Python爬虫之记录一次下载验证码的尝试
好久没有写过爬虫的文章了,今天在尝试着做验证码相关的研究时,遇到了验证码的收集问题。
一般,验证码的加载都有着比较复杂的算法和加密在里边,但是笔者今天碰到的验证码却比较幸运,有迹可循。在此,给出本爬虫的相关记录。
注意,文章和代码中均不会给出相关的真实网站的信息,避免不道德的行为。
首先,让我们来看一看该验证码的页面,如下:
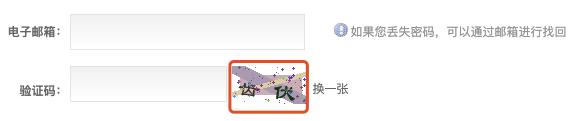
如果我们尝试着查看该验证码加载时的源代码,会发现源码如下:

我们可以发现,该验证码的加载机制其实并不复杂,只是在网址后面跟了一个时间戳,而这个时间戳,是由JavaScript中的方法产生的,函数内容为new Date().getTime()。
知道了验证码背后加载的原理,那么我们不难通过Python来实现验证码的下载。
可惜的是,上述JS函数产生的时间戳是13位数字,而Python的time.time()方法产生的时间戳为浮点数,小数点前10位,小数点后6位。那么,我们如果来产生符合上述JS函数产生的时间戳呢?
一个简单的想法是,我们让Python来调用JS。真的可以吗?幸运的是,前人已经提我们做好了这个工作,有个神奇的Python第三方模块,叫做PyExecJS。顾名思义,这个模块就是用来执行JS代码的。
该模块的源码中给出了一个例子,我们可以尝试下,代码如下:
# -*- coding: utf-8 -*-
import execjs
print(execjs.eval("'red yellow blue'.split(' ')"))
ctx = execjs.compile("""
function add(x, y) {
return x + y;
}
""")
print(ctx.call("add", 1, 2))
输出结果如下:
['red', 'yellow', 'blue']
3
OK,有了上面的例子,我们就知道如何使用该模块了,我们可以轻松地写出下面的代码来下载验证码了:
# -*- coding: utf-8 -*-
import execjs
import urllib.request
js_func = """
function get_milliseconds(){
return new Date().getTime();
}
"""
ctx = execjs.compile(js_func)
result = ctx.call("get_milliseconds")
print(len(str(result)))
# 注意,网址已经隐藏
url = "http://***/captcha/?%s" % result
urllib.request.urlretrieve(url, "1.png")
下载的验证码如下:
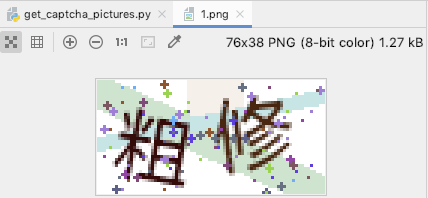
通过我们这次的尝试,发现如下:
- PyExecJS支持Python对JavaScript的操作,所以下次有机会,可以在Python中执行JS函数;
- 验证码的加载算法不宜简单,要注意加密。
本次分享到此结束,感谢大家的阅读~
Python爬虫之记录一次下载验证码的尝试的更多相关文章
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- Python爬虫个人记录(三)爬取妹子图
这此教程可能会比较简洁,具体细节可参考我的第一篇教程: Python爬虫个人记录(一)豆瓣250 Python爬虫个人记录(二)fishc爬虫 一.目的分析 获取煎蛋妹子图并下载 http://jan ...
- 如何用Python爬虫实现百度图片自动下载?
Github:https://github.com/nnngu/LearningNotes 制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求 分析网页源代码,配合开发者工具 编写正则表达式或 ...
- python爬虫学习过程记录
项目为爬取Python词条的信息. 项目代码在我的码云仓库. https://gitee.com/libo-sober/learn-python/tree/master/baike_spider 1. ...
- python爬虫学习记录
爬虫基础 urllib,urllib2,re都是python自带的模块 urllib,urllib2区别是urllib2可以接受一个Request类的实例来设置url请求的headers,即可以模拟浏 ...
- Python爬虫实践 -- 记录我的第二只爬虫
1.爬虫基本原理 我们爬取中国电影最受欢迎的影片<红海行动>的相关信息.其实,爬虫获取网页信息和人工获取信息,原理基本是一致的. 人工操作步骤: 1. 获取电影信息的页面 2. 定位(找到 ...
- Python爬虫学习记录【内附代码、详细步骤】
引言: 昨天在网易云课堂自学了<Python网络爬虫实战>,视频链接 老师讲的很清晰,跟着实践一遍就能掌握爬虫基础了,强烈推荐! 另外,在网上看到一位学友整理的课程记录,非常详细,可以优先 ...
- Python爬虫个人记录(四)利用Python在豆瓣上写一篇日记
涉及关键词:requests库 requests.post方法 cookies登陆 version 1.5(附录):使用post方法登陆豆瓣,成功! 缺点:无法获得登陆成功后的cookie,要使用js ...
- Python爬虫实践 -- 记录我的第一只爬虫
一.环境配置 1. 下载安装 python3 .(或者安装 Anaconda) 2. 安装requests和lxml 进入到 pip 目录,CMD --> C:\Python\Scripts,输 ...
随机推荐
- IDEA运行报错 Error:java: 错误: 不支持发行版本 xx
解决方案 修改项目配置,进入Project Setting,截图可参考下面的截图 1.修改全局设置 修改Project->Project Language Level->选择版本比当前jd ...
- MySQL(Linux)编码问题——网站刚刚上线就被光速打脸
MySQL(Linux)编码问题--刚刚上线就被光速打脸 MySql默认编码问题 总结了一下,大致是这样的 修改数据库配置 在URL上加载参数 MySql默认编码问题 说到这里真的想哭,改了无数bug ...
- pyhton 信号量Semaphore和BoundedSemaphore
Semaphore和BoundedSemaphore两个,用起来好像没啥区别 都是定义信号量 sem=threading.BoundedSemaphore(5) sem=threading.Semap ...
- ubuntu16.04下安装java8
从Oracle官网下载jdk,jdk-8u231-linux-x64.tar.gz (1)复制到/opt 目录内 sudo cp jdk-8u231-linux-x64.tar.gz /opt (3) ...
- mac 升级到mavericks 安装php扩展现问题
mac 升级到mavericks 安装php扩展现以下问题 grep: /usr/include/php/main/php.h: No such file or directory grep: /us ...
- 微信小程序mpvue-动态改变navigationBarTitleText值
通过JS动态 改变navigationBarTitleText的值 能否通过JS动态改变navigationBarTitleText的值? 方法一:可以在onLoad方法中通过wx.setNaviga ...
- 一天学一个Linux命令:第二天 cd pwd
文章更新于:2020-03-08 注:本文参照 man pwd 手册,并给出使用样例. 文章目录 一.命令之 `cd` 和 `pwd` 1.命令介绍 2.语法格式 3.使用样例 4.pwd 参数 5. ...
- C/C++ 数据精确度的设置
#include<iostream>#include<iomanip> //此库为代码最后一行快捷设置数据格式需要用的的库 #include<math.h>usin ...
- mysql添加,授权,删除用户以及连接数据库Can't connect to MySQL server on '192.168.31.106' (113)错误排查
centos7下面操作mysql添加,授权,删除用户 添加用户 以root用户登录数据库,运行以下命令: create user test identified by '; 上面创建了用户test,密 ...
- java 中类为啥要序列化
java里为什么要序列化?http://zhidao.baidu.com/link?url=7_wAQ8eAl28vcJPE5OKM5Y0Bo4aINNQokHhRmI9XPszEoTO5QF-gNb ...