tensorflow文本分类实战——卷积神经网络CNN
首先说明使用的工具和环境:python3.6.8 tensorflow1.14.0 centos7.0(最好用Ubuntu)
关于环境的搭建只做简单说明,我这边是使用pip搭建了python的虚拟环境(virtualenv),并在虚拟环境中安装tensorflow。详细步骤可以查看tensorflow的官网。
训练数据
训练(train.txt)和测试(test.txt)数据,两个文件的分类相同为100个分类,其中test.txt每个类下有200条测试数据,train.txt每个类下有1800条训练数据;数据共有两列,第一列为标签信息 第二列为标题,见下图

百度云链接:https://pan.baidu.com/s/1MZX8SOJ7lerov_UqZhSWeQ
提取码:9nvj
训练代码
闲话少说直接上代码,支持训练模型固化,代码粘贴前都经过了测试,均可复现,并且在相应位置给出了注释,有任何疑问欢迎留言,不忙就会回复。
###################cnn训练代码#################
#coding=utf8
import os
import codecs
import random
import heapq
import numpy as np
import pandas as pd
import tensorflow as tf
import tensorflow.contrib.keras as kr
from collections import Counter #简单的计数器 用于统计字符出现的个数
from sklearn.preprocessing import LabelEncoder #标签编码
from sklearn.metrics import confusion_matrix #混淆矩阵 labelEncoder = LabelEncoder() #标签编码
#输出格式显示设置
#pd.set_option('display.max_columns', None) #显示所有列
pd.set_option('display.max_rows', None) #显示所有行
#pd.set_option('max_colwidth', 500) #设置value的显示长度为100,默认为50
np.set_printoptions(threshold=np.inf) #设置print输出完整性
os.environ["CUDA_VISIBLE_DEVICES"] = "" #设置只有一个gpu可见 #cnn参数设置 可根据实际情况自行修改
vocab_size = 5000 #词汇表大小
seq_length = 100 #标题序列长度
embedding_dim = 64 #词向量维度
num_classes = 100 #类别数(初始值,后边会根据具体训练数据类目数量修改)
num_filters = 128 #卷积核数目
kernel_size = 5 #卷积核尺寸
hidden_dim = 128 #全连接层神经元
dropout_keep_prob = 0.5 #dropout保留比例
learning_rate = 1e-3 #学习率
batch_size = 100 #每批训练大小 with open('train.txt', encoding='utf8') as file: #加载训练数据
line_list = [k.strip() for k in file.readlines()] #提取训练数据中的一行
train_label_list = [k.split()[0] for k in line_list] #提取标签数据
train_content_list = [k.split(maxsplit=1)[1] for k in line_list] #提取标题数据 def getVocabularyList(content_list, vocabulary_size):
allContent_str = ''.join(content_list)
counter = Counter(allContent_str)
vocabulary_list = [k[0] for k in counter.most_common(vocabulary_size)]
return vocabulary_list def makeVocabularyFile(content_list, vocabulary_size):
vocabulary_list = getVocabularyList(content_list, vocabulary_size)
with open('vocab_last.txt', 'w', encoding='utf8') as file:
for vocabulary in vocabulary_list:
file.write(vocabulary + '\n') #makeVocabularyFile(train_content_list, 5000) #根据训练数据集创建新的 单字表 with open('vocab.txt', encoding='utf8') as file: #加载 词汇表(单字表) 数据
vocabulary_list = [k.strip() for k in file.readlines()]
word2id_dict = dict([(b ,a) for a,b in enumerate(vocabulary_list)]) #单字 与 id对照表
content2idList = lambda content : [word2id_dict[word] for word in content if word in word2id_dict]
train_idlist_list = [content2idList(content) for content in train_content_list] #标题训练id列表 train_X = kr.preprocessing.sequence.pad_sequences(train_idlist_list, seq_length) #按照seq_length补全和截断 训练数据
train_y = labelEncoder.fit_transform(train_label_list) #train_y 所有的训练标签数据 做编码 num_classes = len(labelEncoder.classes_) #根据训练数据重新定义类目数量
#保存类目预测标签
y_lable = codecs.open('y_lable_last.txt', 'w', 'utf-8')
for label in labelEncoder.classes_:
str1 = label + '\n'
y_lable.write(str1)
y_lable.close()
print('参与训练的类目数量', num_classes)
train_Y = kr.utils.to_categorical(train_y, num_classes) #标签的one-hot #搭建神经网络 这里使用的是默认的W、b
tf.reset_default_graph()
X_holder = tf.placeholder(tf.int32, [None, seq_length])
Y_holder = tf.placeholder(tf.float32, [None, num_classes])
embedding = tf.get_variable('embedding', [vocab_size, embedding_dim]) #vocab_size*embedding_dim 矩阵形状 5000*64
embedding_inputs = tf.nn.embedding_lookup(embedding, X_holder) #batch_size*seq_length*embedding_dim 100*100*64
conv = tf.layers.conv1d(embedding_inputs, num_filters, kernel_size) #形状为batch_size*(100-5+1)*num_filter 64*96*128 这里的100指标题序列长度(seq_length)
max_pooling = tf.reduce_max(conv, reduction_indices=[1]) #最大值池化 形状为batch_size*num_filter 100*128
full_connect = tf.layers.dense(max_pooling, hidden_dim) #添加全连接层 形状为batch_size*hidden_dim 100*128
full_connect_dropout = tf.contrib.layers.dropout(full_connect, dropout_keep_prob) #防止全连接过拟合
full_connect_activate = tf.nn.relu(full_connect_dropout) #全连接激活函数
softmax_before = tf.layers.dense(full_connect_activate, num_classes) #添加全连接层形状为batch_size*num_classes 100*100
predict_Y = tf.nn.softmax(softmax_before) #softmax方法给出预测概率值
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y_holder, logits=softmax_before) #交叉熵作为损失函数
loss = tf.reduce_mean(cross_entropy) #反向传播计算损失值
optimizer = tf.train.AdamOptimizer(learning_rate) #优化器
train = optimizer.minimize(loss) #最小化损失
isCorrect = tf.equal(tf.argmax(Y_holder, 1), tf.argmax(predict_Y, 1)) #预算准确率
accuracy = tf.reduce_mean(tf.cast(isCorrect, tf.float32))
#参数初始化 对于神经网络模型,重要是其中的W、b这两个参数
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init) #测试数据加载、转换
with open('test.txt', encoding='utf8') as file:
line_list = [k.strip() for k in file.readlines()]
test_label_list = [k.split()[0] for k in line_list]
test_content_list = [k.split(maxsplit=1)[1] for k in line_list]
test_idlist_list = [content2idList(content) for content in test_content_list]
test_X = kr.preprocessing.sequence.pad_sequences(test_idlist_list, seq_length)
test_y = labelEncoder.transform(test_label_list)
test_Y = kr.utils.to_categorical(test_y, num_classes) #做one-hot for i in range(10000): #表示模型迭代的次数
selected_index = random.sample(list(range(len(train_y))), k=batch_size)
batch_X = train_X[selected_index]
batch_Y = train_Y[selected_index]
session.run(train, {X_holder:batch_X, Y_holder:batch_Y}) #模型训练
step = i+1
if step % 100 == 0:
selected_index = random.sample(list(range(len(test_y))), k=100) #在测试集中随机抽取100行进行测试
batch_X = test_X[selected_index]
batch_Y = test_Y[selected_index]
loss_value, accuracy_value = session.run([loss, accuracy], {X_holder:batch_X, Y_holder:batch_Y})
print('step:%d loss:%.4f accuracy:%.4f' %(step, loss_value, accuracy_value)) #保存模型
saver = tf.train.Saver()
save_path = saver.save(session, 'train_model/fenlei_cnn.ckpt')
print('Save to path:', save_path) def predictAll(test_X, data_size=100):
predict_value_list = []
for i in range(0, len(test_X), data_size):
selected_X = test_X[i:i+data_size]
predict_value = session.run(predict_Y, {X_holder:selected_X})
predict_value_list.extend(predict_value)
return np.array(predict_value_list) #预测全部的测试数据
Y = predictAll(test_X)
#可修改Y的提取数量
y = np.argmax(Y, axis=1)
predict_label_list = labelEncoder.inverse_transform(y) df=pd.DataFrame(confusion_matrix(test_label_list, predict_label_list),
columns = labelEncoder.classes_,
index = labelEncoder.classes_ )
#print(df) ###报告表
import numpy as np
from sklearn.metrics import precision_recall_fscore_support def eval_model(y_true, y_pred, labels):
#计算每个分类的Precision, Recall, f1, support
p,r,f1,s = precision_recall_fscore_support(y_true, y_pred)
#计算总体的平局Precision,recall,f1,support
tot_p = np.average(p, weights=s)
tot_r = np.average(r, weights=s)
tot_f1 = np.average(f1, weights=s)
tot_s = np.sum(s)
res1 = pd.DataFrame({
u'Label':labels,
u'Precision':p,
u'Recall':r,
u'F1':f1,
u'Support':s
})
res2 = pd.DataFrame({
u'Label':['总体'],
u'Precision':[tot_p],
u'Recall':[tot_r],
u'F1':[tot_f1],
u'Support':[tot_s]
})
res2.index = [999]
res = pd.concat([res1, res2])
return res[['Label', 'Precision', 'Recall', 'F1', 'Support']]
tables = eval_model(test_label_list, predict_label_list, labelEncoder.classes_)
print(tables)
预测代码
python预测代码,代码支持批量预测和debug单条测试
执行方式:python cnn_predict.py debug或python cnn_predict.py batch
#coding=utf8
import tensorflow as tf
import os
import sys
import time
import codecs
import random
import heapq
import numpy as np
import tensorflow.contrib.keras as kr
from sklearn.preprocessing import LabelEncoder #标签编码 labelEncoder = LabelEncoder() #标签编码
os.environ["CUDA_VISIBLE_DEVICES"] = "" #设置只有一个gpu可见
#可根据实际情况自行修改
vocab_size = 5000 #词汇表大小
seq_length = 100 #序列长度
embedding_dim = 64 #词向量维度
num_classes = 100 #类别数
num_filters = 128 #卷积核数目
kernel_size = 5 #卷积核尺寸
hidden_dim = 128 #全连接层神经元
dropout_keep_prob = 1 #dropout保留比例 注意:这里要保留为1 与训练参数的差距
learning_rate = 1e-3 #学习率
batch_size = 100 #每批训练大小 np.set_printoptions(threshold=np.inf) #设置print输出完整性 with open('vocab.txt', encoding='utf8') as file: #加载 词汇表(单字表) 数据
vocabulary_list = [k.strip() for k in file.readlines()]
word2id_dict = dict([(b ,a) for a,b in enumerate(vocabulary_list)]) #单字 与 id对照表
content2idList = lambda content : [word2id_dict[word] for word in content if word in word2id_dict] with open('y_lable.txt', encoding='utf8') as file:
train_label_list = [k.strip() for k in file.readlines()]
labelEncoder.fit_transform(train_label_list) #所有的训练标签数据 做编码
#搭建神经网络
tf.reset_default_graph()
X_holder = tf.placeholder(tf.int32, [None, seq_length])
Y_holder = tf.placeholder(tf.float32, [None, num_classes])
embedding = tf.get_variable('embedding', [vocab_size, embedding_dim]) #vocab_size*embedding_dim 矩阵形状 5000*64
embedding_inputs = tf.nn.embedding_lookup(embedding, X_holder) #batch_size*seq_length*embedding_dim 100*100*64
conv = tf.layers.conv1d(embedding_inputs, num_filters, kernel_size) #形状为batch_size*(100-5+1)*num_filter 64*96*128
max_pooling = tf.reduce_max(conv, reduction_indices=[1]) #最大值池化 形状为batch_size*num_filter 64*128
full_connect = tf.layers.dense(max_pooling, hidden_dim) #添加全连接层 形状为batch_size*hidden_dim 64*128
full_connect_dropout = tf.contrib.layers.dropout(full_connect, dropout_keep_prob) #防止全连接过拟合
full_connect_activate = tf.nn.relu(full_connect_dropout) #全连接激活函数
softmax_before = tf.layers.dense(full_connect_activate, num_classes) #添加全连接层形状为batch_size*num_classes 100*100
predict_Y = tf.nn.softmax(softmax_before) #softmax方法给出预测概率值
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y_holder, logits=softmax_before) #交叉熵作为损失函数
loss = tf.reduce_mean(cross_entropy) #反向传播计算损失值
optimizer = tf.train.AdamOptimizer(learning_rate) #优化器
train = optimizer.minimize(loss) #最小化损失
isCorrect = tf.equal(tf.argmax(Y_holder, 1), tf.argmax(predict_Y, 1)) #预算准确率
accuracy = tf.reduce_mean(tf.cast(isCorrect, tf.float32)) session = tf.Session()
#加载预测模型
saver = tf.train.Saver()
saver.restore(session, 'train_model/fenlei_cnn.ckpt')
print('load model succesful') def predictAll(test_X, data_size=100):
predict_value_list = []
for i in range(0, len(test_X), data_size):
selected_X = test_X[i:i+data_size]
predict_value = session.run(predict_Y, {X_holder:selected_X})
predict_value_list.extend(predict_value)
return np.array(predict_value_list) #给出五个预测结果,及预测分数,测试准确率
def format_predict5(Y):
y_index = []
y_value = []
for Y_l in Y:
index_l = heapq.nlargest(5, range(len(Y_l)), Y_l.take) #获取前五个下标
value_l = heapq.nlargest(5, Y_l) #获取前五个类目数值
y_index.append(index_l)
y_value.append(value_l)
#print('前五个类目得分:',value_l)
for i in range(0,len(test_id_list)):
num=0
flag=0
#判断预测类目阈值
for n in range(5):
if test_label_list[i] in train_label_list and y_value[i][n] > 0.1:
num+=1
elif y_value[i][n] > 0.9: #如果原类目没有训练 则阈值要大于0.9
num+=1
flag=1
if num == 0:
continue
#把名称index转换成name
pre_Yname = []
for ii in range(num):
pre_Yname.append(labelEncoder.classes_[y_index[i][ii]])
#判断源目录与预测类目相同
if test_label_list[i] in pre_Yname:
continue str1 = test_id_list[i]+'\t'+test_content_list[i]+'\t'+test_label_list[i]+'\t'+ str(flag)
for j in range(num):
str1 += '\t'+pre_Yname[j]+'('+str(y_value[i][j]) +')'
str1+='\n'
fo.write(str1) if __name__ == "__main__":
if len(sys.argv) != 2:
print ('python cnn_predict.py batch(debug)')
exit(1)
if sys.argv[1] == 'batch':
_time = time.strftime("%m%d%H%M", time.localtime())
fo = codecs.open('test_result'+_time+'.txt', 'w', 'utf8')
batch_line = [] #批处理检测 满足1000条进行一次批处理
b_size = 0
with codecs.open('test.txt', 'rb', 'utf8', 'ignore') as file:
for line in file:
datalist1 = line.strip().split('\t')
if len(datalist1) != 3: # or datalist[1] not in train_label_list:
continue
batch_line.append(line.strip())
b_size+=1
if b_size == 1000:
test_id_list = [k.split('\t')[0] for k in batch_line]
test_label_list = [k.split('\t')[2] for k in batch_line]
test_content_list = [k.split('\t')[1] for k in batch_line]
test_idlist_list = [content2idList(content) for content in test_content_list]
test_X = kr.preprocessing.sequence.pad_sequences(test_idlist_list, seq_length) #预测接口
Y = predictAll(test_X)
format_predict5(Y)
batch_line.clear()
b_size = 0
fo.close()
elif sys.argv[1] == 'debug':
while(1):
title = input("title:")
if not title.strip():
continue
title_idlist_list = [content2idList(title.strip())]
test_X = kr.preprocessing.sequence.pad_sequences(title_idlist_list, seq_length)
selected_X = test_X[0:10]
predict_value = session.run(predict_Y, {X_holder:selected_X})
index_l = heapq.nlargest(10, range(len(predict_value[0])), predict_value[0].take) #获取前十个数下标
value_l = heapq.nlargest(10, predict_value[0])
for i in range(10):
line = ' '+str(i+1)+'. '+labelEncoder.classes_[index_l[i]]+'('+str(value_l[i]) +')'
print (line)
最后贴几张结果:
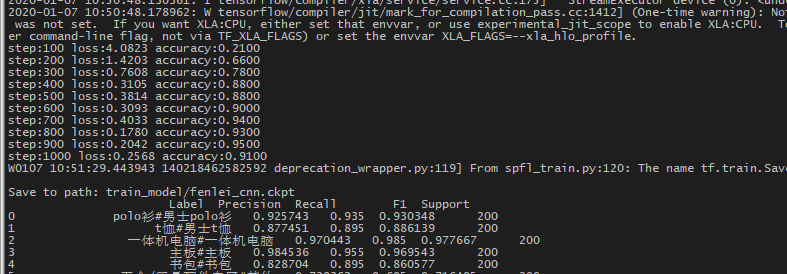
训练(上图)
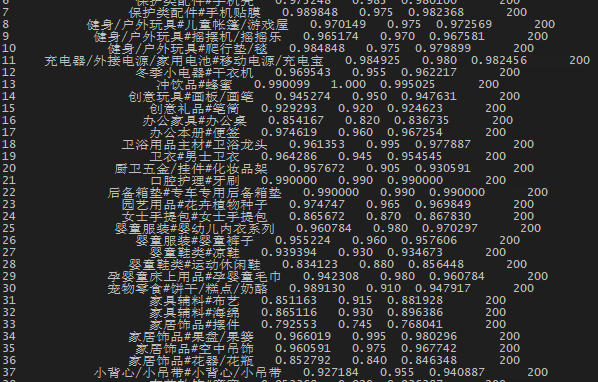
准确率 召回率 f1(上图)
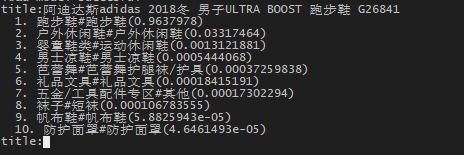
debug单条给出十个预测结果(上图)
分类代码以字为单位,没有进行分词,两部分代码可单独运行,100个类的测试集平均准确率可达到95%,有问题欢迎留言。
tensorflow文本分类实战——卷积神经网络CNN的更多相关文章
- 在 TensorFlow 中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- 在TensorFlow中实现文本分类的卷积神经网络
在TensorFlow中实现文本分类的卷积神经网络 Github提供了完整的代码: https://github.com/dennybritz/cnn-text-classification-tf 在 ...
- TensorFlow 2.0 深度学习实战 —— 浅谈卷积神经网络 CNN
前言 上一章为大家介绍过深度学习的基础和多层感知机 MLP 的应用,本章开始将深入讲解卷积神经网络的实用场景.卷积神经网络 CNN(Convolutional Neural Networks,Conv ...
- 深度学习之卷积神经网络CNN及tensorflow代码实现示例
深度学习之卷积神经网络CNN及tensorflow代码实现示例 2017年05月01日 13:28:21 cxmscb 阅读数 151413更多 分类专栏: 机器学习 深度学习 机器学习 版权声明 ...
- 卷积神经网络CNN原理以及TensorFlow实现
在知乎上看到一段介绍卷积神经网络的文章,感觉讲的特别直观明了,我整理了一下.首先介绍原理部分. [透析] 卷积神经网络CNN究竟是怎样一步一步工作的? 通过一个图像分类问题介绍卷积神经网络是如何工作的 ...
- 深度学习之卷积神经网络CNN及tensorflow代码实例
深度学习之卷积神经网络CNN及tensorflow代码实例 什么是卷积? 卷积的定义 从数学上讲,卷积就是一种运算,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分.级数,所以看起来觉得很复杂 ...
- 写给程序员的机器学习入门 (八) - 卷积神经网络 (CNN) - 图片分类和验证码识别
这一篇将会介绍卷积神经网络 (CNN),CNN 模型非常适合用来进行图片相关的学习,例如图片分类和验证码识别,也可以配合其他模型实现 OCR. 使用 Python 处理图片 在具体介绍 CNN 之前, ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(三)—— charCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- 每天进步一点点------时序分析基础与时钟约束实例(四)IO口时序(Input Delay /output Delay)
1.1 概述 在高速系统中FPGA时序约束不止包括内部时钟约束,还应包括完整的IO时序约束和时序例外约束才能实现PCB板级的时序收敛.因此,FPGA时序约束中IO口时序约束也是一个重点.只有约束正确 ...
- shell脚本入门笔记
转载:http://mp.weixin.qq.com/s?__biz=MzA3MTIxNzkyNg==&mid=204081791&idx=1&sn=27bb1d827e0f8 ...
- Docker容器里配置计划任务 crontab(DaoCloud+Docker +Laravel5)
最近项目涉及到一个定时任务的功能,所以去这几天研究了一下 crontab 的使用方法,按照网上的相关教程顺利在自己的电脑上成功开启了这个功能 Laravel + crontab 添加 crontab ...
- laravel5.1学习1-Model的创建
laravel5.1中可以很方便的用命令行创建Model 1.php artisan make:model Content 接着添加属性 $fillable =array('id','article_ ...
- 学习laravel遇到的问题
1.今天学习使用form的组件,首先使用composer命令来引入: composer require illuminate/html 接着在blog/config/app.php中的两个地方添加内容 ...
- Block Chain Learning Notes
区块链是什么 区块链技术是由比特币创造的,本文也将从比特币开始进行引导,一步一步告诉大家什么是区块链.如果你想立马知道区块链是什么,也可以直接转到文章末尾的区块链定义. 区块链,可能是当下最有前景又充 ...
- 【C语言】创建一个函数,并调用比较三个数的大小
#include <stdio.h> int max(int x,int y,int z) { if(x>=y) if(x>=z) return x; else return ...
- HDU 1312 Red and Black(经典DFS)
嗯... 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1312 一道很经典的dfs,设置上下左右四个方向,读入时记下起点,然后跑dfs即可...最后答 ...
- Could not transfer artifact org.springframework.boot:spring-boot-starter-parent:pom:2.1.9.RELEASE from/to 阿里云镜像地址
今天从 http://start.spring.io/ 下载的demo项目,导入eclipse后,pom文件一直报 parent包错,然后感觉就是自己maven镜像里面搜不到这个包, 所以改了 mav ...
- 本地缓存Caffeine
Caffeine 说起Guava Cache,很多人都不会陌生,它是Google Guava工具包中的一个非常方便易用的本地化缓存实现,基于LRU算法实现,支持多种缓存过期策略.由于Guava的大量使 ...