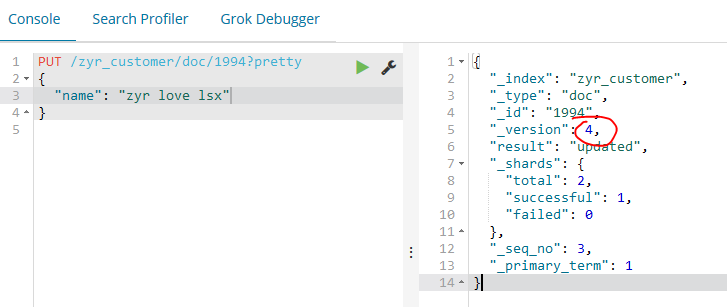
这里我们需要注意,如果我们插入文档的时候,不设定id,系统会自动分配id,实际Elasticsearch生成的ID(或者是我们明确指定的)将会在API调用成功后返回:
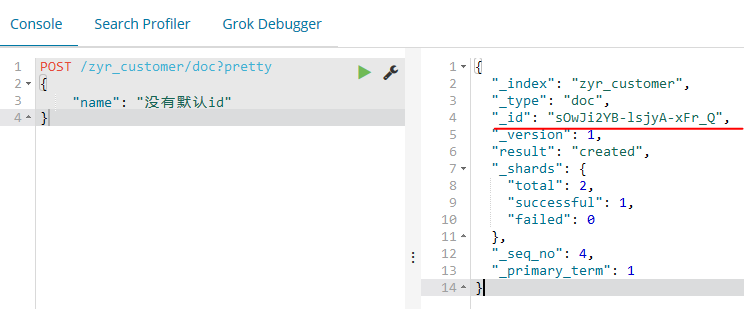
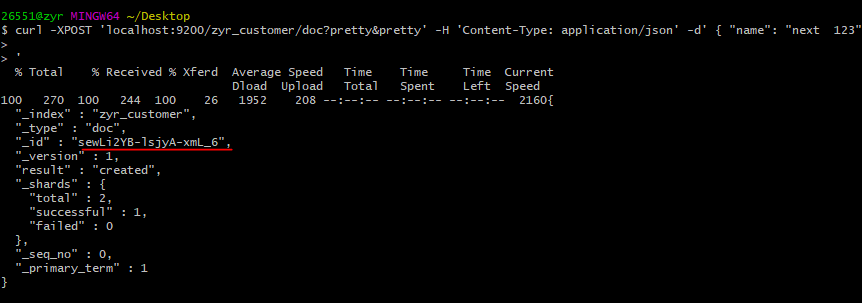
curl -XPOST 'localhost:9200/zyr_customer/doc?pretty&pretty' -H 'Content-Type: application/json' -d' { "name": "next 123" }'
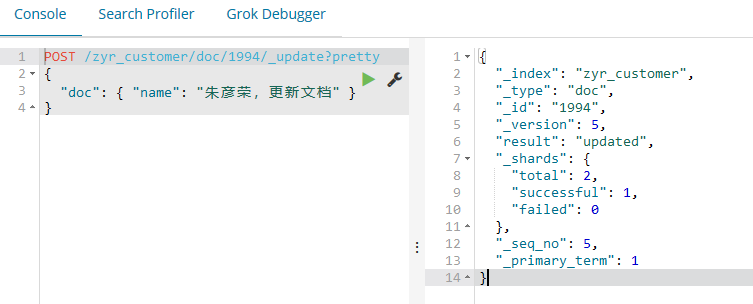
更新文档:
除了能够新增和替换文档,我们也可以更新文档。注意虽然Elasticsearch在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch首先去删除旧的文档,然后加入新的文档。
POST /zyr_customer/doc//_update?pretty
{
"doc": { "name": "朱彦荣,更新文档" }
}
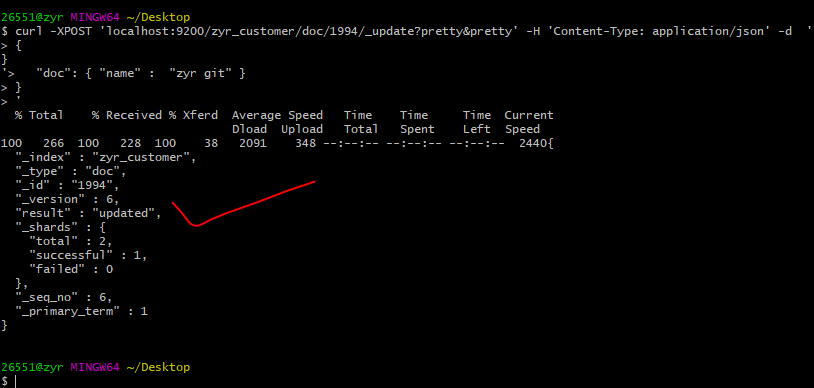
使用curl:
curl -XPOST 'localhost:9200/zyr_customer/doc/1994/_update?pretty&pretty' -H 'Content-Type: application/json' -d '
{
"doc": { "name" : "zyr git" }
}
'
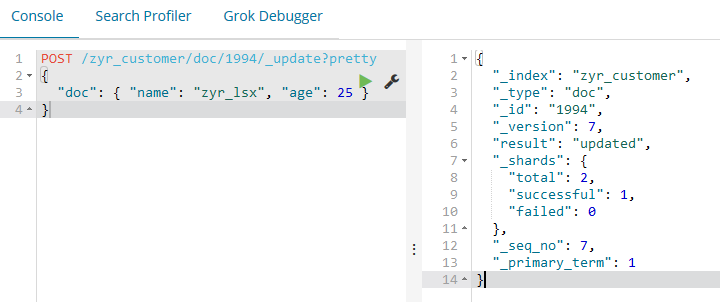
更新操作也可以使用简单的脚本来执行,比如:
POST /zyr_customer/doc//_update?pretty
{
"script" : "ctx._source.age += 5"
}
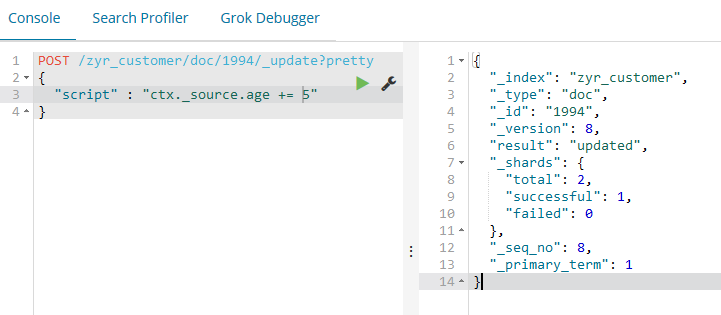
curl -XPOST 'localhost:9200/zyr_customer/doc/1994/_update?pretty&pretty' -H 'Content-Type: application/json' -d ' { "script" : "ctx._source.age += 5" } '
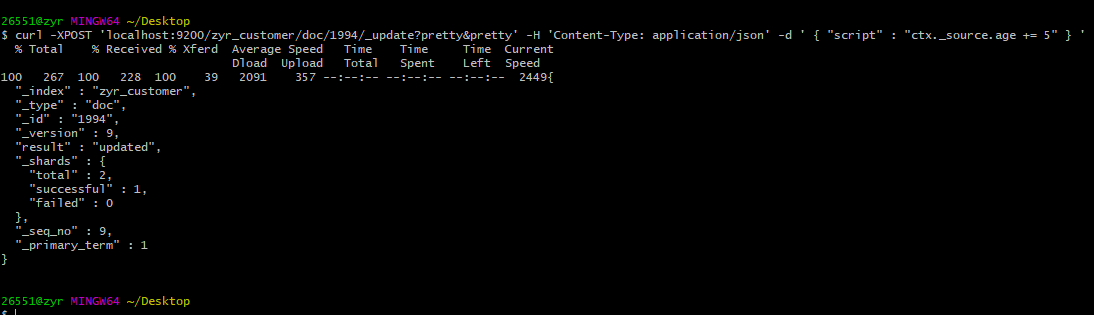
ctx._source指代的是当前需要被更新的source文档。

5.8、删除一个文档
DELETE /zyr_customer/doc/?pretty
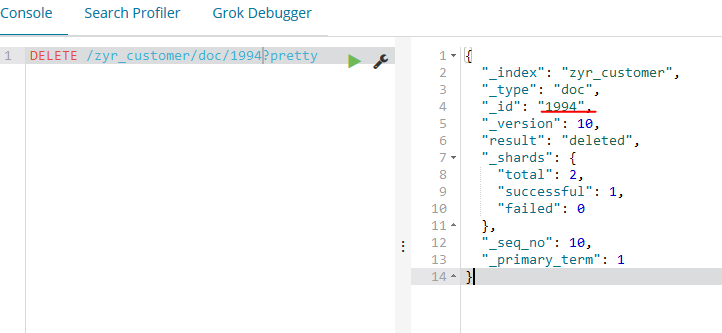
curl -XDELETE 'localhost:9200/zyr_customer/doc/1994?pretty&pretty'
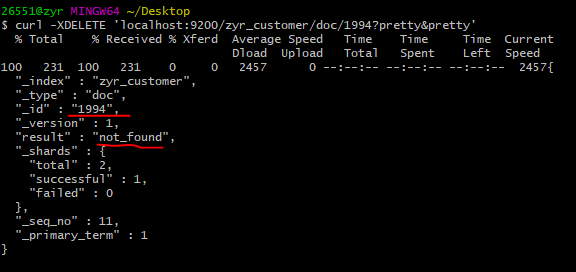
5.9、批处理
除了在单个文档上执行索引,更新和删除操作外,Elasticsearch还提供了批操作的功能,通过使用 _bulk API完成。这个功能非常重要,因为它提供了一种非常高效的机制去通过更少的网络切换尽可能快的执行多个操作。
POST /zyr_customer/doc/_bulk?pretty
{"index":{"_id":""}}
{"name": "zyr" }
{"index":{"_id":""}}
{"name": "lsx" }
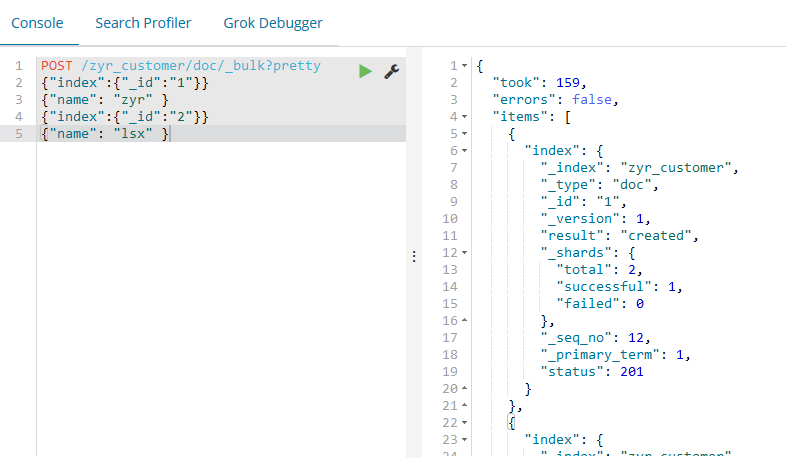
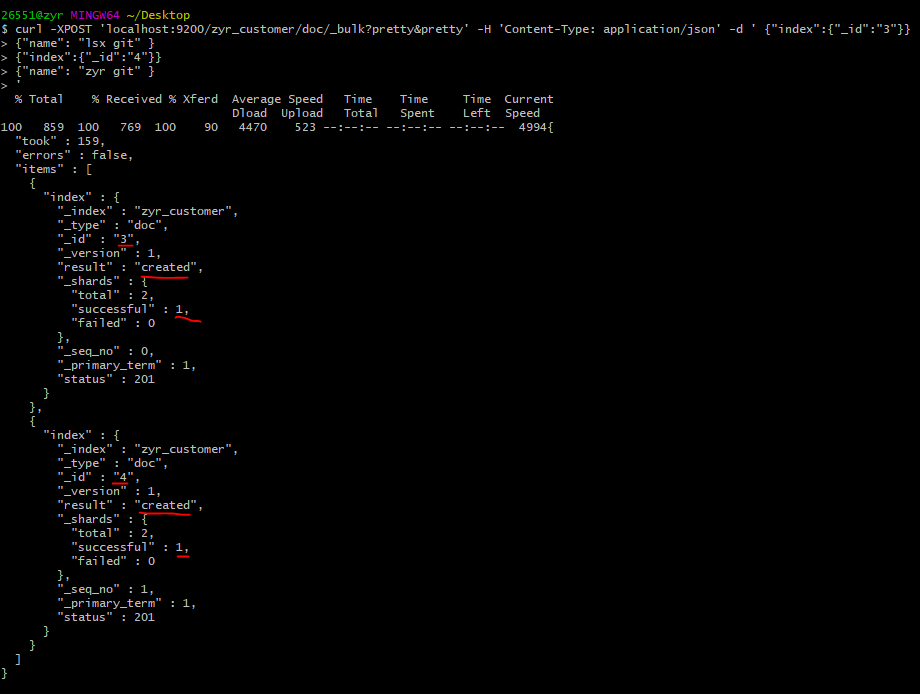
curl -XPOST 'localhost:9200/zyr_customer/doc/_bulk?pretty&pretty' -H 'Content-Type: application/json' -d ' {"index":{"_id":"3"}}
{"name": "lsx git" }
{"index":{"_id":""}}
{"name": "zyr git" }
'
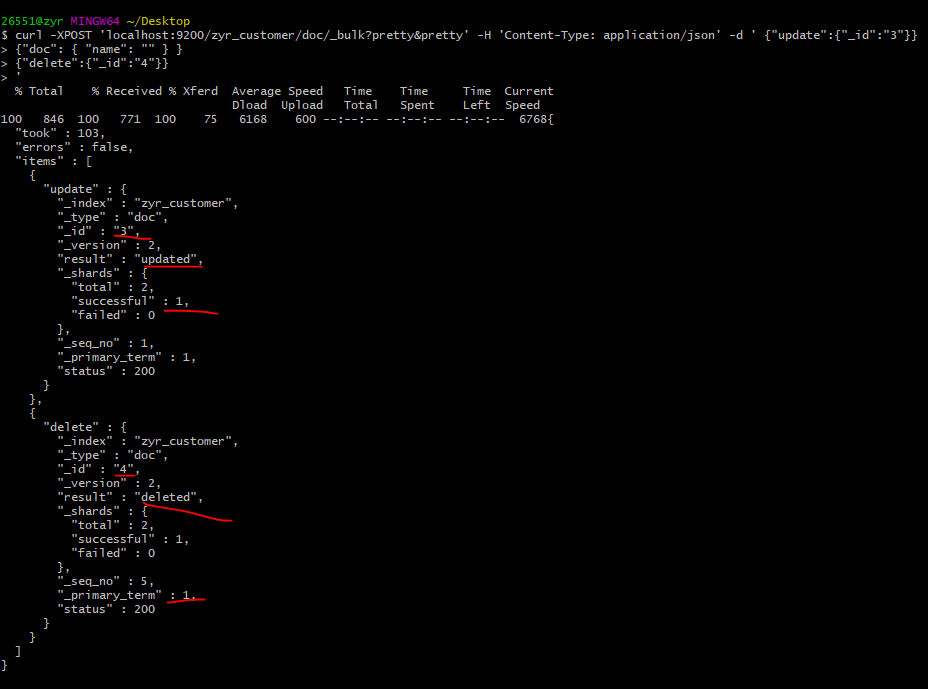
再如下面的案例,更新id为1的文档,删除id为2的文档:
POST /zyr_customer/doc/_bulk?pretty
{"update":{"_id":""}}
{"doc": { "name": "批处理更新" } }
{"delete":{"_id":""}}

curl -XPOST 'localhost:9200/zyr_customer/doc/_bulk?pretty&pretty' -H 'Content-Type: application/json' -d ' {"update":{"_id":"3"}}
{"doc": { "name": "" } }
{"delete":{"_id":""}}
'
至此,我们对es的增删改查有了非常深刻的理解和使用。
六、批量导入数据到elasticsearch中并处理
6.1、批量导入数据
首先我们需要有数据,可以从这里拿到数据,然后保存到本地,命名为account.json文件。
之后,我们需要使用git命令,将目录调整到存放account.json的目录,然后使用下面的命令,创建索引为bank,文档为account的数据:
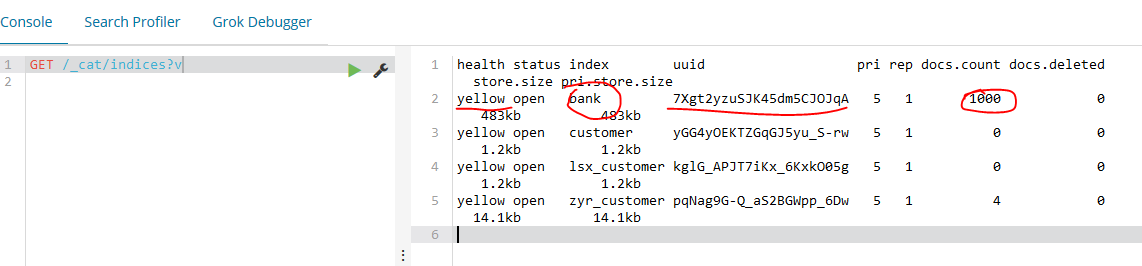
curl -H "Content-Type: application/json" -XPOST 'localhost:9200/bank/account/_bulk?pretty&refresh' --data-binary "@account.json"

这样数据就导入成功了,如下所示,1000条信息。
6.2、搜索API
执行搜索有两种基础的方式,一种是在请求的URL中加入参数来实现,另一种方式是将请求内容放到请求体中。使用请求体可以让JSON数据以一种更加可读和更加富有展现力的方式发送。REST API可以使用_search端点来实现搜索。
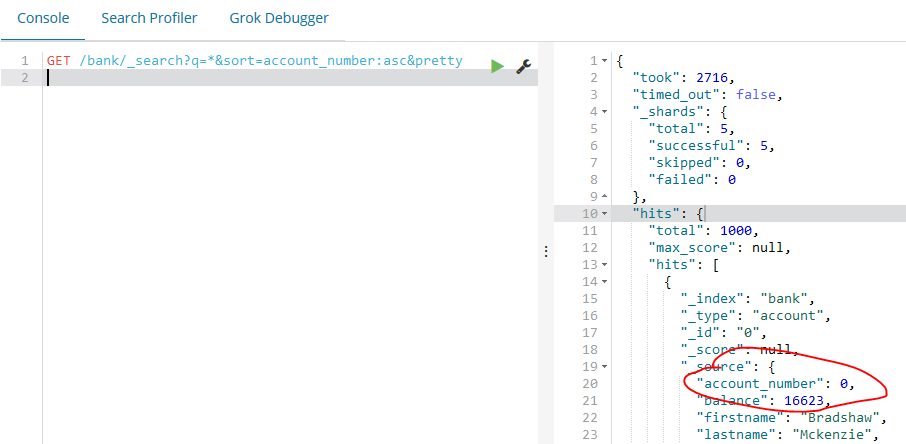
如下的示例将返回bank索引的所有的文档并且按照某一个参数(account_number)从小到大排序:
GET /bank/_search?q=*&sort=account_number:asc&pretty
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": null,
"hits": [
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": ,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "bradshawmckenzie@euron.com",
"city": "Hobucken",
"state": "CO"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Amber",
"lastname": "Duke",
"age": ,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Roberta",
"lastname": "Bender",
"age": ,
"gender": "F",
"address": "560 Kingsway Place",
"employer": "Chillium",
"email": "robertabender@chillium.com",
"city": "Bennett",
"state": "LA"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Levine",
"lastname": "Burks",
"age": ,
"gender": "F",
"address": "328 Wilson Avenue",
"employer": "Amtap",
"email": "levineburks@amtap.com",
"city": "Cochranville",
"state": "HI"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Rodriquez",
"lastname": "Flores",
"age": ,
"gender": "F",
"address": "986 Wyckoff Avenue",
"employer": "Tourmania",
"email": "rodriquezflores@tourmania.com",
"city": "Eastvale",
"state": "HI"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Leola",
"lastname": "Stewart",
"age": ,
"gender": "F",
"address": "311 Elm Place",
"employer": "Diginetic",
"email": "leolastewart@diginetic.com",
"city": "Fairview",
"state": "NJ"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Hattie",
"lastname": "Bond",
"age": ,
"gender": "M",
"address": "671 Bristol Street",
"employer": "Netagy",
"email": "hattiebond@netagy.com",
"city": "Dante",
"state": "TN"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Levy",
"lastname": "Richard",
"age": ,
"gender": "M",
"address": "820 Logan Street",
"employer": "Teraprene",
"email": "levyrichard@teraprene.com",
"city": "Shrewsbury",
"state": "MO"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Jan",
"lastname": "Burns",
"age": ,
"gender": "M",
"address": "699 Visitation Place",
"employer": "Glasstep",
"email": "janburns@glasstep.com",
"city": "Wakulla",
"state": "AZ"
},
"sort": [
]
},
{
"_index": "bank",
"_type": "account",
"_id": "",
"_score": null,
"_source": {
"account_number": ,
"balance": ,
"firstname": "Opal",
"lastname": "Meadows",
"age": ,
"gender": "M",
"address": "963 Neptune Avenue",
"employer": "Cedward",
"email": "opalmeadows@cedward.com",
"city": "Olney",
"state": "OH"
},
"sort": [
]
}
]
}
}搜索结果
搜索结果
curl -XGET 'localhost:9200/bank/_search?q=*&sort=account_number:asc&pretty&pretty'
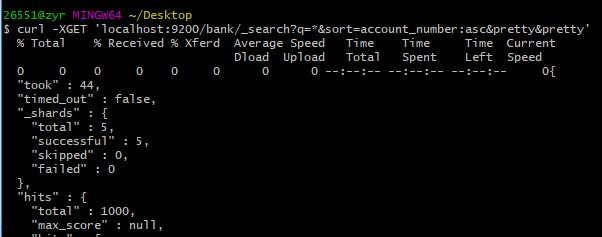
took - Elasticsearch执行此次搜索所用的时间(单位:毫秒)
timed_out - 告诉我们此次搜索是否超时
_shards - 告诉我们搜索了多少分片,还有搜索成功和搜索失败的分片数量
hits - 搜索结果
hits.total - 符合搜索条件的文档数量
hits.hits - 实际返回的搜索结果对象数组(默认只返回前10条)
hits.sort - 返回结果的排序字段值(如果是按score进行排序,则没有)
hits._score 和 max_score - 目前先忽略这两个字段
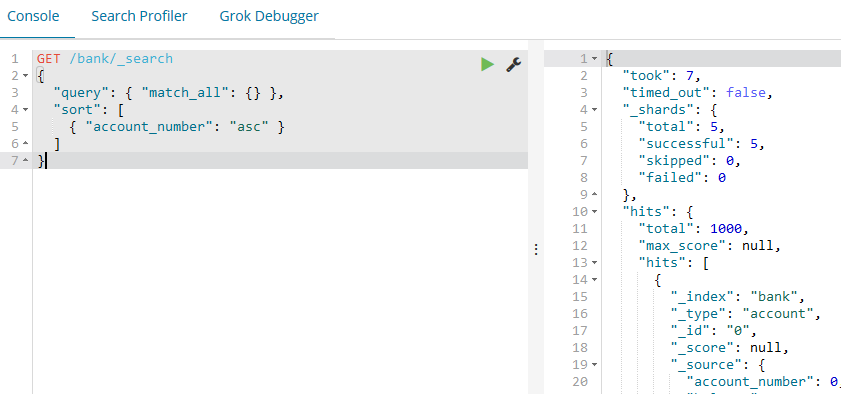
使用请求体的方式来获得:
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}
curl -XGET 'localhost:9200/bank/_search?pretty' -H 'Content-Type: application/json' -d '
{ "query": { "match_all": {} }, "sort": [ { "account_number": "asc" } ] } '

这里的不同点在于我们使用一个JSON格式的请求体代替了在URI中的 q=* 参数,一旦得到了返回结果,Elasticsearch就完全执行结束,不会保持任何的服务器资源或者往结果里加入开放的游标,理解这一点是非常重要的。这同很多其他的平台比如SQL数据库的一些特性形成了鲜明的对比,比如在SQL数据库中可能在查询时,会首先得到查询结果的一部分,然后需要通过一些有状态的服务端游标不断地去请求服务端来取得剩余的查询结果。
七、Query DSL语言
Elasticsearch提供了一种JSON格式的领域特定语言,你可以使用它来执行查询。这个通常叫做Query DSL。这门查询语言相当的全面。
7.1、Query DSL语言简单使用
如下面的查询,分析以上查询,query 部分告诉我们我们的查询定义是什么,match_all 部分简单指定了我们想去执行的查询类型,意思就是在索引中搜索所有的文档。除了query参数,我们还可以通过其他的参数影响搜索结果。
GET /bank/_search
{
"query": { "match_all": {} }
}
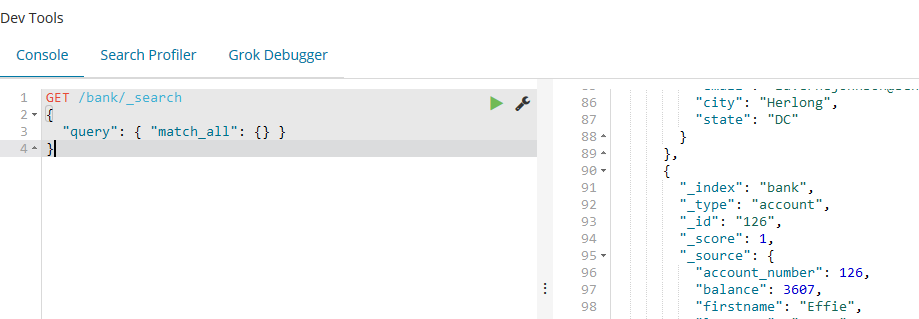
比如我们增加查询条件size,如果size没有指定,它默认为10。
GET /bank/_search
{
"query": { "match_all": {} },
"size":
}
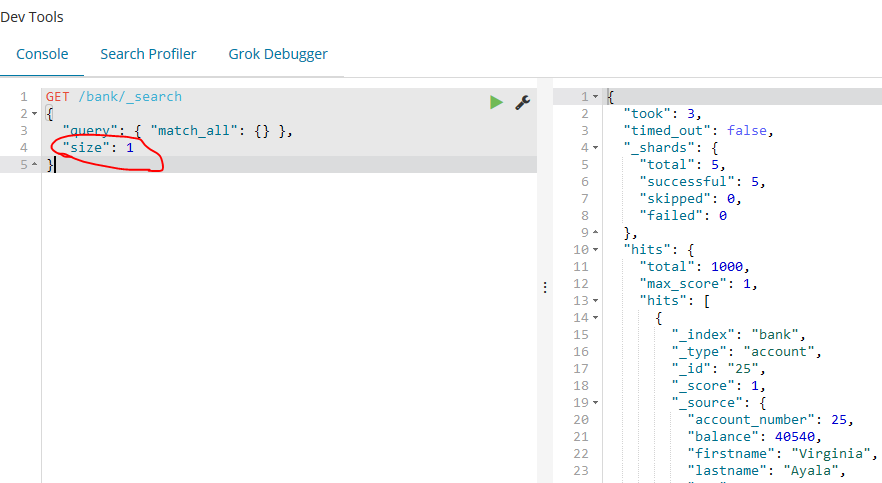
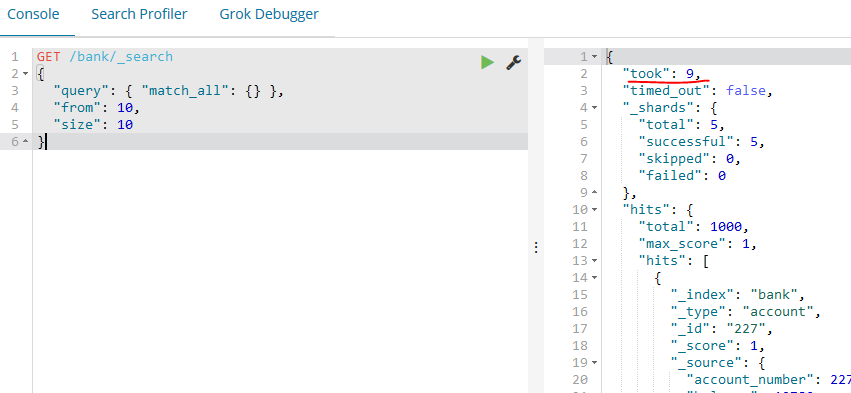
如下的示例使用match_all并返回了11到20(一共10个)的文档,from 参数(从0开始)指定了从哪个文档索引开始,size 参数指定了从from指定的索引开始返回多少个文档。这个特性在实现分页搜索时很有用。注意如果from参数没有指定,它默认为0。
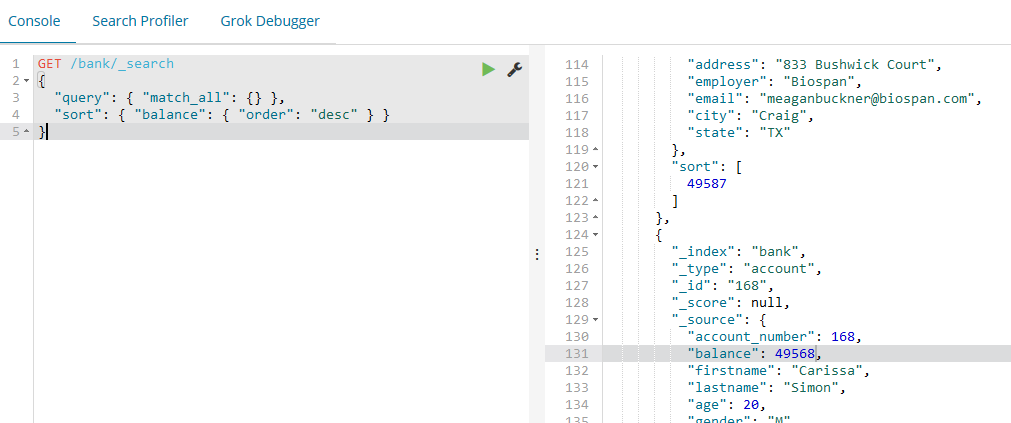
如下示例使用match_all并且按账户的balance值进行倒序排列后返回前10条文档:
GET /bank/_search
{
"query": { "match_all": {} },
"sort": { "balance": { "order": "desc" } }
}
7.2、高级搜索功能
首先,我们来关注一下返回的文档属性。默认情况下,文档会作为搜索结果的一部分返回所有的属性值。这个文档的JSON内容被称为source(返回结果中的hits的_source属性值)。如果我们不需要返回所有的source文档属性,我们可以在请求体中加入我们需要返回的属性名。
如下的示例演示了如何返回两个属性,account_number 和 balance (在_source中):
GET /bank/_search
{
"query": { "match_all": {} },
"_source": ["account_number", "balance"]
}
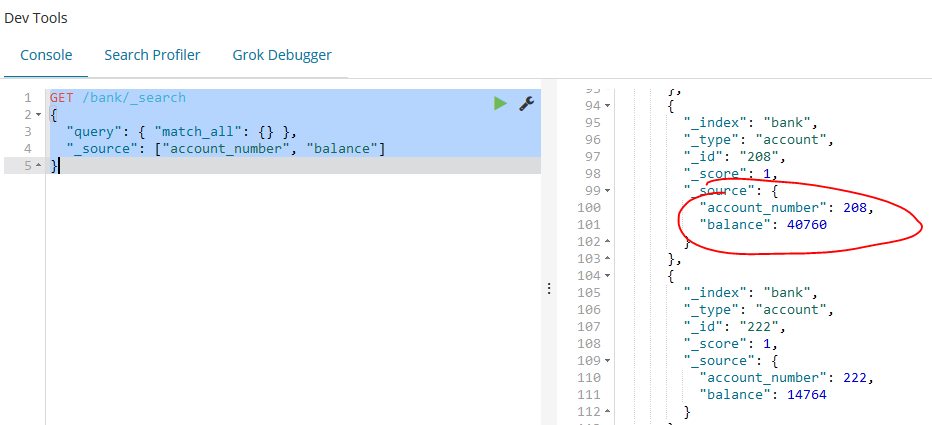
match_all匹配所有的文档,match 查询,它可以被认为是基本的属性搜索查询,就是通过特定的一个或多个属性来搜索:
GET /bank/_search
{
"query": { "match": { "account_number": } }
}

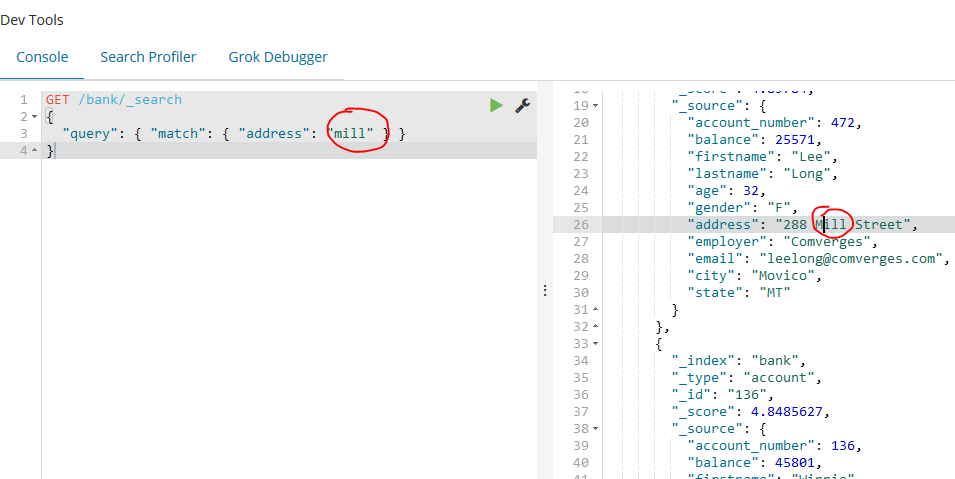
如下示例返回所有的address字段中包含“mill”这个单词,不区分大小写的账户文档:
GET /bank/_search
{
"query": { "match": { "address": "mill" } }
}
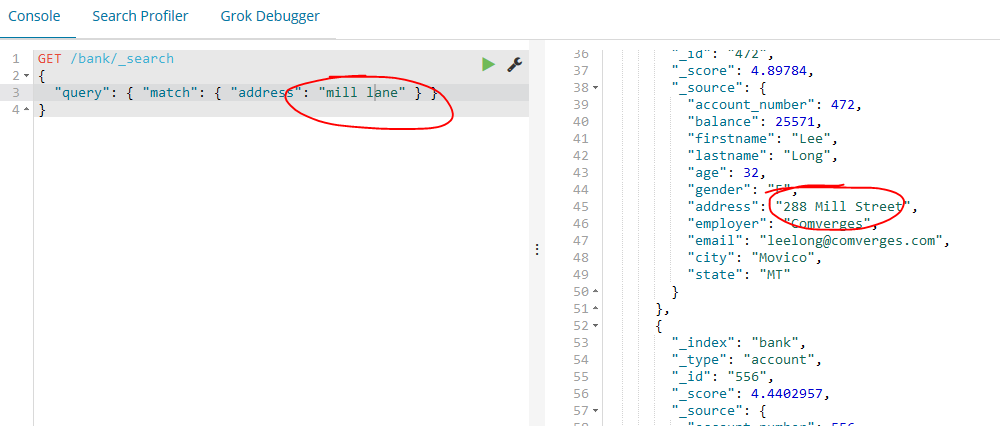
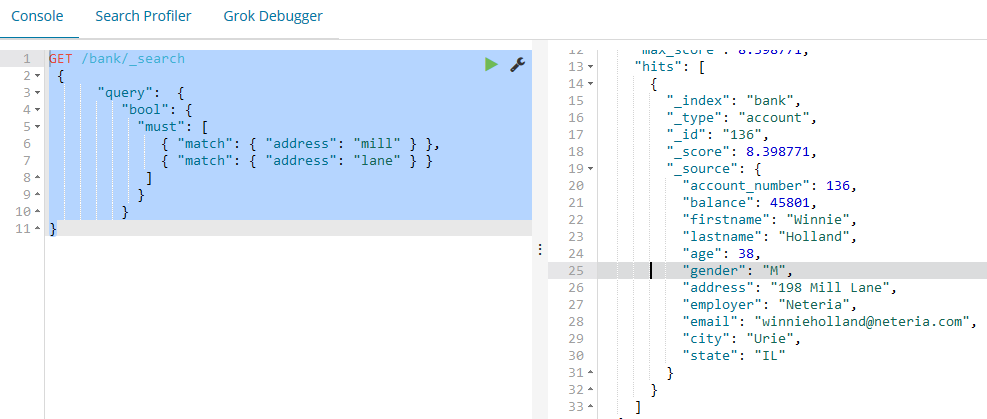
如下示例返回所有的address字段中包含“mill”或者是“lane”的账户文档:
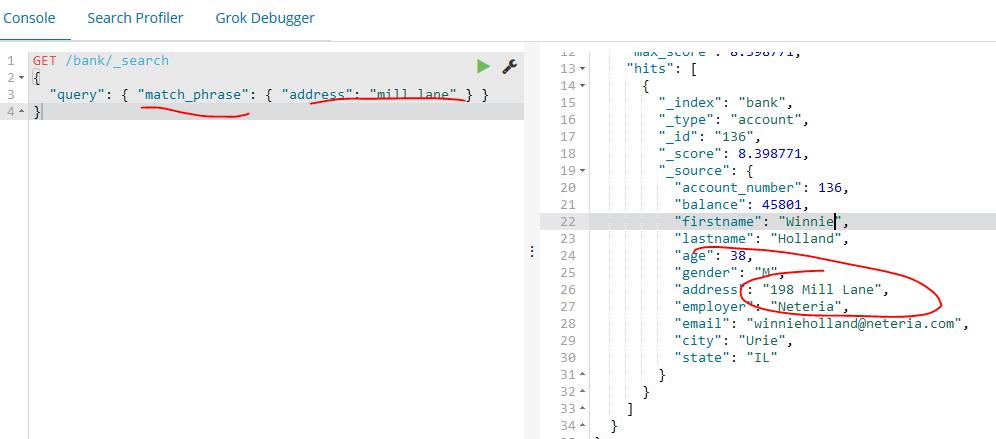
如下示例是match的一种变体(match_phrase),这个将返回所有address中包含“mill lane”这个短语(也就是都包含,且按照顺序)的账户文档:
bool 查询允许我们使用布尔逻辑将小的查询组成大的查询。如下的示例组合两个match查询并且返回所有address属性中包含 “mill” 和 “lane” 的账户文档,bool must 子句指定了所有匹配文档必须满足的条件。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "address": "mill" } },
{ "match": { "address": "lane" } }
]
}
}
}
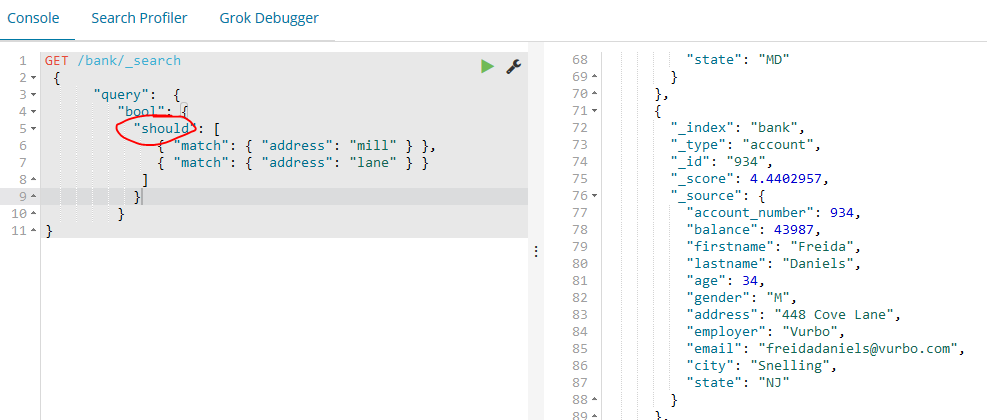
相比之下,如下的示例组合两个match查询并且返回所有address属性中包含 “mill” 或 “lane” 的账户文档,需要用到should关键字。
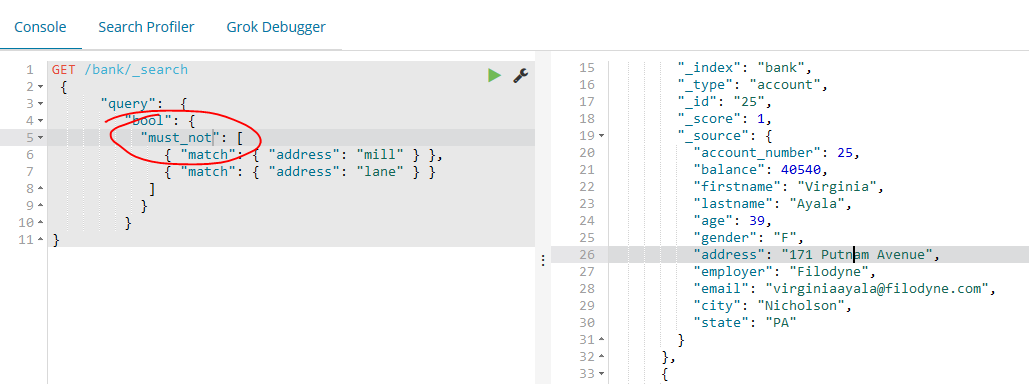
如下示例组合两个match查询并且返回所有address属性中既不包含 “mill” 也不包含 “lane” 的账户文档:
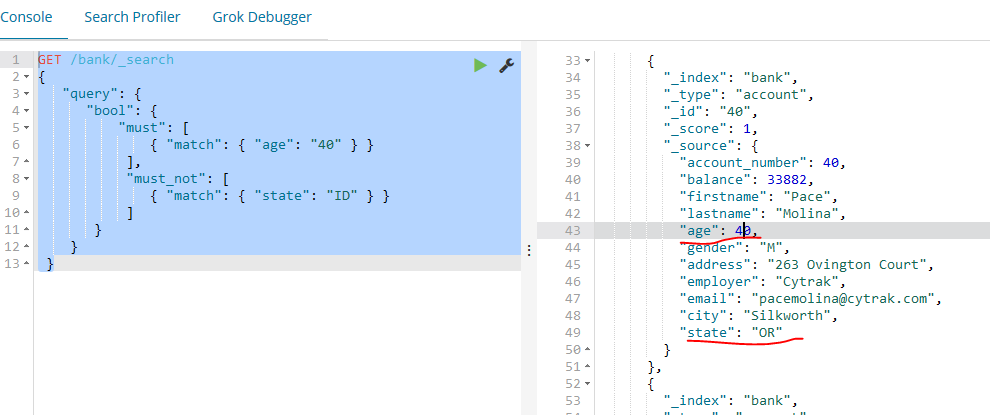
如下的示例返回所有age属性为40,并且state属性不为ID的账户文档:
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "age": "" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
7.3、执行过滤
_score属性是一个数值,它是一个相对量,用来衡量搜索结果跟我们指定的关键字的相关程度。分数越高,说明这个文档的相关性越大,分数越低,说明这个文档的相关性越小。但是一些查询结果并不总是需要产生得分,尤其是当他们仅仅被用来过滤文档集的时候。Elasticsearch会检测这种情况并自动优化查询以免计算无用的分数。
bool 查询也支持 filter 子句,它允许我们可以在不改变得分计算逻辑的的情况下限制其他子句匹配的查询结果。range 查询允许我们通过一个值区间来过滤文档。这个通常用在数值和日期过滤上。
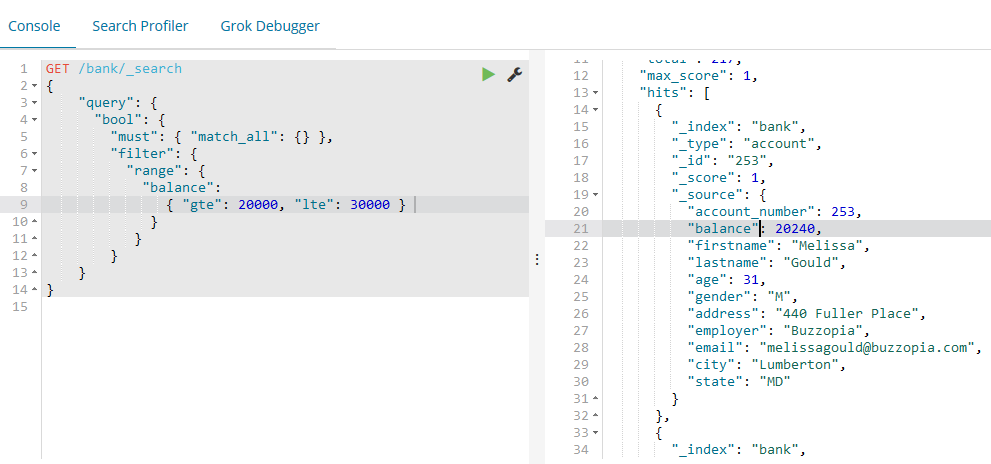
如下的示例使用bool查询返回所有余额在20000到30000之间的账户(包含边界)。
GET /bank/_search
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance":
{ "gte": , "lte": }
}
}
}
}
}
7.4、执行聚合
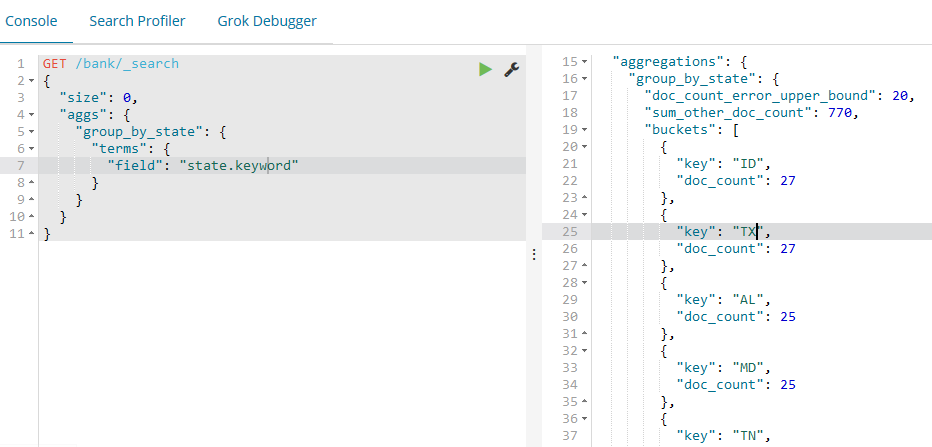
聚合提供了功能可以分组并统计数据。理解聚合最简单的方式就是可以把它粗略的看做SQL的GROUP BY操作和SQL的聚合函数。在Elasticsearch中,可以在执行搜索后在一个返回结果中同时返回搜索结果和聚合结果。可以使用简洁的API执行搜索和多个聚合操作,并且可以一次拿到所有的结果,避免网络切换,就此而言,这是一个非常强大和高效功能。注意我们设置了size=0来不显示hits搜索结果,因为我们这里只关心聚合结果。
GET /bank/_search
{
"size": ,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": ,
"hits": []
},
"aggregations": {
"group_by_state": {
"doc_count_error_upper_bound": ,
"sum_other_doc_count": ,
"buckets": [
{
"key": "ID",
"doc_count":
},
{
"key": "TX",
"doc_count":
},
{
"key": "AL",
"doc_count":
},
{
"key": "MD",
"doc_count":
},
{
"key": "TN",
"doc_count":
},
{
"key": "MA",
"doc_count":
},
{
"key": "NC",
"doc_count":
},
{
"key": "ND",
"doc_count":
},
{
"key": "ME",
"doc_count":
},
{
"key": "MO",
"doc_count":
}
]
}
}
}
类似于:SELECT state, COUNT(*) FROM bank GROUP BY state ORDER BY COUNT(*) DESC
如下示例我们在上一个聚合的基础上构建,这个示例计算每个state分组的平均账户余额(还是使用默认按count倒序返回前10个):
GET /bank/_search
{
"size": ,
"aggs": {
"group_by_state": {
"terms": {"field": "state.keyword" },
"aggs": {
"average_balance": {
"avg": { "field": "balance" }
}
}
}
}
}
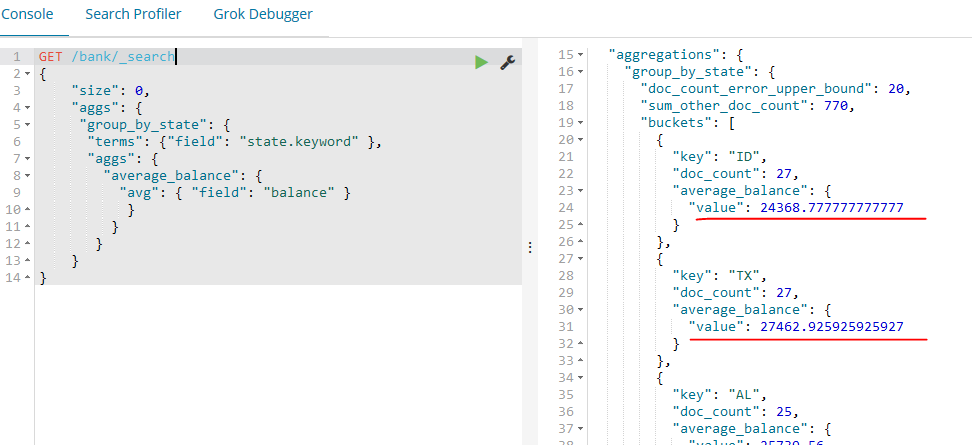
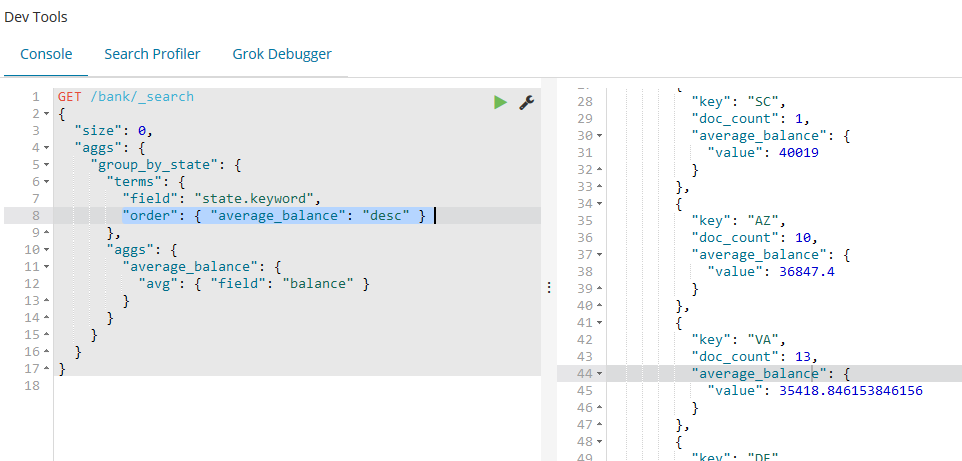
如下例子依然是在之前的聚合上构建,我们现在来按平均余额倒序排列:
GET /bank/_search
{
"size": ,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": { "average_balance": "desc" }
},
"aggs": {
"average_balance": {
"avg": { "field": "balance" }
}
}
}
}
}
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": ,
"hits": []
},
"aggregations": {
"group_by_state": {
"doc_count_error_upper_bound": -,
"sum_other_doc_count": ,
"buckets": [
{
"key": "AL",
"doc_count": ,
"average_balance": {
"value": 41418.166666666664
}
},
{
"key": "SC",
"doc_count": ,
"average_balance": {
"value":
}
},
{
"key": "AZ",
"doc_count": ,
"average_balance": {
"value": 36847.4
}
},
{
"key": "VA",
"doc_count": ,
"average_balance": {
"value": 35418.846153846156
}
},
{
"key": "DE",
"doc_count": ,
"average_balance": {
"value": 35135.375
}
},
{
"key": "WA",
"doc_count": ,
"average_balance": {
"value": 34787.142857142855
}
},
{
"key": "ME",
"doc_count": ,
"average_balance": {
"value": 34539.666666666664
}
},
{
"key": "OK",
"doc_count": ,
"average_balance": {
"value": 34529.77777777778
}
},
{
"key": "CO",
"doc_count": ,
"average_balance": {
"value": 33379.769230769234
}
},
{
"key": "MI",
"doc_count": ,
"average_balance": {
"value": 32905.916666666664
}
}
]
}
}
}
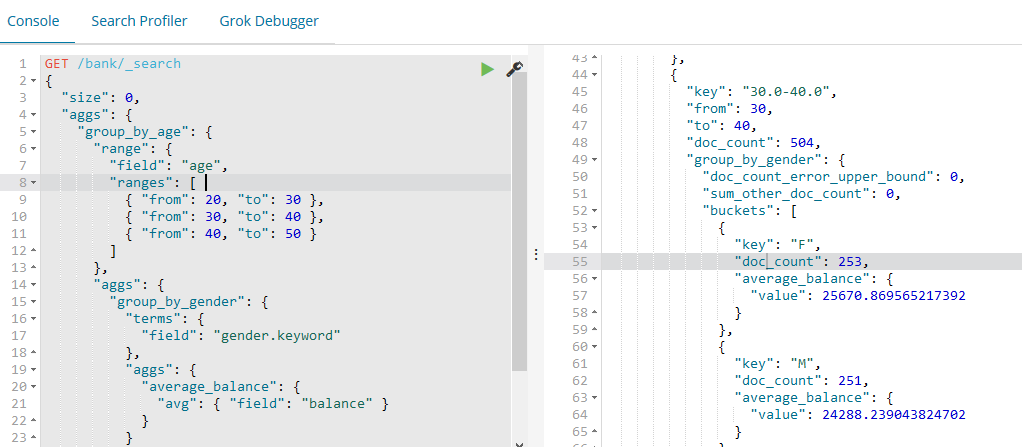
如下示例演示我们如何按年龄区间分组(20-29,30-39,40-49),然后按性别,最后获取每个年龄区间,每个性别的平均账户余额:
GET /bank/_search
{
"size": ,
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{ "from": , "to": },
{ "from": , "to": },
{ "from": , "to": }
]
},
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"average_balance": {
"avg": { "field": "balance" }
}
}
}
}
}
}
}
{
"took": ,
"timed_out": false,
"_shards": {
"total": ,
"successful": ,
"skipped": ,
"failed":
},
"hits": {
"total": ,
"max_score": ,
"hits": []
},
"aggregations": {
"group_by_age": {
"buckets": [
{
"key": "20.0-30.0",
"from": ,
"to": ,
"doc_count": ,
"group_by_gender": {
"doc_count_error_upper_bound": ,
"sum_other_doc_count": ,
"buckets": [
{
"key": "M",
"doc_count": ,
"average_balance": {
"value": 27374.05172413793
}
},
{
"key": "F",
"doc_count": ,
"average_balance": {
"value": 25341.260273972603
}
}
]
}
},
{
"key": "30.0-40.0",
"from": ,
"to": ,
"doc_count": ,
"group_by_gender": {
"doc_count_error_upper_bound": ,
"sum_other_doc_count": ,
"buckets": [
{
"key": "F",
"doc_count": ,
"average_balance": {
"value": 25670.869565217392
}
},
{
"key": "M",
"doc_count": ,
"average_balance": {
"value": 24288.239043824702
}
}
]
}
},
{
"key": "40.0-50.0",
"from": ,
"to": ,
"doc_count": ,
"group_by_gender": {
"doc_count_error_upper_bound": ,
"sum_other_doc_count": ,
"buckets": [
{
"key": "M",
"doc_count": ,
"average_balance": {
"value": 26474.958333333332
}
},
{
"key": "F",
"doc_count": ,
"average_balance": {
"value": 27992.571428571428
}
}
]
}
}
]
}
}
}
八、总结
在实例中,我们安装了elk这三种工具,其实最核心的就是Elasticsearch,Elasticsearch是一个既简单又复杂的产品。我们到目前为止已经学习了基础的知识,知道了它是什么,它内部的实现原理,以及如何使用REST API去操作它。logstash是为了提供原素材,es处理之后进行存储和显示,而kibana是为了界面的显示,便于我们操作,用了这三样东西,我们对日志的处理和分析等工作就有了更好地了解和认知。
参考文献:https://blog.csdn.net/hololens/article/details/78932628
沉淀再出发:ELK使用初探的更多相关文章
- 沉淀再出发:kafka初探
沉淀再出发:kafka初探 一.前言 从我们接触大数据开始,可能绕在耳边的词汇里面出现的次数越来越多的就包括kfaka了.kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息, ...
- 沉淀再出发:dubbo的基本原理和应用实例
沉淀再出发:dubbo的基本原理和应用实例 一.前言 阿里开发的dubbo作为服务治理的工具,在分布式开发中有着重要的意义,这里我们主要专注于dubbo的架构,基本原理以及在Windows下面开发出来 ...
- 沉淀再出发:OpenStack初探
沉淀再出发:OpenStack初探 一.前言 OpenStack是IaaS的一种平台,通过各种虚拟化来提供服务.我们主要看一下OpenStack的基本概念和相应的使用方式. 二.OpenStack的框 ...
- 沉淀,再出发:AngularJS初探
沉淀,再出发:AngularJS初探 一.前言 知识的学习需要形成一个闭环,在这个闭环之内可以自圆其说,从而触类旁通,加以理想创造,从而产生灵感.关于前端的知识,我已经写得差不多了,但是还有一个知识点 ...
- 沉淀再出发:jvm的本质
沉淀再出发:jvm的本质 一.前言 关于jvm,使用的地方实在是太多了,从字面意思上我们都能明白这也是一个虚拟机,那么其他的虚拟机都会用来运行别的操作系统的,而jvm却是实现了可以在不用的操作系统之上 ...
- 沉淀再出发:再谈java的多线程机制
沉淀再出发:再谈java的多线程机制 一.前言 自从我们学习了操作系统之后,对于其中的线程和进程就有了非常深刻的理解,但是,我们可能在C,C++语言之中尝试过这些机制,并且做过相应的实验,但是对于ja ...
- 沉淀再出发:用python画各种图表
沉淀再出发:用python画各种图表 一.前言 最近需要用python来做一些统计和画图,因此做一些笔记. 二.python画各种图表 2.1.使用turtle来画图 import turtle as ...
- 沉淀再出发:在python3中导入自定义的包
沉淀再出发:在python3中导入自定义的包 一.前言 在python中如果要使用自己的定义的包,还是有一些需要注意的事项的,这里简单记录一下. 二.在python3中导入自定义的包 2.1.什么是模 ...
- 沉淀再出发:java中的equals()辨析
沉淀再出发:java中的equals()辨析 一.前言 关于java中的equals,我们可能非常奇怪,在Object中定义了这个函数,其他的很多类中都重载了它,导致了我们对于辨析其中的内涵有了混淆, ...
随机推荐
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
- ListView和BaseAdapter
参考资料:http://www.runoob.com/w3cnote/android-tutorial-listview.html <LinearLayout xmlns:android=&qu ...
- MySQL中使用SHOW PROFILE命令分析性能的用法整理(配合explain效果更好,可以作为优化周期性检查)
这篇文章主要介绍了MySQL中使用show profile命令分析性能的用法整理,show profiles是数据库性能优化的常用命令,需要的朋友可以参考下 show profile是由Jerem ...
- DateReader读取数据
DateReader对象提供了用循序的.只读的方式读取Command对象获取的数据结果集正是因为DateReader是以循序的方法连续地读取数据,所以DateReader会以独占的方式打开数据库连接. ...
- Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构
Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构 之前我们简要的看过了DataNode的main函数以及整个类的大至,现在结合前面我们研究的线程和RPC,则可以进一步 ...
- [javaSE] 网络编程(TCP-并发上传图片)
客户端: 1.服务端点 2.读取客户端已有的图片数据 3.通过socket输出流将数据发给服务端 4.读取服务端反馈信息 5.关闭 获取Socket对象,new出来,构造参数:String的服务端ip ...
- [javaSE] IO流(RandomAccessFile)
随机访问文件,可以看作一个大型的byte[]数组,不算是IO体系中的一员,内部封装了字节输入输出流,可以设置权限,可以调整指针的位置 获取RandomAccessFile对象,构造参数:String文 ...
- 怎样求逆序对数(Inverse Number)?
#返回上一级 @Author: 张海拔 @Update: 2014-01-14 @Link: http://www.cnblogs.com/zhanghaiba/p/3520089.html /* * ...
- Java开发相关官方存档下载地址
前言 集中收藏Java开发中需要用到的常用下载地址 jdk Java SE 最新下载 | Oracle 技术网 : http://www.oracle.com/technetwork/cn/java/ ...
- 撩课-Web大前端每天5道面试题-Day9
1. 请用至少3中方式实现数组去重? 方法一: indexOf ,,,,,,,,]; function repeat1(arr){ ,arr2=[];i<arr.length;i++){ ){ ...