【原创】linux spinlock/rwlock/seqlock原理剖析(基于ARM64)
背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
吹起并发机制研究的进攻号角了!
作为第一篇文章,应该提纲挈领的介绍下并发。
什么是并发,并发就是:你有两个儿子,同时抢一个玩具玩,你一巴掌打在你大儿子手上,小儿子拿到了玩具。
并发是指多个执行流访问同一个资源,并发引起竞态。
来张图吧:
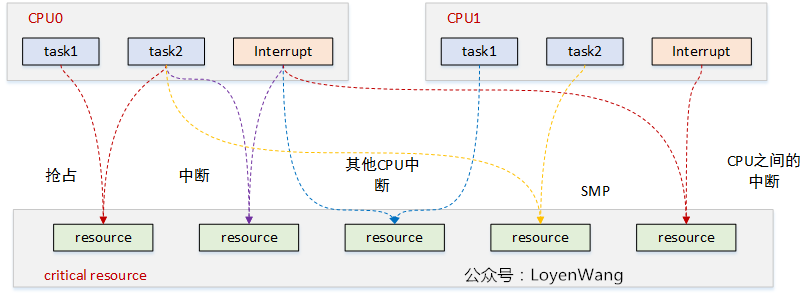
图中每一种颜色代表一种竞态情况,主要归结为三类:
- 进程与进程之间:单核上的抢占,多核上的SMP;
- 进程与中断之间:中断又包含了上半部与下半部,中断总是能打断进程的执行流;
- 中断与中断之间:外设的中断可以路由到不同的CPU上,它们之间也可能带来竞态;
目前内核中提供了很多机制来处理并发问题,spinlock就是其中一种。
spinlock,就是大家熟知的自旋锁,它的特点是自旋锁保护的区域不允许睡眠,可以用在中断上下文中。自旋锁获取不到时,CPU会忙等待,并循环测试等待条件。自旋锁一般用于保护很短的临界区。
下文将进一步揭开神秘的面纱。
2. spinlock原理分析
2.1 spin_lock/spin_unlock
先看一下函数调用流程:
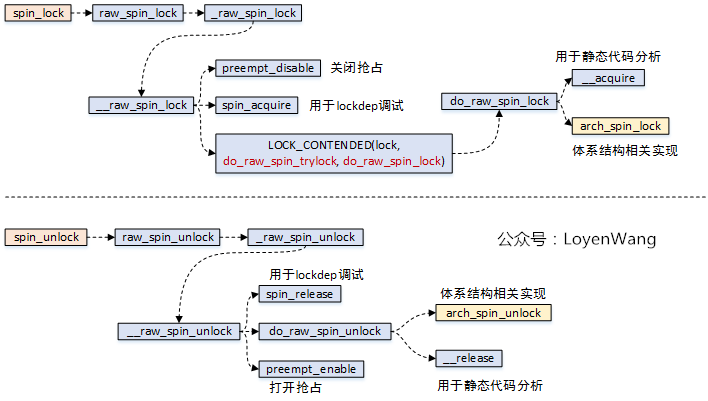
spin_lock操作中,关闭了抢占,也就是其他进程无法再来抢占当前进程了;spin_lock函数中,关键逻辑需要依赖于体系结构的实现,也就是arch_spin_lock函数;spin_unlock函数中,关键逻辑需要依赖于体系结构的实现,也就是arch_spin_unlock函数;
直接看ARM64中这个arch_spin_lock/arch_spin_unlock函数的实现吧:
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned int tmp;
arch_spinlock_t lockval, newval;
asm volatile(
/* Atomically increment the next ticket. */
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" prfm pstl1strm, %3\n"
"1: ldaxr %w0, %3\n"
" add %w1, %w0, %w5\n"
" stxr %w2, %w1, %3\n"
" cbnz %w2, 1b\n",
/* LSE atomics */
" mov %w2, %w5\n"
" ldadda %w2, %w0, %3\n"
__nops(3)
)
/* Did we get the lock? */
" eor %w1, %w0, %w0, ror #16\n"
" cbz %w1, 3f\n"
/*
* No: spin on the owner. Send a local event to avoid missing an
* unlock before the exclusive load.
*/
" sevl\n"
"2: wfe\n"
" ldaxrh %w2, %4\n"
" eor %w1, %w2, %w0, lsr #16\n"
" cbnz %w1, 2b\n"
/* We got the lock. Critical section starts here. */
"3:"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp), "+Q" (*lock)
: "Q" (lock->owner), "I" (1 << TICKET_SHIFT)
: "memory");
}
static inline void arch_spin_unlock(arch_spinlock_t *lock)
{
unsigned long tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" ldrh %w1, %0\n"
" add %w1, %w1, #1\n"
" stlrh %w1, %0",
/* LSE atomics */
" mov %w1, #1\n"
" staddlh %w1, %0\n"
__nops(1))
: "=Q" (lock->owner), "=&r" (tmp)
:
: "memory");
}
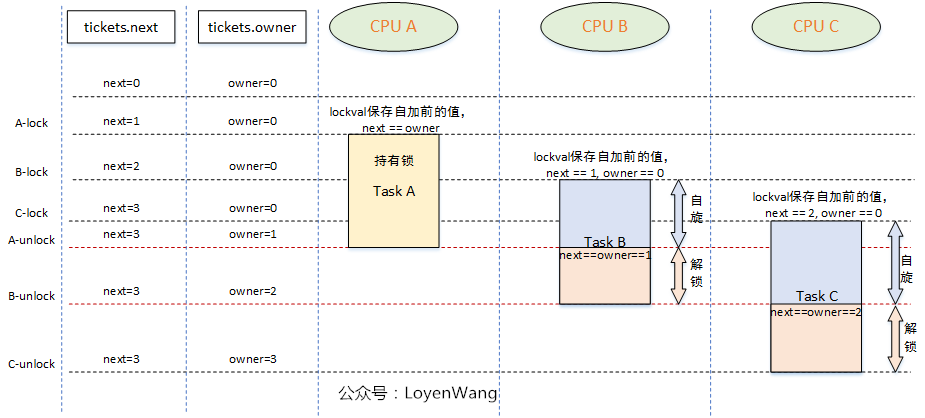
spinlock的核心思想是基于tickets的机制:
- 每个锁的数据结构
arch_spinlock_t中维护两个字段:next和owner,只有当next和owner相等时才能获取锁;- 每个进程在获取锁的时候,
next值会增加,当进程在释放锁的时候owner值会增加;- 如果有多个进程在争抢锁的时候,看起来就像是一个排队系统,
FIFO ticket spinlock;
上边的代码中,核心逻辑在于asm volatile()内联汇编中,有点迷糊吗?把核心逻辑翻译成C语言,类似于下边:
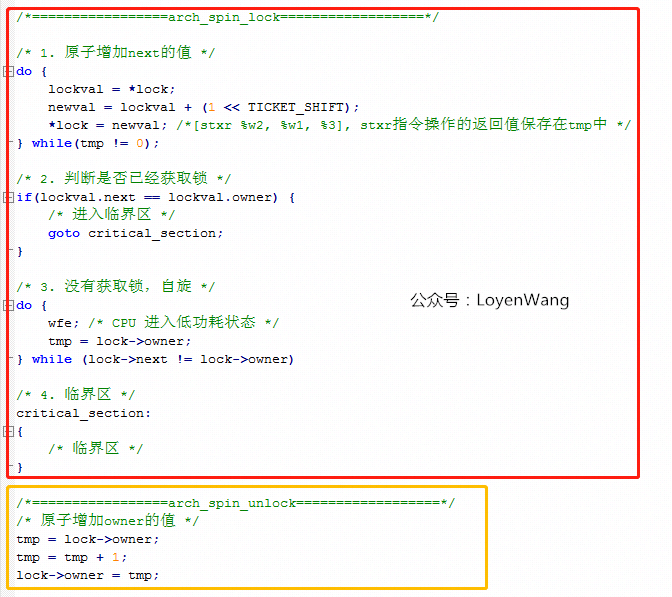
asm volatile内联汇编中,有很多独占的操作指令,只有基于指令的独占操作,才能保证软件上的互斥,简单介绍如下:ldaxr:Load-Acquire Exclusive Register derives an address from a base register value, loads a 32-bit word or 64-bit doubleword from memory, and writes it to a register,从内存地址中读取值到寄存器中,独占访问;stxr:Store Exclusive Register stores a 32-bit or a 64-bit doubleword from a register to memory if the PE has exclusive access to the memory address,将寄存器中的值写入到内存中,并需要返回是否独占访问成功;eor:Bitwise Exclusive OR,执行独占的按位或操作;ldadda:Atomic add on word or doubleword in memory atomically loads a 32-bit word or 64-bit doubleword from memory, adds the value held in a register to it, and stores the result back to memory,原子的将内存中的数据进行加值处理,并将结果写回到内存中;
此外,还需要提醒一点的是,在
arch_spin_lock中,当自旋等待时,会执行WFE指令,这条指令会让CPU处于低功耗的状态,其他CPU可以通过SEV指令来唤醒当前CPU。
如果说了这么多,你还是没有明白,那就再来一张图吧:
2.2 spin_lock_irq/spin_lock_bh
自旋锁还有另外两种形式,那就是在持有锁的时候,不仅仅关掉抢占,还会把本地的中断关掉,或者把下半部关掉(本质上是把软中断关掉)。
这种锁用来保护临界资源既会被进程访问,也会被中断访问的情况。
看一下调用流程图:
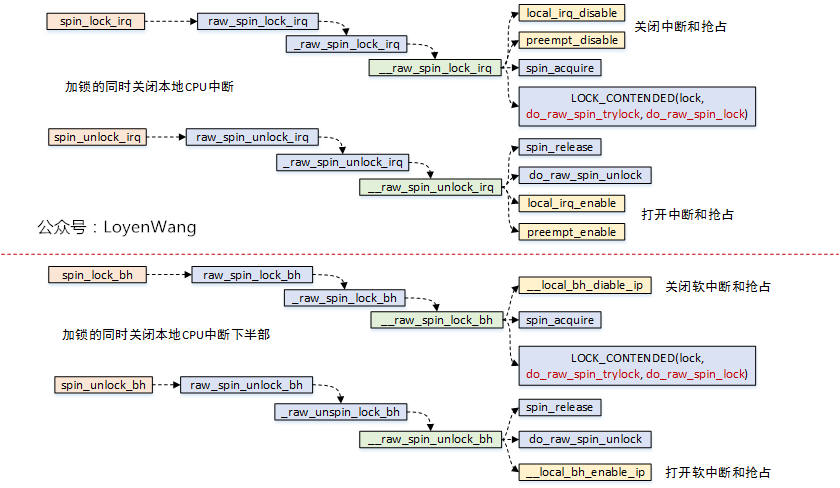
- 可以看到这两个函数中,实际锁的机制实现跟
spin_lock是一样的; - 额外提一句,
spin_lock_irq还有一种变种形式spin_lock_irqsave,该函数会将当前处理器的硬件中断状态保存下来;
__local_bh_disable_ip是怎么实现的呢,貌似也没有看到关抢占?有必要前情回顾一下了,如果看过之前的文章的朋友,应该见过下边这张图片:

thread_info->preempt_count值就维护了各种状态,针对该值的加减操作,就可以进行状态的控制;
3. rwlock读写锁
- 读写锁是自旋锁的一种变种,分为读锁和写锁,有以下特点:
- 可以多个读者同时进入临界区;
- 读者与写者互斥;
- 写者与写者互斥;
先看流程分析图:
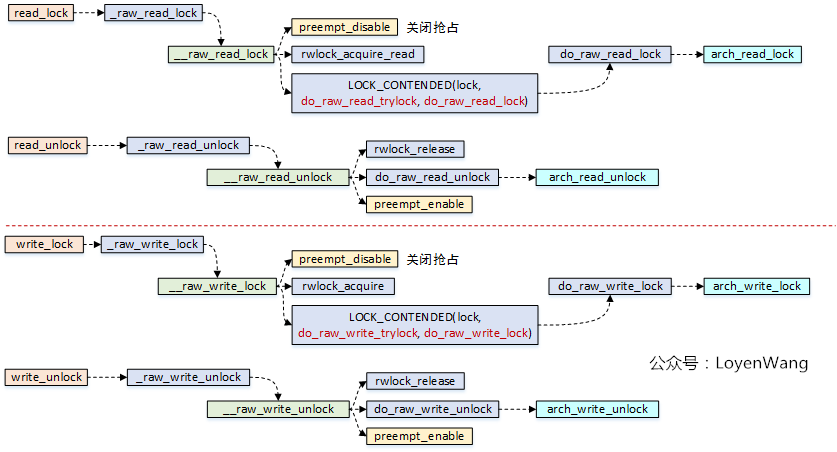
看一下arch_read_lock/arch_read_unlock/arch_write_lock/arch_write_unlock源代码:
static inline void arch_read_lock(arch_rwlock_t *rw)
{
unsigned int tmp, tmp2;
asm volatile(
" sevl\n"
ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
"1: wfe\n"
"2: ldaxr %w0, %2\n"
" add %w0, %w0, #1\n"
" tbnz %w0, #31, 1b\n"
" stxr %w1, %w0, %2\n"
" cbnz %w1, 2b\n"
__nops(1),
/* LSE atomics */
"1: wfe\n"
"2: ldxr %w0, %2\n"
" adds %w1, %w0, #1\n"
" tbnz %w1, #31, 1b\n"
" casa %w0, %w1, %2\n"
" sbc %w0, %w1, %w0\n"
" cbnz %w0, 2b")
: "=&r" (tmp), "=&r" (tmp2), "+Q" (rw->lock)
:
: "cc", "memory");
}
static inline void arch_read_unlock(arch_rwlock_t *rw)
{
unsigned int tmp, tmp2;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
"1: ldxr %w0, %2\n"
" sub %w0, %w0, #1\n"
" stlxr %w1, %w0, %2\n"
" cbnz %w1, 1b",
/* LSE atomics */
" movn %w0, #0\n"
" staddl %w0, %2\n"
__nops(2))
: "=&r" (tmp), "=&r" (tmp2), "+Q" (rw->lock)
:
: "memory");
}
static inline void arch_write_lock(arch_rwlock_t *rw)
{
unsigned int tmp;
asm volatile(ARM64_LSE_ATOMIC_INSN(
/* LL/SC */
" sevl\n"
"1: wfe\n"
"2: ldaxr %w0, %1\n"
" cbnz %w0, 1b\n"
" stxr %w0, %w2, %1\n"
" cbnz %w0, 2b\n"
__nops(1),
/* LSE atomics */
"1: mov %w0, wzr\n"
"2: casa %w0, %w2, %1\n"
" cbz %w0, 3f\n"
" ldxr %w0, %1\n"
" cbz %w0, 2b\n"
" wfe\n"
" b 1b\n"
"3:")
: "=&r" (tmp), "+Q" (rw->lock)
: "r" (0x80000000)
: "memory");
}
static inline void arch_write_unlock(arch_rwlock_t *rw)
{
asm volatile(ARM64_LSE_ATOMIC_INSN(
" stlr wzr, %0",
" swpl wzr, wzr, %0")
: "=Q" (rw->lock) :: "memory");
}
知道你们不爱看汇编代码,那么翻译成C语言的伪代码看看吧:

- 读写锁数据结构
arch_rwlock_t中只维护了一个字段:volatile unsigned int lock,其中bit[31]用于写锁的标记,bit[30:0]用于读锁的统计; - 读者在获取读锁的时候,高位
bit[31]如果为1,表明正有写者在访问临界区,这时候会进入自旋的状态,如果没有写者访问,那么直接去自加rw->lock的值,从逻辑中可以看出,是支持多个读者同时访问的; - 读者在释放锁的时候,直接将
rw->lock自减1即可; - 写者在获取锁的时候,判断
rw->lock的值是否为0,这个条件显得更为苛刻,也就是只要有其他读者或者写者访问,那么都将进入自旋,没错,它确实很霸道,只能自己一个人持有; - 写者在释放锁的时候,很简单,直接将
rw->lock值清零即可; - 缺点:由于读者的判断条件很苛刻,假设出现了接二连三的读者来访问临界区,那么
rw->lock的值将一直不为0,也就是会把写者活活的气死,噢,是活活的饿死。
读写锁当然也有类似于自旋锁的关中断、关底半部的形式:
read_lock_irq/read_lock_bh/write_lock_irq/write_lock_bh,原理都类似,不再赘述了。
4. seqlock顺序锁
- 顺序锁也区分读者与写者,它的优点是不会把写者给饿死。
来看一下流程图:
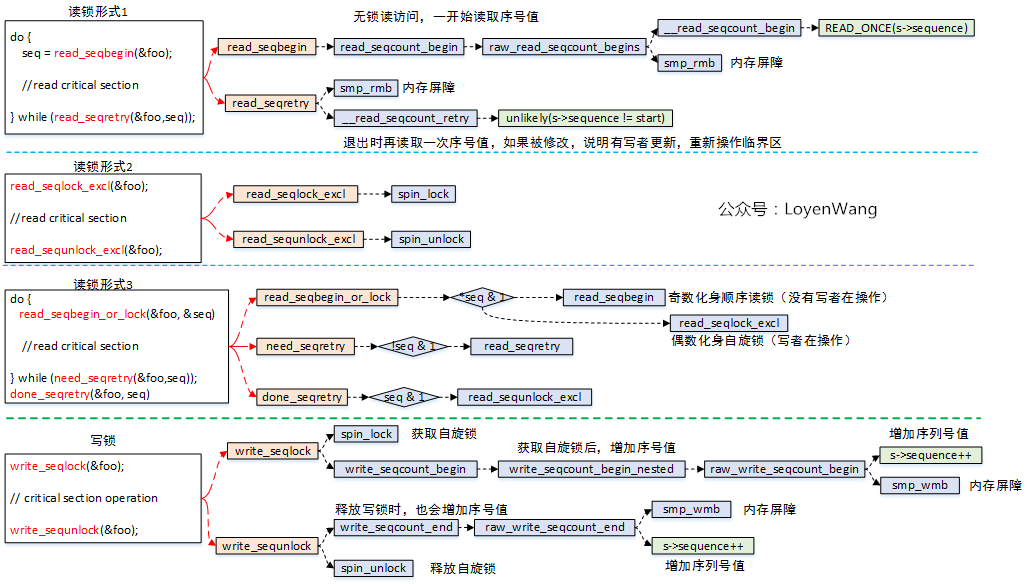
- 顺序锁的读锁有三种形式:
- 无加锁访问,读者在读临界区之前,先读取序列号,退出临界区操作后再读取序列号进行比较,如果发现不相等,说明被写者更新内容了,需要重新再读取临界区,所以这种情况下可能给读者带来的开销会大一些;
- 加锁访问,实际是
spin_lock/spin_unlock,仅仅是接口包装了一下而已,因此对读和写都是互斥的; - 在形式1和形式2中动态选择,如果有写者在写临界区,读者化身为自旋锁,没有写者在写临界区,则化身为顺序无锁访问;
- 顺序锁的写锁,只有一种形式,本质上是用自旋锁来保护临界区,然后再把序号值自加处理;
- 顺序锁也有一些局限的地方,比如采用读者的形式1的话,临界区中存在地址(指针)操作,如果写者把地址进行了修改,那就可能造成访问错误了;
- 说明一下流程图中的
smp_rmb/smp_wmb,这两个函数是内存屏障操作,作用是告诉编译器内存中的值已经改变,之前对内存的缓存(缓存到寄存器)都需要抛弃,屏障之后的内存操作需要重新从内存load,而不能使用之前寄存器缓存的值,内存屏障就像是代码中一道不可逾越的屏障,屏障之前的load/store指令不能跑到屏障的后边,同理,后边的也不能跑到前边; - 顺序锁也同样存在关中断和关下半部的形式,原理基本都是一致的,不再啰嗦了。
最近在项目中,遇到了RCU Stall的问题,下一个topic就先来看看RCU吧,其他的并发机制都会在路上,
Just keep growing and fuck everthing else,收工!
欢迎关注公众号,不定期发布Linux内核机制探索文档。

【原创】linux spinlock/rwlock/seqlock原理剖析(基于ARM64)的更多相关文章
- 【原创】Linux RCU原理剖析(二)-渐入佳境
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
- 【Xamarin 跨平台机制原理剖析】
原文:[Xamarin 跨平台机制原理剖析] [看了请推荐,推荐满100后,将发补丁地址] Xamarin项目从喊口号到现在,好几个年头了,在内地没有火起来,原因无非有三,1.授权费贵 2.贵 3.原 ...
- 【Xamain 跨平台机制原理剖析】
原文:[Xamain 跨平台机制原理剖析] [看了请推荐,推荐满100后,将发补丁地址] Xamarin项目从喊口号到现在,好几个年头了,在内地没有火起来,原因无非有三,1.授权费贵 2.贵 3.原生 ...
- MapReduce/Hbase进阶提升(原理剖析、实战演练)
什么是MapReduce? MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归约)",和他们 ...
- 写给 Android 应用工程师的 Binder 原理剖析
写给 Android 应用工程师的 Binder 原理剖析 一. 前言 这篇文章我酝酿了很久,参考了很多资料,读了很多源码,却依旧不敢下笔.生怕自己理解上还有偏差,对大家造成误解,贻笑大方.又怕自己理 ...
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- 开源 serverless 产品原理剖析 - Kubeless
背景 Serverless 架构的出现让开发者不用过多地考虑传统的服务器采购.硬件运维.网络拓扑.资源扩容等问题,可以将更多的精力放在业务的拓展和创新上. 随着 serverless 概念的深入人心, ...
随机推荐
- 【技巧】歪脑筋优化flexbox瀑布流布局方案
效果先行 需求 在大量"不定宽"元素并排的布局模式下,上图是我们想要的最佳布局但是FlexBox布局虽然枪弹但并不能完全呈现以上布局,于是我们需要结合FlexBox作下小的改动即可 ...
- JS基础入门篇(十八)—日期对象
1.日期对象 日期对象: 通过new Date()就能创建一个日期对象,这个对象中有当前系统时间的所有详细信息. 以下代码可以获取当前时间: <script> var t = new Da ...
- 【Java面试题】关于String,最近被问到了这2道面试题
1. 前言 最近面试了几家公司,体验了一下电话面试和今年刚火起来的视频面试, 虽然之前就有一些公司会先通过电话面试的形式先评估下候选人的能力水平,但好像不多,至少我以前的面试形式100%都是现场面试. ...
- IEEE1588 PTP对时系统原理及特点
IEEE1588 PTP对时系统原理及特点 随着网络技术的快速发展,以太网的定时同步精度也在不断入提高,为了适应网络技术的变化,人们开发出了NTP网络时间协议来提高各网络设备的定时同步功能,但在一些对 ...
- 22 Specifications动态查询
Specifications动态查询 有时我们在查询某个实体的时候,给定的条件是不固定的,这时就需要动态构建相应的查询语句,在Spring Data JPA中可以通过JpaSpecificationE ...
- python3编写程序,根据输入的行列数值,生成相应的矩阵(其中元素为随机数)。
代码如下: import random n = int(input("请输入行:")) m = int(input("请输入列:")) x = y = 0 wh ...
- 2.5D地图系统技术方案
1. 2.5D地图概述 1.1. 概述 2.5维地图就是根据dem.dom.dlg等数据,以及真三维模型在一定高度.视角和灯光效果,按照轴侧投影的方式生成的地图.本文以臻图信息ZTMapE ...
- 如何为SpringBoot服务添加HTTPS证书
HTTPS是HTTP的安全版本,旨在提供数据传输层安全性(TLS).当你的应用不使用HTTP协议的时候,浏览器地址栏就会出现一个不安全的提示.HTTPS加密每个数据包以安全方式进行传输,并保护敏感数据 ...
- CODING 携手优普丰,道器合璧打造敏捷最佳实践
随着全球进入到信息化时代,越来越多的企业迫切地寻求新的商业模式,要求迭代.探索.不断加速创新以响应快速变化的市场.如今一系列新兴概念如敏捷开发.极限编程.微服务.自动化.DevOps 等大行其道,然而 ...
- web架构之Nginx简介(1)
目录 1.Nginx概述 2.Nginx快速安装 2.1.源码方式安装Nginx 2.2.yum方式安装Nginx 3.Nginx配置文件 4.Nginx核心功能模块 5.Ningx目录介绍 1.Ng ...