理解HTTP之keep-alive
理解HTTP之keep-alive
在前面一篇文章中讲了TCP的keepalive,这篇文章再讲讲HTTP层面keep-alive。两种keepalive在拼写上面就是不一样的,只是发音一样,于是乎大家就都迷茫了。HTTP层面的keep-alive是我们接触比较多的,也是大家平时口头上的"keepalive"。下面我们就来谈谈HTTP的keep-alive
短连接&长连接&并行连接
再说keep-alive之前,先说说HTTP的短连接&长连接。
短连接
所谓短连接,就是每次请求一个资源就建立连接,请求完成后连接立马关闭。每次请求都经过“创建tcp连接->请求资源->响应资源->释放连接”这样的过程
长连接
所谓长连接(persistent connection),就是只建立一次连接,多次资源请求都复用该连接,完成后关闭。要请求一个页面上的十张图,只需要建立一次tcp连接,然后依次请求十张图,等待资源响应,释放连接。
并行连接
所谓并行连接(multiple connections),其实就是并发的短连接。
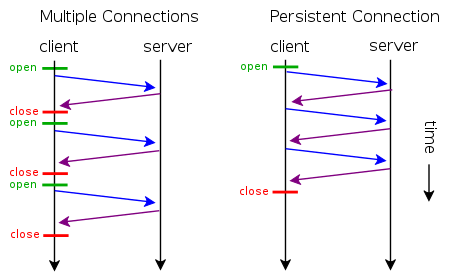
keep-alive
具体client和server要从短连接到长连接最简单演变需要做如下改进:
- client发出的HTTP请求头需要增加Connection:keep-alive字段
- Web-Server端要能识别Connection:keep-alive字段,并且在http的response里指定Connection:keep-alive字段,告诉client,我能提供keep-alive服务,并且"应允"client我暂时不会关闭socket连接
在HTTP/1.0里,为了实现client到web-server能支持长连接,必须在HTTP请求头里显示指定
Connection:keep-alive
在HTTP/1.1里,就默认是开启了keep-alive,要关闭keep-alive需要在HTTP请求头里显示指定
Connection:close
现在大多数浏览器都默认是使用HTTP/1.1,所以keep-alive都是默认打开的。一旦client和server达成协议,那么长连接就建立好了。
接下来client就给server发送http请求,继续上面的例子:请求十张图片。如果每次"请求->响应"都是独立的,那还好,10张图片的内容都是独立的。但是如果pipeline模式,上一个请求还没响应,下一个请求就发出,这样并发地发出10个请求,对于10个response client要怎么区分呢?而HTTP协议又是没有办法区分的,所以这种情况下必须要求server端地响应是顺序的,通过Conten-Length区分每次请求,这还只是针对静态资源,那对于动态资源无法预知页面大小的情况呢?我还没有深入研究,可以查看https://www.byvoid.com/blog/http-keep-alive-header
另外注意: 指定keep-alive是一种client和server端尽可能需要满足的约定,client和server可以在任意时刻都关闭keep-alive,彼此都不应该受影响。
Nginx keepa-alive配置
具体到Nginx的HTTP层的keepalive配置有
- keepalive_timeout
Syntax: keepalive_timeout timeout [header_timeout];
Default: keepalive_timeout 75s;
Context: http, server, location
The first parameter sets a timeout during which a keep-alive client connection will stay open on the server side. The zero value disables keep-alive client connections. The optional second parameter sets a value in the “Keep-Alive: timeout=time” response header field. Two parameters may differ.
- keepalive_requests
Syntax: keepalive_requests number;
Default: keepalive_requests 100;
Context: http, server, location
Sets the maximum number of requests that can be served through one keep-alive connection. After the maximum number of requests are made, the connection is closed.
可以看看Nginx的关于 keepalive_timeout 是实现
./src/http/ngx_http_request.c
static void
ngx_http_finalize_connection(ngx_http_request_t *r){
...
if (!ngx_terminate
&& !ngx_exiting
&& r->keepalive
&& clcf->keepalive_timeout > 0)
{
ngx_http_set_keepalive(r);
return;
}
...
}
static void
ngx_http_set_keepalive(ngx_http_request_t *r){
//如果发现是pipeline请求,判断条件是缓存区里有N和N+1个请求同时存在
if (b->pos < b->last) {
/* the pipelined request */
}
// 本次请求已经结束,开始释放request对象资源
r->keepalive = 0;
ngx_http_free_request(r, 0);
c->data = hc;
// 如果尝试读取keep-alive的socket返回值不对,可能是客户端close了。那么就关闭socket
if (ngx_handle_read_event(rev, 0) != NGX_OK) {
ngx_http_close_connection(c);
return;
}
//开始正式处理pipeline
...
rev->handler = ngx_http_keepalive_handler;
...
// 设置了一个定时器,触发时间是keepalive_timeout的设置
ngx_add_timer(rev, clcf->keepalive_timeout);
...
}
static void
ngx_http_keepalive_handler(ngx_event_t *rev){
// 发现超时则关闭socket
if (rev->timedout || c->close) {
ngx_http_close_connection(c);
return;
}
// 读取keep-alive设置从socket
n = c->recv(c, b->last, size);
if (n == NGX_AGAIN) {
if (ngx_handle_read_event(rev, 0) != NGX_OK) {
ngx_http_close_connection(c);
return;
}
...
}
//此处尚有疑惑?
ngx_reusable_connection(c, 0);
c->data = ngx_http_create_request(c);
// 删除定时器
ngx_del_timer(rev);
// 重新开始处理请求
rev->handler = ngx_http_process_request_line;
ngx_http_process_request_line(rev);
}
参考资料
from: http://www.firefoxbug.com/index.php/archives/2806/
理解HTTP之keep-alive的更多相关文章
- MapReduce剖析笔记之一:从WordCount理解MapReduce的几个阶段
WordCount是一个入门的MapReduce程序(从src\examples\org\apache\hadoop\examples粘贴过来的): package org.apache.hadoop ...
- Neutron 理解 (7): Neutron 是如何实现负载均衡器虚拟化的 [LBaaS V1 in Juno]
学习 Neutron 系列文章: (1)Neutron 所实现的虚拟化网络 (2)Neutron OpenvSwitch + VLAN 虚拟网络 (3)Neutron OpenvSwitch + GR ...
- 理解 OpenStack 高可用(HA)(3):Neutron 分布式虚拟路由(Neutron Distributed Virtual Routing)
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- MQTT V3.1--我的理解
最近因为工作需要,需要对推送消息了解,因此对MQTT进行了整理,这里更多的是对MQTT英文版的翻译和理解. MQTT(Message Queue Telemetry Transport),遥测传输协议 ...
- 19.fastDFS集群理解+搭建笔记
软件架构理解 1FastDFS介绍 1.1什么是FastDFS FastDFS是用c语言编写的一款开源的分布式文件系统.FastDFS为互联网量身定制,充分考虑了冗余备份.负载均衡.线性扩容等机制,并 ...
- 【Java】深入理解ThreadLocal
一.前言 要理解ThreadLocal,首先必须理解线程安全.线程可以看做是一个具有一定独立功能的处理过程,它是比进程更细度的单位.当程序以单线程运行的时候,我们不需要考虑线程安全.然而当一个进程中包 ...
- Linux下线程池的理解与简单实现
首先,线程池是什么?顾名思义,就是把一堆开辟好的线程放在一个池子里统一管理,就是一个线程池. 其次,为什么要用线程池,难道来一个请求给它申请一个线程,请求处理完了释放线程不行么?也行,但是如果创建线程 ...
- linux下socket keep alive讲解
[需求] 不影响服务器处理的前提下,检测客户端程序是否被强制终了.[现状]服务器端和客户端的Socket都设定了keepalive属性.服务器端设定了探测次数等参数,客户端.服务器只是打开了keepa ...
- Java WeakReference的理解与使用
转载:http://itindex.net/detail/47754-%E9%9D%A2%E8%AF%95-java-weakreference?utm_source=tuicool&utm_ ...
- 【转】Linux下socket keep alive讲解
[需求]不影响服务器处理的前提下,检测客户端程序是否被强制终了.[现状]服务器端和客户端的Socket都设定了keepalive属性.服务器端设定了探测次数等参数,客户端.服务器只是打开了keepal ...
随机推荐
- MVC,MVP设计模式
什么是MVP MVP是模型(Model).视图(View).主持人(Presenter)的缩写,分别代表项目中3个不同的模块. 模型(Model):负责处理数据的加载或者存储,比如从网络或本地数据库获 ...
- -webkit-line-clamp 限制多行文字
一.应用 CSS代码: .box { width: 100px; display: -webkit-box; -webkit-line-clamp: 2; -webkit-box-orient: ve ...
- window 连linux
https://blog.csdn.net/ruanjianruanjianruan/article/details/46954681 https://blog.csdn.net/u013754317 ...
- zoj3299 线段树区间更新,坐标建立线段树的方式
/* 平台和砖块的坐标离散化,边缘坐标转换成单位长度 处理下落信息,sum数组维护区间的砖块数量 把平台按高度从高到低排序,询问平台区间的砖块有多少,询问后将该区域砖块数置0 */ #include& ...
- for循环输出9~0
示例 for(var i = 9; i>-1;i--){ println(i) } function println(a) { document.write(a+"<br> ...
- 【C++ Primer 第10章】 10.4.2 插入迭代器
iostream迭代器 标准库为iostream定义了可用于这些IO类型对象的迭代器. istream_iterator读取输入流, ostream_iterator向一个输出流写数据. 1. i ...
- hdu 1240 3维迷宫 求起点到终点的步数 (BFS)
题意,给出一个N,这是这个三空间的大小,然后给出所有面的状况O为空地,X为墙,再给出起始点的三维坐标和终点的坐标,输出到达的步数 比较坑 z是x,x是y,y是z,Sample InputSTART 1 ...
- centos7 编译安装php 5.6
https://www.cnblogs.com/37yan/p/6879404.html
- asp.net core日志组件
日志介绍 Logging的使用 1. appsettings.json中Logging的介绍 Logging的配置信息是保存在appsettings.json配置文件中的.因为之前介绍配置文件的时候我 ...
- java面试题大全-基础方面 答案自己写
Java基础方面: 1.作用域public,private,protected,以及不写时的区别 2.Anonymous Inner Class (匿名内部类) 是否可以extends(继承)其它类, ...