激活函数--(Sigmoid,tanh,Relu,maxout)
Question?
激活函数是什么?
激活函数有什么用?
激活函数怎么用?
激活函数有哪几种?各自特点及其使用场景?
1.激活函数
1.1激活函数是什么?
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。 那么激活函数应该具有什么样的性质呢?
可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate
1.2激活函数有什么用?
引入非线性因素。
在我们面对线性可分的数据集的时候,简单的用线性分类器即可解决分类问题。但是现实生活中的数据往往不是线性可分的,面对这样的数据,一般有两个方法:引入非线性函数、线性变换。
线性变换
就是把当前特征空间通过一定的线性映射转换到另一个空间,让数据能够更好的被分类。
激活函数
激活函数是如何引入非线性因素的呢?在神经网络中,为了避免单纯的线性组合,我们在每一层的输出后面都添加一个激活函数(sigmoid、tanh、ReLu等等),这样的函数长这样:
1.3激活函数有哪几种?各自特点及其使用场景?
2.Sigmoid
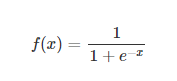
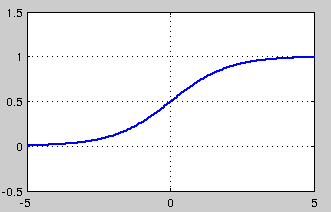
sigmoid 是使用范围最广的一类激活函数,具有指数函数形状,它在物理意义上最为接近生物神经元。此外,(0, 1) 的输出还可以被表示作概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数。
可以看出,sigmoid函数连续,光滑,严格单调,以(0,0.5)中心对称,是一个非常良好的阈值函数。
当x趋近负无穷时,y趋近于0;趋近于正无穷时,y趋近于1;x=0时,y=0.5。当然,在x超出[-6,6]的范围后,函数值基本上没有变化,值非常接近,在应用中一般不考虑。
Sigmoid函数的值域范围限制在(0,1)之间,我们知道[0,1]与概率值的范围是相对应的,这样sigmoid函数就能与一个概率分布联系起来了。
Sigmoid函数的导数是其本身的函数,即f′(x)=f(x)(1−f(x))f′(x)=f(x)(1−f(x)),计算非常方便,也非常节省计算时间。
然而,sigmoid也有其自身的缺陷,最明显的就是饱和性。从上图可以看到,其两侧导数逐渐趋近于0
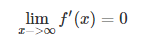
具有这种性质的称为软饱和激活函数。具体的,饱和又可分为左饱和与右饱和。与软饱和对应的是硬饱和, 即
sigmoid 的软饱和性,使得深度神经网络在二三十年里一直难以有效的训练,是阻碍神经网络发展的重要原因。具体来说,由于在后向传递过程中,sigmoid向下传导的梯度包含了一个 f′(x)f′(x) 因子(sigmoid关于输入的导数),因此一旦输入落入饱和区,f′(x)f′(x) 就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象
此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
3.tanh
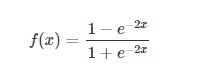
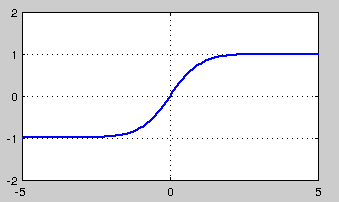
tanh也是一种非常常见的激活函数。与sigmoid相比,它的输出均值是0,使得其收敛速度要比sigmoid快,减少迭代次数。然而,从途中可以看出,tanh一样具有软饱和性,从而造成梯度消失。
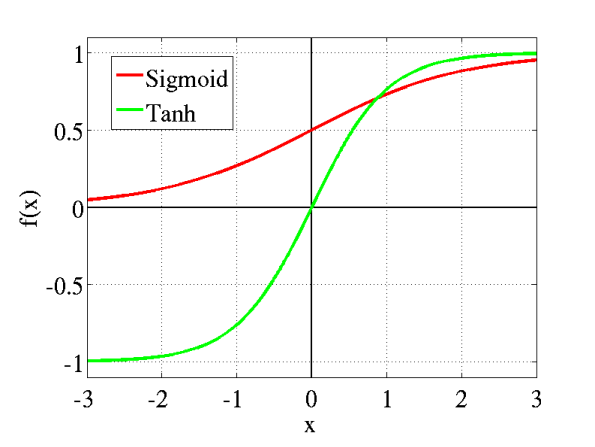
此图为sigmoid和tanh合图。
4.ReLU,P-ReLU, Leaky-ReLU
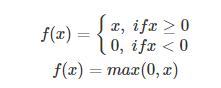
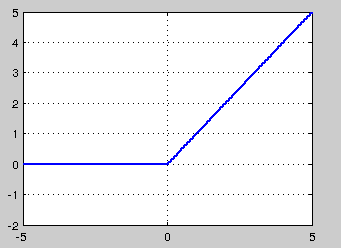
ReLU的全称是Rectified Linear Units,是一种后来才出现的激活函数。 可以看到,当x<0时,ReLU硬饱和,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。这让我们能够直接以监督的方式训练深度神经网络,而无需依赖无监督的逐层预训练。
然而,随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。与sigmoid类似,ReLU的输出均值也大于0,偏移现象和 神经元死亡会共同影响网络的收敛性。
针对在x<0的硬饱和问题,我们对ReLU做出相应的改进,使得
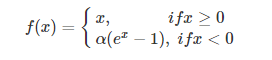
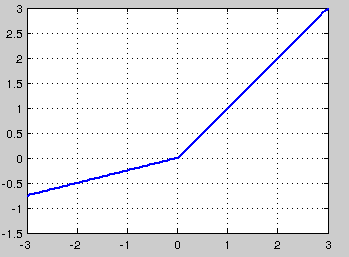
这就是Leaky-ReLU, 而P-ReLU认为,αα也可以作为一个参数来学习,原文献建议初始化a为0.25,不采用正则。
5.ELU
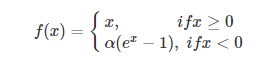
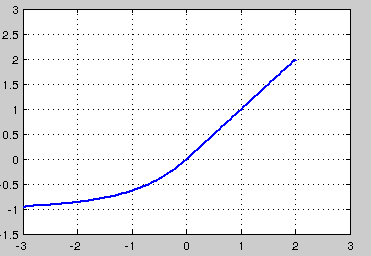
融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。在 ImageNet上,不加 Batch Normalization 30 层以上的 ReLU 网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU 网络在Fan-in/Fan-out下都能收敛
6. Maxout
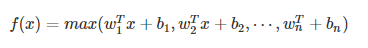
Maxout模型实际上也是一种新型的激活函数,在前馈式神经网络中,Maxout的输出即取该层的最大值,在卷积神经网络中,一个Maxout feature map可以是由多个feature map取最值得到。
maxout的拟合能力是非常强的,它可以拟合任意的的凸函数。但是它同dropout一样需要人为设定一个k值。
为了便于理解,假设有一个在第i层有2个节点第(i+1)层有1个节点构成的神经网络。 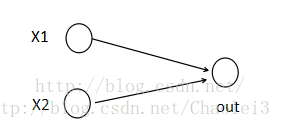
激活值 out = f(W.X+b); f是激活函数。’.’在这里代表內积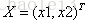
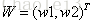
那么当我们对(i+1)层使用maxout(设定k=5)然后再输出的时候,情况就发生了改变。 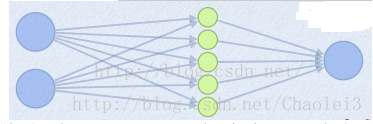
此时网络形式上就变成上面的样子,用公式表现出来就是:
z1 = W1.X+b1;
z2 = W2.X+b2;
z3 = W3.X+b3;
z4 = W4.X+b4;
z5 = W4.X+b5;
out = max(z1,z2,z3,z4,z5);
也就是说第(i+1)层的激活值计算了5次,可我们明明只需要1个激活值,那么我们该怎么办?其实上面的叙述中已经给出了答案,取这5者的最大值来作为最终的结果。
总结一下,maxout明显增加了网络的计算量,使得应用maxout的层的参数个数成k倍增加,原本只需要1组就可以,采用maxout之后就需要k倍了。
再叙述一个稍微复杂点的应用maxout的网络,网络图如下: 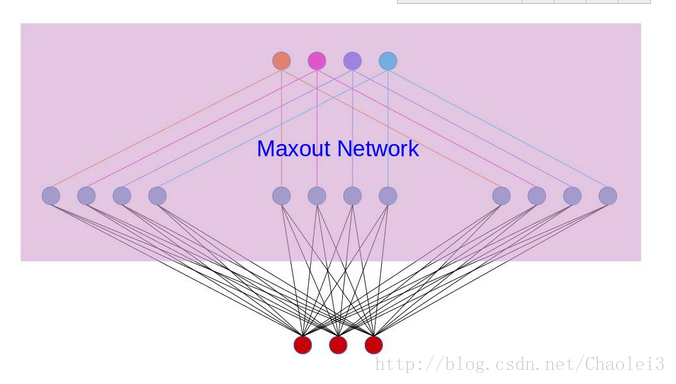
对上图做个说明,第i层有3个节点,红点表示,而第(i+1)层有4个结点,用彩色点表示,此时在第(i+1)层采用maxout(k=3)。我们看到第(i+1)层的每个节点的激活值都有3个值,3次计算的最大值才是对应点的最终激活值。我举这个例子主要是为了说明,决定结点的激活值的时候并不是以层为单位,仍然以节点为单位。
激活函数--(Sigmoid,tanh,Relu,maxout)的更多相关文章
- 深度学习原理与框架-神经网络架构 1.神经网络构架 2.激活函数(sigmoid和relu) 3.图片预处理(减去均值和除标准差) 4.dropout(防止过拟合操作)
神经网络构架:主要时表示神经网络的组成,即中间隐藏层的结构 对图片进行说明:我们可以看出图中的层数分布: input layer表示输入层,维度(N_num, input_dim) N_num表示输 ...
- 激活函数Sigmoid、Tanh、ReLu、softplus、softmax
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/9276412.html 激活函数: 就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端. 常见 ...
- 神经网络激活函数sigmoid relu tanh 为什么sigmoid 容易梯度消失
https://blog.csdn.net/danyhgc/article/details/73850546 什么是激活函数 为什么要用 都有什么 sigmoid ,ReLU, softmax 的比较 ...
- 激活函数sigmoid、tanh、relu、Swish
激活函数的作用主要是引入非线性因素,解决线性模型表达能力不足的缺陷 sigmoid函数可以从图像中看出,当x向两端走的时候,y值越来越接近1和-1,这种现象称为饱和,饱和意味着当x=100和x=100 ...
- 激活函数——sigmoid函数(理解)
0 - 定义 $Sigmoid$函数是一个在生物学中常见的S型函数,也称为$S$型生长曲线.在信息科学中,由于其单增以及反函数单增等性质,$Sigmoid$函数常被用作神经网络的阈值函数,将变量映射到 ...
- TensorFlow(2)Softmax Regression
Softmax Regression Chapter Basics generate random Tensors Three usual activation function in Neural ...
- 激活函数:Sigmod&tanh&Softplus&Relu详解
什么是激活函数? 激活函数(Activation functions)对于人工神经网络模型去学习.理解非常复杂和非线性的函数来说具有十分重要的作用. 它们将非线性特性引入到我们的网络中.其主要目的是将 ...
- 激活函数,Batch Normalization和Dropout
神经网络中还有一些激活函数,池化函数,正则化和归一化函数等.需要详细看看,啃一啃吧.. 1. 激活函数 1.1 激活函数作用 在生物的神经传导中,神经元接受多个神经的输入电位,当电位超过一定值时,该神 ...
- Pytorch1.0深度学习:损失函数、优化器、常见激活函数、批归一化详解
不用相当的独立功夫,不论在哪个严重的问题上都不能找出真理:谁怕用功夫,谁就无法找到真理. —— 列宁 本文主要介绍损失函数.优化器.反向传播.链式求导法则.激活函数.批归一化. 1 经典损失函数 1. ...
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
随机推荐
- MUI 样式按钮的禁用
1)如果是button,input等标签,可以 .attr("disabled",true)或者.attr("disabled","disab ...
- shell 备份代码
#!/bin/sh # 备份代码 basedir=/data/backup www_src=$basedir/$(date +%F_$H) [ ! -d "$www_src" ] ...
- 1024. Palindromic Number (25)
A number that will be the same when it is written forwards or backwards is known as a Palindromic Nu ...
- 51job_selenium测试2
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- nginx-1.12.1编译参数详情
一下nginx-1.12.1编译参数详情 #/usr/local/nginx/sbin/nginx -V nginx version: nginx/1.12.1 built by gcc 4.4.7 ...
- Dubbo协议
参考dubbo官方文档http://dubbo.apache.org/zh-cn/docs/user/references/protocol/dubbo.html dubbo共支持如下几种通信协议: ...
- 向GitHub上上传代码(转)
使用git将项目上传到github(最简单方法) 首先你需要一个github账号,所有还没有的话先去注册吧! https://github.com/ 我们使用git需要先安装git工具,这里给出下 ...
- WINFROM窗体实现圆角
首先我们先看看效果图 接下来我们看看怎么实现 先把窗体的FromBorderStyle属性改成None. 接下来登录窗体代码代码: 添加一个窗体Paint事件,引用using System.Drawi ...
- QDialog对话框
QDialog对话框,用来实现那些只是暂时存在的用户界面,是独立的窗口,但通常也有父窗口对话框有模态和非模态两种,,非模态对话框的行为和使用方法都类似于普通的窗口,模态对话框则有所不同,当模态对话框显 ...
- springboot使用elasticsearch报No property index found for type错误
一.前提:项目之前使用springboot+spring-data-mongodb.现在需要加入elasticsearch做搜索引擎,这样mongo和elasticsearch共存了. 二.报错信息: ...