SIFT定位算法关键步骤的说明
1. SIFT算法中一些符号的说明
$I(x,y)$表示原图像。
$G(x,y,\sigma)$表示高斯滤波器,其中$G(x,y,\sigma) = \frac{1}{2\pi\sigma^2}exp(-(x^2+y^2)/2\sigma^2)$。
$L(x,y,\sigma)$表示由一个高斯滤波器与原图像卷积而生成的图像,即$L(x,y,\sigma) = G(x,y,\sigma)\otimes I(x,y)$。一系列的$\sigma_i$,则可以生成一系列的$L(x,y,\sigma_i)$图像,此时我们把这一系列的$L(x,y,\sigma)$图像称为原图像的一个尺度空间表示。关于尺度空间的知识可以参考:图像特征提取:尺度空间理论。
$DOG$表示高斯差分(Difference of Gaussians),也可以表示为$D(x,y,\sigma)$,其中$D(x,y,\sigma) = (G(x,y,k\sigma) – G(x,y,\sigma))\otimes I(x,y) = L(x,y,k\sigma) – L(x,y,\sigma)$。
上面特别值得注意的是尺度为$\sigma$的高斯差分图像由于尺度为$k\sigma$与尺度为$\sigma$的L图像生成的。$k$为两相邻尺度空间倍数的常数。
$O$:高斯金字塔的组数(Octave),其中值得注意的是在实际构建中,第一组的索引可以为0也可以为-1,这个在后面解释原理。
$S$:高斯金字塔每一组的层数。在实际最开始构建尺度空间图像,即L图像的时候,构建了S+3层,一定要把这个S+3与S区分开,为什么是S+3后面分析。
2. 构建高斯差分金字塔
2.1 第一组第一层图像的生成
很多初涉SIFT的都会被这个问题所困惑,这里要分两种情况:其一是把第一组的索引定为0;其二是把第一组的索引定为-1。
我们先考虑第一组索引为0的情况,我们知道第一组第一层的图像是由原图像与$\sigma_o$(一般设置为1.6)的高斯滤波器卷积生成,那么原图像是谁呢?是$I(x,y)$吗?不是!为了图像反走样的需要,通常假设输入图像是经过高斯平滑处理的,其值为$\sigma_n = 0.5$,即半个像元。意思就是说我们采集到的图像$I(x,y)$,已经被$\sigma = \sigma_n = 0.5$的高斯滤波器平滑过了。所以我们不能直接对$I(x,y)$用$\sigma_0$的高斯滤波器平滑,而应该用$\sigma = \sqrt{\sigma_0^2 - \sigma_n^2}$的高斯滤波器去平滑$I(x,y)$,即
$$FirstLayer(x,y) = I(x,y)\otimes G(x,y,\sqrt{\sigma_0^2 - \sigma_n^2})$$
其中$FirstLayer(x,y)$表示整个尺度空间为第1组第1层的图像,$\sigma_o$一般取1.6,$\sigma_n = 0.5$。
现在我们来考虑把第一组的索引定为-1的情况。那么首先第一个问题便是为什么要把索引定为-1。如果索引为0,如上面那种情况所示,整个尺度空间的第1组的第1层图像已经是由原图像模糊生成的了,那么也就是说已经丢失了细节信息,那么原图像我们完全没有利用上。基于这种考虑,我们先将图像放大2倍,这样原图像的细节就隐藏在了其中。由上面一种情况分析,我们已经知识了I(x,y)看成是已经被$\sigma_n = 0.5$模糊过的图像,那么将$I(x,y)$放大2倍后得到$I_s(x,y)$,则可以看为是被$2\sigma_n= 1$的高斯核模糊过的图像。那么由$I_s$生成第1组第1层的图像用的高斯滤波器的$\sigma = \sqrt{\sigma_0^2 -(2 \sigma_n)^2}$。可以表示为。
$$FirstLayer(x,y) = I_s(x,y)\otimes G(x,y,\sqrt{\sigma_0^2 - (2\sigma_n)^2})$$
其中$FirstLayer(x,y)$表示整个尺度空间为第1组第1层的图像,$I_s(x,y)$是由$I(x,y)$用双线性插值放大后的图像。$\sigma_o$一般取1.6,$\sigma_n = 0.5$。
2.2 尺度空间生成了多少幅图像
我们知道S是我们最终构建出来的用来寻找特征点的高斯差分图像,而特征点的寻找需要查找的是空间局部极小值,即在某一层上查找局部极值点的时候需要用到上一层与下一层的高斯差分图像,所以如果我们需要查找S层的特征点,需要S+2层高斯差分图像,然后查找其中的第2层到第S+1层。
而每一个高斯差分图像$G(x,y,\sigma)$都需要两幅尺度空间的图像$L(x,y,k\sigma)$与$L(x,y,\sigma)$进行差分生成,这里假设S =3,则我们需要的高斯差分图像有S+2 = 5张,分别为$G(x,y,\sigma),G(x,y,k\sigma),G(x,y,k^2\sigma),G(x,y,k^3\sigma),G(x,y,k^4\sigma)$。其中的$G(x,y,k\sigma),G(x,y,k^2\sigma),G(x,y,k^3\sigma)$这三张图像是我们用来查找局部极值点的图像。那么我们则需要S+3 = 6张尺度空间图像来生成上面那些高斯差分图像,它们分别为:$L(x,y,\sigma),L(x,y,k\sigma),L(x,y,k^2\sigma),L(x,y,k^3\sigma),L(x,y,k^4\sigma),L(x,y,k^5\sigma)$
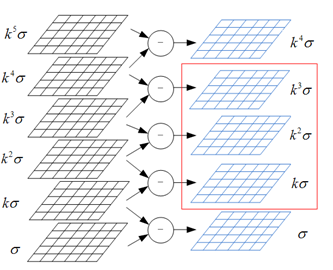
从上面的分析,我们知道对于尺度空间来说,我们一共需要S+3层图像来构建出来S+2层高斯差分图像。所以,如果整个尺度空间一共有O组,每组有S+3层图像。共O*(S+3)张尺度图像,如果我们查找OpenCV中的SIFT源码,则很容易找到如下代码来说明问题:
pyr.resize(nOctaves*(nOctaveLayers + ));
上面代码中的pyr代表了整个尺度空间的图像,nOctaves为组数,nOctaveLayers即为我们定义的S。
2.3 为什么是倒数第3张
相信你在看很多SIFT算法描述里都这样写着,取上一张的倒数第3张图像隔行采样后作为下一组的第一张图像。
答案是为了保证尺度空间的连续性,我们下面来仔细分析。
我们知道对于尺度空间第o组,第s层的图像,它的尺度为$\sigma = \sigma_o k^{o+s/S},其中,k =1/2,o\in[0,1,2,\dots,nOctave-1],s\in[0,1,2,\dots,S+2]$。那么我们从第0组开始,看它各层的尺度。
第0组:$\sigma_o \to 2^{1/3}\sigma_0\to 2^{2/3}\sigma_0\to 2^{3/3}\sigma_0\to 2^{4/3}\sigma_0\to 2^{5/3}\sigma_0$
第1组:$2\sigma_o\to 2*2^{1/3}\sigma_0\to 2*2^{2/3}\sigma_0\to 2*2^{3/3}\sigma_0\to 2*2^{4/3}\sigma_0\to 2*2^{5/3}\sigma_0$
我们只分析2组便可以看出,第1组的第0层图像恰好与第0组的倒数第三幅图像一致,尺度都为$2\sigma_0$,所以我们不需要再根据原图来重新卷积生成每组的第0张图像,只需采用上一层的倒数第3张来降采样即可。
我们也可以继续分析,第0组尺度空间得到的高斯差分图像的尺度为:$\sigma_o\to 2^{1/3}\sigma_0\to 2^{2/3}\sigma_0\to 2^{3/3}\sigma_0\to 2^{4/3}\sigma_0$
而第1组尺度空间得到的高斯差分图像的尺度为:$2\sigma_o\to 2*2^{1/3}\sigma_0\to 2*2^{2/3}\sigma_0\to 2*2^{3/3}\sigma_0\to 2*2^{4/3}\sigma_0$
如果我们把它们的中间三项取出来拼在一起,则尺度为:$2^{1/3}\sigma_0\to 2^{2/3}\sigma_0\to 2^{3/3}\sigma_0\to 2*2^{1/3}\sigma_0\to 2*2^{2/3}\sigma_0\to 2*2^{3/3}\sigma_0$,正好连续!!这一效果带来的直接的好处是在尺度空间的极值点确定过程中,我们不会漏掉任何一个尺度上的极值点,而是能够综合考虑量化的尺度因子。
2.4 用第i-1层的图像生成第i层的图像
值得注意的是,在SITF的源码里,尺度空间里的每一层的图像(除了第1层)都是由其前面一层的图像和一个相对$sigma$的高斯滤波器卷积生成,而不是由原图和对应尺度的高斯滤波器生成的,这一方面是因为我前面提到的不存在所谓意思上的“原图”,我们的输入图像$I(x,y)$已经是尺度为$\sigma = 0.5$的图像了。另一方面是由于如果用原图计算,那么相邻两层之间相差的尺度实际上非常小,这样会造成在做高斯差分图像的时候,大部分值都趋近于0,以致于后面我们很难检测到特征点。
基于上面两点原因(个人认为原因1是最主要的,原因2只是根据实际尝试后的一个猜想,并无理论依据),所以对于每一组的第$i+1$层的图像,都是由第$i$层的图像和一个相对尺度的高斯滤波器卷积生成。
那么相对尺度如何计算呢,我们首先考虑第0组,它们的第$i+1$层图像与第$i$层图像之间的相对尺度为$SigmaDiff_i = \sqrt{(\sigma_0k^{i+1})^2 – (\sigma_0 k^i)^2}$,为了保持尺度的连续性,后面的每一组都用这样一样相对尺度(SIFT实际代码里是这样做的)。这里有一个猜测,比如说尺度为$2\sigma_0$的这一组,第$i$层与第$i+1$层之间的相对尺度计算的结果应该为$\sqrt{(2\sigma_0k^{i+1})^2 – (2\sigma_0 k^i)^2} = 2\cdot SigmaDiff_i$,可是代码里依然用$SigmaDiff_i$是因为这一层被降维了。
sig[] = sigma;
double k = pow(., . / nOctaveLayers);
for (int i = ; i < nOctaveLayers + ; i++)
{
double sig_prev = pow(k, (double)(i - ))*sigma;
double sig_total = sig_prev*k;
sig[i] = std::sqrt(sig_total*sig_total - sig_prev*sig_prev);
}
3. 特征点的搜索
3.1 搜索策略
斑点的搜索是通过同一组内各DoG相邻层之间比较完成的。为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点进行比较,看其是否比它的图像域和尺度域的相邻点大或小。对于其中的任意一个检测点都要和它同尺度的8个相邻点和上下相邻尺度对应的$9\times2$个点共26个点比较,以确保在尺度空间和二维图像位置空间都检测到极值点。也就是,比较是在一个$3\times3$的立方体内进行。
搜索过程从每组的第二层开始,以第二层为当前层,对第二层的DoG图像中的每个点取一个$3\times3$的立方体,立方体上下层为第一层与第三层。这样,搜索得到的极值点既有位置坐标(DoG的图像坐标),又有空间尺度坐标(层坐标)。当第二层搜索完成后,再以第三层作为当前层,其过程与第二层的搜索类似。当S=3时,每组里面要搜索3层。
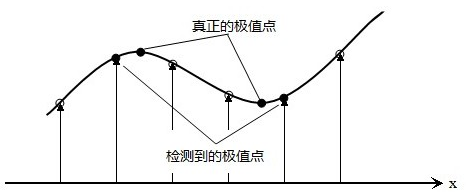
3.2 子像元插值
上的的极值点的搜索是在离散空间中进行的,检测到的极值点并不是真正意义上的极值点。下图显示了一维信号离散空间得到的极值点与连续空间的极值点之间的差别。利用已知的离散空间点插值到连续空间极值点的方法叫子像元插值。
首先我们来看一个一维函数插值的例子。我们已经$f(x)$上几个点的函数值$f(-1) = 1,f(0) = 6,f(1) = 5$,求$f(x)$在$[-1,1]$上的最大值。
如果我们只考虑离散的情况,那么只用简单比较一下,便知最大值为$f(0) = 6$,下面我们用子像元插值法来考虑连续区间的上情况:
利用泰勒级数,可以将$f(x)$在$f(0)$附近展开为:
$$f(x) \approx f(0) + f’(0)x+\frac{f’’(0)}{2}x^2$$
另外我们知道$f(x)$在$x$处的导数写成离散的形式为$f’(x) = \frac{f(x+1) – f(x)}{2}$,二阶导数写成离散形式为$f’’(x) = f(x+1)+f(x-1)-2f(x)$。
所以,我们可以算出$f(x) \approx 6+2x+\frac{-6}{2}x^2 = 6+2x-3x^2$
求取函数$f(x)$的极大值和极大值所在的位置:
$$f’(x) = 2-6x = 0, \ \ \ \hat{x} = \frac{1}{3}$$
$$f(\hat{x}) = 6+2\times \frac{1}{3} – 3\times(\frac{1}{3})^2 = 6\frac{1}{3}$$
现在回到我们SIFT点检测中来,我们要考虑的是一个三维问题,假设我们在尺度为$\sigma$的尺度图像$D(x,y)$上检测到了一个局部极值点,空间位置为$(x,y,\sigma)$,由上面的分析我们知道,它只是一个离散情况下的极值点,连续情况下,极值点可能落在了$(x,y,\sigma)$的附近,设其偏离了$(x,y,\sigma)$的坐标为$(\Delta x,\Delta y,\Delta \sigma)$。则对$D(\Delta x,\Delta y,\Delta\sigma)$可以表示为在点$(x,y,\sigma)$处的泰勒展开:
$$D(\Delta x,\Delta y,\Delta \sigma) = D(x,y,\sigma)+\begin{bmatrix}
\frac{\partial D}{x} & \frac{\partial D}{y} & \frac{\partial D}{\sigma}
\end{bmatrix}\begin{bmatrix}
\Delta x\\
\Delta y\\
\Delta \sigma
\end{bmatrix}+\frac{1}{2}\begin{bmatrix}
\Delta x &\Delta y & \Delta \sigma
\end{bmatrix}\begin{bmatrix}
\frac{\partial ^2D}{\partial x^2} & \frac{\partial ^2D}{\partial x\partial y} &\frac{\partial ^2D}{\partial x\partial \sigma} \\
\frac{\partial ^2D}{\partial y\partial x}& \frac{\partial ^2D}{\partial y^2} & \frac{\partial ^2D}{\partial y\partial \sigma}\\
\frac{\partial ^2D}{\partial \sigma\partial x}&\frac{\partial ^2D}{\partial \sigma\partial y} & \frac{\partial ^2D}{\partial \sigma^2}
\end{bmatrix}\begin{bmatrix}
\Delta x\\
\Delta y\\
\Delta \sigma
\end{bmatrix}$$
可以将上式写成矢量形式如下:
$$D(x) = D+\frac{\partial D^T}{\partial x}\Delta x+\frac{1}{2}\Delta x^T\frac{\partial ^2D^T}{\partial x^2}\Delta x$$
令上式的一阶导数等于0,可以求得$\Delta x = -\frac{\partial^2D^{-1}}{\partial x^2}\frac{\partial D(x)}{\partial x}$
通过多次迭代(Lowe算法里最多迭代5次),得到最终候选点的精确位置与尺度$\hat{x}$,将其代入公式求得$D(\hat{x})$,求其绝对值得$|D(\hat{x})|$。如果其绝对值低于阈值的将被删除。
Vec3f dD((img.at<sift_wt>(r, c + ) - img.at<sift_wt>(r, c - ))*deriv_scale,
(img.at<sift_wt>(r + , c) - img.at<sift_wt>(r - , c))*deriv_scale,
(next.at<sift_wt>(r, c) - prev.at<sift_wt>(r, c))*deriv_scale);
// dD为一阶差分矢量Df/Dx
float v2 = (float)img.at<sift_wt>(r, c) * ;
float dxx = (img.at<sift_wt>(r, c + ) + img.at<sift_wt>(r, c - ) - v2)*second_deriv_scale;
float dyy = (img.at<sift_wt>(r + , c) + img.at<sift_wt>(r - , c) - v2)*second_deriv_scale;
float dss = (next.at<sift_wt>(r, c) + prev.at<sift_wt>(r, c) - v2)*second_deriv_scale;
float dxy = (img.at<sift_wt>(r + , c + ) - img.at<sift_wt>(r + , c - ) -
img.at<sift_wt>(r - , c + ) + img.at<sift_wt>(r - , c - ))*cross_deriv_scale;
float dxs = (next.at<sift_wt>(r, c + ) - next.at<sift_wt>(r, c - ) -
prev.at<sift_wt>(r, c + ) + prev.at<sift_wt>(r, c - ))*cross_deriv_scale;
float dys = (next.at<sift_wt>(r + , c) - next.at<sift_wt>(r - , c) -
prev.at<sift_wt>(r + , c) + prev.at<sift_wt>(r - , c))*cross_deriv_scale; Matx33f H(dxx, dxy, dxs,
dxy, dyy, dys,
dxs, dys, dss);
// dD + Hx = 0 --> x = H^-1 * (-dD)
Vec3f X = H.solve(dD, DECOMP_LU);
3.3 删除边缘效应
为了得到稳定的特征点,只是删除DoG响应值低的点是不够的。由于DoG对图像中的边缘有比较强的响应值,而一旦特征点落在图像的边缘上,这些点就是不稳定的点。一方面图像边缘上的点是很难定位的,具有定位歧义性;另一方面这样的点很容易受到噪声的干扰而变得不稳定。
一个平坦的DoG响应峰值往往在横跨边缘的地方有较大的主曲率,而在垂直边缘的方向有较小的主曲率。而主曲率可以通过$2\times2$的Hessian矩阵$H$求出:
$$H(x,y) = \begin{bmatrix}D_{xx}(x,y) & D_{xy}(x,y)\\ D_{xy}(x,y) &D_{yy}(x,y) \end{bmatrix}$$
上式中,$D$值可以通过求取邻近点像素的差分得到。$H$的特征值与$D$的主曲率成正比例。我们可以避免求取具体的特征值,因为我们只关心特征值的比例。令$\alpha = \lambda_{max}$为最大的特征值,$\beta = \lambda_{min}$为最小的特征值,那么,我们通过$H$矩阵直迹计算它们的和,通过$H$矩阵的行列式计算它们的乘积:
$$Tr(H) = D_{xx}+D_{yy} = \alpha +\beta$$
$$Det(H) = D_{xx}D_{yy}-(D_{xy})^2=\alpha \beta$$
如果$\gamma$为最大特征值与最小特征值之间的比例,那么$\alpha = \gamma \beta$,这样便有
$$\frac{Tr(H)^2}{Det(H)} = \frac{(\alpha+\beta)^2}{\alpha\beta} = \frac{(\gamma+1)^2}{\gamma}$$
上式的结果只与两个特征值的比例有关,而与具体特征值无关。当两个特征值相等时,$\frac{(\gamma+1)^2}{\gamma}$的值最小,随着$\gamma$的增加,$\frac{(\gamma+1)^2}{\gamma}$的值也增加。所以要想检查主曲率的比例小于某一阈值$\gamma$,只要检查下式是否成立:
$$\frac{Tr(H)^2}{Det(H)} < \frac{(\gamma+1)^2}{\gamma}$$
Lowe在论文中给出的$\gamma = 10$。也就是说对于主曲率比值大于10的特征点将被删除。
float t = dD.dot(Matx31f(xc, xr, xi));
//D(\bar{x}) = D + 1/2*dD*\bar{x}
contr = img.at<sift_wt>(r, c)*img_scale + t * 0.5f; // 插值得到的极值点的值
if (std::abs(contr) * nOctaveLayers < contrastThreshold)
return false;
// principal curvatures are computed using the trace and det of Hessian
float v2 = img.at<sift_wt>(r, c)*.f;
float dxx = (img.at<sift_wt>(r, c + ) + img.at<sift_wt>(r, c - ) - v2)*second_deriv_scale;
float dyy = (img.at<sift_wt>(r + , c) + img.at<sift_wt>(r - , c) - v2)*second_deriv_scale;
float dxy = (img.at<sift_wt>(r + , c + ) - img.at<sift_wt>(r + , c - ) -
img.at<sift_wt>(r - , c + ) + img.at<sift_wt>(r - , c - )) * cross_deriv_scale;
float tr = dxx + dyy;
float det = dxx * dyy - dxy * dxy; if (det <= || tr*tr*edgeThreshold >= (edgeThreshold + )*(edgeThreshold + )*det)
return false;
SIFT定位算法关键步骤的说明的更多相关文章
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 关于APIT定位算法的讨论
关于APIT定位算法的讨论 [摘要] 无线传感器网络节点定位机制的研究中,基于距离无关的定位技术得到快速发展,其中基于重叠区域的APIT定位技术在实际环境中的定位精度高,被广泛研究和应用. [关键 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- opencv3.0中contrib模块的添加+实现SIFT/SURF算法
平台:win10 x64 +VS 2015专业版 +opencv-3.x.+CMake+Anaconda3(python3.7.0) Issue说明:Opencv3.0版本已经发布了有一段时间,在这段 ...
- [CLPR] 定位算法探幽 - 边缘和形态学
一. 引言 如何从一副图片中找到车牌? 这是机器视觉的一个应用. 理所当然地, 思考的角度是从车牌本身的信息入手, 为了讨论方便, 下面均以长窄型蓝白车牌为例. 下图就是这样一张车牌的基本信息. 一眼 ...
- 详细讲解 A/B 测试关键步骤,快来检查下还有哪些疏漏的知识点
作为一种对照实验方法,A/B 测试通过比较两个 (或多个) 不同版本之间的差异来验证假设是否正确.该方法将特定测试组从实验其余部分中独立出来,从而得出可靠结果.在被测人不知情且测试场景真实的情况下,A ...
- Trilateration三边测量定位算法
转载自Jiaxing / 2014年2月22日 基本原理 Trilateration(三边测量)是一种常用的定位算法: 已知三点位置 (x1, y1), (x2, y2), (x3, y3) 已知未知 ...
- 关于安卓苹果手机安装证书抓https的关键步骤
苹果有关键步骤!!!
随机推荐
- jquery ui学习笔记
- Spring 7大功能模块的作用[转]
核心容器(Spring core) 核心容器提供Spring框架的基本功能.Spring以bean的方式组织和管理Java应用中的各个组件及其关系.Spring使用BeanFactory来产生和管理B ...
- iOS开发UI篇—使用嵌套模型完成的一个简单汽车图标展示程序
iOS开发UI篇—使用嵌套模型完成的一个简单汽车图标展示程序 一.plist文件和项目结构图 说明:这是一个嵌套模型的示例 二.代码示例: YYcarsgroup.h文件代码: // // YYcar ...
- good
1,将NodeList 转化成 Arrayvar divs = Array.from(document.querySelectorAll('div'));2,将 arguments 转化成 Array ...
- 关于VS2013中Win32程序怎么修改图标
首先向资源文件上加上你要添加的资源(把你要添加的图标放在你的工程的下面,然后右击资源文件选中添加资源,然后选择导入你要添加的图标),下面你只要打开你项目的.rc文件要用查看代码形式打开,然后只要把系统 ...
- OpenCV是什么?
OpenCV其实就是一对C和C++语言的源代码文件,这些源代码文件中实现了许多常用的计算机视觉算法.例如C借口函数cvCanny()实现了Canny边缘提取算法.可以直接将这些源代码添加到我们自己的项 ...
- [转]设置Android手机以使用ARM Streamline进行性能分析(一)
本博客第一次转载的文章,原文访问不到了,这篇是从google cache里挖出来的,为有需要的同学准备.原文地址 Posted by Fang Bao,(鲍方) 4 Comments 11 J ...
- C++ 迭代器模式实现
STL模板库中有大量迭代器实现,这些迭代器隔离了算法实现与访问接口,我们也可以编写属于自己的迭代器.STL中的迭代器均继承至一个通用迭代器接口: template <class _Categor ...
- Codeforces Round #378 (Div. 2) A B C D 施工中
A. Grasshopper And the String time limit per test 1 second memory limit per test 256 megabytes input ...
- ubuntu 上安装mysql
打开"终端窗口",输入"sudo apt-get install mysql-server mysql-client"-->回车-->输入" ...