Impala 笔记
简介
Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
基于Hive使用内存计算,兼顾数据仓库、具有实时、批处理、多并发等优点
是CDH平台首选的PB级大数据实时查询分析引擎
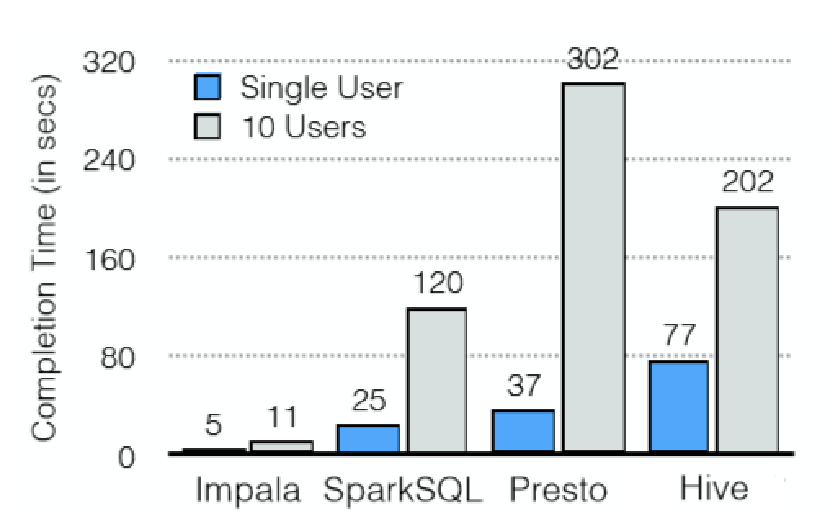
Impala 优势
基于内存进行计算, 能够对 PB 级数据进行交互式实时查询、分析
无需转换为MR, 直接读取HDFS数据
C++ 编写, LLVM统一编译运行
兼容 HiveSQL
具有数据仓库的特性, 可对hive数据直接做数据分析
支持Data Local
支持列式存储
支持JDBC / ODBC 远程访问
Impala 劣势
对内存依赖大
cpp编写, 非大佬比较难以改源码
完全依赖于hive
实践过程中, 分区超过1w 性能严重下降
稳定性不如 hive
安装方式
ClouderaManager
手动安装
核心组件
Statestore Daemon
example*1 - statestored
负责收集分布在集群中各个impalad进程的资源信息、各节点健康状况,同步节点信息.
负责query的调度
Catalog Daemon
example*2 - catalogd
分发表的元数据信息到各个impalad中
接收来自statestore的所有请求
Impala Daemon
example*N - impalad
接收client、hue、jdbc或者odbc请求、Query执行并返回给中心协调节点
子节点上的守护进程,负责向statestore保持通信,汇报工作
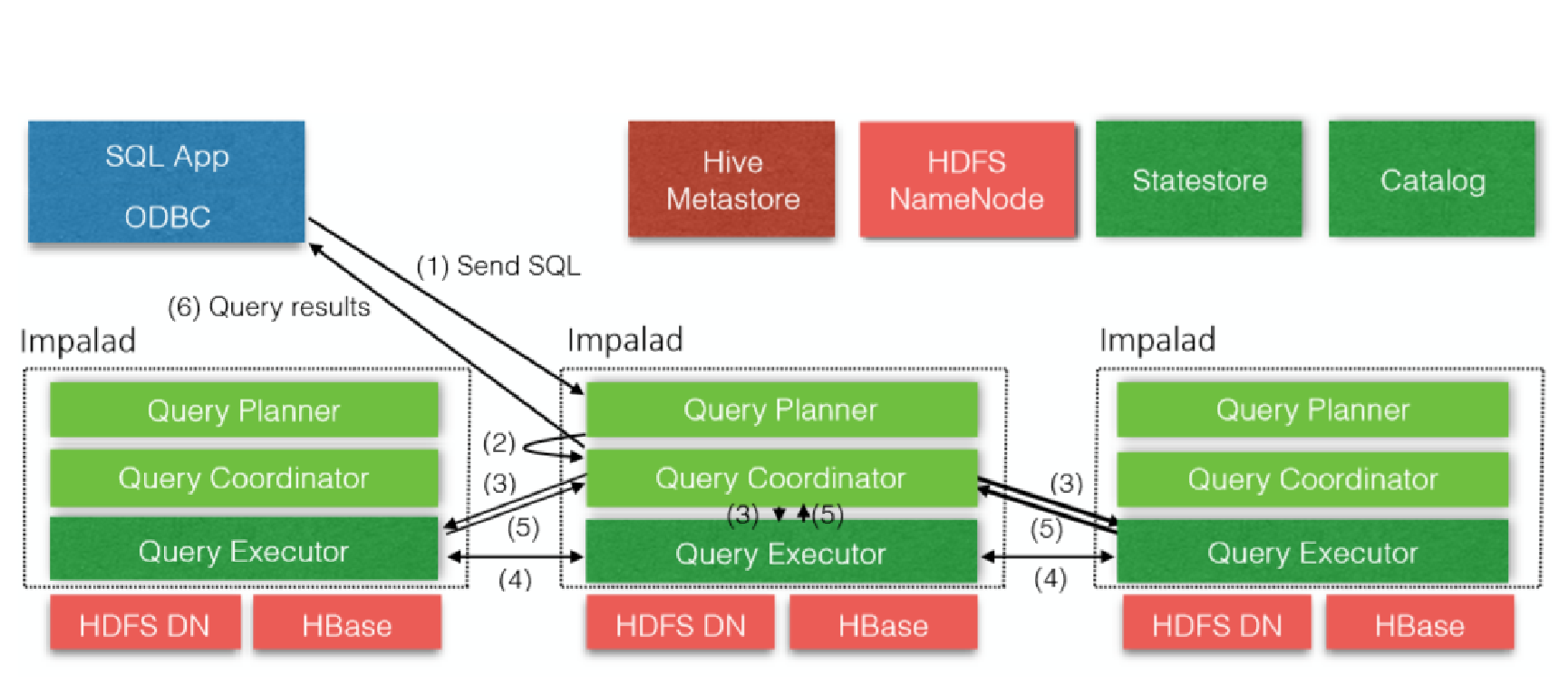
Impala 架构
Impala Shell
外部命令:
-h(--help)帮助
-v(--version)查询版本信息
-V(--verbose)启用详细输出
--quiet 关闭详细输出
-p 显示执行计划
-i hostname(--impalad=hostname) 指定连接主机 格式hostname:port 默认端口21000
-r(--refresh_after_connect)刷新所有元数据
-q query(--query=query)从命令行执行查询,不进入impala-shell
-d default_db(--database=default_db)指定数据库
-B(--delimited)去格式化输出
- --output_delimiter=character 指定分隔符
- --print_header 打印列名
-f query_file(--query_file=query_file)执行查询文件,以分号分隔
-o filename(--output_file filename)结果输出到指定文件
-c 查询执行失败时继续执行
-k(--kerberos) 使用kerberos安全加密方式运行impala-shell
-l 启用LDAP认证
-u 启用LDAP时,指定用户名
特殊用法[内部命令]:
help
connect < hostname:port > 连接主机,默认端口21000
refresh 增量刷新元数据库
invalidate metadata 全量刷新元数据库
explain 显示查询执行计划、步骤信息
- set explain_level 设置显示级别(0,1,2,3)
shell 不退出impala-shell执行Linux命令
profile (查询完成后执行) 查询最近一次查询的底层信息
Impala 监控管理
查看StateStore
查看Catalog
Impala 存储 && 分区
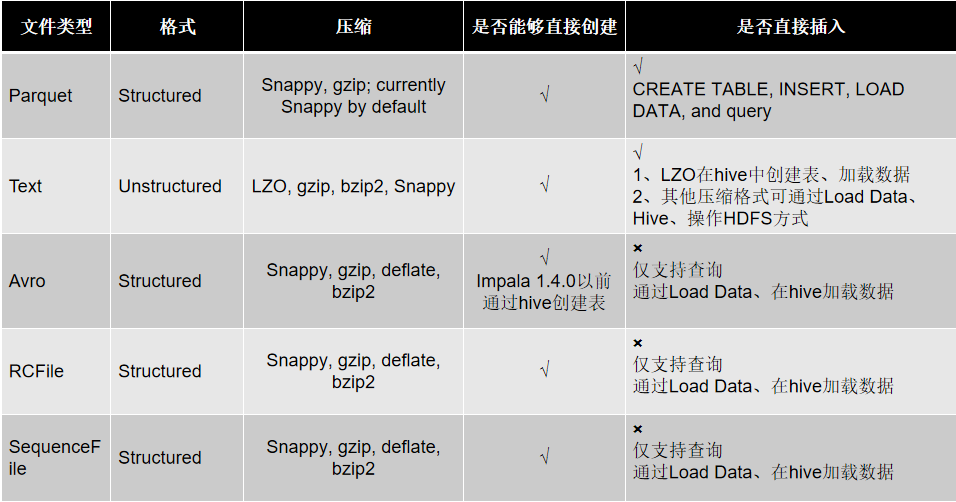
压缩方式

添加分区方式
partitioned by 创建表时,添加该字段指定分区列表
使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string);
alter table t_person add partition (sex='man');
alter table t_person drop partition (sex='man');
alter table t_person drop partition (sex='man',type='boss');
分区内添加数据
insert into t_person partition (type='boss') values (1,’gaben’,18),(2,’newell’,23);
insert into t_person partition (type='coder') values (3,Jeep Barnett’,22),(4,’David Nasbeth’,28),(5,’John McDonald’,24);
查询指定分区数据
select id,name from t_person where type='coder'
Impala SQL
支持数据类型
- INT
- TINYINT
- SMALLINT
- BIGINT
- BOOLEAN
- CHAR
- VARCHAR
- STRING
- FLOAT
- DOUBLE
- REAL
- DECIMAL
- TIMESTAMP
CDH5.5版本后支持以下类型
- ARRAY
- MAP
- STRUCT
- Complex (复数?)
Impala不支持 HiveQL以下特性:
可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes
XML、JSON函数
某些聚合函数:
- covar_pop, covar_samp, corr, percentile, percentile_approx, histogram_numeric, collect_set
- Impala仅支持:AVG,COUNT,MAX,MIN,SUM
多Distinct查询
UDF、UDAF
以下语句:
ANALYZE TABLE (Impala:COMPUTE STATS)、DESCRIBE COLUMN、DESCRIBE DATABASE、EXPORT TABLE、IMPORT TABLE、SHOW TABLE EXTENDED、SHOW INDEXES、SHOW COLUMNS、
创建数据库
create database db1;
use db1;
删除数据库
use default;
drop database db1;
```
创建表(内部表)
默认方式创建表:
create table t_person1(
id int,
name string
)
指定存储方式:
create table t_person2(
id int,
name string
)
row format delimited
fields terminated by '\0'
stored as textfile
-- (impala1.3.1版本以上支持‘\0’ )
其他方式创建内部表
- 使用现有表结构:
create table tab_3 like tab_1;
指定文本表字段分隔符:
alter table tab_3 set serdeproperties ('serialization.format'=',','field.delim’=',');
```插入数据
- 直接插入值方式:
insert into t_person values (1,hex(‘hello world’));
- 从其他表插入数据:
insert (overwrite) into tab_3 select * from tab_2 ;
- 批量导入文件方式方式:
load data local inpath '/xxx/xxx' into table tab_1;
创建表(外部表)
默认方式创建表:
create external table tab_p1(
id int,
name string
)
location '/user/xxx.txt'
指定存储方式:
create external table tab_p2 like parquet_tab
'/user/xxx/xxx/1.dat'
partition (year int , month tinyint, day tinyint)
location '/user/xxx/xxx'
stored as parquet;视图
创建视图:
create view v1 as select count(id) as total from tab_3;
查询视图:
select * from v1;
查看视图定义:
describe formatted v1;
注意
- 不能向impala的视图进行插入操作
- insert 表可以来自视图
数据文件处理
加载数据:
insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式加载批量数据
load data方式:在进行批量插入时使用这种方式比较合适
来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。
空值处理:
- impala将“\n”表示为NULL,在结合sqoop使用是注意做相应的空字段过滤,
- 也可以使用以下方式进行处理:
- alter table name set tblproperties (“serialization.null.format”=“null”)
Impala Hbase 整合
- Impala可以通过Hive外部表方式和HBase进行整合,步骤如下:
- 步骤1:创建hbase 表,向表中添加数据
```sql
create 'test_info', 'info'
put 'test_info','1','info:name','john'
put 'test_info','2','info:name','ronnie';
```
- 步骤2:创建hive表
```sql
CREATE EXTERNAL TABLE test_info(key string,name string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:name")
TBLPROPERTIES
("hbase.table.name" = "test_info");
```
- 步骤3:刷新Impala表
```sql
invalidate metadata
```
Impala JDBC
配置:
impala.driver=org.apache.hive.jdbc.HiveDriver
impala.url=jdbc:hivex://nodex:21050/;auth=noSasl
impala.username=
impala.password=
尽量使用PreparedStatement执行SQL语句
性能上PreparedStatement要好于Statement
Statement存在查询不出数据的情况
Impala 性能优化
执行计划
查询sql执行之前,先对该sql做一个分析,列出需要完成这一项查询的详细方案
命令:explain sql、profile
explain select count(name) from t_person;
要点:
- SQL优化,使用之前调用执行计划
- 选择合适的文件格式进行存储
- 避免产生很多小文件(如果有其他程序产生的小文件,可以使用中间表)
- 使用合适的分区技术,根据分区粒度测算
- 使用compute stats table_name进行表信息搜集
- 网络io的优化:
- 避免把整个数据发送到客户端
- 尽可能的做条件过滤
- 使用limit字句
- 输出文件时,避免使用美化输出
- 使用profile输出底层信息计划,在做相应环境优化
Impala 笔记的更多相关文章
- Impala笔记之通用命令
help help命令用于查询其它命令的用法 [quickstart.cloudera:21000] > help select; Executes a SELECT... query, fet ...
- impala学习笔记
impala学习笔记 -- 建库 CREATE DATABASE IF NOT EXISTS database_name; -- 在HDFS文件系统中创建数据库,需要指定要创建数据库的位置. CREA ...
- Impala入门笔记
From:http://tech.uc.cn/?p=817 问题背景: 初步了解Impala的应用 重点测试Impala的查询速度是否真的如传说中的比Hive快3~30倍 写作目的: 了解Impala ...
- impala安装笔记(Ubuntu)
1.Override 1.With Impala, you can query data, whether stored in HDFS or Apache HBase – including SEL ...
- Impala 安装笔记3一impala安装
安装impala之前,确认满足Cloudera Impala Requirements中要求的所有条件: Supported Operating Systems Supported CDH Versi ...
- Impala 安装笔记1一Cloudera CDH4.3.0安装
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库 ...
- Impala ODBC 安装笔记
Impala在线文档介绍了 Impala ODBC接口安装和配置 http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH5 ...
- Impala 安装笔记2一hive和mysql安装
l 安装hive,hive-metastore hive-server $ sudo yum install hive hive-metastore hive-server l 安装mysql ...
- Hadoop-Impala学习笔记之入门
CDH quickstart vm包含了单节点的全套hadoop服务生态,可从https://www.cloudera.com/downloads/quickstart_vms/5-13.html下载 ...
随机推荐
- 使用Vue.js 和Chart.js制作绚丽多彩的图表
前言 深入学习 chart.js 的选项来制作漂亮的图表.交互式图表可以给你的数据可视化提供很酷的展示方式.但是大多数开箱即用的解决方案用默认的选项并不能做出很绚丽的图表. 这篇文章中,我会教你如何自 ...
- Android开发_*.R文件无法自动生成
问题描述: 今天是我决定专注Android开发的第一天,我在网上下载了一个数独游戏的源码,准备开始着手学习.在导入之后出现Java文件中import *.R文件报错,在gen目 ...
- 【剑指Offer面试编程题】题目1348:数组中的逆序对--九度OJ
题目描述: 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对.输入一个数组,求出这个数组中的逆序对的总数. 输入: 每个测试案例包括两行: 第一行包含一个整数n,表示数组 ...
- java学习-初级入门-面向对象①-面向对象概述-结构化程序设计
为了学习面向对象程序设计,今天我们先利用面向对象以前的知识,设计一个学生类. 要求进行结构化程序设计. 学生类: Student 要求:存储学生的基本信息(姓名.性别.学历层次和年级),实现学生信息的 ...
- Day3-K-Can you solve this equation? HDU2199
Now,given the equation 8*x^4 + 7*x^3 + 2*x^2 + 3*x + 6 == Y,can you find its solution between 0 and ...
- 「AT2292」Division into Two
传送门 Luogu 解题思路 考虑如何 \(\text{DP}\) 为了方便处理,我们设 \(A > B\) 设 \(dp[i]\) 表示处理完 \(1...i\) ,并且第 \(i\) 个数放 ...
- 手写MQ框架(四)-使用netty改造梳理
一.背景 书接上文手写MQ框架(三)-客户端实现,前面通过web的形式实现了mq的服务端和客户端,现在计划使用netty来改造一下.前段时间学习了一下netty的使用(https://www.w3cs ...
- JavaScript 标识符,关键字和保留字
JavaScript 标识符,关键字和保留字 标识符 标识符(Identifier)就是名称的专业术语.JavaScript 标识符包括变量名.函数名.参数名和属性名. 合法的标识符应该注意以下强制规 ...
- Codestorm:Game with a Boomerang
题目连接:https://www.hackerrank.com/contests/codestorm/challenges/game-with-a-boomerang 上一篇博客不知怎么复制过来题目, ...
- 51nod 1433:0和5
1433 0和5 题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 10 难度:2级算法题 收藏 取消关注 小K手中有n张牌,每张牌上有一个一位数的数, ...