【Hadoop离线基础总结】网站流量日志数据分析系统
目录
点击流数据模型
概述
点击流(Click Stream)是指用户在网站上持续访问的轨迹。点击流数据(Click Stream Data)代表了用户浏览网站的整个流程。
实际上,大部分的大型网站都会有日志埋点,通过js的方式获取用户在网站上面点击到的所有链接、按钮、商品等,包括用户访问的URL等。这些js埋点一般由专业的前端来做,而埋点收集到的数据都会发送到日志服务器中,一条日志大概有1kb左右,通过分析用户的点击数据,就可以得到点击流模型。点击流模型
点击流模型由散点状的点击日志数据数理所得,类型分为两种:pageViews模型表 和 visit模型表
原始访问日志表
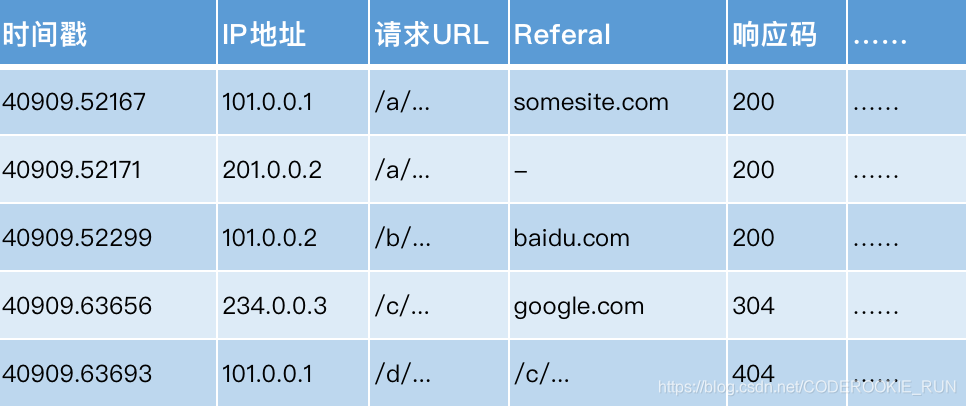
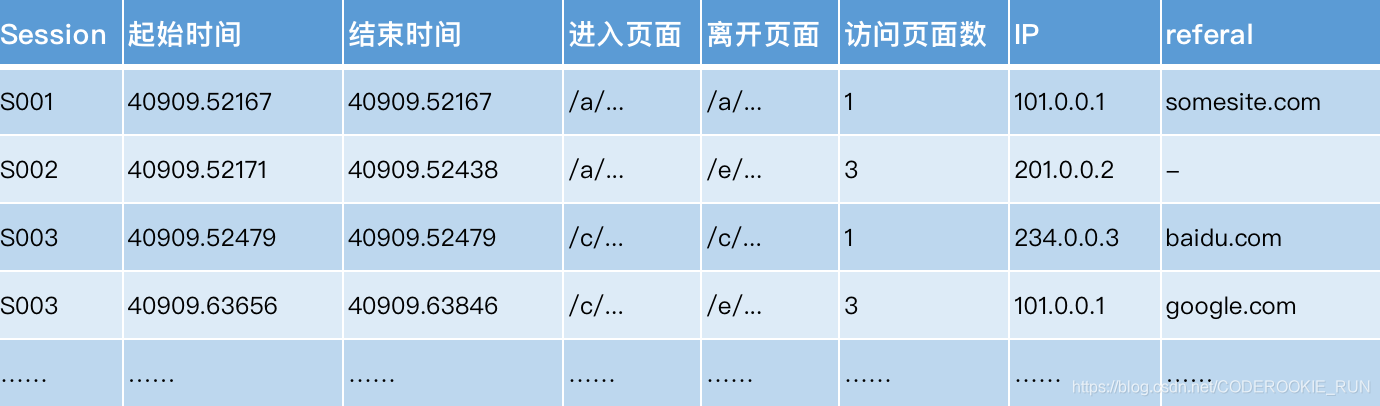
pageViews表(强调的是对一个用户的一次访问session的信息识别)
重视的是每一个页面受到的访问情况,每访问一个页面,就算一条记录

visit表(强调的是一次访问session内的起始与结束时间点的情况)
每一个session会话内,哪个页面进来,哪个页面出去,进入时间,出去时间
网站流量分析

金字塔顶端的 ROI 就是网站的目标:投资回报率
网站流量模型分析
网站流量来源
1.广告推广
2.自然搜索(百度搜索 / google搜索)
3.直接流量(直接输网址)
4.BD流量(商务拓展流量,也就是付费搜索,比如百度竞价排名)

流量最重要的不是数量,而是质量
网站流量多维度细分

访问来源就是指用户从什么地方来访问的
访问媒介是指用户是新访客还是老访客,用户的目标页面网站内容及导航分析
所有的网站都可以划分为三个类型:导航页、功能页、内容页。
首页和列表页都是典型的导航页。
站内搜索页面、注册表单页面和购物车页面都是典型的功能页。
产品详情页、新闻和文章页都是典型的内容页。
一般用户进入网站的流程

网站运营者最不希望看到的情况:

网站转化及漏斗分析
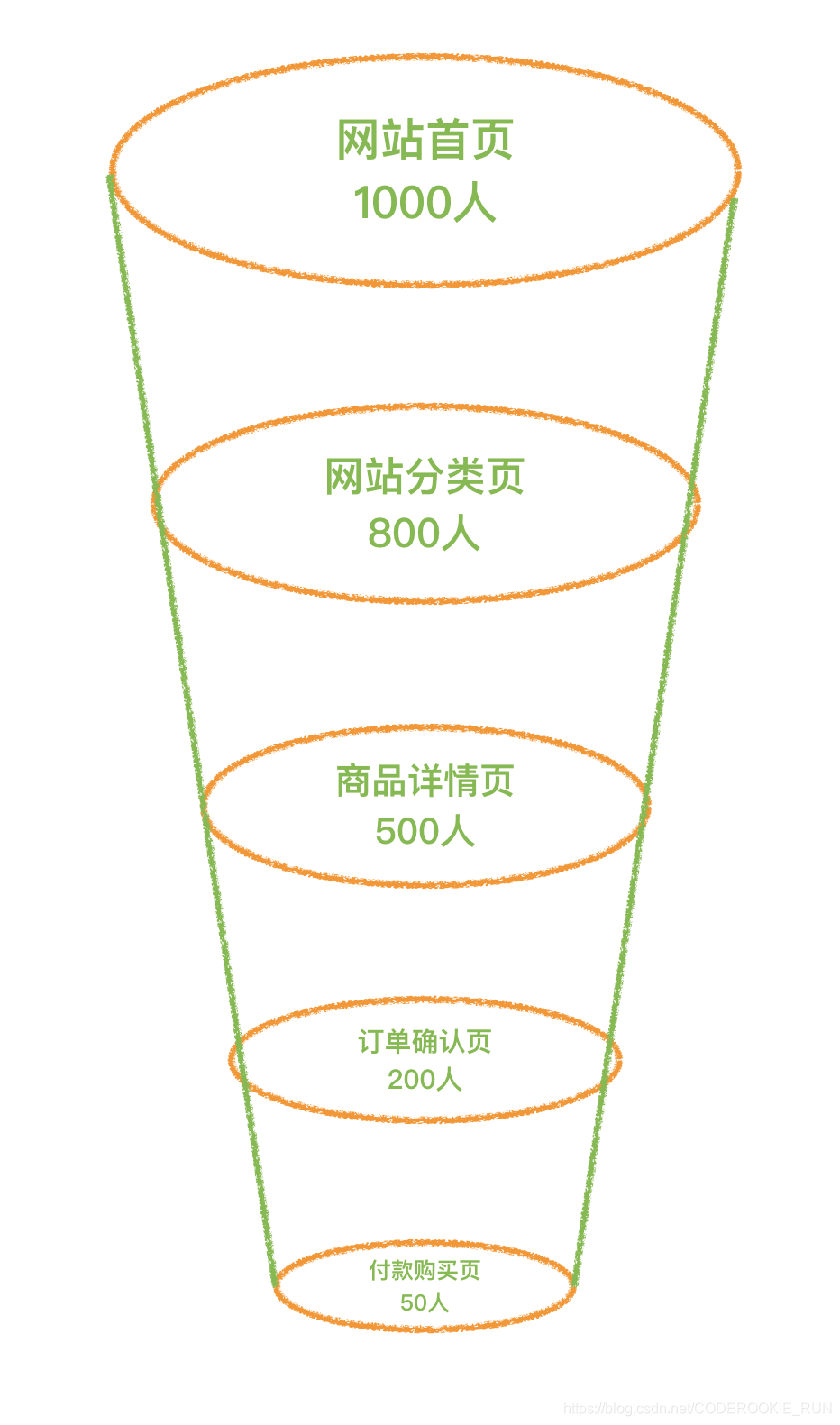
漏斗模型是指进入渠道的用户在各环节递进过程中逐 渐流失的形象描述。
访客减少的现象一般称为 流失 和 迷失。
流失的原因主要有不恰当的商品或活动推荐,对支付环节中专业名词的解释不当等。
迷失的原因主要有转化流量设计不合理,访问者在特定阶段得不到需要的信息,并且不能根据现有的信息作出决策等。比如在线购买演唱会门票,直到支付也没看到在线选座的提示,就有可能产生迷失。
流量常见分析角度和指标分类
指标概述
指标是网站分析的基础,用来记录和衡量访问者在网站的各种行为。比如我们经常说的流量就是一个网站指标,它是用来衡量网站获得的访问量。
指标分类
1.骨灰级指标
IP: 一天之内访问网站的不重复IP数。一天内相同IP地址多次访问网站只被计算一次。曾经IP指标可以用来表示用户访问身份,目前则更多的用来获取访问者的地理位置信息。
PageView浏览量: 一般称为PV值。用户每打开一个网站页面,记录一个PV。用户打开同一页面多次,PV就会累计多次,所以PV值可以理解为页面加载的总次数。
Unique PageView: 不同的用户对应不同的cookie,以用户的cookie为依据,统计访问网站的不重复用户数。一天内同一访客多次访问网站只被计算1次,也就是去重后的访问人数。
2.基础级指标
访问次数: 访客从进入网站到离开网站的一系列活动记为一次访问,也称 会话(session),一次 session 可能包含多个PV。
网站停留时间: 访问者在网站上花费的时间。
页面停留时间: 访问者在某个特定页面或某组网页上所花费的时间。
3.复合级指标
人均浏览页数: 平均每个独立访客产生的PV。人均浏览页数 = 浏览次数/独立访客。体现网站对访客的吸引程度。
跳出率: 指某一范围内单页访问次数或访问者与总访问次数的百分比。其中跳出指单页访问或访问者的次数,即在一次访问中访问者进入网站后只访问了一个页面就离开的数量。
退出率: 指某一范围内退出的访问者与综合访问量的百分比。其中退出指访问者离开网站的次数,通常是基于某个范围的。分析角度
1.基础分析(IP,PV,UV)
趋势分析: 根据选定的时段,提供网站流量数据,通过流量趋势变化形态,为您分析网站访客的访问规律、网站发展状况提供参考。
对比分析: 根据选定的两个对比时段,提供网站流量在时间上的纵向对比报表,帮您发现网站发展状况、发展规律、流量变化率等。
当前在线: 提供当前时刻站点上的访客量,以及最近15分钟流量、来源、受访、访客变化情况等,方便用户及时了解当前网站流量状况。
访问明细: 提供最近7日的访客访问记录,可按每个PV或每次访问行为(访客的每次会话)显示,并可按照来源、搜索词等条件进行筛选。 通过访问明细,用户可以详细了解网站流量的累计过程,从而为用户快速找出流量变动原因提供最原始、最准确的依据。

2.来源分析
来源分类: 提供不同来源形式(直接输入、搜索引擎、其他外部链接、站内来源)、不同来源项引入流量的比例情况。通过精确的量化数据,帮助用户分析什么类型的来路产生的流量多、效果好,进而合理优化推广方案。
搜索引擎: 提供各搜索引擎以及搜索引擎子产品引入流量的比例情况。
搜索词: 提供访客通过搜索引擎进入网站所使用的搜索词,以及各搜索词引入流量的特征和分布。帮助用户了解各搜索词引入流量的质量,进而了解访客的兴趣关注点、网站与访客兴趣点的匹配度,为优化SEO(搜索引擎优化)方案及SEM(搜索引擎营销)提词方案提供详细依据。
最近7日的访客搜索记录: 可按每个PV或每次访问行为(访客的每次会话)显示,并可按照访客类型、地区等条件进行筛选。为您搜索引擎优化提供最详细的原始数据。
来路域名: 提供具体来路域名引入流量的分布情况,并可按“社会化媒体”、“搜索引擎”、“邮箱”等网站类型对来源域名进行分类。 帮助用户了解哪类推广渠道产生的流量多、效果好,进而合理优化网站推广方案。
来路页面: 提供具体来路页面引入流量的分布情况。 尤其对于通过流量置换、包广告位等方式从其他网站引入流量的用户,该功能可以方便、清晰地展现广告引入的流量及效果,为优化推广方案提供依据。
来源升降榜: 提供开通统计后任意两日的TOP10000搜索词、来路域名引入流量的对比情况,并按照变化的剧烈程度提供排行榜。 用户可通过此功能快速找到哪些来路对网站流量的影响比较大,从而及时排查相应来路问题。

3.受访分析
受访域名: 提供访客对网站中各个域名的访问情况。 一般情况下,网站不同域名提供的产品、内容各有差异,通过此功能用户可以了解不同内容的受欢迎程度以及网站运营成效。
受访页面: 提供访客对网站中各个页面的访问情况。 站内入口页面为访客进入网站时浏览的第一个页面,如果入口页面的跳出率较高则需要关注并优化;站内出口页面为访客访问网站的最后一个页面,对于离开率较高的页面需要关注并优化。
受访升降榜: 提供开通统计后任意两日的TOP10000受访页面的浏览情况对比,并按照变化的剧烈程度提供排行榜。 可通过此功能验证经过改版的页面是否有流量提升或哪些页面有巨大流量波动,从而及时排查相应问题。
热点图: 记录访客在页面上的鼠标点击行为,通过颜色区分不同区域的点击热度;支持将一组页面设置为"关注范围",并可按来路细分点击热度。 通过访客在页面上的点击量统计,可以了解页面设计是否合理、广告位的安排能否获取更多佣金等。
用户视点: 提供受访页面对页面上链接的其他站内页面的输出流量,并通过输出流量的高低绘制热度图,与热点图不同的是,所有记录都是实际打开了下一页面产生了浏览次数(PV)的数据,而不仅仅是拥有鼠标点击行为。
访问轨迹: 提供观察焦点页面的上下游页面,了解访客从哪些途径进入页面,又流向了哪里。 通过上游页面列表比较出不同流量引入渠道的效果;通过下游页面列表了解用户的浏览习惯,哪些页面元素、内容更吸引访客点击。

4.访客分析
地区运营商: 提供各地区访客、各网络运营商访客的访问情况分布。 地方网站、下载站等与地域性、网络链路等结合较为紧密的网站,可以参考此功能数据,合理优化推广运营方案。
终端详情: 提供网站访客所使用的浏览终端的配置情况。 参考此数据进行网页设计、开发,可更好地提高网站兼容性,以达到良好的用户交互体验。
新老访客: 当日访客中,历史上第一次访问该网站的访客记为当日新访客;历史上已经访问过该网站的访客记为老访客。 新访客与老访客进入网站的途径和浏览行为往往存在差异。该功能可以辅助分析不同访客的行为习惯,针对不同访客优化网站,例如为制作新手导航提供数据支持等。
忠诚度: 从访客一天内回访网站的次数(日访问频度)与访客上次访问网站的时间两个角度,分析访客对网站的访问粘性、忠诚度、吸引程度。 由于提升网站内容的更新频率、增强用户体验与用户价值可以有更高的忠诚度,因此该功能在网站内容更新及用户体验方面提供了重要参考。
活跃度: 从访客单次访问浏览网站的时间与网页数两个角度,分析访客在网站上的活跃程度。 由于提升网站内容的质量与数量可以获得更高的活跃度,因此该功能是网站内容分析的关键指标之一。

5.转化路径分析
转化定义: 访客在您的网站完成了某项您期望的活动,记为一次转化,如注册、下载、购买。
目标示例:
获得用户目标:在线注册、创建账号等。
咨询目标:咨询、留言、电话等。
互动目标:视频播放、加入购物车、分享等。
收入目标:在线订单、付款等。
路径分析: 根据设置的特定路线,监测某一流程的完成转化情况,算出每步的转换率和流失率数据,如注册流程,购买流程等。
转化类型:
页面

事件

流量日志分析网站整体架构模块
步骤

模块开发之数据采集
1.首先肯定是用flume日志采集系统
2.关于source的配置a1.sources = r1
a1.sources.r1.type = TAILDIR
a1.sources.r1.channels = c1
a1.sources.r1.positionFile = /var/log/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /var/log/test1/example.log
a1.sources.r1.filegroups.f2 = /var/log/test2/.*log.*
TAILDIR(Tail Source) 可以同时监控tail多个目录中的文件,所以filegroups可以有多个,用空格来分隔。
positionFile需要配置检查点文件的路径,检查点文件会以json格式保存已经tail文件的位置,解决了断点不能传续的缺陷。
filegroups.<filegroupName>配置每个filegroup的文件绝对路径,文件名可以用正则表达式匹配
3.sink用HDFS sink,channel用memory channel即可模块开发之数据预处理
1.主要目的
数据清洗 —— 过滤“不合规”数据,清洗无意义的数据
2.实现方式
首先经过flume采集后的数据会有十个字段,每个字段都会由空格来分隔

有效数据应该是这样1、访客ip地址: 58.215.204.118
2、访客用户信息: - -
3、请求时间:[18/Sep/2013:06:51:35 +0000]
4、请求方式:GET
5、请求的url:/wp-includes/js/jquery/jquery.js?ver=1.10.2
6、请求所用协议:HTTP/1.1
7、响应码:304
8、返回的数据流量:0
9、访客的来源url:http://blog.fens.me/nodejs-socketio-chat/
10、访客所用浏览器:Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0
开发一个MapReduce程序WeblogPreProcess
package cn.itcast.bigdata.weblog.pre; import java.io.IOException;
import java.net.URI;
import java.text.SimpleDateFormat;
import java.util.HashSet;
import java.util.Set; import cn.itcast.bigdata.weblog.utils.DateUtil;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.itcast.bigdata.weblog.mrbean.WebLogBean;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /**
* 处理原始日志,过滤出真实pv请求 转换时间格式 对缺失字段填充默认值 对记录标记valid和invalid
*
*/ public class WeblogPreProcess extends Configured implements Tool { @Override
public int run(String[] args) throws Exception {
//Configuration conf = new Configuration();
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
/*String inputPath= "hdfs://node01:9000/weblog/"+DateUtil.getYestDate()+"/input";
String outputPath="hdfs://node01:9000/weblog/"+DateUtil.getYestDate()+"/weblogPreOut";
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), conf);
if (fileSystem.exists(new Path(outputPath))){
fileSystem.delete(new Path(outputPath),true);
}
fileSystem.close();
FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
*/
FileInputFormat.addInputPath(job,new Path("file:////Users/zhaozhuang/Desktop/8.大数据离线第八天/日志文件数据/input"));
job.setInputFormatClass(TextInputFormat.class);
FileOutputFormat.setOutputPath(job,new Path("file:////Users/zhaozhuang/Desktop/8.大数据离线第八天/日志文件数据/weblogPreOut"));
job.setOutputFormatClass(TextOutputFormat.class);
job.setJarByClass(WeblogPreProcess.class);
job.setMapperClass(WeblogPreProcessMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
boolean res = job.waitForCompletion(true);
return res?0:1;
} static class WeblogPreProcessMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
// 用来存储网站url分类数据
Set<String> pages = new HashSet<String>();
Text k = new Text();
NullWritable v = NullWritable.get(); /**
* 从外部配置文件中加载网站的有用url分类数据 存储到maptask的内存中,用来对日志数据进行过滤
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/"); } @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
WebLogBean webLogBean = WebLogParser.parser(line);
if (webLogBean != null) {
// 过滤js/图片/css等静态资源
WebLogParser.filtStaticResource(webLogBean, pages);
/* if (!webLogBean.isValid()) return; */
k.set(webLogBean.toString());
context.write(k, v);
}
}
} public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int run = ToolRunner.run(configuration, new WeblogPreProcess(), args);
System.exit(run);
}
}
运行后得到以下数据
点击流模型PageViews表
由于大量的指标统计从点击流模型中更容易得出,所以在预处理阶段,可以使用mr程序来生成点击流模型的数据。
有结构化数据转换为pageView模型的思路:
1.相同ip的数据放到一起按照时间排序,排序后打上标识
2.同一个ip的两条数据之间的时间差,如果大于30分,就不是同一个session,如果小于30分,就认为是同一个session
3.以ip作为key2,相同的数据发送到同一个reduce形成一个集合package cn.itcast.bigdata.weblog.clickstream; import cn.itcast.bigdata.weblog.mrbean.WebLogBean;
import cn.itcast.bigdata.weblog.utils.DateUtil;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import java.io.IOException;
import java.net.URI;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.*; /**
*
* 将清洗之后的日志梳理出点击流pageviews模型数据
*
* 输入数据是清洗过后的结果数据
*
* 区分出每一次会话,给每一次visit(session)增加了session-id(随机uuid)
* 梳理出每一次会话中所访问的每个页面(请求时间,url,停留时长,以及该页面在这次session中的序号)
* 保留referral_url,body_bytes_send,useragent
*
*
* @author
*
*/
public class ClickStreamPageView extends Configured implements Tool { @Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
/*String inputPath="hdfs://node01:9000/weblog/"+DateUtil.getYestDate()+"/weblogPreOut";
String outputPath="hdfs://node01:9000/weblog/"+DateUtil.getYestDate()+"/pageViewOut";
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:9000"), conf);
if (fileSystem.exists(new Path(outputPath))){
fileSystem.delete(new Path(outputPath),true);
}
fileSystem.close();
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));*/ job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:////Users/zhaozhuang/Desktop/8.大数据离线第八天/日志文件数据/weblogPreOut"));
TextOutputFormat.setOutputPath(job,new Path("file:////Users/zhaozhuang/Desktop/8.大数据离线第八天/日志文件数据/pageViewOut")); job.setJarByClass(ClickStreamPageView.class);
job.setMapperClass(ClickStreamMapper.class);
job.setReducerClass(ClickStreamReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(WebLogBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); boolean b = job.waitForCompletion(true);
return b?0:1;
} static class ClickStreamMapper extends Mapper<LongWritable, Text, Text, WebLogBean> {
Text k = new Text();
WebLogBean v = new WebLogBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\001");
if (fields.length < 9) return;
//将切分出来的各字段set到weblogbean中
v.set("true".equals(fields[0]) ? true : false, fields[1], fields[2], fields[3], fields[4], fields[5], fields[6], fields[7], fields[8]);
//只有有效记录才进入后续处理
if (v.isValid()) {
//此处用ip地址来标识用户
k.set(v.getRemote_addr());
context.write(k, v);
}
}
} static class ClickStreamReducer extends Reducer<Text, WebLogBean, NullWritable, Text> {
Text v = new Text();
@Override
protected void reduce(Text key, Iterable<WebLogBean> values, Context context) throws IOException, InterruptedException {
ArrayList<WebLogBean> beans = new ArrayList<WebLogBean>();
// 先将一个用户的所有访问记录中的时间拿出来排序
try {
for (WebLogBean bean : values) {
//为什么list集合当中不能直接添加循环出来的这个bean?
//这里通过属性拷贝,每次new 一个对象,避免了bean的属性值每次覆盖
WebLogBean webLogBean = new WebLogBean();
try {
BeanUtils.copyProperties(webLogBean, bean);
} catch(Exception e) {
e.printStackTrace();
}
beans.add(webLogBean);
}
//将bean按时间先后顺序排序
Collections.sort(beans, new Comparator<WebLogBean>() {
@Override
public int compare(WebLogBean o1, WebLogBean o2) {
try {
Date d1 = toDate(o1.getTime_local());
Date d2 = toDate(o2.getTime_local());
if (d1 == null || d2 == null)
return 0;
return d1.compareTo(d2);
} catch (Exception e) {
e.printStackTrace();
return 0;
}
} }); /**
* 以下逻辑为:从有序bean中分辨出各次visit,并对一次visit中所访问的page按顺序标号step
* 核心思想:
* 就是比较相邻两条记录中的时间差,如果时间差<30分钟,则该两条记录属于同一个session
* 否则,就属于不同的session
*
*/ int step = 1;
String session = UUID.randomUUID().toString();
for (int i = 0; i < beans.size(); i++) {
WebLogBean bean = beans.get(i);
// 如果仅有1条数据,则直接输出
if (1 == beans.size()) { // 设置默认停留时长为60s
v.set(session+"\001"+key.toString()+"\001"+bean.getRemote_user() + "\001" + bean.getTime_local() + "\001" + bean.getRequest() + "\001" + step + "\001" + (60) + "\001" + bean.getHttp_referer() + "\001" + bean.getHttp_user_agent() + "\001" + bean.getBody_bytes_sent() + "\001"
+ bean.getStatus());
context.write(NullWritable.get(), v);
session = UUID.randomUUID().toString();
break;
} // 如果不止1条数据,则将第一条跳过不输出,遍历第二条时再输出
if (i == 0) {
continue;
}
// 求近两次时间差
long timeDiff = timeDiff(toDate(bean.getTime_local()), toDate(beans.get(i - 1).getTime_local()));
// 如果本次-上次时间差<30分钟,则输出前一次的页面访问信息
if (timeDiff < 30 * 60 * 1000) { v.set(session+"\001"+key.toString()+"\001"+beans.get(i - 1).getRemote_user() + "\001" + beans.get(i - 1).getTime_local() + "\001" + beans.get(i - 1).getRequest() + "\001" + step + "\001" + (timeDiff / 1000) + "\001" + beans.get(i - 1).getHttp_referer() + "\001"
+ beans.get(i - 1).getHttp_user_agent() + "\001" + beans.get(i - 1).getBody_bytes_sent() + "\001" + beans.get(i - 1).getStatus());
context.write(NullWritable.get(), v);
step++;
} else { // 如果本次-上次时间差>30分钟,则输出前一次的页面访问信息且将step重置,以分隔为新的visit
v.set(session+"\001"+key.toString()+"\001"+beans.get(i - 1).getRemote_user() + "\001" + beans.get(i - 1).getTime_local() + "\001" + beans.get(i - 1).getRequest() + "\001" + (step) + "\001" + (60) + "\001" + beans.get(i - 1).getHttp_referer() + "\001"
+ beans.get(i - 1).getHttp_user_agent() + "\001" + beans.get(i - 1).getBody_bytes_sent() + "\001" + beans.get(i - 1).getStatus());
context.write(NullWritable.get(), v);
// 输出完上一条之后,重置step编号
step = 1;
session = UUID.randomUUID().toString();
} // 如果此次遍历的是最后一条,则将本条直接输出
if (i == beans.size() - 1) {
// 设置默认停留市场为60s
v.set(session+"\001"+key.toString()+"\001"+bean.getRemote_user() + "\001" + bean.getTime_local() + "\001" + bean.getRequest() + "\001" + step + "\001" + (60) + "\001" + bean.getHttp_referer() + "\001" + bean.getHttp_user_agent() + "\001" + bean.getBody_bytes_sent() + "\001" + bean.getStatus());
context.write(NullWritable.get(), v);
}
} } catch (ParseException e) {
e.printStackTrace(); } } private String toStr(Date date) {
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.US);
return df.format(date);
} private Date toDate(String timeStr) throws ParseException {
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss", Locale.US);
return df.parse(timeStr);
} private long timeDiff(String time1, String time2) throws ParseException {
Date d1 = toDate(time1);
Date d2 = toDate(time2);
return d1.getTime() - d2.getTime(); } private long timeDiff(Date time1, Date time2) throws ParseException { return time1.getTime() - time2.getTime(); } } public static void main(String[] args) throws Exception {
int run = ToolRunner.run(new Configuration(), new ClickStreamPageView(), args);
System.exit(run);
}
}
生成如下数据

点击流模型visit信息表
注:“一次访问”=“N次连续请求”
直接从原始数据中用hql语法得出每个人的“次”访问信息比较困难,可先用mapreduce程序分析原始数据得出“次”信息数据,然后再用hql进行更多维度统计package cn.itcast.bigdata.weblog.clickstream; import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator; import cn.itcast.bigdata.weblog.utils.DateUtil;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import cn.itcast.bigdata.weblog.mrbean.PageViewsBean;
import cn.itcast.bigdata.weblog.mrbean.VisitBean;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; /**
* 输入数据:pageviews模型结果数据
* 从pageviews模型结果数据中进一步梳理出visit模型
* sessionid start-time out-time start-page out-page pagecounts ......
*
* @author
*
*/
public class ClickStreamVisit extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
Configuration conf = super.getConf();
Job job = Job.getInstance(conf);
/*String inputPath = "hdfs://node01:9000/weblog/"+ DateUtil.getYestDate() + "/pageViewOut";
String outPutPath="hdfs://node01:9000/weblog/"+ DateUtil.getYestDate() + "/clickStreamVisit";
FileSystem fileSystem = FileSystem.get(new URI("hdfs://node01:9000"),conf);
if (fileSystem.exists(new Path(outPutPath))){
fileSystem.delete(new Path(outPutPath),true);
}
fileSystem.close();
FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outPutPath));
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);*/ job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextInputFormat.addInputPath(job,new Path("file:////Users/zhaozhuang/Desktop/8.大数据离线第八天/日志文件数据/pageViewOut"));
TextOutputFormat.setOutputPath(job,new Path("file:////Users/zhaozhuang/Desktop/8.大数据离线第八天/日志文件数据/clickStreamVisit")); job.setJarByClass(ClickStreamVisit.class);
job.setMapperClass(ClickStreamVisitMapper.class);
job.setReducerClass(ClickStreamVisitReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(PageViewsBean.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(VisitBean.class);
boolean res = job.waitForCompletion(true);
return res?0:1;
} // 以session作为key,发送数据到reducer
static class ClickStreamVisitMapper extends Mapper<LongWritable, Text, Text, PageViewsBean> { PageViewsBean pvBean = new PageViewsBean();
Text k = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString();
String[] fields = line.split("\001");
int step = Integer.parseInt(fields[5]);
//(String session, String remote_addr, String timestr, String request, int step, String staylong, String referal, String useragent, String bytes_send, String status)
//299d6b78-9571-4fa9-bcc2-f2567c46df3472.46.128.140-2013-09-18 07:58:50/hadoop-zookeeper-intro/160"https://www.google.com/""Mozilla/5.0"14722200
pvBean.set(fields[0], fields[1], fields[2], fields[3],fields[4], step, fields[6], fields[7], fields[8], fields[9]);
k.set(pvBean.getSession());
context.write(k, pvBean); } } static class ClickStreamVisitReducer extends Reducer<Text, PageViewsBean, NullWritable, VisitBean> { @Override
protected void reduce(Text session, Iterable<PageViewsBean> pvBeans, Context context) throws IOException, InterruptedException { // 将pvBeans按照step排序
ArrayList<PageViewsBean> pvBeansList = new ArrayList<PageViewsBean>();
for (PageViewsBean pvBean : pvBeans) {
PageViewsBean bean = new PageViewsBean();
try {
BeanUtils.copyProperties(bean, pvBean);
pvBeansList.add(bean);
} catch (Exception e) {
e.printStackTrace();
}
} Collections.sort(pvBeansList, new Comparator<PageViewsBean>() {
@Override
public int compare(PageViewsBean o1, PageViewsBean o2) {
return o1.getStep() > o2.getStep() ? 1 : -1;
}
}); // 取这次visit的首尾pageview记录,将数据放入VisitBean中
VisitBean visitBean = new VisitBean();
// 取visit的首记录
visitBean.setInPage(pvBeansList.get(0).getRequest());
visitBean.setInTime(pvBeansList.get(0).getTimestr());
// 取visit的尾记录
visitBean.setOutPage(pvBeansList.get(pvBeansList.size() - 1).getRequest());
visitBean.setOutTime(pvBeansList.get(pvBeansList.size() - 1).getTimestr());
// visit访问的页面数
visitBean.setPageVisits(pvBeansList.size());
// 来访者的ip
visitBean.setRemote_addr(pvBeansList.get(0).getRemote_addr());
// 本次visit的referal
visitBean.setReferal(pvBeansList.get(0).getReferal());
visitBean.setSession(session.toString());
context.write(NullWritable.get(), visitBean);
}
} public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(),new ClickStreamVisit(),args);
} }生成如下数据

【Hadoop离线基础总结】网站流量日志数据分析系统的更多相关文章
- 【Hadoop离线基础总结】流量日志分析网站整体架构模块开发
目录 数据仓库设计 维度建模概述 维度建模的三种模式 本项目中数据仓库的设计 ETL开发 创建ODS层数据表 导入ODS层数据 生成ODS层明细宽表 统计分析开发 流量分析 受访分析 访客visit分 ...
- 【Hadoop离线基础总结】Hue的简单介绍和安装部署
目录 Hue的简单介绍 概述 核心功能 安装部署 下载Hue的压缩包并上传到linux解压 编译安装启动 启动Hue进程 hue与其他框架的集成 Hue与Hadoop集成 Hue与Hive集成 Hue ...
- 【Hadoop离线基础总结】impala简单介绍及安装部署
目录 impala的简单介绍 概述 优点 缺点 impala和Hive的关系 impala如何和CDH一起工作 impala的架构及查询计划 impala/hive/spark 对比 impala的安 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- 【Hadoop离线基础总结】Sqoop常用命令及参数
目录 常用命令 常用公用参数 公用参数:数据库连接 公用参数:import 公用参数:export 公用参数:hive 常用命令&参数 从关系表导入--import 导出到关系表--expor ...
- 【Hadoop离线基础总结】Hive调优手段
Hive调优手段 最常用的调优手段 Fetch抓取 MapJoin 分区裁剪 列裁剪 控制map个数以及reduce个数 JVM重用 数据压缩 Fetch的抓取 出现原因 Hive中对某些情况的查询不 ...
- 【Hadoop离线基础总结】MapReduce增强(上)
MapReduce增强 MapReduce的分区与reduceTask的数量 概述 MapReduce当中的分区:物以类聚,人以群分.相同key的数据,去往同一个reduce. ReduceTask的 ...
- 【Hadoop离线基础总结】工作流调度器azkaban
目录 Azkaban概述 工作流调度系统的作用 工作流调度系统的实现 常见工作流调度工具对比 Azkaban简单介绍 安装部署 Azkaban的编译 azkaban单服务模式安装与使用 azkaban ...
- 【Hadoop离线基础总结】MapReduce 社交粉丝数据分析 求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
MapReduce 社交粉丝数据分析 求出哪些人两两之间有共同好友,及他俩的共同好友都有谁? 用户及好友数据 A:B,C,D,F,E,O B:A,C,E,K C:F,A,D,I D:A,E,F,L E ...
随机推荐
- Threejs从入门到入门
前言threejs官网:https://threejs.org/ github各个版本:https://github.com/mrdoob/three.js/tags 版本更迭很快,我用的时候还是r9 ...
- 原创hadoop2.6.4 namenode HA+Federation集群高可用部署
今天下午刚刚搭建了一个高可用hadoop集群,整理如下,希望大家能够喜欢. namenode HA:得有两个节点,构成一个namenode HA集群 namenode Federation:可以有 ...
- Docker常用命令--ps/attach/run
ps查看container 若查看正在运行的container docker ps 查看所有的container docker ps -a run启动容器 第一次启动container docker ...
- calculator.py
代码如下: #计算器类 class Count: def __init__(self, a, b): self.a = int(a) self.b = int(b) #计算器加法 def add(se ...
- pytorch 中的LSTM模块
- Apache漏洞利用与安全加固实例分析
Apache 作为Web应用的载体,一旦出现安全问题,那么运行在其上的Web应用的安全也无法得到保障,所以,研究Apache的漏洞与安全性非常有意义.本文将结合实例来谈谈针对Apache的漏洞利用和安 ...
- php下载各种编辑器输出的内容到word中展示
<?php/** * Created by PhpStorm. * User: 工作 * Date: 2018/1/11 * Time: 12:02 */ //连接数据库$dsn = " ...
- docker(2)
docker三大核心组件的概念 1镜像: Docker 镜像类似于虚拟机镜像,可以将它理解为一个只读的模板.例如,一个镜像可以包含一个基本的操作系统环境,里面仅安装了 Apache 应用程序(或用户需 ...
- Scala教程之:面向对象的scala
文章目录 面向对象的scala Unified Types Classes Traits 面向对象的scala 我们知道Scala是一种JVM语言,可以合java无缝衔接,这也就大大的扩展了scala ...
- Tomcat实现Session复制
Tomcat实现Session复制 需要三台虚拟机一台Nginx两台Tomcat 关闭相关的安全机制 systemctl stop firewalldiptables -Fsetenforce 0 首 ...