大数据萌新的Python学习之路(三)
笔记内容:

一、集合及其运算
在之列表中我们可以存储数据,并且对数据进行各种各样的操作。但是如果我们想要对数据进行去重时是十分麻烦的,需要使用循环,要建立新的列表,还要
进行对比,十分的麻烦,还消耗内存,所以我们在编程过程中就要使用集合。
Python中的集合和数学中的集合是一样的,也存在交并补的运算。集合的所有数据用花括号括起来,每个数据用逗号分隔。
我们可以来建立一个集合或者建立之后的列表通过set()来进行转换成集合。
set_1 = {1,5,15,25,48,78,44}
list_1 = [2,15,5,98,23,28]
set_2 = set(list_1)
print(set_1)
print(set_2)
输出结果:
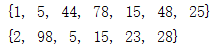
我们建立了一个名为set_1的集合,名为list_1的列表,但是输出结果都是集合的形式,这是因为我们set_1是我们直接建立的集合,而set_2是我们通过set()用列表来转化而来的集合。集合中的数据也是和字典一样无序的,不能通过索引来存取数据。
set_1与set_2的两组数据之间是有重复的数据的5和15,那么如果我们想要把重复的数据取出来是,在数学中的做法是取交集,在Python中也是如此,像这样进行集合运算的操作叫做关系测试。
交集:
set_1 = {1,5,15,25,48,78,44}
set_2 = set([2,15,5,98,23,28])
print(set_2.intersection(set_1)) #交集
输出结果:
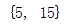
并集:
set_1 = {1,5,15,25,48,78,44}
set_2 = set([2,15,5,98,23,28])
print(set_2.union(set_1)) #并集
输出结果:
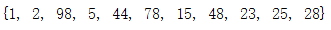
差集:
set_1 = {1,5,15,25,48,78,44}
set_2 = set([2,15,5,98,23,28])
print(set_2.difference(set_1)) #差集
输出结果:
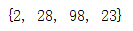
差集求的是set_2中有set_1中没有的数据。同时也可以反过来取。
子父集判断:
set_1 = {1,5,15,25,48,78,44}
set_2 = set([2,15,5,98,23,28])
set_3 = {5,15}
print(set_2.issubset(set_1)) #子集判断
print(set_2.issuperset(set_1)) #父集判断
print(set_3.issubset(set_2))
print(set_2.issuperset(set_3))
输出结果:
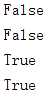
对称差集:
set_1 = {1,5,15,25,48,78,44}
set_2 = set([2,15,5,98,23,28])
set_3 = {5,15}
print(set_2.symmetric_difference(set_1)) #对称差集
输出结果:
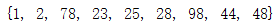
对称差集取出的是两组数据中不重复的数据,把两组数据的交集去除掉的一个集合。
我们进行关系测试不仅可以通过函数来求,还可以通过符号来进行运算。
set_1 = {1,5,15,25,48,78,44}
set_2 = set([2,15,5,98,23,28])
set_3 = set_1 | set_2 #并集
set_4 = set_1 & set_2 #交集
set_5 = set_1 - set_2 #差集
set_6 = set_1 ^ set_2 #对称差集
print(set_3)
print(set_4)
print(set_5)
print(set_6)
我们不仅可以对集合进行关系测试,同时同时还可以对集合进行添加,删除等操作。
set_1 = {1,5,15,25,48,78,44}
set_1.add(66)
print(set_1)
输出结果:
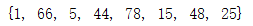
通过.add()来对集合进行添加数据元素。我们可以看到添加的数据没有添加到最后面,这正是因为集合中的元素是无序的。
在集合中不仅可以添加一个元素还可以同时添加多个元素
set_1 = {1,5,15,25,48,78,44}
set_1.update([66,88,99])
print(set_1)
输出结果:
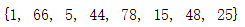
对个数据就组成了一个列表,添加 多个数据就相当于把一个列表添加到集合中。
对于删除数据元素我们使用.remove()来对数据进行删除操作。
set_1 = {1,5,15,25,48,78,44}
set_1.remove(1)
print(set_1)
输出结果:
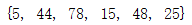
在检测一个数据元素是否在集合中的时候我们可以使用x in s或者x not in s,这两个语句来检测,同时在集合中也有浅复制.copy()。
二、文件操作
在写程序的时候我们常常会对文件进行操作,所以文件操作一定要熟练掌握。
在windows下如果我们想要对一个txt文件进行操作的时候分为三步:1.找到文件 2.打开文件 3.操作文件 4.关闭文件
而在Python中也是大同小异,打开操作关闭。
我们在.py文件的同文件夹下建立一个名为A_Memorable_Day的TXT文件。
谁都无法命令激越的心灵
谁都无法扑灭情感的火焰
如若上苍将你赐予了我
我就是世界上最幸福的人
多么美好
这难忘的一天
多么美好
这难忘的一天
你是我梦中情人
你是我黎明之光
是百般呵护的恋人
是千般宠爱的姑娘
是千般宠爱的姑娘
data = open("A_Memorable_Day",encoding="utf-8").read()
print(data)
上述代码会将文件内容都打印出来。在Python中我们通过open()来打开文件,通过.read()来读取文件,在open()中有的参数分别是文件名和文件路径,还有一个是编码方式。当打开这个文件后使用.read()来读取它并赋值给data。这个encoding = "utf-8"是告诉系统应该使用utf-8的编码方式来输出,如果不告诉系统使用什么方式来编码的话,windows默认为gbk,而Python的编码方式是utf-8。

这就是没有指定编码方式的报错。
打开的文件我们不仅仅是只可以进行读操作,还可以进行修改,添加等等的一系列操作,所以我们就要把这个打开的文件赋给一个变量,我们对这个变量进行操作我们默认这个变量为f。
f = open("A_Memorable_Day",encoding="utf-8")
这个就是我们把打开的文件赋予f变量,我们后续就可以通过这个变量找到文件地址,并对文件进行操作。这个语句赋给f的是一个内存对象同时也被称为称为:文件句柄
我们可以看一下这个f的数据类型。
f = open("A_Memorable_Day",encoding="utf-8")
print(type(f))
输出结果:
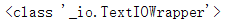
我们就可以看到这个f的数据类型是一个TXT文件。
而如果我们对文件进行读操作后,就会变成字符串。
f = open("A_Memorable_Day",encoding="utf-8")
data = f.read()
data2 = f.read()
print("--------data---------\n",data)
print("--------data2---------",data2)
输出结果:

我们可以看到data和data2我们都赋予了文件句柄,但是data2却没有输出,可以说是没有,为空,这是为什么呢,这是因为在文件的操作中读文件会从头开始读,一直读到末尾。data在读文件的时候已经从头部读到末尾了,所以data2读不到文件了就好像有一个光标一样,data已经把光标从头挪到了末尾,所以在第二次读的时候光标不会自己再回到头部,而在末尾读不到任何数据。那么想要再读一遍的话就要把这个光标挪回头部。
有时光标不一定在末尾,那么我们就要确定位置
f = open("A_Memorable_Day", encoding="utf-8")
print(f.tell())
在没对文件进行任何操作的时候我们会得到0,但是如果有操作的话就会显示其他数字,这个数字的意思不是行而是字节数,也就是说在光标前面有多少字节。
假如我们把文件都读了一遍光标在最末尾,我们想要把光标移动到最前端要用seek()
f = open("A_Memorable_Day", encoding="utf-8")
print(f.read(11))
print(f.tell())
print(f.seek(0))
print(f.tell())
输出结果:

既然有读文件那么就可以写文件,读是read写就是write。
f = open("A_Memorable_Day",encoding="utf-8")
data = f.read()
f.write('是千般宠爱的姑娘~~~~~')
print(data)
这样写是错误的,因为再文件句柄中我们要传递参数,以什么方式打开,在读文件的时候我们并没有指定模式,这是因为默认为读模式。
f = open("A_Memorable_Day",'w',encoding="utf-8")
data = f.write('是千般宠爱的姑娘~~~~~')
这样我们就可以把新的内容写入到文件中,但是我们如果去翻看这个文件的时候会发现我们之前的内容消失了,不见了,这是因为这个w写模式,是重新创建一个文件和之前创建的文件同名就会把之前的内容给冲掉。如果我们想要在文件中写新的内容的时候是追加a。
f = open("A_Memorable_Day",'a',encoding="utf-8")
data = f.write('是千般宠爱的姑娘~~~~~')
我们将这句话追加到文件夹中:

为了整齐我们可以在追加的时候加上回车换行'\n'。
在读模式中我们只能读全部文件,要单独读某一行或者某几行就要用readline()。
f = open("A_Memorable_Day",encoding="utf-8")
print(f.readline())
print(f.readline())
print(f.readline())
print(f.readline())
print(f.readline())
输出结果:

我们通过readline()读出了前五行,但是我们要避免重复的书写代码,就可是使用循环来输出前五行。
f = open("A_Memorable_Day",encoding="utf-8")
for i in range(5):
print(f.readline())
除了循环,也可以使用其他方法来实现输出。我们发现还有一个函数是readlines(),它会把每一行的内容变为列表的元素存到列表中。
f = open("A_Memorable_Day",encoding="utf-8")
print(f.readlines())
输出内容:['谁都无法命令激越的心灵\n', '谁都无法扑灭情感的火焰\n', '如若上苍将你赐予了我\n', '我就是世界上最幸福的人\n', '多么美好\n', '这难忘的一天\n', '多么美好\n', '这难忘的一天\n', '你是我梦中情人\n', '你是我黎明之光\n', '是百般呵护的恋人\n', '是千般宠爱的姑娘\n', '是千般宠爱的姑娘是千般宠爱的姑娘~~~~~']
我们看到每一行都是列表中的一个元素。这样我们就可以对列表进行操作来对文件操作。
f = open("A_Memorable_Day",encoding="utf-8")
for line in f.readlines():
print(line,end = '')
通过for循环我们就可以打印文件,打印前五行的话可以使用index来进行索引判断。
f = open("A_Memorable_Day",encoding="utf-8")
for index,line in enumerate(f.readlines()):
if index < 5:
print(line, end='')
这样就可以打印前五行或者任意行,只需要对索引进行控制即可。
readlines()只适合对小文件进行操作,这是因为readlines在读文件的时候会生成一个列表,这个列表存放在内存中,如果这个文件有10G的话那么内存是有可能被撑爆的所以readlines()对大文件操作是不现实的。
所以我们要一行一行的读内存中始终只有一行数据,读一行删除一行,代码很简单。
f = open("A_Memorable_Day", encoding="utf-8")
for line in f:
print(line, end='')
这样就是一行一行的读,也是循环。但是效率明显比上一个要好很多,但是在这个时候已经不是列表的形式了,无法通过索引来取出数据,所以就要使用计数器来控制。
f = open("A_Memorable_Day", encoding="utf-8")
count = 0
for line in f:
print(line, end='')
if count > 3:
break
count += 1
通过count来控制循环次数来实现打印多行,或者打印某行。
f.encoding
打印文件编码方式
在之前说过对文件操作的时候有几步,找到文件,打开文件,对文件进行操作,还有关闭文件。
f.close()
.close()就可以将文件关闭,切记在操作文件后要关闭文件。
你活得不快乐的原因是:既无法忍受目前的状态,又没能力改变这一切。
大数据萌新的Python学习之路(三)的更多相关文章
- 大数据萌新的Python学习之路(一)
笔记开始简介 从2018年9月份正式进入大学的时代,大数据和人工智能的崛起让我选择了计算机专业学习数据科学与大数据技术专业,接触的第一门语言就是C语言,后来因为同学推荐的原因进入了学校的人工智能研究协 ...
- 大数据萌新的Python学习之路(二)
笔记内容: 一.模块 Python越来越被广大程序员使用,越来越火爆的原因是因为Python有非常丰富和强大标准库和第三方库,几乎可以实现你所想要实现的任何功能,并且都有相应的Python库支持,比如 ...
- 读书分享全网学习资源大合集,推荐Python学习手册等三本书「01」
0.前言 在此之前,我已经为准备学习python的小白同学们准备了轻量级但超无敌的python开发利器之visio studio code使用入门系列.详见 1.PYTHON开发利器之VS Code之 ...
- CS萌新的汇编学习之路02 Learning of Assembly Language
第二节课 寄存器 1. 寄存器的定义: 进行信息储存的器件,是CPU中程序员可以读写的部件,通过改变各种寄存器中的内容来实现对CPU的控制 2. 寄存器的种类: 本节课学习通用寄存器和段寄存器 2. ...
- CS萌新的汇编学习之路(其实是老师作业呵呵哒)Learning of Assembly Language
第一节课学习汇编语言,做笔记,做笔记 1.概念 首先是汇编语言这门课程的定义以及对于学习高级语言.深入理解计算机系统的作用 软硬件接口机器语言 汇编语言 高级语言 关系 机器语言和汇编语言可移植性差 ...
- python学习之路三(文件读写)
# -*- coding: utf-8 -* ''' Created on 2013-7-29 @author: lixingle ''' import os #引入操作文件和目录的函数包 impor ...
- python学习之路 三:字符编码
本节重点 彻底掌握字符编码之前的转换关系 掌握 python2 vs python3 上编码的区别 掌握 python2 和python3 上bytes,str 的区别 补充知识点:三元运算 三元运 ...
- python学习之路-day2-pyth基础2
一. 模块初识 Python的强大之处在于他有非常丰富和强大的标准库和第三方库,第三方库存放位置:site-packages sys模块简介 导入模块 import sys 3 sys模 ...
- Python学习之路-Day2-Python基础3
Python学习之路第三天 学习内容: 1.文件操作 2.字符转编码操作 3.函数介绍 4.递归 5.函数式编程 1.文件操作 打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个 ...
随机推荐
- AOP统一日志打印处理
在日常开发工作中,我们免不了要打印很多log.而大部分需要输出的log又是重复的(例如传入参数,返回值).因此,通过AOP方式来进行日志管理可以减少很多代码量,也更加优雅. Springboot通过A ...
- ANSYS 非线性材料模型简介1 ---常用弹塑性模型
目录 1. 材料非线性 2. 三个准则 2.1 屈服准则 2.2 流动准则 2.3 强化准则 3. 常用弹塑性模型 3.1 双线性等向强化 3.2 多线性等向强化 3.3 非线性等向强化 3.4 双线 ...
- Update(Stage4):scala补充知识
1.惰性加载: 在企业的大数据开发中,有时候会编写非常复杂的SQL语句,这些SQL语句可能有几百行甚至上千行.这些SQL语句,如果直接加载到JVM中,会有很大的内存开销.如何解决? 当有一些变量保存的 ...
- 开关机安全控制!(设置进入bois的密码)
1.调整 BOIS 引导设置(1)将第一引导设备设为当前系统所在硬盘 (2)设置管理员密码 (3)进入bois后如图所示需输入bols密码才能登入
- [ DLPytorch ] 批量归一化与残差网络
批量归一化 通常来说,数据标准化预处理对于浅层模型就足够有效了.随着模型训练的进行,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化.但对深层神经网络来说,即使输入数据已做标准化,训练中模型参数的 ...
- kafka start bat
start D:\Homes\kafka_2.12-2.3.0\bin\windows\kafka-server-start.bat D:\Homes\kafka_2.12-2.3.0\config\ ...
- [IDEA] Idea复制文件到项目一直updating indices的问题
通常我们在开发JavaWeb项目的时候,都需要先将网页写好,在进行复制到web目录下,如果里面包含了很多的资源文件,就会造成一直updating indices. 方法一: 这是因为项目需要对web目 ...
- css简单整理
style1.css /*统一设置h1.h2.a标签的样式*/ h1,h2,a{ color: aqua; font-size: 50px; } /*如果h1.h2没有上面的单独设置样式那么就会继承b ...
- 浅谈CVE-2018-12613文件包含/buuojHCTF2018签到题Writeup
文件包含 蒻姬我最开始接触这个 是一道buuoj的web签到题 进入靶机,查看源代码 <!DOCTYPE html> <html lang="en"> &l ...
- Python 爬取的类封装【将来可能会改造,持续更新...】(2020年寒假小目标09)
日期:2020.02.09 博客期:148 星期日 按照要求,我来制作 Python 对外爬取类的固定部分的封装,以后在用 Python 做爬取的时候,可以直接使用此类并定义一个新函数来处理CSS选择 ...