mode|平均数|方差|标准差|变异系数|四分位数|几何平均数|异众比率|偏态|峰态
应用统计学
数据的概括性度量
集中趋势
Mode众数是唯一描述无序类别数据,由图可知众数便是图形中的峰。


对于类别变量,众数就是某一种类别。
中位数和平均数都可能不是样本中的值。
中位数不受极值影响,对于类别数据来说,中位数是某一类别(同mode),各变量值与中位数的离差绝对值之和最小,与均数不同。
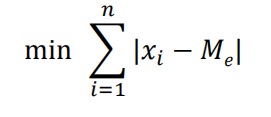
平均数的求法,令函数等于各变量值与平均数的离差平方之和,该函数表达如下式。
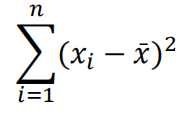
对该函数求一阶导,如下式,
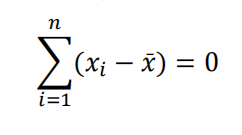
当一阶导为零时该函数取到最小值,此时样本均值表达式为:
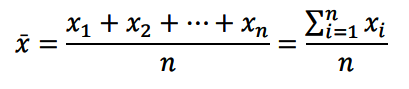
各变量值与平均数的离差平方之和最小,各变量值与中位数的离差绝对值之和最小。两性质验证如下表:
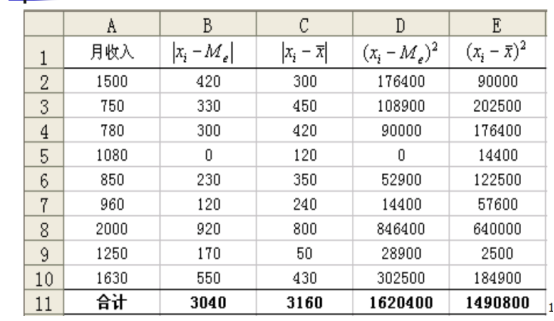
平均值可代数计算且无偏有效,所以数学属性比中位数好。
四分位数中上下四分位数有不同算法,算法的准确度也不同,但是n变大则各算法之间差距变小,同时变的更精确。
几何平均数推导:由以下公式转换,其中x值为比率。
100(1+G)=100(1+x1)(1+x2)(1+x3),等式变换之后得到G的表达式,该G值即为

应用:一种测量多次的平均数比一次测量更准确,样本均值的方差比随机变量的方差小,更准确。所以用样本均值的分布比总体分布的方差小。样本均值方差是总体分布方差/n.
离散趋势
因为平均值不能代表大多数情况,所以引入描述离散程度的特征值。
异众比率即与众数不一样观测值的比率,如下式。
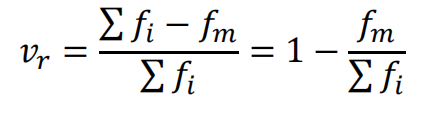
如果异众比率大,则其代表性不是很好。
四分位差:inter quartile range,即3/4处值-1/4处值。
极差:未考虑数据分布
平均差:离均差总和除以总数
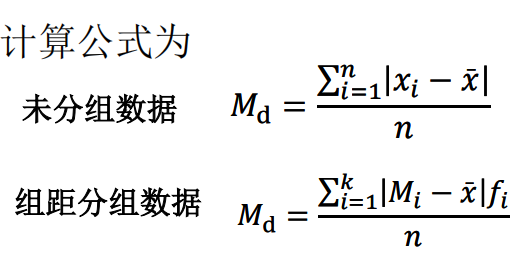
方差&标准差
为什么样本方差的分母为n-1?
若使用n作为分母,则用样本方差估计总体方差有偏。若使用样本方差则无偏。

2.自由度degree of freedom:指数据个数与附加给独立的观测值的约束或限制的个
数之差,即n-(约束个数)。所以就此例可知,要求样本方差,但其中除已知特征值外,还有一个样本均值的约束,所以样本方差的自由度为n-1。
除此之外还有变异系数,消除了数据水平高低和计量单位的影响。
偏态和峰态
偏态系数即表现数据分布的较正态分布的偏斜程度:

峰态系数即表现与标准正态分布比峰值的高低:

mode|平均数|方差|标准差|变异系数|四分位数|几何平均数|异众比率|偏态|峰态的更多相关文章
- 比率(ratio)|帕雷托图|雷达图|轮廓图|条形图|茎叶图|直方图|线图|折线图|间隔数据|比例数据|标准分数|标准差系数|离散系数|平均差|异众比率|四分位差|切比雪夫|右偏分布|
比率是什么? 比率(ratio) :不同类别数值的比值 在中文里,比率这个词被用来代表两个数量的比值,这包括了两个相似却在用法上有所区分的概念:一个是比的值:另一是变化率,是一个数量相对于另一数量的变 ...
- 方差+标准差+四分位数+z-score公式
一.方差公式 $S^2 = \frac{1}{N}\sum_{i=1}^{N}(X_i - \mu)^2 = \frac{1}{N}[(X_1-\mu)^2 + (X_2-\mu)^2 + ... + ...
- C语言之文件操作07——读取文件数据并计算均值方差标准差
//文件 /* =============================================================== 题目:从文本文件"high.txt" ...
- 数据分析First week(7.15~7.21)
描述统计学 当我们面对大量信息的时候,经常会出现数据越多,事实越模糊的情况,因此我们需要对数据进行简化,描述统计学就是用几个关键的数字来描述数据集的整体情况. 1.集中趋势 1.1 众数 众数是样本观 ...
- R语言笔记005——计算描述性统计量
数据的分布特征: 分布的集中趋势,反应各数据向其中心值靠拢或聚集的程度(平均数,中位数,四分位数,众数) 分布的离散程度,反应各数据远离其中心值的趋势(极差,四分位差,方差,标准差,离散系数) 分布的 ...
- 数据分析second week(7.22~7.28)
描述性统计Python实现 这周学习时间也就几个小时,由于python也正在学习,Anaconda也有,所以那些安装啥的就偷懒下不写了,直接贴出python代码 数据是随机生成,计算是调用库里的函数. ...
- 【Udacity】数据的集中程度:众数、平均数和中位数
重视Code Review 极致--目标是成为优秀的开发者 Data tells a story!(数据会讲故事) 分析过程对于建模非常的重要,可以帮助我们减少实际上不相关的特征被错误的加入到模型中, ...
- SPSS 2019年10月31日 20:20:53今日学习总结
◆描述性统计分析 概念:描述性统计分析方法是指应用分类.制表.图形及概括性数据指标(去均值,方差等)来概括数据分布特征的方法. 而推断性统计分析方法则是通过随机抽样,应用统计方法把从样本数据得到的结论 ...
- 描述性统计分析-用脚本将统计量函数批量化&分步骤逐一写出
计算各种描述性统计量函数脚本(myDescriptStat.R)如下: myDescriptStat <- function(x){ n <- length(x) #样本数据个数 m &l ...
随机推荐
- CodeForces 1294D MEX maximizing(思维)
http://codeforces.com/contest/1294/problem/D 大致题意: 刚开始有一个空集合,会往里添加q次数,每次加一个值,而且你可以让这个数任意加减x若干次 每次添加后 ...
- LeetCode——230. 二叉搜索树中第K小的元素
给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素. 说明: 你可以假设 k 总是有效的,1 ≤ k ≤ 二叉搜索树元素个数. 示例 1: 输入: root = ...
- MyBatis从入门到精通(第6章):6.3 使用枚举或其他对象
6.3 使用枚举或其他对象 在 sys_role 表中存在一个字段 enabled,这个字段只有两个可选值,0 为禁用,1 为启用.但是在 SysRole 类中,我们使用的是 Integer enab ...
- 关于PIL库Image模块的一些测试代码
为了加深理解,写了一些代码测试,在这里记录一下吧: 关于图片的模式问题,之前做过笔记,有“1”,“L”,"P","RGB","RGBA",& ...
- linux 查看链接库的版本
我们编译可执行文件的时候,会链接各种依赖库, 但是怎么知道依赖库的版本正确呢? 下面有几种办法: ldd 这是比较差的,因为打印结果更与位置相关 dpkg -l | grep libprotobuf ...
- Cover letter|review|Discussion
选择期刊考虑影响因子和载文量(流量) 分类:多学科eg:CNS 专业综合:eg:nature子刊:lancet:cell,jacs 细分:eg:CA-A 投完Cover letter后,根据审稿结果修 ...
- win32概述
win32基于已有的框架 有意入口函数只有一个 都需要有一个主函数 所有程序的入口都是maincrtstartup tydedef 顾名思义 window是基于c,c++ 又想有自己所特有的数据类型 ...
- Codeforces 1294E - Obtain a Permutation
题目大意: 给定一个n*m的矩阵 可以更改任意一个位置的值 也可以选择一整列全部往上移动一位,最上方的数移动到最下方 问最少操作多少次可以把这个矩阵移动成 1 2 3 ... m m+1 m+2 m+ ...
- tensorflow实现sphereFace网络(20层CNN)
#coding:utf-8 import tensorflow as tf from tensorflow.python.framework import ops import numpy as np ...
- Python模块——hashlib
简介 hashlib模块是用于对字符串进行加密,其可以把任意长度的数据转换为一个长度固定的数据串,且这种加密是不可逆的,故这种加密方式的安全性都很高.hash本质是一个函数,该模块提供了许多不同的加密 ...