论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes
一句话概括本文工作
使用词汇资源——知网——来提升词嵌入的表征能力,并提出了三种基于知网资源的词嵌入学习模型,在通用的中文词嵌入评测数据集上进行了评测,取得了较好的结果。
作者简介
该论文选自 ACL 2017,是清华大学孙茂松刘知远老师组的成果。论文的两名共同第一作者分别是牛艺霖和谢若冰。
牛艺霖,清华本科生。
谢若冰,清华研究生(2014-2017),清华本科生(2010-2014),发表过多篇机器学习领域高质量论文。[1]
论文立意
在表征学习领域,词嵌入(word embedding)问题是一个研究热点。其中,中文领域的词嵌入技术更是得到了很多深入地研究:从把词拆成字(CWE算法)[2],到把汉字拆偏旁部首 [3,4],再到根据人工总结的字件[5],再到基于汉字图片使用卷积神经网络自动提取特征的GWE [6],最后到2018年阿里巴巴提出的基于汉字笔画的词嵌入学习方法[7],中文词嵌入技术在形态学可谓已经被研究到了极致。
本文另辟蹊径,从词汇资源(Lexical Resource)——知网——入手,从词语背后的庞大信息量着手来提升词嵌入的表示能力。
词嵌入的研究方法综述
香港的 NLP 研究者刘李嫣然总结出了词嵌入的四大研究方向,分别是:Interpretable Relations、beyond words、lexical resource、beyond English [8]。
2018年,宋彦师兄创造性地提出了基于强化学习的词嵌入学习方法[9],至此,词嵌入的研究领域新增了一个新的研究方向——new model。也即引入其他学习方法的word embedding思路。
从2015年各大顶会论文的趋势来看,对于 word embedding 的研究已经进入基本完备,也就是进入了所谓的“后 word embedding 时代”[8]。关于word embedding的研究是这样的历史进程: 1954年,Harris 提出“语义相似的单词往往会出现在相似的上下文中 "[13]。2003年,Bengio 提出 神经网络语言模型[14]。2013年,google的Mikolov 提出 word2vec[15,16]。2015年,word embedding领域集大成之作的论文[17]横空出世,标志着后word embedding时代的到来。
本文贡献
首次利用知网中的义原来提高词向量的表征能力;采用注意力机制,从上下文中来寻找词义和学习表示。
本文工作
立意
词义由义原构成,本文改进了google 提出的 word2vec模型,加入注意力机制,从而可以很好的利用词义资源,以此来提高词向量的表征能力。
基线系统
google 提出的 word2vec 中的两种模型:Skip-Gram(SG) 和 CBOW。
斯坦福提出的 GloVe
训练数据集
Sougou-T,搜狗公司提出的互联网语料库,内含1.3亿张网页,相当于27亿个词汇,相当于 5TB 数据量。[10]
测试数据集
清华大学之前提出的词语相似度测试集 WordSim-240, WordSim-297, Analogy [11,12]
评测任务
词语相似度和词汇类推
模型方法
Simple Sememes Aggregation Model
仅利用了词对应的全部义原的平均值。
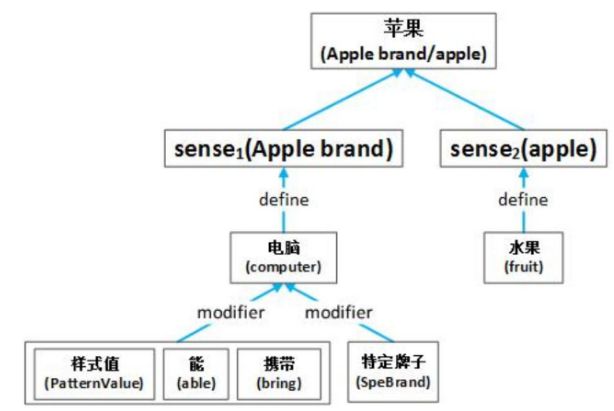
w 代表“词”;
S 代表词对应的词义集合;
X 代表词义对应的义原集合
m 代表全部义原的数量
\[
w = \frac{1}{m} \sum_{S} \sum_{X}x
\]
Sememe Attention over Context Model
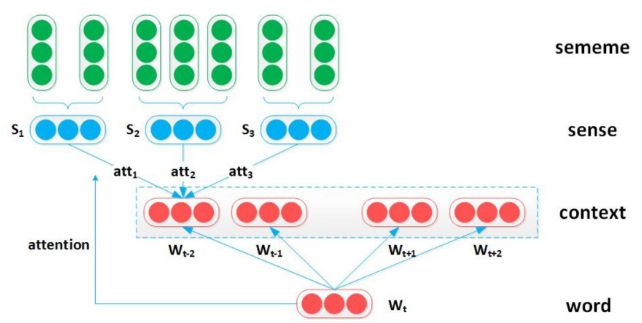
利用注意力机制,根据目标词选择上下文词的适当意义。
\[
w_c = \sum_{j=1}^{|S|} att(S_j) \cdot S_j
\]
\[
att(S_j) = \frac{\exp(w \cdot \hat S_j)}{\sum_{k=1}^{|S|} \exp(w\cdot \hat S_k)}
\]
\[
\hat S^{(w_c)} = \frac{1}{|X_j^{(w_c)}|} \sum_{k=1}^{|X_j^{(w_c)}|} X_k
\]
Sememes Attention over Target Model
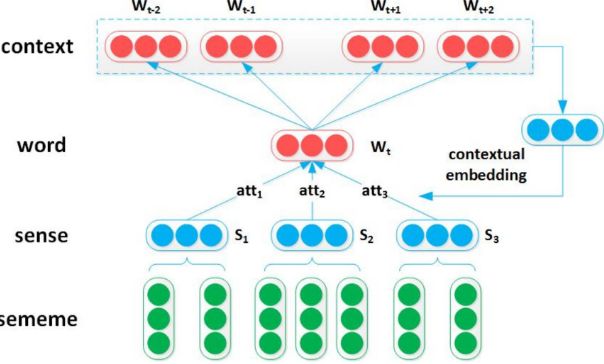
以上下文词为关注焦点,选择目标词的词义。
\[
w = \sum_{j=1}^{|S^{}|} att(S_j) \cdot S_j
\]
\[
att(S_j) = \frac{\exp{(w_c{'} \cdot \hat S_j)}}{\sum_{k=1}^{|S|}\exp(w_c{'} \cdot \hat S_k)}
\]
\[
w_c{'} = \frac{1}{2K{'}}\sum_{k=i-K{'}}^{k = i + K{'}} w_k, \quad k \neq i
\]
本文的不足
- 过于主观的评价方法,本文不同于其他的高水平词嵌入研究论文, 没有在较有说服力的机器翻译、文本分类上测试该词嵌入方法的性能。
- 不好懂的句式、语法和词汇,不同于李航和周志华的英文论文,本文的阅读难度较大。
参考文献
[1] Ruobing Xie`s Profile. http://nlp.csai.tsinghua.edu.cn/~xrb/
[2] Chen X, Xu L, Liu Z, et al. Joint learning of character and word embeddings[C]// International Conference on Artificial Intelligence. AAAI Press, 2015:1236-1242.
[3] Sun Y, Lin L, Yang N, et al. Radical-Enhanced Chinese Character Embedding[J]. Lecture Notes in Computer Science, 2014, 8835:279-286.
[4] Li Y, Li W, Sun F, et al. Component-Enhanced Chinese Character Embeddings[J]. Computer Science, 2015.
[5] Yu J, Jian X, Xin H, et al. Joint Embeddings of Chinese Words, Characters, and Fine-grained Subcharacter Components[C]// Conference on Empirical Methods in Natural Language Processing. 2017:286-291.
[6] Su T R, Lee H Y. Learning Chinese Word Representations From Glyphs Of Characters[C]// Conference on Empirical Methods in Natural Language Processing. 2017:264-273.
[7] cw2vec: Learning Chinese Word Embeddings with Stroke n-gram Information. 2018 AAAI
[8] 刘李嫣然. 后 Word Embedding 的热点会在哪里?. 2015. http://yanran.li/peppypapers/2015/08/17/post-word-embedding.html
[9] Yan Song. Learning Word Embedding with Reinforcement Learning. IJCAI. 2018
[10] http://www.sogou.com/labs/resource/t.php
[11] https://github.com/Leonard-Xu/CWE/tree/master/data
[12] Zhiyuan Liu, Maosong Sun, et al. Joint Learning of Character and Word Embeddings. IJCAI 2015.
[13] Harris, Zellig S. Distributional structure. Word 1954
[14] Bengio, Yoshua, et al. A neural probabilistic language model. JMLR 2003
[15] Mikolov, Tomas, et al. Efficient estimation of word representations in vector space[J]. Computer Science. 2013
[16] Mikolov, Tomas, et al. Distributed representations of words and phrases and their compositionality. NIPS 2013
[17] Lai S, et al. How to Generate a Good Word Embedding[J]. IEEE Intelligent Systems, 2016, 31(6): 5-14.
论文阅读笔记 Improved Word Representation Learning with Sememes的更多相关文章
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- 翻译 Improved Word Representation Learning with Sememes
翻译 Improved Word Representation Learning with Sememes 题目 Improved Word Representation Learning with ...
- [论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
- 论文阅读笔记二十三:Learning to Segment Instances in Videos with Spatial Propagation Network(CVPR2017)
论文源址:https://arxiv.org/abs/1709.04609 摘要 该文提出了基于深度学习的实例分割框架,主要分为三步,(1)训练一个基于ResNet-101的通用模型,用于分割图像中的 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
随机推荐
- js 的date的format时间,获取当前时间,前一天的日期
Date.prototype.Format = function (fmt) { //author: meizz var o = { "M+": this.getMonth() + ...
- leetcode473 Matchsticks to Square
一开始想求所有结果为target的组合来着,但是所选元素不能重叠.用这个递归思想很简单,分成四个桶,每次把元素放在任意一个桶里面,最后如果四个桶相等就可以放进去,有一个地方可以剪枝,假如任意一个桶的元 ...
- jmeter 发送加密请求 beanshell断言 线程组间传递参数
原文地址https://www.cnblogs.com/wnfindbug/p/5817038.html 最近在做http加密接口,请求头的uid参数及body的请求json参数都经过加密再发送请求, ...
- PyQT5速成教程-3 布局管理
本文由 沈庆阳 所有,转载请与作者取得联系! 布局(Layout)管理 Qt Designer中,在工具箱中最上方可以看到有4种布局.分别是垂直布局.水平布局.栅格布局和表单布局. 四种布局 布局 ...
- List<String> 2List <Long>
public static List<Integer> CollStringToIntegerLst(List<String> inList){ List<Integer ...
- java中的锁之AbstractQueuedSynchronizer源码分析(二)
一.成员变量. 1.目录. 2.state.该变量标记为volatile,说明该变量是对所有线程可见的.作用在于每个线程改变该值,都会马上让其他线程可见,在CAS(可见锁概念与锁优化)的时候是必不可少 ...
- springboot之session、cookie
1- 获取session的方案 session: https://blog.csdn.net/yiifaa/article/details/77542208 2- session什么时候创建? ...
- <script> 属性crossorigin
今日偶然见到如下代码: <script src="https://cdnjs.cloudflare.com/ajax/libs/popper.js/1.11.0/umd/popper. ...
- KVM_webvirtmgr
一.webvirtmgr安装前说明: 1:操作做系统:centos7.2_x86_64 2:安装参考出处1:https://github.com/retspen/webvirtmgr/wiki/Ins ...
- NSThread(II)
非线程安全 //初始化火车票数量.卖票窗口(非线程安全).并开始卖票 - (void)initTicketStatusNotSave { // 1. 设置剩余火车票为 50 self.ticketSu ...