Pandas 精简实例入门

import pandas as pd
import numpy as np
0. 案例引入
# 由np直接生成的ndarray
stock_change = np.random.normal(0, 1, (10, 8))
stock_change
array([[ 0.74057955, 0.78604657, -0.15264135, 0.05680483, 0.09388135,
0.7313751 , -1.52338443, 1.71156505],
[ 0.42204925, 0.62541715, -1.41583042, -0.27434654, 0.98587136,
-0.55797884, 0.31026482, -0.47964535],
[ 0.99741102, -0.94397298, -0.40782973, -1.33631227, -0.0124836 ,
1.1873408 , -0.25430393, -0.74264106],
[ 0.34156662, -0.40621262, 0.82861416, 0.1272128 , 1.04101412,
0.79061324, -0.60325544, 1.29954581],
[-1.23289547, 0.83789748, 1.19276989, 0.45092868, -1.7418129 ,
-0.65362211, -0.17752493, 1.87679286],
[-0.4268705 , 1.14017572, 0.18261009, -0.28947877, 0.82489897,
0.11566058, -0.53191371, -0.96065812],
[ 0.92792797, 0.26086313, 0.08316582, -0.94533007, -0.77956139,
0.23006703, -0.81971461, -1.36742474],
[ 0.82241768, 0.54201367, -0.19331564, 0.50576697, -0.42545839,
-0.24247517, -0.03526651, -0.02268451],
[ 1.67480093, -1.23265948, -2.88199942, -1.07761987, -1.37844497,
-0.13581683, 2.06013919, 1.18986057],
[ 0.60744357, 0.52348326, 0.76418263, -0.73385554, 0.54857341,
0.27310645, -0.26464179, 0.77370496]])
# 通过pd.DataFrame生成 (pd.DataFrame(ndarray))
stock_df = pd.DataFrame(stock_change)
stock_df
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 1 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 2 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 3 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| 4 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| 5 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 6 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 7 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 8 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 9 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
stock_df.shape
(10, 8)
# 添加行索引
stock_name = ['股票{}'.format(i+1) for i in range(stock_df.shape[0])]
stock_df = pd.DataFrame(data=stock_change, index=stock_name)
stock_df
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| 股票1 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 股票2 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 股票3 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 股票4 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| 股票5 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| 股票6 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 股票7 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 股票8 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 股票9 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 股票10 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
# 添加列索引
# 引入df.date_range(),start-开始日期, end: 结束日期, periods - 持续时间, frep- B:工作日, M:月, D:天
date = pd.date_range(start='2020-3-30', periods=stock_df.shape[1], freq='d')
date
DatetimeIndex(['2020-03-30', '2020-03-31', '2020-04-01', '2020-04-02',
'2020-04-03', '2020-04-04', '2020-04-05', '2020-04-06'],
dtype='datetime64[ns]', freq='D')
stock_df = pd.DataFrame(stock_change, index=stock_name, columns=date)
stock_df
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 2020-03-30 | 2020-03-31 | 2020-04-01 | 2020-04-02 | 2020-04-03 | 2020-04-04 | 2020-04-05 | 2020-04-06 | |
|---|---|---|---|---|---|---|---|---|
| 股票1 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 股票2 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 股票3 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 股票4 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| 股票5 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| 股票6 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 股票7 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 股票8 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 股票9 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 股票10 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
1. Pandas 主要数据结构
1.1 DataFrame
stock_df
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 2020-03-30 | 2020-03-31 | 2020-04-01 | 2020-04-02 | 2020-04-03 | 2020-04-04 | 2020-04-05 | 2020-04-06 | |
|---|---|---|---|---|---|---|---|---|
| 股票1 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 股票2 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 股票3 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 股票4 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| 股票5 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| 股票6 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 股票7 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 股票8 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 股票9 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 股票10 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
# 查看DataFrame形状,类似于2d array
stock_df.shape
(10, 8)
# 取行索引
stock_df.index
Index(['股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9', '股票10'], dtype='object')
# 取列索引
stock_df.columns
DatetimeIndex(['2020-03-30', '2020-03-31', '2020-04-01', '2020-04-02',
'2020-04-03', '2020-04-04', '2020-04-05', '2020-04-06'],
dtype='datetime64[ns]', freq='D')
# 取ndarray的值
stock_df.values
array([[ 0.74057955, 0.78604657, -0.15264135, 0.05680483, 0.09388135,
0.7313751 , -1.52338443, 1.71156505],
[ 0.42204925, 0.62541715, -1.41583042, -0.27434654, 0.98587136,
-0.55797884, 0.31026482, -0.47964535],
[ 0.99741102, -0.94397298, -0.40782973, -1.33631227, -0.0124836 ,
1.1873408 , -0.25430393, -0.74264106],
[ 0.34156662, -0.40621262, 0.82861416, 0.1272128 , 1.04101412,
0.79061324, -0.60325544, 1.29954581],
[-1.23289547, 0.83789748, 1.19276989, 0.45092868, -1.7418129 ,
-0.65362211, -0.17752493, 1.87679286],
[-0.4268705 , 1.14017572, 0.18261009, -0.28947877, 0.82489897,
0.11566058, -0.53191371, -0.96065812],
[ 0.92792797, 0.26086313, 0.08316582, -0.94533007, -0.77956139,
0.23006703, -0.81971461, -1.36742474],
[ 0.82241768, 0.54201367, -0.19331564, 0.50576697, -0.42545839,
-0.24247517, -0.03526651, -0.02268451],
[ 1.67480093, -1.23265948, -2.88199942, -1.07761987, -1.37844497,
-0.13581683, 2.06013919, 1.18986057],
[ 0.60744357, 0.52348326, 0.76418263, -0.73385554, 0.54857341,
0.27310645, -0.26464179, 0.77370496]])
# 取转置
stock_df.T
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 股票1 | 股票2 | 股票3 | 股票4 | 股票5 | 股票6 | 股票7 | 股票8 | 股票9 | 股票10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2020-03-30 | 0.740580 | 0.422049 | 0.997411 | 0.341567 | -1.232895 | -0.426871 | 0.927928 | 0.822418 | 1.674801 | 0.607444 |
| 2020-03-31 | 0.786047 | 0.625417 | -0.943973 | -0.406213 | 0.837897 | 1.140176 | 0.260863 | 0.542014 | -1.232659 | 0.523483 |
| 2020-04-01 | -0.152641 | -1.415830 | -0.407830 | 0.828614 | 1.192770 | 0.182610 | 0.083166 | -0.193316 | -2.881999 | 0.764183 |
| 2020-04-02 | 0.056805 | -0.274347 | -1.336312 | 0.127213 | 0.450929 | -0.289479 | -0.945330 | 0.505767 | -1.077620 | -0.733856 |
| 2020-04-03 | 0.093881 | 0.985871 | -0.012484 | 1.041014 | -1.741813 | 0.824899 | -0.779561 | -0.425458 | -1.378445 | 0.548573 |
| 2020-04-04 | 0.731375 | -0.557979 | 1.187341 | 0.790613 | -0.653622 | 0.115661 | 0.230067 | -0.242475 | -0.135817 | 0.273106 |
| 2020-04-05 | -1.523384 | 0.310265 | -0.254304 | -0.603255 | -0.177525 | -0.531914 | -0.819715 | -0.035267 | 2.060139 | -0.264642 |
| 2020-04-06 | 1.711565 | -0.479645 | -0.742641 | 1.299546 | 1.876793 | -0.960658 | -1.367425 | -0.022685 | 1.189861 | 0.773705 |
# 查看头部几行数据, 默认5行
stock_df.head(5)
# 查看倒数几行数据
stock_df.tail()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 2020-03-30 | 2020-03-31 | 2020-04-01 | 2020-04-02 | 2020-04-03 | 2020-04-04 | 2020-04-05 | 2020-04-06 | |
|---|---|---|---|---|---|---|---|---|
| 股票6 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 股票7 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 股票8 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 股票9 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 股票10 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
1.1.1 设置索引
# 只能通过对整个index 重新赋值, 整行或者整列
data_index = [['股票__{}'.format(i+1) for i in range(stock_df.shape[0])]]
stock_df.index = data_index
stock_df
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 2020-03-30 | 2020-03-31 | 2020-04-01 | 2020-04-02 | 2020-04-03 | 2020-04-04 | 2020-04-05 | 2020-04-06 | |
|---|---|---|---|---|---|---|---|---|
| 股票__1 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 股票__2 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 股票__3 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 股票__4 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| 股票__5 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| 股票__6 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 股票__7 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 股票__8 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 股票__9 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 股票__10 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
# stock_df.index[3] ='hahha'
# stock_df
1.1.2 重设索引
# reset_index在原来基础上新增一列索引
# drop=False(默认) - 不丢弃原来索引
# drop=True - 丢掉原来索引 index
stock_df.reset_index()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| level_0 | 2020-03-30 00:00:00 | 2020-03-31 00:00:00 | 2020-04-01 00:00:00 | 2020-04-02 00:00:00 | 2020-04-03 00:00:00 | 2020-04-04 00:00:00 | 2020-04-05 00:00:00 | 2020-04-06 00:00:00 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 股票__1 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 1 | 股票__2 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 2 | 股票__3 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 3 | 股票__4 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| 4 | 股票__5 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| 5 | 股票__6 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 6 | 股票__7 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 7 | 股票__8 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 8 | 股票__9 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 9 | 股票__10 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
stock_df.reset_index(drop=True)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 2020-03-30 | 2020-03-31 | 2020-04-01 | 2020-04-02 | 2020-04-03 | 2020-04-04 | 2020-04-05 | 2020-04-06 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 1 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 2 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 3 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| 4 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| 5 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 6 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 7 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 8 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 9 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
1.1.3 以某列为索引
stock_df.set_index(keys='2020-03-30', drop=False) #此处因为类型问题,都是drop 原来的index
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 2020-03-30 | 2020-03-31 | 2020-04-01 | 2020-04-02 | 2020-04-03 | 2020-04-04 | 2020-04-05 | 2020-04-06 | |
|---|---|---|---|---|---|---|---|---|
| 2020-03-30 | ||||||||
| 0.740580 | 0.740580 | 0.786047 | -0.152641 | 0.056805 | 0.093881 | 0.731375 | -1.523384 | 1.711565 |
| 0.422049 | 0.422049 | 0.625417 | -1.415830 | -0.274347 | 0.985871 | -0.557979 | 0.310265 | -0.479645 |
| 0.997411 | 0.997411 | -0.943973 | -0.407830 | -1.336312 | -0.012484 | 1.187341 | -0.254304 | -0.742641 |
| 0.341567 | 0.341567 | -0.406213 | 0.828614 | 0.127213 | 1.041014 | 0.790613 | -0.603255 | 1.299546 |
| -1.232895 | -1.232895 | 0.837897 | 1.192770 | 0.450929 | -1.741813 | -0.653622 | -0.177525 | 1.876793 |
| -0.426871 | -0.426871 | 1.140176 | 0.182610 | -0.289479 | 0.824899 | 0.115661 | -0.531914 | -0.960658 |
| 0.927928 | 0.927928 | 0.260863 | 0.083166 | -0.945330 | -0.779561 | 0.230067 | -0.819715 | -1.367425 |
| 0.822418 | 0.822418 | 0.542014 | -0.193316 | 0.505767 | -0.425458 | -0.242475 | -0.035267 | -0.022685 |
| 1.674801 | 1.674801 | -1.232659 | -2.881999 | -1.077620 | -1.378445 | -0.135817 | 2.060139 | 1.189861 |
| 0.607444 | 0.607444 | 0.523483 | 0.764183 | -0.733856 | 0.548573 | 0.273106 | -0.264642 | 0.773705 |
# 字典方式创建DataFrame
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
df
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| month | year | sale | |
|---|---|---|---|
| 0 | 1 | 2012 | 55 |
| 1 | 4 | 2014 | 40 |
| 2 | 7 | 2013 | 84 |
| 3 | 10 | 2014 | 31 |
df.set_index(keys='month')
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| year | sale | |
|---|---|---|
| month | ||
| 1 | 2012 | 55 |
| 4 | 2014 | 40 |
| 7 | 2013 | 84 |
| 10 | 2014 | 31 |
# 设置2个index, 就是MultiIndex (三维数据结构)
# df.set_index(keys=['month', 'year'])
df.set_index(['month', 'year'])
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| sale | ||
|---|---|---|
| month | year | |
| 1 | 2012 | 55 |
| 4 | 2014 | 40 |
| 7 | 2013 | 84 |
| 10 | 2014 | 31 |
1.2 MultiIndex
df_m = df.set_index(['year', 'month'])
df_m
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| sale | ||
|---|---|---|
| year | month | |
| 2012 | 1 | 55 |
| 2014 | 4 | 40 |
| 2013 | 7 | 84 |
| 2014 | 10 | 31 |
# index属性
# - names: levers的名称
# - levels: 每个level的列表值
df_m.index
MultiIndex([(2012, 1),
(2014, 4),
(2013, 7),
(2014, 10)],
names=['year', 'month'])
df_m.index.names
FrozenList(['year', 'month'])
df_m.index.levels
FrozenList([[2012, 2013, 2014], [1, 4, 7, 10]])
1.3 Series
# 自动生成从0开始的行索引 index
# Data must be 1-dimensional
pd.Series(np.arange(10))
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int32
# 手动指定index值
pd.Series([6.7,5.6,3,10,2], index=['a', 'b', 'c', 'd', 'e'])
a 6.7
b 5.6
c 3.0
d 10.0
e 2.0
dtype: float64
# 通过字典创建
se = pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
se
red 100
blue 200
green 500
yellow 1000
dtype: int64
# 取索引
se.index
Index(['red', 'blue', 'green', 'yellow'], dtype='object')
# 取array值
se.values
array([ 100, 200, 500, 1000], dtype=int64)
pd.Series(np.random.normal(0, 1, (10)))
0 -0.975747
1 0.021589
2 -0.384579
3 -0.412900
4 0.218133
5 -0.866525
6 -0.777209
7 -1.032130
8 0.202134
9 0.295274
dtype: float64
2.基本数据操作
2.1 索引操作
# 使用pd.read_csv()读取本地数据
data = pd.read_csv('./data/stock_day.csv')
data
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 22.942 | 22.142 | 22.875 | 53782.64 | 46738.65 | 55576.11 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 22.406 | 21.955 | 22.942 | 40827.52 | 42736.34 | 56007.50 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 21.938 | 21.929 | 23.022 | 35119.58 | 41871.97 | 56372.85 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 21.446 | 21.909 | 23.137 | 35397.58 | 39904.78 | 60149.60 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 21.366 | 21.923 | 23.253 | 33590.21 | 42935.74 | 61716.11 | 0.58 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-06 | 13.17 | 14.48 | 14.28 | 13.13 | 179831.72 | 1.12 | 8.51 | 13.112 | 13.112 | 13.112 | 115090.18 | 115090.18 | 115090.18 | 6.16 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 12.87 | 93180.39 | 0.26 | 2.02 | 12.820 | 12.820 | 12.820 | 98904.79 | 98904.79 | 98904.79 | 3.19 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 12.61 | 67075.44 | 0.20 | 1.57 | 12.707 | 12.707 | 12.707 | 100812.93 | 100812.93 | 100812.93 | 2.30 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 12.52 | 139071.61 | 0.18 | 1.44 | 12.610 | 12.610 | 12.610 | 117681.67 | 117681.67 | 117681.67 | 4.76 |
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 12.20 | 96291.73 | 0.32 | 2.62 | 12.520 | 12.520 | 12.520 | 96291.73 | 96291.73 | 96291.73 | 3.30 |
643 rows × 14 columns
# 去除一些列,简化数据
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1) # axis=1 去除对应的列,与numpy相反
data
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 0.58 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-06 | 13.17 | 14.48 | 14.28 | 13.13 | 179831.72 | 1.12 | 8.51 | 6.16 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 12.87 | 93180.39 | 0.26 | 2.02 | 3.19 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 12.61 | 67075.44 | 0.20 | 1.57 | 2.30 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 12.52 | 139071.61 | 0.18 | 1.44 | 4.76 |
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 12.20 | 96291.73 | 0.32 | 2.62 | 3.30 |
643 rows × 8 columns
2.1.1 直接使用行列索引
# 必须先列后行
data['high']['2018-02-27']
25.88
# data['2018-02-27']['high']
2.1.2 使用loc和iloc取索引
# loc取字符串, 先行后列
data.loc['2018-02-27']['high']
25.88
# 两种取值方式都可以
data.loc['2018-02-27','high']
25.88
data.loc['2018-02-27':'2018-02-22', 'open']
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
2018-02-22 22.25
Name: open, dtype: float64
# data.loc['high']['2018-02-27']
# iloc取索引数字,先行后列
data.iloc[:3, 3:5]
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| low | volume | |
|---|---|---|
| 2018-02-27 | 23.53 | 95578.03 |
| 2018-02-26 | 22.80 | 60985.11 |
| 2018-02-23 | 22.71 | 52914.01 |
2.1.3 使用ix取混合索引
# ix可以去数字和字符串, 先行后列
# 现版本中已被取消
# data.ix[0:4, ['open', 'close', 'high', 'low']]
# 先通过data.index去除索引并切片
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | close | high | low | |
|---|---|---|---|---|
| 2018-02-27 | 23.53 | 24.16 | 25.88 | 23.53 |
| 2018-02-26 | 22.80 | 23.53 | 23.78 | 22.80 |
| 2018-02-23 | 22.88 | 22.82 | 23.37 | 22.71 |
| 2018-02-22 | 22.25 | 22.28 | 22.76 | 22.02 |
data.index
Index(['2018-02-27', '2018-02-26', '2018-02-23', '2018-02-22', '2018-02-14',
'2018-02-13', '2018-02-12', '2018-02-09', '2018-02-08', '2018-02-07',
...
'2015-03-13', '2015-03-12', '2015-03-11', '2015-03-10', '2015-03-09',
'2015-03-06', '2015-03-05', '2015-03-04', '2015-03-03', '2015-03-02'],
dtype='object', length=643)
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | close | high | low | |
|---|---|---|---|---|
| 2018-02-27 | 23.53 | 24.16 | 25.88 | 23.53 |
| 2018-02-26 | 22.80 | 23.53 | 23.78 | 22.80 |
| 2018-02-23 | 22.88 | 22.82 | 23.37 | 22.71 |
| 2018-02-22 | 22.25 | 22.28 | 22.76 | 22.02 |
data.columns.get_indexer(['close'])
array([2], dtype=int64)
data
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 0.58 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-06 | 13.17 | 14.48 | 14.28 | 13.13 | 179831.72 | 1.12 | 8.51 | 6.16 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 12.87 | 93180.39 | 0.26 | 2.02 | 3.19 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 12.61 | 67075.44 | 0.20 | 1.57 | 2.30 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 12.52 | 139071.61 | 0.18 | 1.44 | 4.76 |
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 12.20 | 96291.73 | 0.32 | 2.62 | 3.30 |
643 rows × 8 columns
2.2 赋值操作
data
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 0.58 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-06 | 13.17 | 14.48 | 14.28 | 13.13 | 179831.72 | 1.12 | 8.51 | 6.16 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 12.87 | 93180.39 | 0.26 | 2.02 | 3.19 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 12.61 | 67075.44 | 0.20 | 1.57 | 2.30 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 12.52 | 139071.61 | 0.18 | 1.44 | 4.76 |
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 12.20 | 96291.73 | 0.32 | 2.62 | 3.30 |
643 rows × 8 columns
# 赋值方式1, 直接取对应的属性值
data.volume = 100
data.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 100 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 100 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 100 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 100 | 0.44 | 2.05 | 0.58 |
# 赋值方式2, 类似于取切片
data['low'] = 100
data.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 100 | 100 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 100 | 100 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 100 | 100 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 100 | 100 | 0.44 | 2.05 | 0.58 |
# 直接取出Series
data.open.head()
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
2018-02-22 22.25
2018-02-14 21.49
Name: open, dtype: float64
# 直接取出Series
data['open'].head()
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
2018-02-22 22.25
2018-02-14 21.49
Name: open, dtype: float64
2.3 排序
data.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 100 | 100 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 100 | 100 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 100 | 100 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 100 | 100 | 0.44 | 2.05 | 0.58 |
2.3.1 以特征值排序
# by --> 传入特征值, 可以传一个或者多个,以列表形式,排前面的作为高优先级,默认升序
data.sort_values(by='open', ascending=False)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2015-06-15 | 34.99 | 34.99 | 31.69 | 100 | 100 | -3.52 | -10.00 | 6.82 |
| 2015-06-12 | 34.69 | 35.98 | 35.21 | 100 | 100 | 0.82 | 2.38 | 5.47 |
| 2015-06-10 | 34.10 | 36.35 | 33.85 | 100 | 100 | 0.51 | 1.53 | 9.21 |
| 2017-11-01 | 33.85 | 34.34 | 33.83 | 100 | 100 | -0.61 | -1.77 | 5.81 |
| 2015-06-11 | 33.17 | 34.98 | 34.39 | 100 | 100 | 0.54 | 1.59 | 5.92 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 100 | 100 | 0.26 | 2.02 | 3.19 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 100 | 100 | 0.20 | 1.57 | 2.30 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 100 | 100 | 0.18 | 1.44 | 4.76 |
| 2015-09-02 | 12.30 | 14.11 | 12.36 | 100 | 100 | -1.10 | -8.17 | 2.40 |
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 100 | 100 | 0.32 | 2.62 | 3.30 |
643 rows × 8 columns
data.sort_values(by=['open', 'high'], ascending=True)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 100 | 100 | 0.32 | 2.62 | 3.30 |
| 2015-09-02 | 12.30 | 14.11 | 12.36 | 100 | 100 | -1.10 | -8.17 | 2.40 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 100 | 100 | 0.18 | 1.44 | 4.76 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 100 | 100 | 0.20 | 1.57 | 2.30 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 100 | 100 | 0.26 | 2.02 | 3.19 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-06-11 | 33.17 | 34.98 | 34.39 | 100 | 100 | 0.54 | 1.59 | 5.92 |
| 2017-11-01 | 33.85 | 34.34 | 33.83 | 100 | 100 | -0.61 | -1.77 | 5.81 |
| 2015-06-10 | 34.10 | 36.35 | 33.85 | 100 | 100 | 0.51 | 1.53 | 9.21 |
| 2015-06-12 | 34.69 | 35.98 | 35.21 | 100 | 100 | 0.82 | 2.38 | 5.47 |
| 2015-06-15 | 34.99 | 34.99 | 31.69 | 100 | 100 | -3.52 | -10.00 | 6.82 |
643 rows × 8 columns
# Series 排序因为只有一个特征值,所以不需要传参
data.close.sort_values()
2015-09-02 12.36
2015-03-02 12.52
2015-03-03 12.70
2015-09-07 12.77
2015-03-04 12.90
...
2017-11-01 33.83
2015-06-10 33.85
2015-06-11 34.39
2017-10-31 34.44
2015-06-12 35.21
Name: close, Length: 643, dtype: float64
2.3.2 以索引排序
# DataFrame 使用sort_index 以索引排序
data.sort_index()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 100 | 100 | 0.32 | 2.62 | 3.30 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 100 | 100 | 0.18 | 1.44 | 4.76 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 100 | 100 | 0.20 | 1.57 | 2.30 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 100 | 100 | 0.26 | 2.02 | 3.19 |
| 2015-03-06 | 13.17 | 14.48 | 14.28 | 100 | 100 | 1.12 | 8.51 | 6.16 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 100 | 100 | 0.44 | 2.05 | 0.58 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 100 | 100 | 0.36 | 1.64 | 0.90 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 100 | 100 | 0.54 | 2.42 | 1.32 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 100 | 100 | 0.63 | 2.68 | 2.39 |
643 rows × 8 columns
# Series 排序
data.high.sort_index()
2015-03-02 12.67
2015-03-03 13.06
2015-03-04 12.92
2015-03-05 13.45
2015-03-06 14.48
...
2018-02-14 21.99
2018-02-22 22.76
2018-02-23 23.37
2018-02-26 23.78
2018-02-27 25.88
Name: high, Length: 643, dtype: float64
3. DataFrame运算
3.1 算数运算
data.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 100 | 100 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 100 | 100 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 100 | 100 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 100 | 100 | 0.44 | 2.05 | 0.58 |
# 推荐使用pd.方法
data['close'].add(100).head()
2018-02-27 124.16
2018-02-26 123.53
2018-02-23 122.82
2018-02-22 122.28
2018-02-14 121.92
Name: close, dtype: float64
# 使用符号运算
(data.close + 100).head()
2018-02-27 124.16
2018-02-26 123.53
2018-02-23 122.82
2018-02-22 122.28
2018-02-14 121.92
Name: close, dtype: float64
data.close.sub(10).head()
2018-02-27 14.16
2018-02-26 13.53
2018-02-23 12.82
2018-02-22 12.28
2018-02-14 11.92
Name: close, dtype: float64
3.2 逻辑运算
3.2.1 逻辑运算符 ( <, > , |, &)
data.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 100 | 100 | 0.63 | 2.68 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 100 | 100 | 0.54 | 2.42 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 100 | 100 | 0.36 | 1.64 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 100 | 100 | 0.44 | 2.05 | 0.58 |
# data.open 返回数据 True, False
# data[data.open] 逻辑判断的结果作为筛选依据
data['open'] > 23
2018-02-27 True
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
...
2015-03-06 False
2015-03-05 False
2015-03-04 False
2015-03-03 False
2015-03-02 False
Name: open, Length: 643, dtype: bool
data[data.open>23].head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 100 | 100 | 0.63 | 2.68 | 2.39 |
| 2018-02-01 | 23.71 | 23.86 | 22.42 | 100 | 100 | -1.30 | -5.48 | 1.66 |
| 2018-01-31 | 23.85 | 23.98 | 23.72 | 100 | 100 | -0.11 | -0.46 | 1.23 |
| 2018-01-30 | 23.71 | 24.08 | 23.83 | 100 | 100 | 0.05 | 0.21 | 0.81 |
| 2018-01-29 | 24.40 | 24.63 | 23.77 | 100 | 100 | -0.73 | -2.98 | 1.64 |
# 利用与或 (& |)完成逻辑判断
# 优先级问题,多加括号
data[(data.close>23) & (data.close<24)].head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-05 | 22.45 | 23.39 | 23.27 | 100 | 100 | 0.65 | 2.87 | 1.31 |
| 2018-01-31 | 23.85 | 23.98 | 23.72 | 100 | 100 | -0.11 | -0.46 | 1.23 |
| 2018-01-30 | 23.71 | 24.08 | 23.83 | 100 | 100 | 0.05 | 0.21 | 0.81 |
| 2018-01-29 | 24.40 | 24.63 | 23.77 | 100 | 100 | -0.73 | -2.98 | 1.64 |
3.2.2 逻辑运算函数
# query(str) 传入字符串
data.query('close>23 & close<24').head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-05 | 22.45 | 23.39 | 23.27 | 100 | 100 | 0.65 | 2.87 | 1.31 |
| 2018-01-31 | 23.85 | 23.98 | 23.72 | 100 | 100 | -0.11 | -0.46 | 1.23 |
| 2018-01-30 | 23.71 | 24.08 | 23.83 | 100 | 100 | 0.05 | 0.21 | 0.81 |
| 2018-01-29 | 24.40 | 24.63 | 23.77 | 100 | 100 | -0.73 | -2.98 | 1.64 |
# isin() 可以传一个值, 也可以传一个列表范围, 判断是否在某个范围内
data['open'].isin([22.80, 23.00])
2018-02-27 False
2018-02-26 True
2018-02-23 False
2018-02-22 False
2018-02-14 False
...
2015-03-06 False
2015-03-05 False
2015-03-04 False
2015-03-03 False
2015-03-02 False
Name: open, Length: 643, dtype: bool
data[data['open'].isin([22.80, 23.00])]
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| 2018-02-26 | 22.8 | 23.78 | 23.53 | 100 | 100 | 0.69 | 3.02 | 1.53 |
| 2018-02-06 | 22.8 | 23.55 | 22.29 | 100 | 100 | -0.97 | -4.17 | 1.39 |
| 2017-12-18 | 23.0 | 23.49 | 23.13 | 100 | 100 | 0.12 | 0.52 | 0.74 |
| 2017-07-24 | 22.8 | 23.79 | 23.03 | 100 | 100 | -0.17 | -0.73 | 2.59 |
| 2017-06-21 | 23.0 | 23.84 | 23.57 | 100 | 100 | -0.51 | -2.12 | 5.13 |
| 2016-01-04 | 22.8 | 22.84 | 20.69 | 100 | 100 | -2.28 | -9.93 | 1.60 |
3.3 统计运算
3.3.1 describe()
# describe()方法可以快速的查看DataFrame的整体属性
# 25% - 第一四分位数(Q1),样本中从小到大排列后第25%的数据
# 50% - 中位数
data.describe()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | turnover | |
|---|---|---|---|---|---|---|---|---|
| count | 643.000000 | 643.000000 | 643.000000 | 643.0 | 643.0 | 643.000000 | 643.000000 | 643.000000 |
| mean | 21.272706 | 21.900513 | 21.336267 | 100.0 | 100.0 | 0.018802 | 0.190280 | 2.936190 |
| std | 3.930973 | 4.077578 | 3.942806 | 0.0 | 0.0 | 0.898476 | 4.079698 | 2.079375 |
| min | 12.250000 | 12.670000 | 12.360000 | 100.0 | 100.0 | -3.520000 | -10.030000 | 0.040000 |
| 25% | 19.000000 | 19.500000 | 19.045000 | 100.0 | 100.0 | -0.390000 | -1.850000 | 1.360000 |
| 50% | 21.440000 | 21.970000 | 21.450000 | 100.0 | 100.0 | 0.050000 | 0.260000 | 2.500000 |
| 75% | 23.400000 | 24.065000 | 23.415000 | 100.0 | 100.0 | 0.455000 | 2.305000 | 3.915000 |
| max | 34.990000 | 36.350000 | 35.210000 | 100.0 | 100.0 | 3.030000 | 10.030000 | 12.560000 |
3.3.2 统计函数
# max(), min()
data.max()
open 34.99
high 36.35
close 35.21
low 100.00
volume 100.00
price_change 3.03
p_change 10.03
turnover 12.56
dtype: float64
data.std()
# data.var()
open 3.930973
high 4.077578
close 3.942806
low 0.000000
volume 0.000000
price_change 0.898476
p_change 4.079698
turnover 2.079375
dtype: float64
data.median()
open 21.44
high 21.97
close 21.45
low 100.00
volume 100.00
price_change 0.05
p_change 0.26
turnover 2.50
dtype: float64
# idxmax ( index-max) 最大值的索引值
data.idxmax()
# data,idxmin()
open 2015-06-15
high 2015-06-10
close 2015-06-12
low 2018-02-27
volume 2018-02-27
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
dtype: object
3.4 累计统计函数
# 常见累计统计函数为:
# cumsum - 累加
# cummax - 累计取最大值, 新的最大值替换原来的最大值
# cummin - 累计取最小值
# cumprod - 累积
data = data.sort_index()
data.p_change
2015-03-02 2.62
2015-03-03 1.44
2015-03-04 1.57
2015-03-05 2.02
2015-03-06 8.51
...
2018-02-14 2.05
2018-02-22 1.64
2018-02-23 2.42
2018-02-26 3.02
2018-02-27 2.68
Name: p_change, Length: 643, dtype: float64
data.p_change.cumsum()
2015-03-02 2.62
2015-03-03 4.06
2015-03-04 5.63
2015-03-05 7.65
2015-03-06 16.16
...
2018-02-14 112.59
2018-02-22 114.23
2018-02-23 116.65
2018-02-26 119.67
2018-02-27 122.35
Name: p_change, Length: 643, dtype: float64
# 利用Pandas自带的绘图功能, 需要运行2次才能出结果
data.p_change.cumsum().plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1d54ecb2848>
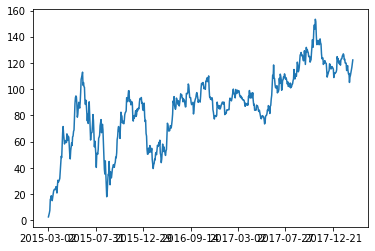
data.p_change.cummax().plot()
<matplotlib.axes._subplots.AxesSubplot at 0x1d54ff73a88>

3.5 自定义函数
# apply(func), fun - lambda函数
data[['open']] # [[]]取出DataFrame
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | |
|---|---|
| 2015-03-02 | 12.25 |
| 2015-03-03 | 12.52 |
| 2015-03-04 | 12.80 |
| 2015-03-05 | 12.88 |
| 2015-03-06 | 13.17 |
| ... | ... |
| 2018-02-14 | 21.49 |
| 2018-02-22 | 22.25 |
| 2018-02-23 | 22.88 |
| 2018-02-26 | 22.80 |
| 2018-02-27 | 23.53 |
643 rows × 1 columns
data[['open']].apply(lambda x: x.max()-x.min()) # 默认axis=0
open 22.74
dtype: float64
4. Pandas内置画图
# DataFrame(x, y, kind='line')
# kind: 绘图的类型, line, bar, barh, hist, pie, scatter
# DataFrame
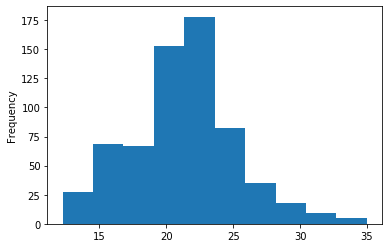
data['open'].plot(kind='hist')
<matplotlib.axes._subplots.AxesSubplot at 0x1d54ffe6c88>
5. 文件读取与存储
5.1 csv文件
# usecols -abs 读取特定列,列表形式传入
# sep=',' 分隔
# 读取文件
data = pd.read_csv('./data/stock_day.csv', usecols=['open', 'high', 'low'], sep=',')
data
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | low | |
|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 23.53 |
| 2018-02-26 | 22.80 | 23.78 | 22.80 |
| 2018-02-23 | 22.88 | 23.37 | 22.71 |
| 2018-02-22 | 22.25 | 22.76 | 22.02 |
| 2018-02-14 | 21.49 | 21.99 | 21.48 |
| ... | ... | ... | ... |
| 2015-03-06 | 13.17 | 14.48 | 13.13 |
| 2015-03-05 | 12.88 | 13.45 | 12.87 |
| 2015-03-04 | 12.80 | 12.92 | 12.61 |
| 2015-03-03 | 12.52 | 13.06 | 12.52 |
| 2015-03-02 | 12.25 | 12.67 | 12.20 |
643 rows × 3 columns
# 存储文件
# columns :存储指定列,
# index:是否存储index
data[:10].to_csv('./data/test_write_in.csv',columns=['high', 'low'], index=False)
5.2 hdf文件
# hdf文件格式是官方推荐的格式,存储读取速度快
# 压缩方式读取速度快,节省空间
# 支持跨平台
day_eps = pd.read_hdf('./data/stock_data/day/day_close.h5')
# 需要安装tables模块才能显示
# hdf文件不能直接打开,需要导入后才能打开
day_eps
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 000001.SZ | 000002.SZ | 000004.SZ | 000005.SZ | 000006.SZ | 000007.SZ | 000008.SZ | 000009.SZ | 000010.SZ | 000011.SZ | ... | 001965.SZ | 603283.SH | 002920.SZ | 002921.SZ | 300684.SZ | 002922.SZ | 300735.SZ | 603329.SH | 603655.SH | 603080.SH | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16.30 | 17.71 | 4.58 | 2.88 | 14.60 | 2.62 | 4.96 | 4.66 | 5.37 | 6.02 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 17.02 | 19.20 | 4.65 | 3.02 | 15.97 | 2.65 | 4.95 | 4.70 | 5.37 | 6.27 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 17.02 | 17.28 | 4.56 | 3.06 | 14.37 | 2.63 | 4.82 | 4.47 | 5.37 | 5.96 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 16.18 | 16.97 | 4.49 | 2.95 | 13.10 | 2.73 | 4.89 | 4.33 | 5.37 | 5.77 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 16.95 | 17.19 | 4.55 | 2.99 | 13.18 | 2.77 | 4.97 | 4.42 | 5.37 | 5.92 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2673 | 12.96 | 35.99 | 22.84 | 4.37 | 9.85 | 16.66 | 8.47 | 7.52 | 6.20 | 17.88 | ... | 12.99 | 23.42 | 47.99 | 32.40 | 22.45 | 28.79 | 23.18 | 24.45 | 14.98 | 26.06 |
| 2674 | 13.08 | 35.84 | 23.02 | 4.41 | 9.85 | 16.66 | 8.49 | 7.48 | 6.01 | 17.75 | ... | 12.83 | 25.76 | 45.14 | 35.64 | 24.70 | 31.67 | 25.50 | 26.90 | 16.48 | 28.67 |
| 2675 | 13.47 | 35.67 | 22.40 | 4.32 | 9.85 | 16.66 | 8.49 | 7.38 | 5.97 | 17.45 | ... | 12.20 | 28.34 | 43.21 | 39.20 | 27.17 | 34.84 | 28.05 | 29.59 | 18.13 | 31.54 |
| 2676 | 13.40 | 35.15 | 22.29 | 4.29 | 9.85 | 16.66 | 8.56 | 7.04 | 5.84 | 17.49 | ... | 12.11 | 31.17 | 43.76 | 40.88 | 29.89 | 34.84 | 29.64 | 32.55 | 19.94 | 34.69 |
| 2677 | 13.55 | 35.55 | 22.20 | 4.37 | 9.85 | 16.66 | 8.67 | 7.06 | 5.99 | 17.76 | ... | 11.91 | 34.29 | 41.71 | 39.10 | 32.88 | 34.84 | 27.92 | 31.82 | 21.93 | 38.16 |
2678 rows × 3562 columns
# 存储格式为 .h5
day_eps_test = day_eps.to_hdf('./data/day_eps_test.h5', key='day_eps')
pd.read_hdf('./data/day_eps_test.h5')
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 000001.SZ | 000002.SZ | 000004.SZ | 000005.SZ | 000006.SZ | 000007.SZ | 000008.SZ | 000009.SZ | 000010.SZ | 000011.SZ | ... | 001965.SZ | 603283.SH | 002920.SZ | 002921.SZ | 300684.SZ | 002922.SZ | 300735.SZ | 603329.SH | 603655.SH | 603080.SH | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16.30 | 17.71 | 4.58 | 2.88 | 14.60 | 2.62 | 4.96 | 4.66 | 5.37 | 6.02 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 17.02 | 19.20 | 4.65 | 3.02 | 15.97 | 2.65 | 4.95 | 4.70 | 5.37 | 6.27 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 17.02 | 17.28 | 4.56 | 3.06 | 14.37 | 2.63 | 4.82 | 4.47 | 5.37 | 5.96 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 16.18 | 16.97 | 4.49 | 2.95 | 13.10 | 2.73 | 4.89 | 4.33 | 5.37 | 5.77 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 16.95 | 17.19 | 4.55 | 2.99 | 13.18 | 2.77 | 4.97 | 4.42 | 5.37 | 5.92 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2673 | 12.96 | 35.99 | 22.84 | 4.37 | 9.85 | 16.66 | 8.47 | 7.52 | 6.20 | 17.88 | ... | 12.99 | 23.42 | 47.99 | 32.40 | 22.45 | 28.79 | 23.18 | 24.45 | 14.98 | 26.06 |
| 2674 | 13.08 | 35.84 | 23.02 | 4.41 | 9.85 | 16.66 | 8.49 | 7.48 | 6.01 | 17.75 | ... | 12.83 | 25.76 | 45.14 | 35.64 | 24.70 | 31.67 | 25.50 | 26.90 | 16.48 | 28.67 |
| 2675 | 13.47 | 35.67 | 22.40 | 4.32 | 9.85 | 16.66 | 8.49 | 7.38 | 5.97 | 17.45 | ... | 12.20 | 28.34 | 43.21 | 39.20 | 27.17 | 34.84 | 28.05 | 29.59 | 18.13 | 31.54 |
| 2676 | 13.40 | 35.15 | 22.29 | 4.29 | 9.85 | 16.66 | 8.56 | 7.04 | 5.84 | 17.49 | ... | 12.11 | 31.17 | 43.76 | 40.88 | 29.89 | 34.84 | 29.64 | 32.55 | 19.94 | 34.69 |
| 2677 | 13.55 | 35.55 | 22.20 | 4.37 | 9.85 | 16.66 | 8.67 | 7.06 | 5.99 | 17.76 | ... | 11.91 | 34.29 | 41.71 | 39.10 | 32.88 | 34.84 | 27.92 | 31.82 | 21.93 | 38.16 |
2678 rows × 3562 columns
5.3 json文件
# oritent: 读取方式
# lines: 是否按行读取
json_read = pd.read_json("./data/Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
json_read
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| article_link | headline | is_sarcastic | |
|---|---|---|---|
| 0 | https://www.huffingtonpost.com/entry/versace-b... | former versace store clerk sues over secret 'b... | 0 |
| 1 | https://www.huffingtonpost.com/entry/roseanne-... | the 'roseanne' revival catches up to our thorn... | 0 |
| 2 | https://local.theonion.com/mom-starting-to-fea... | mom starting to fear son's web series closest ... | 1 |
| 3 | https://politics.theonion.com/boehner-just-wan... | boehner just wants wife to listen, not come up... | 1 |
| 4 | https://www.huffingtonpost.com/entry/jk-rowlin... | j.k. rowling wishes snape happy birthday in th... | 0 |
| ... | ... | ... | ... |
| 26704 | https://www.huffingtonpost.com/entry/american-... | american politics in moral free-fall | 0 |
| 26705 | https://www.huffingtonpost.com/entry/americas-... | america's best 20 hikes | 0 |
| 26706 | https://www.huffingtonpost.com/entry/reparatio... | reparations and obama | 0 |
| 26707 | https://www.huffingtonpost.com/entry/israeli-b... | israeli ban targeting boycott supporters raise... | 0 |
| 26708 | https://www.huffingtonpost.com/entry/gourmet-g... | gourmet gifts for the foodie 2014 | 0 |
26709 rows × 3 columns
# lines 表示存储数据分行, 否则全部为一整行
json_read.to_json('./data/test.json', orient='records', lines=True)
6.高级处理
6.1 处理缺失值
# 缺失值一般使用nan(not a number)来表示
type(np.nan)
float
# 导入数据
movie = pd.read_csv('./data/IMDB-Movie-Data.csv')
movie.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Rank | Title | Genre | Description | Director | Actors | Year | Runtime (Minutes) | Rating | Votes | Revenue (Millions) | Metascore | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Guardians of the Galaxy | Action,Adventure,Sci-Fi | A group of intergalactic criminals are forced ... | James Gunn | Chris Pratt, Vin Diesel, Bradley Cooper, Zoe S... | 2014 | 121 | 8.1 | 757074 | 333.13 | 76.0 |
| 1 | 2 | Prometheus | Adventure,Mystery,Sci-Fi | Following clues to the origin of mankind, a te... | Ridley Scott | Noomi Rapace, Logan Marshall-Green, Michael Fa... | 2012 | 124 | 7.0 | 485820 | 126.46 | 65.0 |
| 2 | 3 | Split | Horror,Thriller | Three girls are kidnapped by a man with a diag... | M. Night Shyamalan | James McAvoy, Anya Taylor-Joy, Haley Lu Richar... | 2016 | 117 | 7.3 | 157606 | 138.12 | 62.0 |
| 3 | 4 | Sing | Animation,Comedy,Family | In a city of humanoid animals, a hustling thea... | Christophe Lourdelet | Matthew McConaughey,Reese Witherspoon, Seth Ma... | 2016 | 108 | 7.2 | 60545 | 270.32 | 59.0 |
| 4 | 5 | Suicide Squad | Action,Adventure,Fantasy | A secret government agency recruits some of th... | David Ayer | Will Smith, Jared Leto, Margot Robbie, Viola D... | 2016 | 123 | 6.2 | 393727 | 325.02 | 40.0 |
# 判断缺失值是否存在
# isnull() :nan - True
# notnull():nan - False
pd.isnull(movie)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Rank | Title | Genre | Description | Director | Actors | Year | Runtime (Minutes) | Rating | Votes | Revenue (Millions) | Metascore | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False | False | False | False | False | False | False |
| 1 | False | False | False | False | False | False | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False | False | False | False | False | False | False |
| 4 | False | False | False | False | False | False | False | False | False | False | False | False |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | False | False | False | False | False | False | False | False | False | False | True | False |
| 996 | False | False | False | False | False | False | False | False | False | False | False | False |
| 997 | False | False | False | False | False | False | False | False | False | False | False | False |
| 998 | False | False | False | False | False | False | False | False | False | False | True | False |
| 999 | False | False | False | False | False | False | False | False | False | False | False | False |
1000 rows × 12 columns
np.any(pd.isnull(movie)) # 其中有任何一个为True(nan值存在), 则返回True
True
np.all(pd.notnull(movie)) # 所有的元素都非nan
False
6.1.1 丢弃缺失值
# 直接丢弃含有nan的一行数据
data = movie.dropna()
np.any(pd.isnull(data))
False
6.1.2 替换缺失值 (常见:平均值或者0)
# 使用平均值替换
# inplace=True , 表示直接对原来movie值进行修改
data = movie['Revenue (Millions)'].fillna(movie['Revenue (Millions)'].mean())
# inplace默认为False, 返回了新的替换后的一个data数据, 原来的movie中仍含有nan
np.any(pd.isnull(movie['Revenue (Millions)']))
True
movie['Revenue (Millions)'].fillna(movie['Revenue (Millions)'].mean(), inplace=True)
# movie['Revenue (Millions)'] 中的nan 已经被替换
np.any(pd.isnull(movie['Revenue (Millions)']))
False
6.1.3 缺失值不是nan
# 全局取消证书验证
# 读取数据
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
# 先将? 数据替换成nan
# 再对nan进行处理
wis
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 1000025 | 5 | 1 | 1.1 | 1.2 | 2 | 1.3 | 3 | 1.4 | 1.5 | 2.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1002945 | 5 | 4 | 4 | 5 | 7 | 10 | 3 | 2 | 1 | 2 |
| 1 | 1015425 | 3 | 1 | 1 | 1 | 2 | 2 | 3 | 1 | 1 | 2 |
| 2 | 1016277 | 6 | 8 | 8 | 1 | 3 | 4 | 3 | 7 | 1 | 2 |
| 3 | 1017023 | 4 | 1 | 1 | 3 | 2 | 1 | 3 | 1 | 1 | 2 |
| 4 | 1017122 | 8 | 10 | 10 | 8 | 7 | 10 | 9 | 7 | 1 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 693 | 776715 | 3 | 1 | 1 | 1 | 3 | 2 | 1 | 1 | 1 | 2 |
| 694 | 841769 | 2 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 2 |
| 695 | 888820 | 5 | 10 | 10 | 3 | 7 | 3 | 8 | 10 | 2 | 4 |
| 696 | 897471 | 4 | 8 | 6 | 4 | 3 | 4 | 10 | 6 | 1 | 4 |
| 697 | 897471 | 4 | 8 | 8 | 5 | 4 | 5 | 10 | 4 | 1 | 4 |
698 rows × 11 columns
# to_replace: 被替换的值, value:去替换的值
wis = wis.replace(to_replace='?', value=np.nan)
wis = wis.dropna()
wis
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| 1000025 | 5 | 1 | 1.1 | 1.2 | 2 | 1.3 | 3 | 1.4 | 1.5 | 2.1 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1002945 | 5 | 4 | 4 | 5 | 7 | 10 | 3 | 2 | 1 | 2 |
| 1 | 1015425 | 3 | 1 | 1 | 1 | 2 | 2 | 3 | 1 | 1 | 2 |
| 2 | 1016277 | 6 | 8 | 8 | 1 | 3 | 4 | 3 | 7 | 1 | 2 |
| 3 | 1017023 | 4 | 1 | 1 | 3 | 2 | 1 | 3 | 1 | 1 | 2 |
| 4 | 1017122 | 8 | 10 | 10 | 8 | 7 | 10 | 9 | 7 | 1 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 693 | 776715 | 3 | 1 | 1 | 1 | 3 | 2 | 1 | 1 | 1 | 2 |
| 694 | 841769 | 2 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 | 2 |
| 695 | 888820 | 5 | 10 | 10 | 3 | 7 | 3 | 8 | 10 | 2 | 4 |
| 696 | 897471 | 4 | 8 | 6 | 4 | 3 | 4 | 10 | 6 | 1 | 4 |
| 697 | 897471 | 4 | 8 | 8 | 5 | 4 | 5 | 10 | 4 | 1 | 4 |
682 rows × 11 columns
6.2 数据离散化
# 数据离散化可以简化数据结构,将数据划分到若干离散的区间,可以简化数据结构, 常用于搭配one-hot编码
# 获取数据
data = pd.read_csv("./data/stock_day.csv")
data_p= data['p_change']
data_p
2018-02-27 2.68
2018-02-26 3.02
2018-02-23 2.42
2018-02-22 1.64
2018-02-14 2.05
...
2015-03-06 8.51
2015-03-05 2.02
2015-03-04 1.57
2015-03-03 1.44
2015-03-02 2.62
Name: p_change, Length: 643, dtype: float64
# pd.qcut() 智能分组
# q: 分组数量
q_cut = pd.qcut(data_p, q=10)
q_cut
2018-02-27 (1.738, 2.938]
2018-02-26 (2.938, 5.27]
2018-02-23 (1.738, 2.938]
2018-02-22 (0.94, 1.738]
2018-02-14 (1.738, 2.938]
...
2015-03-06 (5.27, 10.03]
2015-03-05 (1.738, 2.938]
2015-03-04 (0.94, 1.738]
2015-03-03 (0.94, 1.738]
2015-03-02 (1.738, 2.938]
Name: p_change, Length: 643, dtype: category
Categories (10, interval[float64]): [(-10.030999999999999, -4.836] < (-4.836, -2.444] < (-2.444, -1.352] < (-1.352, -0.462] ... (0.94, 1.738] < (1.738, 2.938] < (2.938, 5.27] < (5.27, 10.03]]
# value_counts(): 每个分组区间内的数据数量
q_cut.value_counts()
(5.27, 10.03] 65
(0.26, 0.94] 65
(-0.462, 0.26] 65
(-10.030999999999999, -4.836] 65
(2.938, 5.27] 64
(1.738, 2.938] 64
(-1.352, -0.462] 64
(-2.444, -1.352] 64
(-4.836, -2.444] 64
(0.94, 1.738] 63
Name: p_change, dtype: int64
# pd.cut(data, bins): 自己指定分组区间
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
cut = pd.cut(data_p, bins=bins)
cut
2018-02-27 (0, 3]
2018-02-26 (3, 5]
2018-02-23 (0, 3]
2018-02-22 (0, 3]
2018-02-14 (0, 3]
...
2015-03-06 (7, 100]
2015-03-05 (0, 3]
2015-03-04 (0, 3]
2015-03-03 (0, 3]
2015-03-02 (0, 3]
Name: p_change, Length: 643, dtype: category
Categories (8, interval[int64]): [(-100, -7] < (-7, -5] < (-5, -3] < (-3, 0] < (0, 3] < (3, 5] < (5, 7] < (7, 100]]
cut.value_counts()
(0, 3] 215
(-3, 0] 188
(3, 5] 57
(-5, -3] 51
(7, 100] 35
(5, 7] 35
(-100, -7] 34
(-7, -5] 28
Name: p_change, dtype: int64
# get_dummies() 取独热矩阵
pd.get_dummies(q_cut)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| (-10.030999999999999, -4.836] | (-4.836, -2.444] | (-2.444, -1.352] | (-1.352, -0.462] | (-0.462, 0.26] | (0.26, 0.94] | (0.94, 1.738] | (1.738, 2.938] | (2.938, 5.27] | (5.27, 10.03] | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-26 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2018-02-23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-22 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-14 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-06 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2015-03-05 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2015-03-04 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2015-03-03 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2015-03-02 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
643 rows × 10 columns
data_dummy = pd.get_dummies(q_cut)
6.3 数据拼接
6.3.1 pd.concat()
# 不指定axis 可能会造成拼接错位,产生很多nan
pd.concat([data, data_dummy], axis=1)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | ... | (-10.030999999999999, -4.836] | (-4.836, -2.444] | (-2.444, -1.352] | (-1.352, -0.462] | (-0.462, 0.26] | (0.26, 0.94] | (0.94, 1.738] | (1.738, 2.938] | (2.938, 5.27] | (5.27, 10.03] | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 22.942 | 22.142 | 22.875 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 22.406 | 21.955 | 22.942 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 21.938 | 21.929 | 23.022 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 21.446 | 21.909 | 23.137 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 21.366 | 21.923 | 23.253 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-06 | 13.17 | 14.48 | 14.28 | 13.13 | 179831.72 | 1.12 | 8.51 | 13.112 | 13.112 | 13.112 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 12.87 | 93180.39 | 0.26 | 2.02 | 12.820 | 12.820 | 12.820 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 12.61 | 67075.44 | 0.20 | 1.57 | 12.707 | 12.707 | 12.707 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 12.52 | 139071.61 | 0.18 | 1.44 | 12.610 | 12.610 | 12.610 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 12.20 | 96291.73 | 0.32 | 2.62 | 12.520 | 12.520 | 12.520 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
643 rows × 24 columns
6.3.2 pd.merge()
# 获取数据
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
# on: 以什么作为键来拼接
result = pd.merge(left, right, on=['key1', 'key2'])
# 内连接就是取交集
result
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
# 外连接
pd.merge(left, right, on=['key1', 'key2'], how='outer')
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
| 5 | K2 | K0 | NaN | NaN | C3 | D3 |
# 左连接
pd.merge(left, right, on=['key1', 'key2'], how='left')
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K0 | K1 | A1 | B1 | NaN | NaN |
| 2 | K1 | K0 | A2 | B2 | C1 | D1 |
| 3 | K1 | K0 | A2 | B2 | C2 | D2 |
| 4 | K2 | K1 | A3 | B3 | NaN | NaN |
# 右连接
pd.merge(left, right, on=['key1', 'key2'], how='right')
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| key1 | key2 | A | B | C | D | |
|---|---|---|---|---|---|---|
| 0 | K0 | K0 | A0 | B0 | C0 | D0 |
| 1 | K1 | K0 | A2 | B2 | C1 | D1 |
| 2 | K1 | K0 | A2 | B2 | C2 | D2 |
| 3 | K2 | K0 | NaN | NaN | C3 | D3 |
6.4 交叉表和透视表
data.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 22.942 | 22.142 | 22.875 | 53782.64 | 46738.65 | 55576.11 | 2.39 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 22.406 | 21.955 | 22.942 | 40827.52 | 42736.34 | 56007.50 | 1.53 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 21.938 | 21.929 | 23.022 | 35119.58 | 41871.97 | 56372.85 | 1.32 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 21.446 | 21.909 | 23.137 | 35397.58 | 39904.78 | 60149.60 | 0.90 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 21.366 | 21.923 | 23.253 | 33590.21 | 42935.74 | 61716.11 | 0.58 |
# 将date.index 转化为datetime格式
date = pd.to_datetime(data.index).weekday
data['week'] = date
data
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | posi_neg | week | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 22.942 | 22.142 | 22.875 | 53782.64 | 46738.65 | 55576.11 | 2.39 | 1 | 1 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 22.406 | 21.955 | 22.942 | 40827.52 | 42736.34 | 56007.50 | 1.53 | 1 | 0 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 21.938 | 21.929 | 23.022 | 35119.58 | 41871.97 | 56372.85 | 1.32 | 1 | 4 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 21.446 | 21.909 | 23.137 | 35397.58 | 39904.78 | 60149.60 | 0.90 | 1 | 3 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 21.366 | 21.923 | 23.253 | 33590.21 | 42935.74 | 61716.11 | 0.58 | 1 | 2 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2015-03-06 | 13.17 | 14.48 | 14.28 | 13.13 | 179831.72 | 1.12 | 8.51 | 13.112 | 13.112 | 13.112 | 115090.18 | 115090.18 | 115090.18 | 6.16 | 1 | 4 |
| 2015-03-05 | 12.88 | 13.45 | 13.16 | 12.87 | 93180.39 | 0.26 | 2.02 | 12.820 | 12.820 | 12.820 | 98904.79 | 98904.79 | 98904.79 | 3.19 | 1 | 3 |
| 2015-03-04 | 12.80 | 12.92 | 12.90 | 12.61 | 67075.44 | 0.20 | 1.57 | 12.707 | 12.707 | 12.707 | 100812.93 | 100812.93 | 100812.93 | 2.30 | 1 | 2 |
| 2015-03-03 | 12.52 | 13.06 | 12.70 | 12.52 | 139071.61 | 0.18 | 1.44 | 12.610 | 12.610 | 12.610 | 117681.67 | 117681.67 | 117681.67 | 4.76 | 1 | 1 |
| 2015-03-02 | 12.25 | 12.67 | 12.52 | 12.20 | 96291.73 | 0.32 | 2.62 | 12.520 | 12.520 | 12.520 | 96291.73 | 96291.73 | 96291.73 | 3.30 | 1 | 0 |
643 rows × 16 columns
# 把p_change 划分为0, 1两类
data['posi_neg'] = np.where(data['p_change']>0, 1, 0)
data.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | turnover | posi_neg | week | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2018-02-27 | 23.53 | 25.88 | 24.16 | 23.53 | 95578.03 | 0.63 | 2.68 | 22.942 | 22.142 | 22.875 | 53782.64 | 46738.65 | 55576.11 | 2.39 | 1 | 1 |
| 2018-02-26 | 22.80 | 23.78 | 23.53 | 22.80 | 60985.11 | 0.69 | 3.02 | 22.406 | 21.955 | 22.942 | 40827.52 | 42736.34 | 56007.50 | 1.53 | 1 | 0 |
| 2018-02-23 | 22.88 | 23.37 | 22.82 | 22.71 | 52914.01 | 0.54 | 2.42 | 21.938 | 21.929 | 23.022 | 35119.58 | 41871.97 | 56372.85 | 1.32 | 1 | 4 |
| 2018-02-22 | 22.25 | 22.76 | 22.28 | 22.02 | 36105.01 | 0.36 | 1.64 | 21.446 | 21.909 | 23.137 | 35397.58 | 39904.78 | 60149.60 | 0.90 | 1 | 3 |
| 2018-02-14 | 21.49 | 21.99 | 21.92 | 21.48 | 23331.04 | 0.44 | 2.05 | 21.366 | 21.923 | 23.253 | 33590.21 | 42935.74 | 61716.11 | 0.58 | 1 | 2 |
# 手动构造交叉表
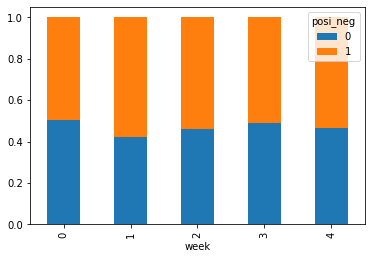
count = pd.crosstab(data['week'], data['posi_neg'])
sum = count.sum(axis=1).astype(np.float32)
pro = count.div(sum, axis=0)
pro.plot(kind='bar', stacked=True)
<matplotlib.axes._subplots.AxesSubplot at 0x1d55bc28408>
# 自动构造交叉表
data.pivot_table(['posi_neg'], index='week')
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| posi_neg | |
|---|---|
| week | |
| 0 | 0.496000 |
| 1 | 0.580153 |
| 2 | 0.537879 |
| 3 | 0.507812 |
| 4 | 0.535433 |
6.5 分组和聚合
6.5.1 pd.groupby()
# 创建数据
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
col
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| color | object | price1 | price2 | |
|---|---|---|---|---|
| 0 | white | pen | 5.56 | 4.75 |
| 1 | red | pencil | 4.20 | 4.12 |
| 2 | green | pencil | 1.30 | 1.60 |
| 3 | red | ashtray | 0.56 | 0.75 |
| 4 | green | pen | 2.75 | 3.15 |
# DataFrame 分组, 推荐使用
# 单独的分组没有意义,进行聚合(求值)才有价值
col.groupby(['color'])['price1'].mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
# 如果设置as_index= False 会创建一列新索引
col.groupby(['color'], as_index= False)['price1'].mean()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| color | price1 | |
|---|---|---|
| 0 | green | 2.025 |
| 1 | red | 2.380 |
| 2 | white | 5.560 |
col.price1
0 5.56
1 4.20
2 1.30
3 0.56
4 2.75
Name: price1, dtype: float64
# Series 分组
col.price1.groupby(col['color']).mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
6.5.2 分组实例
# 获取数据
starbucks = pd.read_csv("./data/starbucks/directory.csv")
starbucks.head()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Brand | Store Number | Store Name | Ownership Type | Street Address | City | State/Province | Country | Postcode | Phone Number | Timezone | Longitude | Latitude | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Starbucks | 47370-257954 | Meritxell, 96 | Licensed | Av. Meritxell, 96 | Andorra la Vella | 7 | AD | AD500 | 376818720 | GMT+1:00 Europe/Andorra | 1.53 | 42.51 |
| 1 | Starbucks | 22331-212325 | Ajman Drive Thru | Licensed | 1 Street 69, Al Jarf | Ajman | AJ | AE | NaN | NaN | GMT+04:00 Asia/Dubai | 55.47 | 25.42 |
| 2 | Starbucks | 47089-256771 | Dana Mall | Licensed | Sheikh Khalifa Bin Zayed St. | Ajman | AJ | AE | NaN | NaN | GMT+04:00 Asia/Dubai | 55.47 | 25.39 |
| 3 | Starbucks | 22126-218024 | Twofour 54 | Licensed | Al Salam Street | Abu Dhabi | AZ | AE | NaN | NaN | GMT+04:00 Asia/Dubai | 54.38 | 24.48 |
| 4 | Starbucks | 17127-178586 | Al Ain Tower | Licensed | Khaldiya Area, Abu Dhabi Island | Abu Dhabi | AZ | AE | NaN | NaN | GMT+04:00 Asia/Dubai | 54.54 | 24.51 |
# 以一个值为分组依据
starbucks.groupby(['Country']).count()
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Brand | Store Number | Store Name | Ownership Type | Street Address | City | State/Province | Postcode | Phone Number | Timezone | Longitude | Latitude | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | ||||||||||||
| AD | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| AE | 144 | 144 | 144 | 144 | 144 | 144 | 144 | 24 | 78 | 144 | 144 | 144 |
| AR | 108 | 108 | 108 | 108 | 108 | 108 | 108 | 100 | 29 | 108 | 108 | 108 |
| AT | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 18 | 17 | 18 | 18 | 18 |
| AU | 22 | 22 | 22 | 22 | 22 | 22 | 22 | 22 | 0 | 22 | 22 | 22 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| TT | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 0 | 3 | 3 | 3 |
| TW | 394 | 394 | 394 | 394 | 394 | 394 | 394 | 365 | 39 | 394 | 394 | 394 |
| US | 13608 | 13608 | 13608 | 13608 | 13608 | 13608 | 13608 | 13607 | 13122 | 13608 | 13608 | 13608 |
| VN | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 25 | 23 | 25 | 25 | 25 |
| ZA | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 2 | 3 | 3 | 3 |
73 rows × 12 columns
starbucks_count = starbucks.groupby(['Country']).count()
starbucks_count['Brand'].plot(kind='bar', figsize=(20, 8))
<matplotlib.axes._subplots.AxesSubplot at 0x1d563dbd148>
# 为了阅读方便,对数据进行排序后画图
starbucks_count.sort_values(by='Brand', ascending=False).head(20)['Brand'].plot(kind='bar', figsize=(20, 8))
<matplotlib.axes._subplots.AxesSubplot at 0x1d55ca68f48>
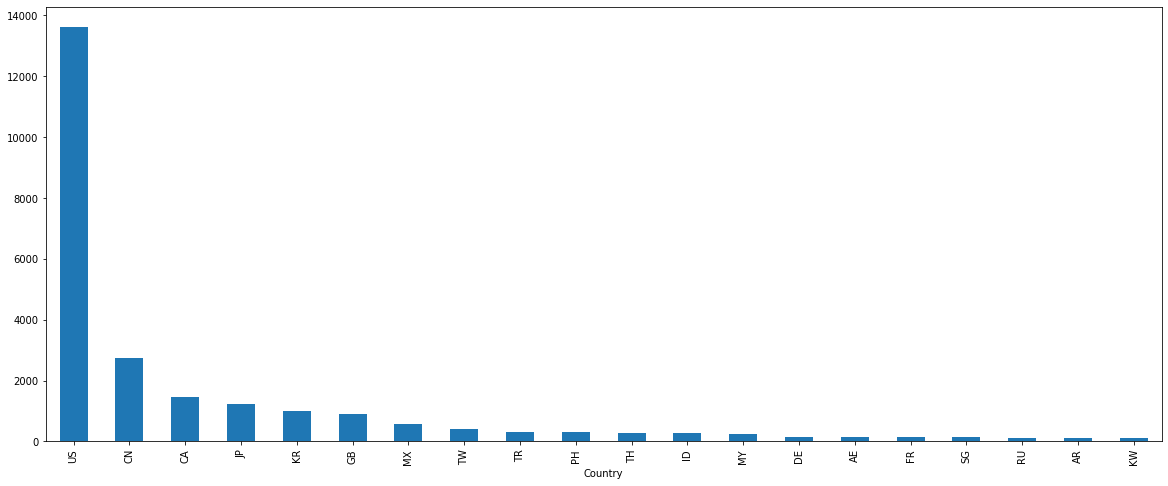
# 多种分组依据
starbucks.groupby(['Country', 'State/Province']).count().head(20)
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| Brand | Store Number | Store Name | Ownership Type | Street Address | City | Postcode | Phone Number | Timezone | Longitude | Latitude | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Country | State/Province | |||||||||||
| AD | 7 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| AE | AJ | 2 | 2 | 2 | 2 | 2 | 2 | 0 | 0 | 2 | 2 | 2 |
| AZ | 48 | 48 | 48 | 48 | 48 | 48 | 7 | 20 | 48 | 48 | 48 | |
| DU | 82 | 82 | 82 | 82 | 82 | 82 | 16 | 50 | 82 | 82 | 82 | |
| FU | 2 | 2 | 2 | 2 | 2 | 2 | 1 | 0 | 2 | 2 | 2 | |
| RK | 3 | 3 | 3 | 3 | 3 | 3 | 0 | 3 | 3 | 3 | 3 | |
| SH | 6 | 6 | 6 | 6 | 6 | 6 | 0 | 5 | 6 | 6 | 6 | |
| UQ | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | |
| AR | B | 21 | 21 | 21 | 21 | 21 | 21 | 18 | 5 | 21 | 21 | 21 |
| C | 73 | 73 | 73 | 73 | 73 | 73 | 71 | 24 | 73 | 73 | 73 | |
| M | 5 | 5 | 5 | 5 | 5 | 5 | 2 | 0 | 5 | 5 | 5 | |
| S | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 0 | 3 | 3 | 3 | |
| X | 6 | 6 | 6 | 6 | 6 | 6 | 6 | 0 | 6 | 6 | 6 | |
| AT | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 5 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | |
| 9 | 14 | 14 | 14 | 14 | 14 | 14 | 14 | 13 | 14 | 14 | 14 | |
| AU | NSW | 9 | 9 | 9 | 9 | 9 | 9 | 9 | 0 | 9 | 9 | 9 |
| QLD | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 0 | 8 | 8 | 8 | |
| VIC | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 0 | 5 | 5 | 5 | |
| AW | AW | 3 | 3 | 3 | 3 | 3 | 3 | 0 | 3 | 3 | 3 | 3 |
Pandas 精简实例入门的更多相关文章
- Matplotlib 精简实例入门
Matplotlob 简明实例入门 通过几个实例,快速了解matplotlib.pyplot 中最为常见的折线图,散点图,柱状图,直方图,饼图的用法 如果您需要更为详细的内容,请参考官方文档: htt ...
- XML实例入门2
工具:notepad++.VS2008(MSXML6.0) 来自msdn的例子(经过修改,因为升级到MSXML6.0,有些关键字不太一样了), 需要文件books.xml,books.vsd(博客只支 ...
- Pandas系列之入门篇
Pandas系列之入门篇 简介 pandas 是 python用来数据清洗.分析的包,可以使用类sql的语法方便的进行数据关联.查询,属于内存计算范畴, 效率远远高于硬盘计算的数据库存储.另外pand ...
- Kivy 中文教程 实例入门 简易画板 (Simple Paint App):1. 自定义窗口部件 (widget)
1. 框架代码 用 PyCharm 新建一个名为 SimplePaintApp 的项目,然后新建一个名为 simple_paint_app.py 的 Python 源文件, 在代码编辑器中,输入以下框 ...
- Kivy crash 中文教程 实例入门 1. 第1个应用 Kivy App (Making a simple App)
1. 空白窗口 在 PyCharm 中创建一个名为 TutorialApp 的项目,然后在该项目中新建了个名为 tutorial_app.py 的 Python 源文件,在 PyCharm 的代码编 ...
- Kivy 中文教程 实例入门 简易画板 (Simple Paint App):3. 随机颜色及清除按钮
1. 随机颜色 通过前面的教程,咪博士已经带大家实现了画板的绘图功能.但是,现在画板只能画出黄色的图案,还十分单调,接下来咪博士就教大家,如何使用随机颜色,让画板变得五彩斑斓. 改进后的代码如下: f ...
- Kivy 中文教程 实例入门 简易画板 (Simple Paint App):2. 实现绘图功能
1. 理解 kivy 坐标系统 上一节中,咪博士带大家实现了画板程序的基础框架,以及一个基本的自定义窗口部件(widget).在上一节的末尾,咪博士留了一道关于 kivy 坐标系统的思考题给大家.通过 ...
- Kivy 中文教程 实例入门 简易画板 (Simple Paint App):0. 项目简介 & 成果展示
本教程咪博士将带领大家学习创建自己的窗口部件 (widget).最终,我们完成的作品是一个简易的画板程序. 当用 kivy 创建应用时,我们需要仔细思考以下 3 个问题: 我们创建的应用需要处理什么数 ...
- React实例入门教程(1)基础API,JSX语法--hello world
前 言 毫无疑问,react是目前最最热门的框架(没有之一),了解并学习使用React,可以说是现在每个前端工程师都需要的. 在前端领域,一个框架为何会如此之火爆,无外乎两个原因:性能优秀,开发 ...
随机推荐
- java内存区域----运行时数据区
Java虚拟机的内存区域也叫做java运行时数据区,共分为五个部分:程序计数器,方法区,本地方法栈,虚拟机栈和堆.方法区和堆是线程之间所共有的,程序计数器,本地方法栈,虚拟机栈是线程私有的.其中虚拟机 ...
- 初识Flask框架
Flask简介: Flask诞生于2010年,是Armin ronacher(人名)用 Python 语言基于 Werkzeug 工具箱编写的轻量级Web开发框架. Flask 本身相当于一个内核,其 ...
- FPGA小白学习之路(1) System Verilog的概念以及与verilog的对比(转)
转自CSDN:http://blog.csdn.net/gtatcs/article/details/8970489 SystemVerilog语言简介 SystemVerilog是一种硬件描述和验证 ...
- go语言指南之切片练习
题目: 实现 Pic.它应当返回一个长度为 dy 的切片,其中每个元素是一个长度为 dx,元素类型为 uint8 的切片.当你运行此程序时,它会将每个整数解释为灰度值(好吧,其实是蓝度值)并显示它所对 ...
- Vmware安装的linux系统开机黑屏,关闭显示虚拟机忙怎么怎么解决?
在vm虚拟机中,可能会遇到打开一台主机直接黑屏,而且无法关闭,关闭会显示虚拟机繁忙这种情况,如下图: 一般是因为没有正常关机或者操作不当导致的 对此,解决办法一般有两种 第一种方法: 1.重启电脑 ...
- 纯CSS实现带返回顶部右侧悬浮菜单
这是我做个人网页的时候加上的带返回顶部右侧悬浮菜单效果,如下图, 使用工具是Hbuilder. 代码如下: <!DOCTYPE html> <html> <head> ...
- 【译文连载】 理解Istio服务网格(第六章 可观测性)
全书目录 第一章 概述 第二章 安装 第三章 流控 第四章 服务弹性 第五章 混沌测试 本文目录 第6章 可观测性 6.1 分布式调用链跟踪(tracing) 6.1.1 基本概念 6.1.2 Ja ...
- An incompatible version [1.1.33] of the APR based Apache Tomcat Native library is installed, while Tomcat requires version [1.2.14]
Springboot项目启动出现如下错误信息 解决办法在此地址:http://archive.apache.org/dist/tomcat/tomcat-connectors/native/1.2.1 ...
- .Net Core项目中整合Serilog
前言:Serilog是.NET应用程序的诊断日志记录库.它易于设置,具有简洁的API,并且可以在所有最新的.NET平台上运行.尽管即使在最简单的应用程序中它也很有用,但当对复杂的,分布式的和异步的应用 ...
- 最简单的???ubuntu 通过crontab定时执行一个程序
crontab在liunx系统中下载,我默认是认为下载安装了的.. crontab貌似只能在liunx系统中存在,如果是windows系统我不知道 创建一个名为jiaoben的文件夹存储sh文件,进入 ...