K均值聚类算法
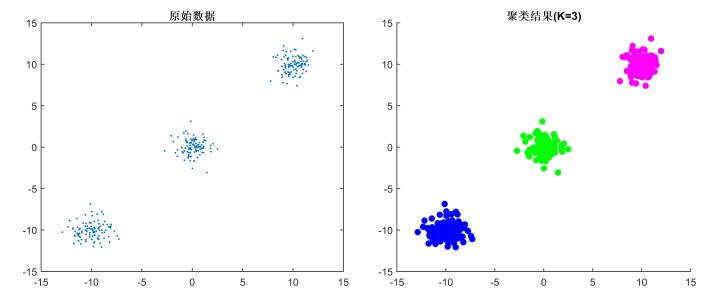
定义
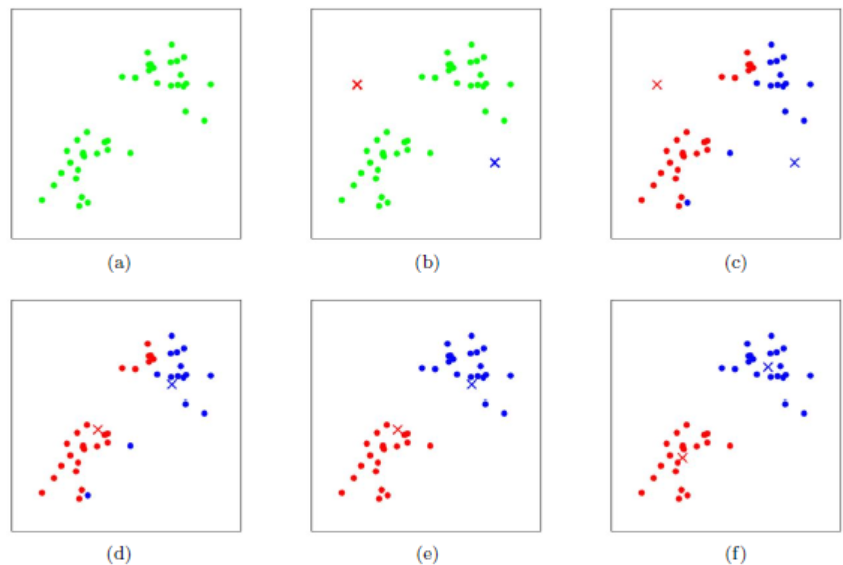
算法
K-Means的优缺点
优点:
1、原理比较简单,实现也是很容易,收敛速度快。
2、当结果簇是密集的,而簇与簇之间区别明显时, 它的效果较好。
3、主要需要调参的参数仅仅是簇数k。
缺点:
1、K值需要预先给定,很多情况下K值的估计是非常困难的。
2、K-Means算法对初始选取的质心点是敏感的,不同的随机种子点得到的聚类结果完全不同 ,对结果影响很大。
3、对噪音和异常点比较的敏感。用来检测异常值。
4、采用迭代方法,可能只能得到局部的最优解,而无法得到全局的最优解。
K均值聚类算法的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 机器学习实战5:k-means聚类:二分k均值聚类+地理位置聚簇实例
k-均值聚类是非监督学习的一种,输入必须指定聚簇中心个数k.k均值是基于相似度的聚类,为没有标签的一簇实例分为一类. 一 经典的k-均值聚类 思路: 1 随机创建k个质心(k必须指定,二维的很容易确定 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
- 机器学习之K均值聚类
聚类的核心概念是相似度或距离,有很多相似度或距离的方法,比如欧式距离.马氏距离.相关系数.余弦定理.层次聚类和K均值聚类等 1. K均值聚类思想 K均值聚类的基本思想是,通过迭代的方法寻找K个 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
随机推荐
- vb.net自学完整版
https://m.book118.com/html/2016/1203/67671992.shtm
- video-player
1. VLC 2. MPlayer 3. FFmpeg 4. 显示媒体信息 5. 视频播放器软件比较 1. VLC https://www.videolan.org/vlc/ https://en.w ...
- 前端学习笔记系列一:2 Vue的单文件组件
(1)非单文件vue组件和单文件vue组件的一般写法 一个完整的vue组件会包括三个部分:一是template模板部分,二是js程序逻辑部分,三是css样式部分.每个组件都有属于自己的模板,js和样式 ...
- super關鍵字
super 关键字 我们知道,this关键字总是指向函数所在的当前对象,ES6 又新增了另一个类似的关键字super,指向当前对象的原型对象. const proto = { foo: 'hello' ...
- SciPy 教程
章节 SciPy 介绍 SciPy 安装 SciPy 基础功能 SciPy 特殊函数 SciPy k均值聚类 SciPy 常量 SciPy fftpack(傅里叶变换) SciPy 积分 SciPy ...
- ubi问题总结
一.挂载成功后,使用正常.有时会出现:UBIFS error (pid 76): ubifs_read_node: bad node type (255 but expected 1)UBIFS er ...
- 实验吧——Recursive
环境:win10,kali虚拟机 工具:ida 虚拟机打开看看,发现是ELF文件,运行一下,额没有什么发现. Ida打开看看,发现是在文件内部运行python解释器,百度搜索了一个基本上可以找到Py_ ...
- VUE - vue.runtime.esm.js?6e6d:619 [Vue warn]: Do not use built-in or reserved HTML elements as component i
<script> export default { name:'header' // 不要使用内置或保留的HTML元素 , 改为Header或者置或保留的HTML元素 ...
- 用JS写一个网站树形菜单
先上效果图: 主体内容就是侧边展示的一二三级菜单,树形结构的. 前端页面布局内容,页面内容简单用ul li 来完成所有的罗列项.用先后顺序来区分一级二级三级: <body> <b&g ...
- Day5 - D - Conscription POJ - 3723
Windy has a country, and he wants to build an army to protect his country. He has picked up N girls ...