UE手游如何应对CPU帧率瓶颈和卡顿?
如何高效准确详细的对性能进行剖析?腾讯游戏学院专家Leonn将归纳总结在UE下对每一性能指标的剖析方法,本文重点讲解如何应对CPU帧率瓶颈和卡顿?
CPU上帧率低和卡顿是性能优化中最易出现的一部分,尤其对于手游,提到卡,就大概率是在CPU上出现的问题,CPU上的卡顿一般是卡逻辑或是卡渲染,本篇将详细系统的介绍基于UE的手游对CPU瓶颈的剖析方法。
低帧率和卡顿
首先低帧率和卡顿是两种完全不同的瓶颈类型,虽然归根到底都是某个函数执行的过慢引起的,但是定位和解决方法并不一样。低帧率瓶颈是需要统计一段时间内CPU把更多的时钟耗费在了哪些函数上,或统计一段时间内各个函数占用的CPU时间百分比,找到百分比高的将其优化,就会使帧率得到整体的提高。卡顿则是在一帧的一次运行内某段代码的运行产生了比平均情况明显的长时间,需要定义这段代码的起始点,分别进行计时,然后在连续的统计数据中找到峰值。简单来说帧率瓶颈是统计平均的CPU占用,而卡顿是找峰值。
低帧率瓶颈—平均CPU占用
对于UE程序,我们通常有下面一些方法去找到函数的平均CPU占用。一种是基于UE内置的stat机制,另一类是基于各种平台相关工具。
UE的stat机制
UE自己的stat机制是一种基于埋点的机制,即通过在一段逻辑前后显示的增加标签来录得这段时间这个标签内逻辑的运行时间。然后利用UE的frontend可视化所有打了标签的函数的运行时间曲线。这个基于埋点的机制的好处是:不仅可以看到平均CPU占用,也能看到峰值。缺点就是需要人工打标签,你需要不断的细分一些标签去找到瓶颈。
Stat的代码机制是这样运作的:
首先UE有很多种类型的stat,测试CPU运行时间的stat叫做cycle stat。典型的使用分三步:
第一步:每个stat一定存在于一个stat group里,需要通过下面宏先定义一个stat group。
DECLARE_STAT_GROUP(Description, StatName, StatCategory, InDefaultEnable, InCompileTimeEnable, InSortByName)
这里的InDefaultEnable表示是否默认开启,默认不开启的话需要在运行时通过 stat group enable StatNamel来动态开启。这个宏会定义一个FStatGroup_StatName的结构体。
第二步:定义一个cycle stat,通过宏DECLARE_CYCLE_STAT(CounterName,StatId,GroupId),这里的groupid就是之前定义的group的statname。这个宏其实是调用一个更加通用类型stat的声明DECLARE_STAT(Description, StatName, GroupName, StatType, bShouldClearEveryFrame, bCycleStat, MemoryRegion),它会定义一个FStat__StatId的结构体,并同时声明一个全局的FThreadSafeStaticStat<FStat__StatId>变量StatPtr_StatId,这个变量有个主要的作用是高效率的通过getstatid()接口返回某个给定名字的statid的全局唯一的FStat__StatId实例。
第三步:测量,定义好之后可以在一段代码的作用域开始处加入SCOPE_CYCLE_COUNTER(StatId),它会为当前作用域的前后埋点,这statid会用来统计这个作用域处的CPU时间开销,其实它获取到全局的这个FStat__StatId用其构造了一个FScopeCycleCounter的临时变量,它继承自FCycleCounter,它是个基于scope的变量,在构造的时候会调用FCycleCounter的start,start就会开始设定这个FStat__StatId的统计,而析构的时候他调用FCycleCounter的stop来停止收集。
所谓收集的过程就是调用FThreadStats::AddMessage( StatName, EStatOperation::CycleScopeStart )通知stat线程去进行一个给定名字的cycle事件的收集,结束则是调用的FThreadStats::AddMessage(StatId, EStatOperation::CycleScopeEnd)。FThreadStats::AddMessage是真正最终让UE做性能统计的接口,而前面定义的stat group和stat id则是上层的封装,你完全可以直接调用FThreadStats::AddMessage去给UE增加一个统计,但是这个只会记录在统计文件里,不能像stat group那样使用控制台指令实时打印在游戏界面上。
这里面除了上面这种最常规的定义一个CPU时间统计的方法,还有很多其他有用的宏方法:
QUICK_SCOPE_CYCLE_COUNTER(Stat):不需要你事先声明一个group,也不需要事先声明一个statid,用这个stat名字作为statid,在STATGROUP_Quick里面定义一个cycle的统计。
DECLARE_SCOPE_CYCLE_COUNTER(CounterName,Stat,GroupId):声明一个在groupid组下的叫做countername的statid,并且立即启动一个它的scopecyclecounter,这也是一个在代码里快捷加cycle 统计的方法。
DECLARE_STATS_GROUP_VERBOSE:声明一个默认不被enable的组。
CONDITIONAL_SCOPE_CYCLE_COUNTER(Stat,bCondition):只有在bCondition为true的情况下才统计。
此外可以定义上面除了int类型之外的cycle counter之外,还可以定义其他类型,使用
DECLARE_FLOAT_COUNTER_STAT
DECLARE_DWORD_COUNTER_STAT
此外cycle counter还可以使用累计模式,即每帧不清空,即统计的是到当前为止的累计值,使用DECLARE_FLOAT_ACCUMULATOR_STAT这样的宏。
除了对cpu cycle的统计之外,stat系统还可以统计其他一些指标,包括:
DECLARE_MEMORY_STAT将声明一个int64的累计的计数器,通常用于统计内存,这种statid通常不用cycle count那种定义FScopeCycleCounter来使用,而是直接在代码里利用INC_MEMORY_STAT_BY/DEC_MEMORY_STAT_BY来手动加减,它其实相当于调用FThreadStats::AddMessage()给他发一个EStatOperation::Add/substrct消息。
当然所有stat都可以调用这个手动加减的接口,甚至还有直接设置每个stat的当前数值的接口SET_DWORD_STAT_FName。
上面列举了各种眼花缭乱的stat定义方法,但是其实这些多种多样的统计宏的背后的机制是简单纯粹的,就是在各种使用这个宏定义。
DECLARE_STAT(Description, StatName, GroupName, StatType, bShouldClearEveryFrame, bCycleStat, MemoryRegion)和FThreadStats::AddMessage()这两个机制。把这个机制抽象起来,可以这样描述:
1.首先在STAT系统定义了一种计数器,通过上面DECLARE_STAT这个宏去生成一个叫做FStat_##StatName的计数器的类型,这个类型要返回一些接口,用来描述:GroupName-属于哪个组,StatType-计数器的数据类型,bShouldClearEveryFrame-是否每帧清空,还是累加,bCycleStat-是否用来统计cpu cycle,MemoryRegion-是否是对memory的统计,如果是统计的mem类型是什么。
2.定义一个通常是全局的FThreadSafeStaticStat<FStat_##Stat>StatPtr_##Stat来方便的获取某个stat 名字的statid计数器类型。
3.使用FThreadStats::AddMessage(FNameInStatName, EStatOperation::TypeInStatOperation )这个机制去操纵某个stat计数器的值。InStatName就是这里的stat的名字,InStatOperation包括的操作包括:CycleScopeStart和CycleScopeEnd -将这段时间内的CPU时间ms记录下来加到计数器里, Set-直接设置计数器的值,Clear-清空计数器的值,Add-增加计数器的值,Subtract-减少计数器的值。
所以上面的各种宏只是对上面这三个步骤的各种简化封装。
Stat系统给我们提供了一个基于埋点的统计函数CPU时间的机制,它很强大,我们可以通过stat group去动态看到这些时间(那些默认enable的),也可以通过UE的profilor去看各个计数器的时间曲线。但是很多时候当我们不能预感到哪里会有瓶颈的时候,即不知道在哪里埋点的时候,就需要更通用一些的机制。就依托一些平台的工具了。
平台工具
XCode的counter
counter是xcode在instrument里面的一个工具,他可以记录CPU上每个线程在一段时间内的各个函数的CPU占用时间比,对于ios系统来说,这个是衡量CPU帧率瓶颈的golden rule。Counter看到的具体内容可以如下:
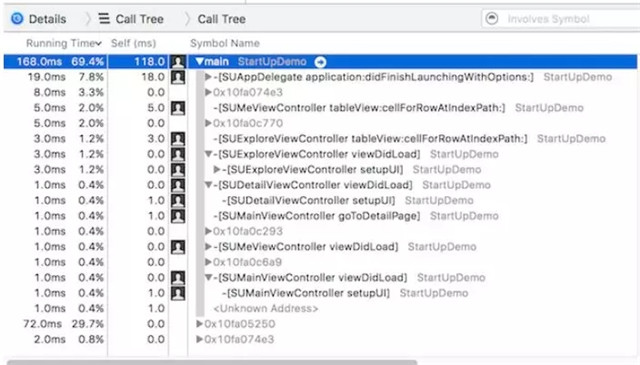
如何从Counter来推测出每个函数的每帧具体时间开销呢?Counter给的是一个CPU的时间占比,我们可以先看到具体gamethread占用CPU的时间比r,然后从UE的stat unit得到gamethread的每帧时间t,然后对于一个具体函数它的CPU时间占比如果是b,那么这个函数平均每帧的执行时间就是t*b/r.
Android Studio的profiler
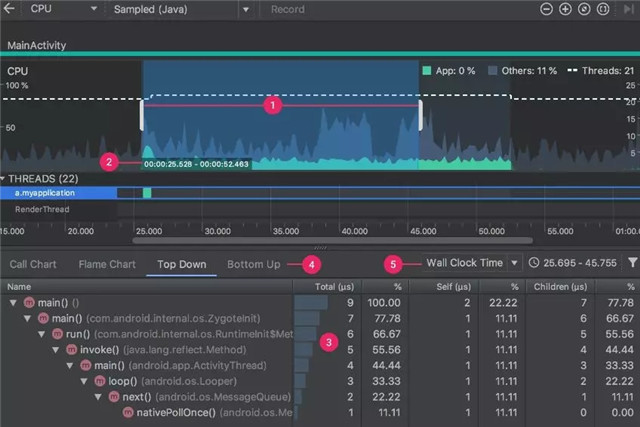
Android Studio3.0以上的profiler很强大,如果device是8.0以上的android系统,那么将可以用profilor capture一段时间的c++即android trace。然后可以从图表中看到当前每个thread中每个函数的CPU占用时间比,执行次数,等等,如图:
还可以看到具体的每个线程每个函数执行的时序,如图:
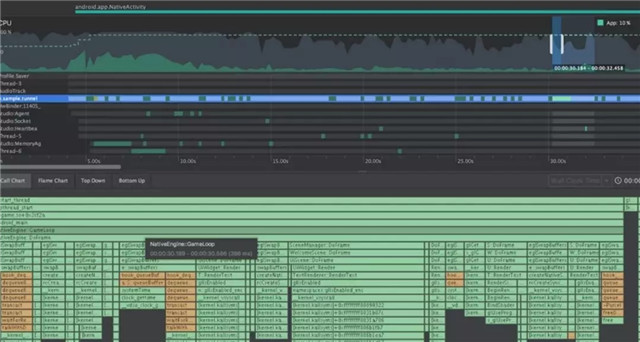
通过这个profiler不仅可以像xcode的counter一样获取所有c++函数的每帧执行时间,找到热点函数,我们还可以从thead的执行时许上直观看到多线程之间的函数执行关系,多线程的执行状态是否合理,比如看到game线程在某个地方需要等待很久某个work线程完成,那么可以尝试把work再分并行,或者调整某些无关的事情提前,让game等这个work的同时在做一些别的工作,不要干等。
Android NDK的simpleperf
对于低版本无法使用android studio profiler调试的可以依赖Android sdk里面的另外两个有用的工具,一个是NDK的simpleperf,它可以调试获取c++层每个函数的CPU占用百分比,除了需要用命令行并且输出的格式没那么好看之外,同studio的profilor能拿到的结果是差不多的。
Simpleperf的完全使用文档在https://developer.android.com/ndk/guides/simpleperf,其实主要分为两步,第一步是用simperperf record命令去采集数据,第二步是用simpleperf report命令去输出数据。
一种比较简单的使用方法是这样的,首先连接手机,运行程序,确保在usb调试状态下,首先进入ndk的simpleperf目录下,打开app_profiler.config去配置一些配置,一定要配置的包括:
App_package_name:包名。
Android_sudio_projectdir:androidsdutio工程路径,这个在UE工程就是目录client/intermediate/android/apk/gradle/。
Native_lib_dir:这个是用来寻找带调试符号的so的地址,在UE工程就是client/intermediate/android/apk/jni/armeabi-v7a/这个目录,因为shipping版本的符号没有,所以这里要提供在develop等版本编译出来的。
Apk_file_path:这是你的apk的路径。
Main_activity:这个对于UE程序一般默认是com.epicgames.ue4.GameActivity。
Record_option:这个比较重要,要参加文档,是record的参数,例如”-e cpu-clock:u–duration 5”就代表采样CPU时钟数,并且仅监控用户空间,采样5秒。至于这里-e还可以采集哪些东西,你可以执行adb shell run-as com.xxx.xxx ./simpleperf list来列出来。
Adb_path:这里要填本机的adb工具的位置。
配置好了,我们可以先启动你的可调式版本的程序在手机上,不能是shipping版本。然后正常情况我们需要做一系列上传符号,找psid,获取各种环境信息的操作给simperf,不过这个simpleperf下面有个快捷的app_profiler.py,它帮我们做好了,我们先python app_profilor.py执行这个py文件就好了。这个过程可能很慢,尤其是上传调试符号,它会代替手机上目录里面的so,所以对于一个手机的一次app安装,这个操作python脚本只要执行一次就好,不执行的话可能结果里面找不到符号信息。
等这个执行好了,我们先找到这个程序的pid,利用adb shell里面的ps命令能拿到。
这时我们就可以进行一次采集,比较常见的采集指令是:
Adb shell run-as com.xxx.xxx
./simpleperf record -e cpu-clock:u --duration 5–p pid--symfs .
采集好后,我们可以通过simpleperf report指令来查看结果。
最简单的指令是./simple report –pidspid通过这个指令可以看到这个进程里面所有线程的各个函数在这段采集时间的CPU占用百分比。如图:

可以看到这个看上去比较乱,我们想逐个线程,并且按照一定排序来看,所以可以先显示各个线程的。
使用 ./simpleperfreport --pidspid--sorttid,comm可以得到。

这样我们就可以先一眼看出主要的几个线程的总的开销,有UE开发经验的同学肯定一眼就能认出这些线程,其实这里的thread-1884就是game线程了,然后我们再一点点的看每个线程就好了,我们使用./simpleperfreport --pidspid–tids 1206 –g来打印RHI线程上的CPU占用,-g表示打印调用关系,我们可以得到。

可以看到很清晰rhi线程上的函数开销,这个百分比是占整个rhi线程的,不是占整个进程的,配合stat unit这样的指令,如果我们知道rhi线程的时间,就能得到每帧某个函数的执行时间,因为rhi线程是api的提交线程,所以排名靠前的除了cpu内存就是一些cmdbuff的执行函数了。
Android SDK的systrace
上面的simpleperf是个对于所有android系统不用root不用特殊工具就能得到的一种通用的函数开销分析,在android sdk下有个systrace,可以得到除CPU函数占用外的另外一些信息,包括比较有用的cpu-gpu trace,线程的工作状况等,也可以用来代替studio里面的线程工作查看功能。具体用法是,首先它的完整文档可以参考
https://developer.android.com/studio/profile/systrace/command-line。
我们进入android sdk的platform-tools下面的systrace文件夹下面,Systrace主要利用了里面的systrace.py这个命令脚本,采集一段trace,并保存成一个html文件,用来查看。常用的用法是:
python systrace.py –t 5 –a appname-o mynewtrace.html gfx view smsched idle load
这里面表示做一次5秒的systrace,将其输出到mynewtrace.html,然后后面是这次trace要采集的内容,具体能采集哪些内容可以使用python systrace.py--list-categories来得到。我们采集后就会生成这个html文件。
下面是查看,很多软件可以查看trace文件,简单的方法是打开chrome浏览器,输入chrome://tracing,就能打开这个trace查看工具,然后load加载你的html文件,就可以看到这个trace图形结果了。如图:
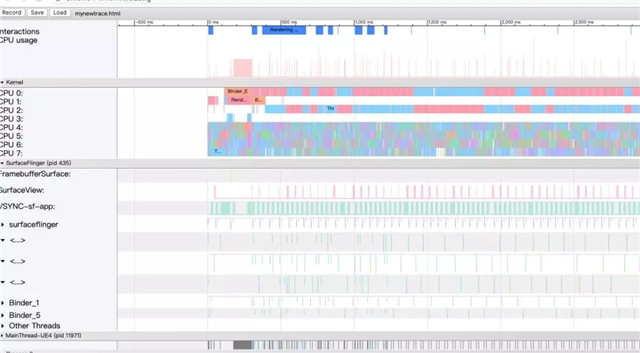
我们去聚焦一些有用的东西:
比如观察CPU的trace,可以看到每个核上正在执行的线程执行的任务。

又比如我们观察下面几行,就可以判断当前CPU还是GPU的瓶颈。我们看SurfaceView即可以认为是GPU的绘制时间,大约10ms之内,而最下面RenderThread2上的eglswapbuf是CPU给GPU每帧最后做提交的截止,两次eglswapbuffer直接的间隔高达53ms,说明当前是明显的CPU瓶颈。

Lua层的函数瓶颈分析
前面我们一直在讨论C++这层的瓶颈,大部分手游可能会在c++上使用lua开发,上面的工具都不直接支持对Lua的热点函数分析,只能得到lua虚拟机的执行时间,我们就需要给lua层提供一种分析方法。
我们可以利用Lua的Debug库,Lua虚拟机自带了一个Debug库,文档可参考https://www.lua.org/pil/23.html,用它可以获取到丰富的lua层的profile信息,最关键的是要为lua设置一个钩子,即debug.sethook,我们勾住每一次函数的call和return,即使用”cr”选项,然后在钩子事件中,我们又可以通过debug.getinfo获得当前勾住的函数信息,我们既然已经能够知道每次函数的调用和返回时机,剩下的工作就是写一些统计性的代码了。
卡顿问题
在最前面我们说低帧率和卡顿是两种性质的问题,找到卡顿问题一般只能使用埋点的方式,即基于UE的stat系统,观察stat的曲线,找到每个峰值。但是问题是为了发现某个位置的卡顿,这些点应该埋在哪里?毕竟UE默认的stat为我们埋的点并不能覆盖所有地方。
我们一般可以基于UE的主线逻辑去不断的做二分(或N分):
UE虽然是一个复杂的多线程工作的系统,但是其GameThread是控制分配其他所有线程的,所以理论上所有线程的卡顿最终都能被反应到GameThread上,而RenderThread和RHI thread是另外两个比较容易出瓶颈的大线程,所以一般上我们能够在这三个大线程上埋好点就可以了。
GameThread:GameThead的每帧的逻辑tick的主流程在FEngineLoop::Tick里面,我们可有通过不断的对这个函数用scopecounter细分埋点来定位卡顿的来源。
RenderThread:RenderThread是一个命令队列,由GameThread充填,只要这个队列里有命令它就会持续执行,UE使用一些统一的宏去把命令加入队列,包括ENQUEUE_UNIQUE_RENDER_COMMAND(TypeName,…)这些宏等,我们很自然的能够想到只要在这些宏里面执行指令的时候加入一个scopecounter就可以了,就能先统计到每个渲染指令的大入口的开销,其实UE已经这样做了,它会为每个渲染指令在STATGROUP_RenderThreadCommands这个组下面生成一个叫做TypeName的stat。当我们找到了那个具体的RenderThread的卡顿点的时候,可以自己进入这个命令的执行函数里面进一步二分去定位。RenderThread里面通常来说比较容易成为瓶颈的大指令函数包括FMobileSceneRenderer::Render,FSlateRenderer::DrawWindow等,这些可以看做渲染的每帧主循环,要在里面进一步细分。
RHIThread:RhiThread也是一个命令队列,由Render或者game填充并驱动指令,负责图形API的调用。RHI命令继承自FRHICommand,并且从ExecuteAndDestruct函数执行,所以我们其实可以在这里加入一个通用的scopecounter做统计,然后找到是哪个rhicommand是瓶颈之后再进一步在指令的excute执行函数里面细分下去。
对于Render和RHI线程,他们的卡顿在stat图表上看最终都会导致gamethread的卡顿,gamethread表现在卡在Waitforevent或者SyncFrameEnd上,都表示game有可能卡在渲染任务上,waitforevent是因为gamethread确实已经无事可做,而还要受taskgraph上其他依赖的线程的完成,可能是渲染线程,syncframeend则是game在执行完一帧结束的时候要检查是不是至少上一帧的rhi执行完毕。
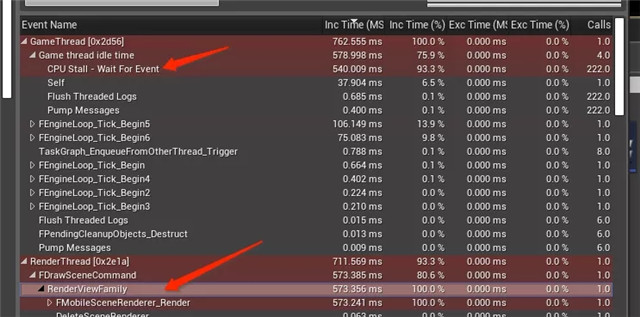
由于game是render和rhi的源驱动,所以通常我们在确定render和rhi卡顿的时候需要进一步追溯到是game的哪一步逻辑导致的render和rhi的卡,即”第一现场”,这里面需要排除一些多线程的因素,一种方法是我们强制单线程,即使用”-onethread”来启动,但是这种设置可能会很卡或者运行不正常,另一种是在多线程下配合各种强制同步方法,包括:
l 调用FlushRenderingCommands在gamethread强行等待当前所有renderthread的指令以及rhithread中的指令全执行完,相当于一次完整的对渲染线程的强制同步。
l 调用GRHICommandList.GetImmediateCommandList().ImmediateFlush()则是只强制将rhithread的指令执行完毕,相当于只强制同步rhi线程。
l 调用GRHICommandList.GetImmediateCommandList().BlockUntilGPUIdle()则会强制把当前的的所有rhi中指令执行完毕,并且把commandbuffer发送给gpu,并且等待gpu执行完成,相当于一个强制同步到GPU的过程。
我们可以通过在某些逻辑处应用这些同步接口来在局部模拟类似单线程的情形来定位渲染上的“第一现场”。
除了Render和RHI之外,game线程在工作的时候会派发很多工作线程出去,这些对game的继续推进有前置依赖的任务如果没有执行完,也会导致gamethread表现的卡顿,但是其实是卡在了某个其他任务线程上,game会表现在卡在wait for event上,这时候第一要去查看其他的thread的工作情况,看看是否某个game等待的工作线程做的太久,另一种情况就是没有找到哪个线程工作的很久,大家都在wait,这时候要分析这个包含这个wait event的函数的逻辑,说明没有哪个线程在满载运行,可能因为:
l 逻辑设计的不合理,线程间互相等待。
l 等待IO。
l 等待了某个需要被延时触发的事件。
l 等待某个昂贵的操作,但是这个操作有又被不合理的大量分帧,所以看上去在没帧内没有哪个线程工作饱满,但是就是在等。
总之这种没有明显特征的wait要具体分析wait处的逻辑,另外要理解UE的taskgraph,asynctask等系统才会有更大帮助。
Stat Hitches
除了基于stat系统埋点之外,UE还提供stat hitches这套指令。Stat埋点的方法通常需要我们去录很长一段数据,可能一些卡顿不是容易出现的,录一段很长的stat数据打开也不方便。Stat Hitches这套指令是动态的去发现当前某一阵是否为卡顿帧(其实它是设置了一个阈值),然后选择将其显示出来,或者保存当前帧前后的stat数据。
一般用法是先设置 t.HitchFrameTimeThreshold定义卡顿的帧时间阈值,然后用指令stat hitches可以直观看到掉帧时的屏幕显示,用指令stat DumpHitches则可以将掉帧时候的stat数据保存下来及输出到控制台。
对于UE程序有很多种方法分析帧率瓶颈及卡顿的性能问题,解决问题的前提是找到问题,而找到问题的前提是找到或者制作合适的工具来捕捉到问题。作为引擎和游戏的优化开发人员,无论是什么机型,只要安装我们的版本,我们就可以找到一个有效的方法定位问题,才能做到不慌,保证问题得到解决。
UE手游如何应对CPU帧率瓶颈和卡顿?的更多相关文章
- 为测试赋能,腾讯WeTest探索手游AI自动化测试之路
作者:周大军/孙大伟, 腾讯后台开发 高级工程师 商业转载请联系腾讯WeTest获得授权,非商业转载请注明出处. WeTest导读 做好自动化测试从来不件容易的事情,更何况是手游的自动化测试,相比传 ...
- APP安全环节缺失,手游运营商怎样应对APP破解困境
2013年手游行业的规模与收入均实现了大幅增长,发展势头强劲.然而,在手游快速发展的同一时候,因为监管.审核等方面存在着漏洞,手机游戏软件被破解后注入恶意代码.盗取用户財产.窃取用户设备信息的现象屡见 ...
- 手游后台PVP系统网络同步方案总结
游戏程序 平台类型: 程序设计: 编程语言: 引擎/SDK: 概述 PVP系统俨然成为现在新手游的上线标配,手游Pvp系统体验是否优秀,很大程度上决定了游戏的品质.从最近半年上线的新手 ...
- U3D手游《苍穹变》性能优化经验谈
4月11日,由unity公司举办的Unite 2016大会在上海正式举行,在4月12日的案例分享专场会议上,天神互动U3D高级开发工程师康凯以手游<苍穹变>为例讲述了3DMMOARPG游戏 ...
- 如何快速优化手游性能问题?从UGUI优化说起
WeTest 导读 本文作者从自身多年的Unity项目UI开发及优化的经验出发,从UGUI,CPU,GPU以及unity特有资源等几个维度,介绍了unity手游性能优化的一些方法. 在之前的文 ...
- Unity3D手游开发实践
<腾讯桌球:客户端总结> 本次分享总结,起源于腾讯桌球项目,但是不仅仅限于项目本身.虽然基于Unity3D,很多东西同样适用于Cocos.本文从以下10大点进行阐述: 架构设计 原生插件/ ...
- 腾讯首度公开S级手游品质管理方法
weimjsam 引言 在最新的手游市场占有率统计中,腾讯游戏稳稳占据一半江山,目前仍以每月一到两款的速度推出新品,在如此复杂多变.响应要求极高的市场环境下,能持续推出高质量产品并保持高效迭代更新 ...
- 日新进用户200W+,解密《龙之谷》手游背后的压测故事
2017年3月,腾讯正式于全平台上线了<龙之谷>手游,次日冲到了App Store畅销排行第二的位置,并维持到了现在.上线当日百度指数超过40万,微信游戏平台数据显示预约数780多万,而据 ...
- 七个要素帮你打造现象级手游!优化程度堪比《QQ飞车》
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由WeTest质量开放平台团队发表于云+社区专栏 作者:申江涛,腾讯互娱客户端工程师 商业转载请联系腾讯WeTest获得授权,非商业转载 ...
随机推荐
- C#中的扩展类的理解
扩展类是一种静态的一种类的调用方法,通过实例化进行调用.利用this进行指正该类,有参数的时候直接在后面追加参数. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ...
- 模拟实现ES6的set类
function Set() { var items = {}; // this.has = function(value){ // return value in items; // } this. ...
- oracle 查看表中有多少字段
select count(*) from user_tab_columns t where t.TABLE_NAME='WPM_CHECK_ORDER'
- CentOS下安装Orcale
以前没有安装过,最近安装了.感觉在Liunx安装真的超麻烦.这是技术文档,分享给大家. LINUX安装oracle数据库步骤: 1.安装依赖包 yum -y install gcc gcc-c ...
- git 创建分支并提交代码
1.查看所有分支 git branch -a 2.查看当前分支 git branch 3.新建一个分支 git branch feature-xx 4.切换到新建分支上面 git checkout f ...
- Excel的查询函数vlookup和index使用
需求 有一些省市的区县,有600多条数据,只有名称,没有编码.现在要根据名称去3000多条数据里面查询. 如图,拿出一部分数据来演示 vlookup 使用vlookup,由于vlookup只能查询数据 ...
- Day7 - J - Raising Modulo Numbers POJ - 1995
People are different. Some secretly read magazines full of interesting girls' pictures, others creat ...
- Codeforces Forethought Future Cup Elimination Round 选做
1146C Tree Diameter 题意 交互题.有一棵 \(n(n\le 100)\) 个点的树,你可以进行不超过 \(9\) 次询问,每次询问两个点集中两个不在同一点集的点的最大距离.求树的直 ...
- Angular2的双向数据绑定
什么是双向绑定 如图: 双向绑定.jpg 双向绑定机制维护了页面(View)与数据(Data)的一致性.如今,MVVM已经是前段流行框架必不可少的一部分. Angular2中的双向绑定 双向绑定, ...
- ActiveMQ的安装与配置详情
(1)ActiveMQ的简介 MQ: (message queue) ,消息队列,也就是用来处理消息的,(处理JMS的).主要用于大型企业内部或与企业之间的传递数据信息. ActiveMQ 是Apac ...