python 写入CSV出现空白行问题及拓展
最近在学习python,要求让出表格。期间在不懂得情况下,写了些代码,运行后发现存在输入写入猴行之间存在空白行。猴发现原来问题在打开文件的方式不对。
现将我的学习交流经验分享如下:
1,自己的起初代码:
#coding=utf-8
import string
import csv resultlist = [{'合计':'合计','国有':110,'集体':112},
{'合计':'国有','国有':50,'集体':61},
{'合计':'合计','国有':50,'集体':40},
{'合计':'集体','国有':15,'集体':25}]
csvFile = open("d:/data/data/3.csv", "w")
# 文件头以列表的形式传入函数,列表的每个元素表示每一列的标识
fileheader = ['合计',"国有","集体"]
dict_writer = csv.DictWriter(csvFile, fileheader)
dict_writer.writeheader()
dict_writer.writerows(resultlist)
2,运行后结果显示:
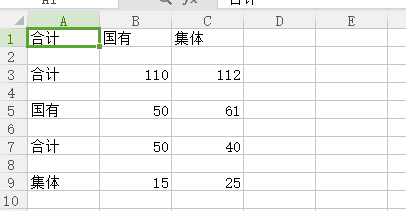
小伙伴们清楚看到,行之间存在数据空白行吧。
问题诊断:
这就是w 和 wb的区别,w是以文本方式打开文件,wb是二进制方式打开文件,以文本方式打开文件时,fwrite函数每碰到一个0x0A时,就在它的前面加入0x0D.其它内容不做添加操作。
拓展演示:
r+ 以可读写方式打开文件,该文件必须存在。
rb+ 读写打开一个二进制文件,只允许读写数据。
rt+ 读写打开一个文本文件,允许读和写。
w 打开只写文件,若文件存在则文件长度清为0,即该文件内容会消失。若文件不存在则建立该文件。
w+ 打开可读写文件,若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件
a 以附加的方式打开只写文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾,即文件原先内容会被保留。(EOF符保留)
a+ 以附加方式打开可读写的文件。若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾后,即文件原先的内容会被保留。
wb 只写打开或新建一个二进制文件;只允许写数据。
wb+ 读写打开或建立一个二进制文件,允许读和写。
wt+ 读写打开或着建立一个文本文件;允许读写。
at+ 读写打开一个文本文件,允许读或在文本末追加数据。
ab+ 读写打开一个二进制文件,允许读或在文件末追加数据。
修改后:

静以修身,俭以养德 --文正公训言
python 写入CSV出现空白行问题及拓展的更多相关文章
- 利用Python写入CSV文件的方法
第一种:CSV写入中文 #! /usr/bin/env python # _*_ coding:utf- _*_ import csv csvfile = file('test.csv', 'wb') ...
- Python写入CSV文件的问题
这篇文章主要是前几天我处理数据时遇到的三个问题: Python写入的csv的问题 Python2与Python3处理写入写入空行不同的处理方式 Python与Python3的编码问题 其实上面第3个问 ...
- python写入csv文件时的乱码问题
今天在使用python的csv库将数据写入csv文件时候,出现了中文乱码问题,解决方法是在写入文件前,先指定utf-8编码,如下: import csv import codecs if __name ...
- python写入csv文件的几种方法总结
生成test.csv文件 #coding=utf- import pandas as pd #任意的多组列表 a = [,,] b = [,,] #字典中的key值即为csv中列名 dataframe ...
- python写入csv
import xlwtimport csvnewfile=open("wu.csv","w",newline="")filewriter=c ...
- python写入csv方法总结
最常用的一种方法,利用pandas包 import pandas as pd #任意的多组列表 a = [1,2,3] b = [4,5,6] #字典中的key值即为csv中列名 dataframe ...
- python 写入csv文件
import csv fieldnames = ['Column1', 'Column2', 'Column3', 'Column4'] rows = [{'Column1': '0', 'Col ...
- Python写入csv文件示例
import csv header = ['City', 'AQI', 'PM2.5/1h', 'PM10/1h', 'CO/1h', 'NO2/1h', 'O3/1h', 'O3/8h', 'SO2 ...
- Python数据写入csv格式文件
(只是传递,基础知识也是根基) Python读取数据,并存入Excel打开的CSV格式文件内! 这里需要用到bs4,csv,codecs,os模块. 废话不多说,直接写代码!该重要的内容都已经注释了, ...
随机推荐
- MySql之游标的使用
一:游标的使用场合 游标只能用于存储过程和函数中. 游标存储了检索语句的结果集,然后在存储过程和函数中可以通过游标来迭代访问结果集中的记录. 二:创建游标 CREATE PROCEDURE 存储过程名 ...
- zabbix 客户端安装配置
1.下载zabbix wget http://netix.dl.sourceforge.net/project/zabbix/ZABBIX%20Latest%20Stable/2.4.7/zabb ...
- 微信公众号基础02_获取accessToken和用户信息
上一篇分享了搭建微信公众号server,本文分享一下假设获取access_Token和用户信息.工具还是新浪云SAE 1.获取access_Token 相见开发文档:https://mp.weixin ...
- Hadoop2.2.0分布式安装配置详解[1/3]
前言 在寒假前的一段时间,开始调研Hadoop2.2.0搭建过程,当时苦于没有机器,只是在3台笔记本上,简单跑通一些数据.一转眼一两个月过去了,有些东西对已经忘了.现在实验室申请下来了,分了10台机器 ...
- [转载]从100PV到1亿级PV网站架构演变
原文地址:http://www.uml.org.cn/zjjs/201307172.asp 一个网站就像一个人,存在一个从小到大的过程.养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有 ...
- 一篇文章让你读懂iOS和Android的历史起源
智能手机虽说是移动电话,但我们完全可以将其作为小型化的电脑来思考.这样一来也能够显示出智能手机OS的高性能.我们首先一起来回顾下智能手机OS的历史. OS的黎明期 其实在很早之前就已经有这样的想法,即 ...
- elasticsearch 忽略大小写模糊搜索实现(转)
在es查询时不区分大小写,可以让查询更方便,具体设置如下: { "settings": { "analysis": { "analyzer" ...
- DataTable转成List集合
项目开发中,经常会获取到DataTable对象,如何把它转化成一个List对象呢?前几天就碰到这个问题,网上搜索整理了一个万能类,用了泛型和反射的知识.共享如下: public class Model ...
- Hexo NexT 博客与Github page 关联指南
上篇文章 Hexo 博客框架NexT主题搭建指南 我们已经在本地搭建好了Hexo博客框架NexT 主题的博客程序,但是这感觉还是远远不够. 我们还想把它部署到我们的Github上,让其他人可以看到我们 ...
- SSH免登录及原理
1.免登陆实现 1)在本机生成公钥/私钥对 ssh-keygen 执行成功后,在.ssh文件夹下,会多出两个文件 id_rsa和id_rsa.pub 2)将公钥写入远端服务器.ssh文件夹下的auth ...